Turn your Notion pages into a Website with your URLs and customizations. Faster than the previos version of notion-proxy because now Notion pages are parsed as static content.
Some other features avilable in the project are:
- inject JavaScript code
- inject CSS code
- robots file supported
We have a project called Industry 4.0 systems where we publish technical information about Industry 4.0. It's really confortable write this information on Notion and maintain our internal projects from there. We want to take in advantage our internal documentation system for publishing a web site with useful and public information.
So, this project is going to be a mechanism of publishing a useful web site using Notion as a CMS (Content Management System).
Project has three parts,
- The crawler, which is going to download Notion pages as HTML static files.
- get_slugs, which will create a map for static HTML pages and pretty URLs.
- OpenResty, it works as an HTTP server and an application server which is going to serve the site assets.
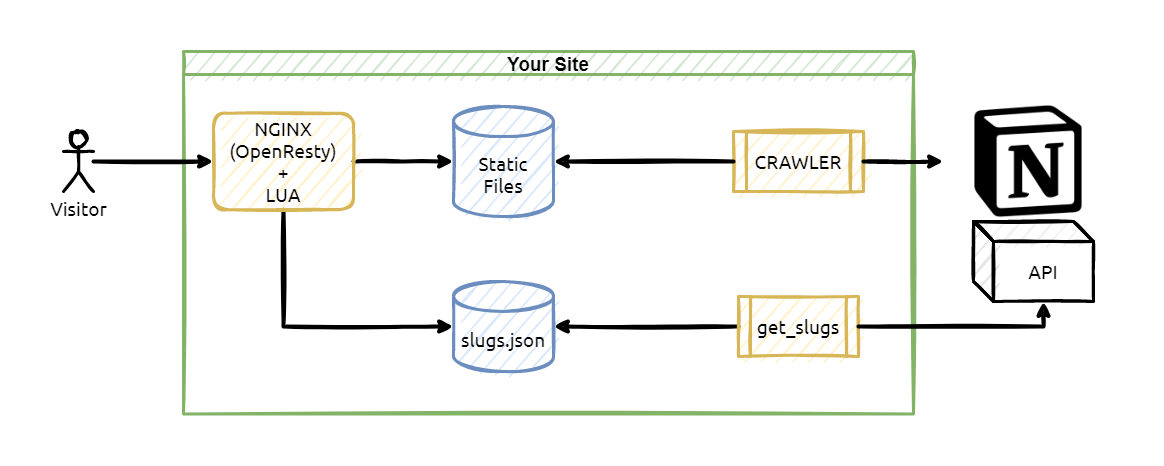
- Crawler module requires 2GB of RAM
git clone [email protected]:equiposinoficina/notion-proxy-ng.git
From here, we assume work directory is at notion-proxy-ng/.
- Docker: https://docs.docker.com/engine/install/
- Docker compose: https://docs.docker.com/compose/install/
installing docker dependencies
apt-get install \
apt-transport-https \
ca-certificates \
curl \
gnupg \
lsb-release
adding docker package repository
echo "deb [arch=amd64 signed-by=/usr/share/keyrings/docker-archive-keyring.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
adding gpg key for docker package repository
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /usr/share/keyrings/docker-archive-keyring.gpg
updating repository package list
apt update
installing docker package
apt-get install docker-ce docker-ce-cli containerd.io
downloading docker-compose
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
giving execution permissions to docker-compose
chmod +x /usr/local/bin/docker-compose
-
Edit crawler/config/site.toml with your parameters, file is auto descriptive:
name = "Industry 4.0 Systems" page = "https://i40sys.notion.site/Industry-4-0-Systems-89f2d3ee8c1249b38840f65d9b1ad392" [site] [[site.meta]] name = "Industry 4.0 Systems" content = "Crea tu propio gateway de IoT" [[site.meta]] name = "description" content = "" [site.fonts] site = 'Offside' navbar = 'Offside' title = 'Offside' h1 = 'Offside' h2 = 'Offside' h3 = 'Offside' body = 'Offside' code = 'Offside' [[site.inject.head.link]] rel="icon" sizes="16x16" type="image/png" href="favicon-16x16.png" [[site.inject.body.script]] type="text/javascript" src="notion-proxy.js" [pages] -
(Optional) For speeding up parsing process, we use an small trick, the idea is set up to localhost the URL hostnames of the iframes which are repeated often in our Notion web pages. If you want to take advantage of that trick, just edit the file crawler/docker-compose.yml. Adding to the "extra_hosts" list your hostnames, in our case the list is:
... extra_hosts: - "youtu.be:127.0.0.1" - "youtube.com:127.0.0.1" - "www.youtube.com:127.0.0.1" - "industry40.systems:127.0.0.1" ... -
Go to the crawler/ directory and build the crawler container:
docker-compose build -
Check that everything is OK with this command:
sudo docker image ls| grep crawleroutput has to be like that:
notion-proxy-ng-crawler latest 8f7e74d94547 3 days ago 1.58GB
Run this container means download and parse Notion pages and convert them to static files.
Go to the crawler/ directory and run:
sudo docker-compose up && sudo docker-compose down
This is going to launch two containers:
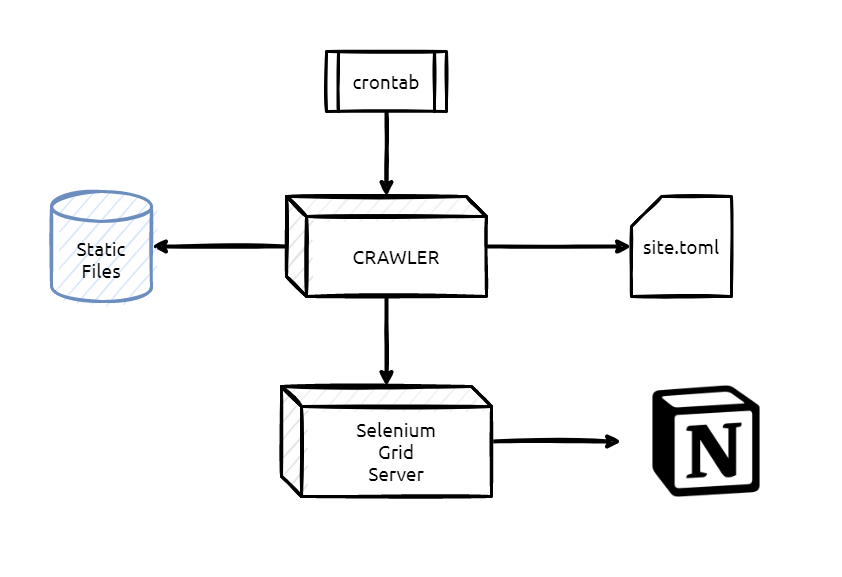
Crawler uses Selenium Grid Server standalone as a virtual browser for retrieving Notion pages.
When the parsing process finishes both container are removed thanks to the 'down' process.
Once everything works OK you can add the 'up' and 'down' process to the crontab.
Point your browser to the URL of the Selenium Grid Server container, usually it will be:
http://localhost:4444
At this page there status information, like the session list and IDs.
In the port 7900 there is a web VNC client which uses the password: secret with the browser session.
http://localhost:7900
Remember to change localhost to the container IP address if you are not running the crawler in your local machine.
If Selenium Grid Server has a stacked session next command can be useful:
curl -v --request DELETE 'http://localhost:4444/se/grid/node/session/<session_id>' --header 'X-REGISTRATION-SECRET;'
Just point the prompt to the directory get_slugs/ and execute:
docker-compose build
Then change owner of cache/ directory:
chown 1000:1000 cache
First of all, remember that slugs are optional and only used for prettifying URLs.
Slugs is a process which uses Notion API for creating a local cache of page ids mapping slug URIs. The cache file will be located at cache/slugs.json.
We organize our pages in tables, take a look at this, for an example:
https://notion.so/423b6065220d4879be893a604602f3fb
Note if you are getting this error: [ERROR] table content empty, file not written. You need to add a property. I added a number property named # (per the example) and assigned them accordingy.
Start configuring the configuration file at get_slugs/config/default.json. You can copy the content of the example file at: get_slugs/config/config.json.example.
If you don't have Notion API key follow the instructions at: https://developers.notion.com/docs/getting-started
When it's configured, it's time to run the process manually, go to get_slugs/ directory and execute:
./run.sh
If everything works OK exit code will be 0 and cache file will have a JSON file, check file timestamp for ensuring it is created just when the script finishes the execution.
Nginx configuration file is located at http/config/main.conf, usually it's not necessary to change anything.
By default port used is :3333, you can change it just modifying docker-compose.yml.
Finally just run:
docker-compose up -d
- Crawler code is based on loconotion created by Leonardo Cavaletti [email protected], thanks for your great work Leonardo.
- loconotion uses chromedriver integrated on its container but it didn't work as good as we expected and we decided to use a project called Selenium Grid Server, so thanks a lot for so great job guys.
- Another inspiring author is Aitor Roma who created https://github.com/aitorroma/aitorroma.com
- Thanks to https://pandao.github.io/editor.md/en.html for helping us with the markdown language.
- And inite thanks to all authors of the Open Sources project that we integrated and supported our code.
GNU General Public License v3.0
Dani Aguayo - http://danielaguayo.com
Oriol Rius - https://oriolrius.me