{kind=link}
Cloudimized is a Google Cloud Platform (GCP) configuration scanning tool. It allows monitoring changes of selected resources.
Cloudimized performs similar function as Oxidized, but for Cloud environment.
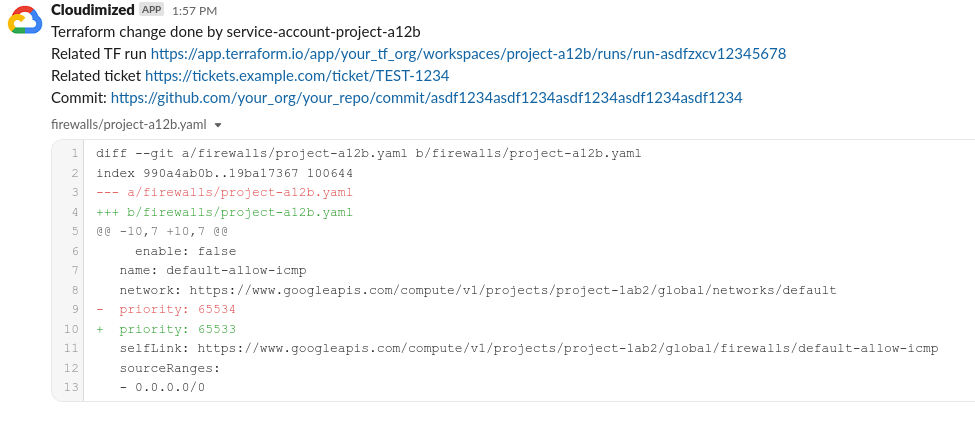
Cloudimized periodical scans of GCP resources via API calls and dumps them into yaml files. Files are tracked in Git, so every configuration change is being tracked. It gathers additional information for each change: changer's identity, related Terraform runs (optionally), identify change ticket number (optionally). Optionally it sends Slack notifications for each change.
- Project discovery across GCP organization
- Identifying changer identity
- Manual changes detection
- Identifying Terraform runs
- Identifying change tickets
- Slack notifications
On each execution Cloudimized performs following actions:
- Gets configuration from previous execution from Git remote
- Clears all configuration files from local repo
- Performs resource reading
- For all projects for all resources executes API call to get resource configuration
- (optional) Performs configured field and item filtering for each resource
- Dumps all results in yaml files format in local Git repo
- Checks local Git repo state and detects all changed resource
- For each detected change performs additional information gathering:
- Get GCP Logs for change to identify changer's identity
- Identifies manual changes
- changes performed directly by individual users as opposed to service accounts i.e. changes done outside of Terraform
- (optional) If change performed via Terraform Service Account, identify related Terraform runs.
- Get Terraform Runs URL
- (optional) Get ticket/issue marker from Terraform Run message. Generate ticket URL.
- Commit each individual change to Git repo
- Contains configuration Git diff
- Contains all additional gathered information
- (optional) Send Slack notification for each change
- Containing same information as Git commit
- Push new commits to remote repo
- Install Cloudimized with pipx (recommended) or plain pip.
pipx install cloudimized
- Cloudimized for operation requires Git repo for storing GCP configuration files.
- Set-up empty Git repo in remote location i.e. GitHub or GitLab
After installation:
- Perform necessary configuration
- Schedule periodic, regular script execution
- This can be achieved via number of ways i.e.
- via cron
- via automation server
- Execute with
cloudimized -c <PATH_TO_FILE>/config.yaml
- This can be achieved via number of ways i.e.
GCP Service Account is used to perform resources scanning, log reading and project discovery. Below steps show setting up account with organization wide reading permissions.
- Create dedicated Service Account in selected GCP project
- On organization level create custom role with permissions:
- logging.logEntries.list //required to identify changer
- <resource>.list //for each resource to be scanned
- i.e. compute.subnetworks.list for scanning of VPC subnetwork resource
- Refer to official Google docs for method and its permission mapping
- On organization level create IAM policy that binds Service Account with Roles: Browser and custom role you've created
This will grant Service Account permission to discover all projects in Organzation, perform scanning of selected resources in all projects and perform Logs scanning in all projects. If needed it is possible to limit permissions to selected Folders and/or Projects.
See:
GIT Service Account is used to get configuration repository from remote and pushing to that repo detected configuration changes. In your GIT remote you need to configure account/access token with proper permissions. Script allows communication via both HTTPS and SSH.
Terraform Account is used to read Terraform Runs. Concept of Service Account doesn't exist in Terraform, so this is performed in following way:
- Create Terraform Team with "Runs: Read Runs" permissions
- For each Terraform organization generate Team API token for your Team
See:
Slack Service Account is used for sending detected change notification to Slack channel. This is done via Slack App.
- Create Slack app on Slack API page
- Select From scratch
- App Name - enter Cloudimized
- Workspace - select your workspace
- In Add features and funcionality select Permissions
- In Scopes -> Bot Token Scopes, click Add an OAuth Scopes
- Select files:write
- In OAuth Tokens for Your Woskrpace, click Install to Workspace
- Click Allow access
- Bot User OAuth Token has been generated, take a note
- Select/create channel to which notifications will be sent
- Add App bot user by @mentioning App name in selected channel
See:
Jira Service Account is used for creating issues(tickets) for selected changes. Depending on your Jira deployement (Cloud vs Server), you need to setup an account with proper permissions to create Issues of selected type in given project.
See:
All secrets required to run script need to be passed via env variables.
Communication with GIT remote can be both SSH and HTTPS based. If using SSH you need to take care of your SSH keys configuration. If using HTTPS you need to pass credentials via following env variables:
- env var
GIT_USR- username - env var
GIT_PSW- password/token
Cloudimized authenticates to GCP using GCP Service Account. After creating account you need to download JSON key file. Passing credentials to script can be achieved either by setting env var or using Google's ADC mechanism
- env var
GOOGLE_APPLICATION_CREDENTIALSset to file path of service account's JSON key token
or
- Authenticate via
gcloud auth application-default loginby providing service account's JSON key token
See:
- Best practices to securely authenticate applications in Google Cloud
- Authenticating as a service account
- gcloud auth application-default login
Cloudimized authenticates to Terraform using Team token for each Terraform organization. Tokens are stored in JSON file that only contains mapping between organization and team token value. File is passed to script by providing JSON file location. This can be done by:
- env var
TERRAFORM_READ_TOKENSset to file path of terraform's JSON mapping key
or
- option
workspace_token_filein configuration file set to file path of terraform's JSON mapping key
Cloudimized authenticates to Slack using Slack's Applications Bot User token. Token is passed to script via env var
- env var
SLACK_TOKENset to token value
Cloudimized authenticates to Jira using Username and Password/Token combination. Credentials are passed to script via env var
- env var
JIRA_USR- Jira's username - (note: not set when using Token auth) - env var
JIRA_PSW- Jira's password/Token
Example configuration file:
services:
# GCP API Service name - https://cloud.google.com/compute/docs/reference/rest/v1#service:-compute.googleapis.com
- serviceName: compute
# GCP API version - https://cloud.google.com/compute/docs/reference/rest/v1#service:-compute.googleapis.com
version: v1
# List of all queries to send for this API Service
queries:
# User defined name of resource
- resource: networks
# GCP API method name - https://cloud.google.com/compute/docs/reference/rest/v1/networks/list
gcp_api_call: networks.list
# GCP API method parameters - https://cloud.google.com/compute/docs/reference/rest/v1/networks/list#path-parameters
gcp_function_args:
# Special Cloudimized value for setting ProjectID - script performs dynamic replacement with real Project ID
project: <PROJECT_ID>
# resource.type value in GCP Logs entries generated for this resource changes - https://cloud.google.com/logging/docs/api/v2/resource-list#tag_gce_network
gcp_log_resource_type: gce_network
# Field name in response where resources are stored, (DEFAULT: items) - https://cloud.google.com/compute/docs/reference/rest/v1/networks/list#response-body
# items: items
# List of fields to exclude from configuration i.e. for status related fields
field_exclude_filter:
# From each resource remove field "stateDetails" nested under "peerings"
- peerings:
# https://cloud.google.com/compute/docs/reference/rest/v1/networks/list#response-body
- stateDetails
# List of conditions to filter out whole individual resources
item_exclude_filter:
# From results remove each resource that "name" under "peerings" matches "servicenetwork-googleapis-com"
- peerings:
name: "servicenetworking-googleapis-com"
sortFields:
# Define fields used to perform sorting of results
## Sort items in results using 'name' field as key
- name
## Sort inner list (under key 'secondaryIpRanges') in each item using 'name' field as key
- secondaryIpRanges: name
git:
# Git repo's URL for GCP configuration storing
remote_url: https://github.com/<ORG>/<REPO_NAME>
# Local directory for storing GCP configuration
local_directory: gcp_config
# Perform dynamic discovery of all projects in GCP organization
discover_projects: True
# Static list of project IDs (alternative to the above approach)
#project_list:
# # GCP project ID
# - my-project-ID
# List of project IDs to exclude from scanning - for use with dynamic discoery
excluded_projects:
- excluded-project-ID
# Number of threads for scanning resources
thread_count: 4 # default - 3
# Change handling configuration
change_processor:
# Interval (in minutes) between each scan - has to match script execution interval
scan_interval: 30
# Regex to identify service account username - match meaning non-manual change
service_account_regex: '^(my-terraform-sa-|\d+@|service-\d+).*'
# Regex to identify ticket/issue from Terraform Run message i.e. ADR-1234
ticket_regex: "^.*?([a-zA-z]{2,3}[-_][0-9]+).*"
# Ticket/Issue URL base in ticketing system. Used to create ticket link
ticket_sys_url: "https://my-tickets.com/list"
# Slack notifications config
slack:
# Slack channel ID for Cloudimized notifications
channelID: "C123456789A"
# Commit URL base in Git system. Used to create commit link
repoCommitURL: "https://github.com/<ORG>/<REPO_NAME>/commit"
# Jira issue creator config
jira:
# Jira's URL
url: "https://my.jira.com"
# Jira's Project Key - Project in which create issue
projectKey: "KEY"
# Jira's Issue Type - Issue's type to be created (optional)
issueType: "Task" #default
# Jira's Issue fields - set values on fields in Issue (optional)
fields:
field_name: "field_value"
# Regex filter for selecting projects for which create issues (optional)
filterSet:
projectId: ".*production-only.*"
# Flag to indicate token use for auth instead of Username/Password
isToken: True
# Terraform Runs configuration
terraform:
# Terraform URL
url: "https://app.terraform.io"
# Path to JSON file containing Organization to team token mapping
#workspace_token_file: "<path-to-file>"
# Mapping between GCP Service Account performing changes and Terraform Org/Workspace
service_workspace_map:
# GCP Service Account name
terraform-service-account-no1:
# Terraform Organization
org: my-organization
# Terraform workspaces list
workspace: ["my-workspace-no1"] Allows to run cloudimized only to scan given resource and dump them into text files, without performing and additional functions (no Git, Terraform, Slack, Jira interaction and no GCP logs lookup).
cloudimized --singlerun/-s <RESOURCE_NAME> --output/-o {yaml, csv}
i.e
cloudimized -s addresses -o csv
Resource configurations for single run (<RESOURCE_NAME> parameter) to be scanned are stored in singlerunconfigs directory and are selected based on filename. Resource configuration is the same as in main config file. Additional singe run mode configs can be added to folder as needed.
Get info available configs or what will be run with <RESOURCE_NAME> with:
cloudimized -s --list
cloudimized -s --describe --name <RESOURCE_NAME>
By default script will dump results in YAML format same as in main mode. If chosen it can dump results in CSV file format (single file per resource).