
Wrapper for The Nu Html Checker (v.Nu)
You need to install the "Java" for working with
node-w3c-validator
Visit https://java.com for downloading the "Java" if you not have it
Install as global package
npm i -g node-w3c-validatorUsage
node-w3c-validator -i ./dist/*.html -f html -o ./reports/result.html -sYou may pass a glob pattern too
node-w3c-validator -i ./dist/**/*.html -f html -o ./reports/result.html -sValidate input path.
default: process.cwd()
Exclude from input path.
default: unset
Specifies whether ASCII quotation marks are substituted for Unicode smart quotation marks in messages.
default: unset
Specifies that only error-level messages and non-document-error messages are reported (so that warnings and info messages are not reported).
default: unset, all message reported, including warnings & info messages
Makes the checker exit zero even if errors are reported for any documents
Specifies the output format for reporting the results
default: unset
possible values: gnu | xml | json | text | html | lint
lintformat is available from 1.4.0 version.
lintformat is designed for convenient error output to the terminal.
it uses a eslint-formatter-pretty under the hood
Specifies a filename. Each line of the file contains either a regular expression or starts with "#" to indicate the line is a comment. Any error message or warning message that matches a regular expression in the file is filtered out (dropped/suppressed)
default: unset, checker does no message filtering
Specifies a regular-expression pattern. Any error message or warning message that matches the pattern is filtered out (dropped/suppressed)
default: unset, checker does no message filtering
Skip documents that don’t have *.html, *.htm, *.xhtml, or *.xht extensions.
default: unset, all documents found are checked, regardless of extension
Forces any *.xhtml or *.xht documents to be parsed using the HTML parser.
default: unset, XML parser is used for *.xhtml and *.xht documents
Disables language detection, so that documents are not checked for missing or mislabeled html[lang] attributes.
default: unset, language detection & html[lang] checking are performed
Forces all documents to be be parsed in buffered mode instead of streaming mode (causes some parse errors to be treated as non-fatal document errors instead of as fatal document errors).
default: unset, non-streamable parse errors cause fatal document errors
Specifies "verbose" output. (Currently this just means that the names of files being checked are written to stdout.)
default: unset, output is not verbose
Shows the current version number.
Write reporting result to the path
Increase maxBuffer size to prevent !!! OUTPUT ERROR or Unexpected end of JSON input errors. This is because child_process stdout being truncated when validator check a lot of files.
# increase buffer size (1024 * 500)
node-w3c-validator -i static/**/*.html -b 500// increase buffer size (1024 * 500)
nodeW3CValidator(validatePath, {
format: 'html',
exec: {
buffersize: 1024 * 500
}
}, function (err, output) {
// ...
});Install in your project
npm i --save-dev node-w3c-validatorParameters:
| Name | Data type | Description |
|---|---|---|
pathTo |
string |
The path to the folder or directly to the file, for verification, also it can be url to the Web document |
options |
Object |
Options for validating, sеe description below |
done |
Function |
Validation callback, sеe description below |
You can use all available options from CLI / Options. Only change props name to the camelCase style,
exeception --no-stream and --no-langdetect they must be declared without no part
example
--errors-only-errorsOnly: true--no-langdetect-langdetect: false--format json-format: 'json'
an exception
--buffersize 500
transforms to
exec: {
buffersize: 1024 * 500
}Validation callback.
Parameters:
| Name | Data type | Description |
|---|---|---|
err |
Error / null |
if no errors - will be null, otherwise - Error object |
output |
string |
string with reporting result, if no errors - can be as empty string |
Write file
Parameters:
| Name | Data type | Argument | Description |
|---|---|---|---|
filePath |
string |
relative path to saving a file | |
outputData |
string / Buffer |
file output content | |
done |
Function |
optional | if exist - it will asynchronous writes output to the filePath. See fs.writeFile(file, data, callback) |
// imports
const nodeW3CValidator = require('node-w3c-validator');
// paths
const validatePath = './dist/*.html';
// or directly to the file - './dist/index.html'
// or a glob pattern - './dist/**/*.html'
const resultOutput = './reports/result.html';
// validate
nodeW3CValidator(validatePath, {
format: 'html',
skipNonHtml: true,
verbose: true
}, function (err, output) {
if (err === null) {
return;
}
nodeW3CValidator.writeFile(resultOutput, output);
});You can ignore some errors or warnings by suppressing them.
Note! This feature can be used only on html, json and lint formats.
You need to specify nodeW3Cvalidator field in your project package.json file.
Here can be two arrays, for errors (suppressErrors) and warnigns(suppressWarnings).
Values must be a string parts or fully value of "unwanted" message.
Under the hood - node-w3c-validator will use String.protorype.includes
method for filtering messages.
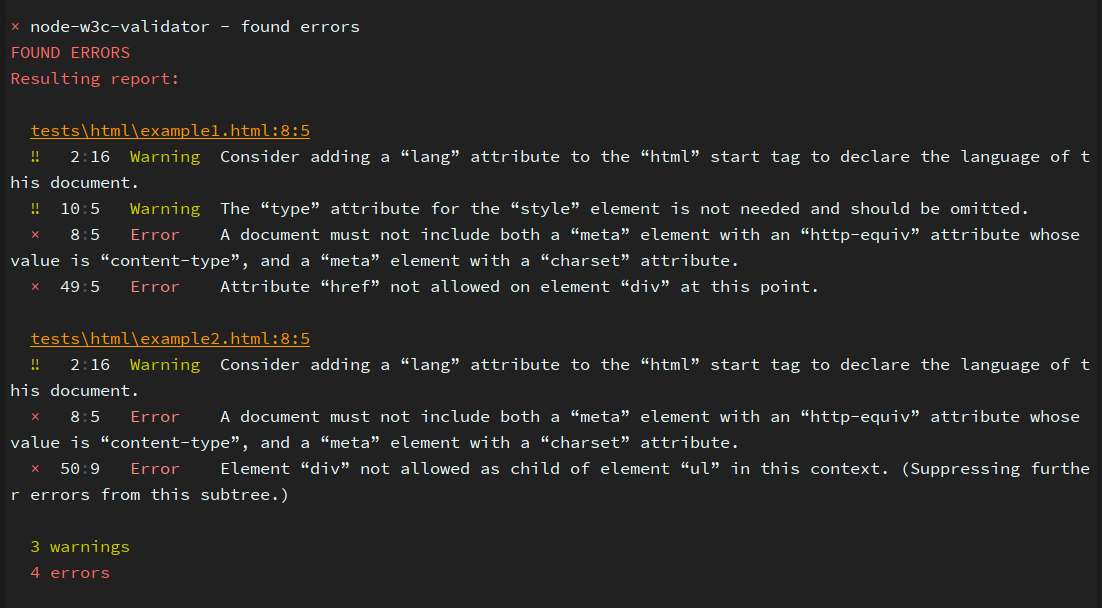
For example, you receive warning message:
The “type” attribute for the “style” element is not needed and should be omitted.
Now you can suppress it
{
"nodeW3Cvalidator": {
"suppressErrors": [],
"suppressWarnings": [
"The “type” attribute for the “style” element is not needed and should be omitted."
]
}
}Or like this with a part of message:
{
"nodeW3Cvalidator": {
"suppressErrors": [],
"suppressWarnings": [
"is not needed and should be omitted"
]
}
}See Releases history
Please read CONTRIBUTING.md
Please read CODE_OF_CONDUCT.md