RyuJIT: Allow developers to provide Branch Prediction Information #6225
Comments
|
@lemmaa @seanshpark @parjong @chunseoklee We might need to consider this option (something like "likely" and "unlikely" macros in Linux kernel) for ARM optimisation. |
|
@myungjoo afaik the Linux kernel "likely" and "unlikely" is actually The idea that I had in mind is providing something like this: public static class Unsafe
{
[JitIntrinsec]
[MethodImpl(MethodImplOptions.AggresiveOptimization)]
public bool Expect ( bool value, bool branchTaken )
{
return value;
}
}In that way, if the JIT version do understand it, it can (after inlining) reorder the blocks and put the unlikely branch at the end of the method (very away from the critical path). If it is not understood, the inlining process will eliminate the call altogether. Surely it is not an optimization for everybody, but there are cases where it would make sense. |
|
Related issue: #4966 |
|
cc @dotnet/jit-contrib |
|
I like the idea, and using |
|
@CarolEidt I was using the existing practice to show the idea. Another alternative is |
|
I think the biggest problem with this construct is its ability to become stale rapidly. There are certainly less problematic use cases, like error handling functions, whose likelihood is easy to validate via code inspection and can be abstracted behind wrapper methods, but other cases become very sensitive to level of programmer discipline to properly maintain accurate information, lest seemingly innocent refactoring leads to big local performance losses that accumulate because they are difficult to detect individually (bitrot). I'm no fan of telling people they can't have a sometimes-useful feature just because other people might shoot themselves in the foot with it, but I do think we should consider not adding this until we have rich tooling/infrastructure available to validate the annotations and possibly even automatically update them based on profile data. The big problem with that argument is that such infrastructure would probably share a lot of features with a proper profile feedback system, so one might argue you should just wait for the whole thing. That said, this is being proposed as a stopgap. Perhaps it's acceptable to live with the potential for misuse until a proper profile feedback system comes online, at which time we commit to the annotation validation infrastructure. |
|
@RussKeldorph wholeheartly agree with you, this is choosing between giving the developer the power to get higher quality code; which is easy to build (and probably can be done in a few weeks by one of your guys) and could have a huge impact, even if some devs occasionally forget they have a loaded gun and shoot themselves in the foot. On the other hand, we have a very hard problem which can takes months to build and probably a year or two to get right (which would be very useful to have available today, even in rudimentary state). I am a lazy programmer, I would prefer the JIT to do the proper job every time, but I also know that is impossible for every single case... for most, if the JIT can handle the 99% its great, but IMHO we shouldnt punish the 1% either, because those are the framework, library and/or high performance developer that later make the great business cases. The work that was done at Kestrel on the performance front is such an achievement. A single morpher (https://github.com/dotnet/coreclr/issues/1619) improved most managed implementations of hashing functions (both at the framework and at our end) by a wide margin, couldnt have been done without providing the tools to do so. |
|
The JIT could use likelihood information to type-specialize by cloning code for different cases. Here, it could specialize the code for arrays and other IList's: Turning into: Multiple cases could be supported e.g. |
|
Somewhat related to the |
|
Just to provide some context of the kind of speed up (and business value) this kind of optimization can achieve and the complexity of the code we have to write to work-around the lack of control. This is the code we have to write: [MethodImpl(MethodImplOptions.AggressiveInlining)]
public byte* GetTailPointer(int offset, bool isWritable = false)
{
if (_lastTailPointer.PageNumber == Header.Ptr->TailPageNumber)
return _lastTailPointer.Value.DataPointer + offset;
// This is an unlikely case which doesnt make any sense to inline.
// A method call is smaller than all the code that has to be executed.
return UnlikelyGetTailPointer(offset, isWritable);
}
private byte* UnlikelyGetTailPointer(int offset, bool isWritable)
{
var page = _pageLocator.GetReadOnlyPage(Header.Ptr->TailPageNumber);
_lastTailPointer = new PageHandlePtr(page, isWritable);
return page.DataPointer + offset;
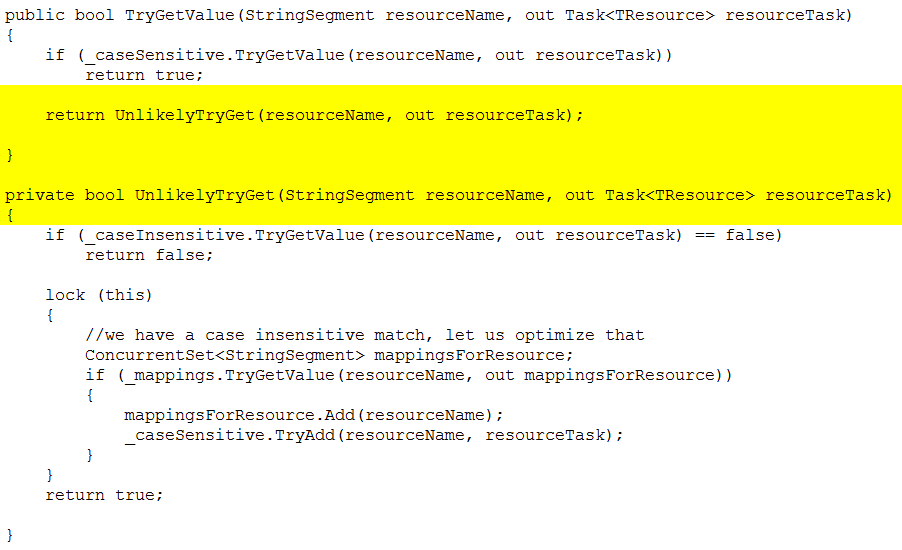
}and we have many such routines, it is not an isolated case. For a detailed analysis on how much we are able to gain using this workaround see: https://ayende.com/blog/175841/multiple-optimizations-passes-with-case-insensitive-routing For reference purposes... This is pre-optimization: We shaved 6%+ (or 250ms) with this simple change (which could have been automatically done by the JIT knowing the second part of the branch is And given these results, we are sure that using unlikely hints at the codegen level could generate far bigger improvements... Hope this helps to upgrade the priority of this optimization ;) PS: For the other ugly hacks, aka optimization oportunities, you can take a look to that and other blog series where we show the workarounds we use. |

|
This looks like partial inlining, not branch prediction stuff. Granted, partial inlining would need to know if the branch is likely taken or not but ultimately partial inlining is a feature in its own right and not a trivial one. |
|
Branch predicción and aggresive inlining will behave in the same way as partial inlining. I the JIT knows that first part of the code is expected or the second is rare, then it will be marked cold. the rare block of code is going to be written at the end of the method. With the added benefit of skipping the method call altogether. Partial inlining in its own right is very difficult but you can still get a restricted one with branch prediction information. |
This doesn't apply to
It doesn't really matter where that block of code is going to be written. What marking a block as rarely run may do is improve register allocation and in turn that may make the surrounding code more efficient. Or not, it depends on the code. You got 6% improvement by eliminating a call from a hot path. There's no evidence anywhere that lifting the EH inlining restriction and inlining the original |
|
Not really that is just a single example, our most common example is the code I posted (as code). Agree that the blog example which would require EH but we can still workaround it (as we did it) in those cases. Most of the time we are just dealing with our code, therefore we are (among other things) abusing goto's to control the emitted code and generate cold sections by hand (which could be solved by the JIT if the hint is provided). The improvement is rarely less than 6% on tight code-paths (which we have many). If you are interested into measuring the difference on a real business critical example just try out the different alternatives of our The one that probably is most interesting for this issue purposes is: |
|
So if I understand correctly PageLocatorV7 is the best version you have. And 32 items probably means that cacheSize is 32. I played with Anyway, that code doesn't need And I presume that this code usually runs on 64 bit machines. If that's the case then the code performance actually sucks because the iteration variable is of type |
|
Depends on the processor, we have to support a wide array of hardware. On our lowest level hw (the one we use for measurements) int had a sensible advantage by the time we introduced the use of fingerprints. Gonna take a look if bound checking removal had any side effect there. To the point, unlikely is not just branch prediction it is also a hint to move the block outside of the hot path entirely. That is an example where you use it before the exit block, which is not always the case. Sure there are many code layout missing optimizations but today there is just no choice to control the layout, branch or block hints give you exactly that without nasty goto hacks. There are also many cases where not even a C compiler can take the code outside of the loop without an expect directive. |
|
Btw use Read because in many cases the other ops weren't optimized at all and are leftovers of previous attempt s |
There's no way that
Well, it certainly has nothing to do with branch prediction, the CPU should have no problem predicting those branches correctly. The slowdown is most likely caused by the slightly higher cost of taken branches (even if they're correctly predicted) and instruction decoder bandwidth waste. One of those 4-compare blocks has ~48 bytes if the code is not move outside of the loop and ~16 bytes if the code is moved. 2 x 32 code bytes go down the drain on every iteration.
As far as I can tell that while loop is identical in Read/Write/Reset. |
|
At higher sizes the memory loads add up. We optimized this to move from 16 to 64+ ... Eventually we figured out that for most cases we can manage with 64. At 8 bytes per item with 64 items size it's still 512 bytes vs 256 bytes. As long as you can keep that horrendous code dependency free the processor still manages to execute it very efficiently. I will try out long on a few architectures next week to see experimentally if we can get better performance out of this. But let's keep the discussion on the point. JIT branch prediction is quite a different beast than processor prediction which works very well. The point of this optimization is being able to mark blocks of code as cold and move it out of the way in order to save along other things decoder bandwidth (which has a tremendous impact on tight code) in the same way the JIT moved exception code away. This optimization will in order be useful for inlining? Yes, specifically when dealing with partial inlining. The inliner would never inline the part of the code that's cold. Will issue an standard call for it, in the same way that it forces a jump to an out of the way code when hitting a cold block. More specifically the point of this issue is give information to the JIT that the dev knows to make its job easier and obtain better code because of it. |
|
I think several things that RyuJIT currently doesn't do have been said here. Namely:
Does anyone like to see them made into GH issues (if not already) for tracking purposes? |
|
Is this something that can/should be baked into IL as prefixes for branching instructions? Ultimately I'd like to see something like this: I'd like this to drive code generation to pack the hot path as close together as possible for cache optimization. So this would create: This could also enable PGO prior to distribution without needing AOT. |
|
@scalablecory For blocks that clearly always throw, shouldn't that be done automatically? I think |
|
@svick you're right, I totally forgot about that rule. So -- not the best example. There are plenty more blocks I could use this for, though. The problem is that for a lot of code this doesn't matter, but when it does matter it can have a significant benefit... which means perf-sensitive code (often not the simplest to read already) becomes even more loopy, like with @redknightlois's example. |
|
I have plans sketched out for how the JIT should eventually tackle this sort of thing (as part of a much larger effort), but haven't ever polished them to the point where they'd make sense to a wider audience. Let me try and give an overview here:
I was hoping to get some of the groundwork for this in place during 3.0 but it didn't happen. As we start to think about post-3.0 work, I'll try and polish my notes and put forth specific proposals for some of the above. |
|
Also it'd be nice to have an api for switch(Expect(x, 10)) {
case 0: |
|
With any luck we may actually get around to this in the 8.0 release. |
|
Cost on its own is not large, but it's a follow-on on efforts that are large, so leaving the costing as is for now. |
The
__builtin_expectfunction provided by GCC comes to my mind here. While I would root for a great profile based collection system, this could be very helpful as an stopgap into that direction.http://stackoverflow.com/questions/7346929/why-do-we-use-builtin-expect-when-a-straightforward-way-is-to-use-if-else
category:cq
theme:profile-feedback
skill-level:expert
cost:large
The text was updated successfully, but these errors were encountered: