This project aims to analyze and improve the performance of a customer loan product for a fintech company. The provided dataset (credit_default.json) includes various customer attributes, such as age, sex, job, housing status, purpose of the loan, and financial metrics. The ultimate goal is to build a predictive model to identify customers at risk of default.
Formulate the problem statement: Improve the performance of the customer loan product by analyzing customer attributes and building a predictive model to identify potential defaults.
-
Descriptive Analysis:
- Examining the distribution of age, gender, occupation, housing status, loan purpose, average balances, and loan durations.
- Calculating descriptive statistics such as mean, median, mode, and visualizing data using graphs and diagrams.
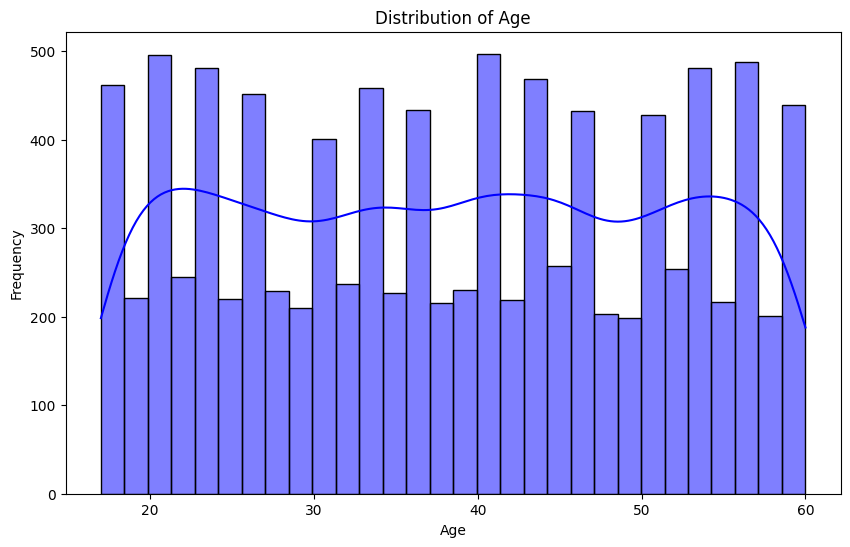
- Distribution Age
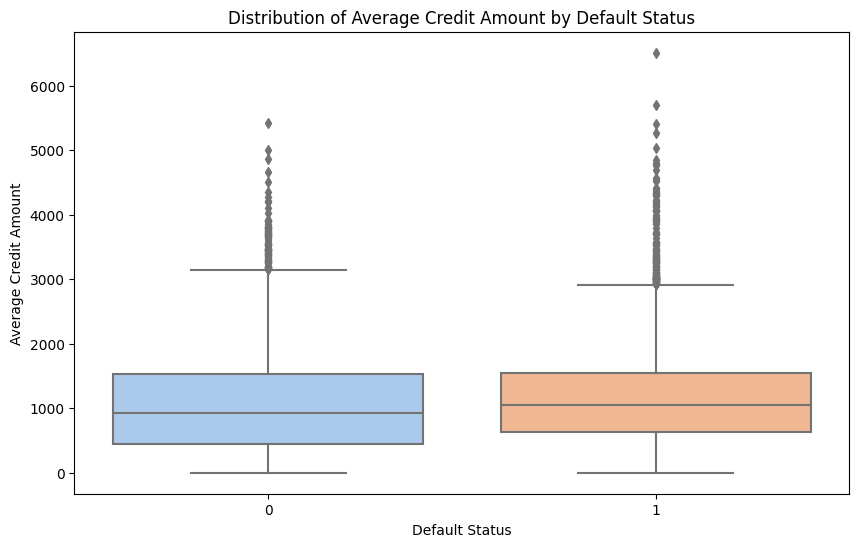
- Distribution of Average Credit Amount by Default Status
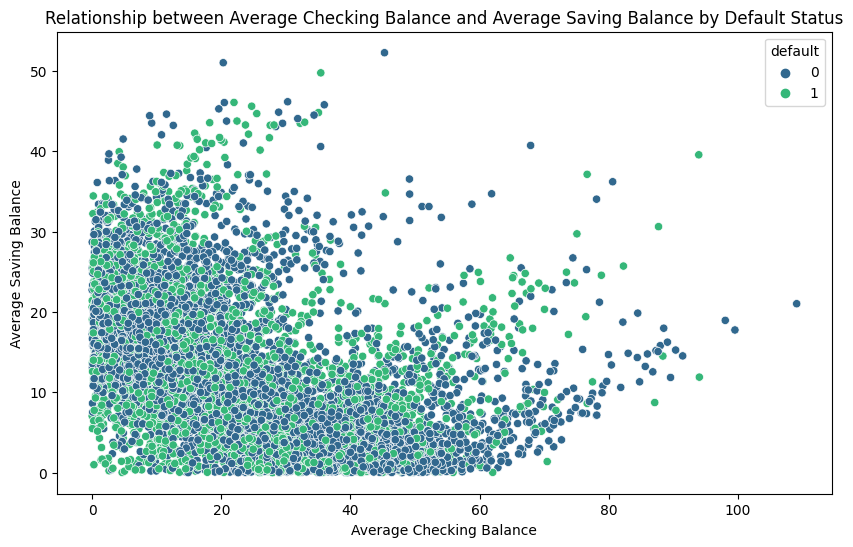
- Relationship between Average Checking Balance and Average Saving Balance by Default Status
- Distribution Age
-
Attribute Influence on Default:
- Conduct statistical tests (t-test) to identify attributes significantly influencing defaults.
- Example: Test the significance of average loan duration for default and non-default customers.
-
Classification Model:
- Preprocess data by handling missing values and encoding categorical variables.
- Build a RandomForestClassifier model.
- Perform hyperparameter tuning using GridSearchCV.
-
Model Evaluation:
- Assess the model's accuracy and provide a classification report.
credit_default.json: The dataset in JSON format.Fintech_Loan_Performance.ipynb: Jupyter Notebook containing the Python code for the analysis.
I recommend using Visual Studio Code to access the .ipynb files, as it comes equipped with both Jupyter notebooks and a terminal. However, if you prefer using the terminal along with the JupyterLab server, that is also allowed. Please follow the steps below to set up the environment to run the files:
Begin by installing Anaconda (or Miniconda), git.
Next, clone this repository by opening the terminal and typing the following commands (don't type the $ symbol, it just indicates that these are terminal commands):
$ git clone https://github.com/dikhimartin/Fintech-Loan-Performance-Analysis.git
$ cd Fintech-Loan-Performance-Analysis
Then, run the following commands:
$ conda env create -f environment.yml
$ conda activate bol_datascience_course
$ python -m ipykernel install --user --name=bol_datascience_course
If you're not using Visual Studio Code, you need to start Jupyter Lab to open the ipynb notebook.
$ jupyter lab
Note: To activate this environment, use:
$ conda activate bol_datascience_course
To deactivate the active environment, use:
$ conda deactivate
The project involves a comprehensive analysis of customer loan data, including descriptive analysis, statistical tests to identify influential attributes, and the development of a predictive model. The results aim to provide actionable insights for the fintech company to enhance the performance of its loan products.
Feel free to explore the notebook for detailed code implementation and analysis.
Rebekz. (n.d.). GitHub - rebekz/datascience_course: A series of complement resource for data science course. GitHub. https://raw.githubusercontent.com/rebekz/datascience_course/main/data/credit_default.json
#1, D., & Bunyamin, H. (2023). Analisis dan Prediksi Default Kartu Kredit dengan Model Machine Learning (Vol. 5). http://strategi.it.maranatha.edu/index.php/strategi/article/download/445/332
Amhjf. (n.d.). Tutorial: membuat, mengevaluasi, dan menilai model prediksi churn - Microsoft Fabric. Microsoft Learn. https://learn.microsoft.com/id-id/fabric/data-science/customer-churn
Shafi, A. (2023, February 24). Random Forest Classification with Scikit-Learn. https://www.datacamp.com/tutorial/random-forests-classifier-python
Great Learning Team. (2023, May 30). An Introduction to GridSearchCV | What is Grid Search | Great Learning. Great Learning Blog: Free Resources What Matters to Shape Your Career! https://www.mygreatlearning.com/blog/gridsearchcv/
Shah, R. (2023, December 6). Tune Hyperparameters with GridSearchCV. Analytics Vidhya. https://www.analyticsvidhya.com/blog/2021/06/tune-hyperparameters-with-gridsearchcv/