RobinHood is a research caching system for application servers in large web services. A single user request to such an application server results in multiple queries to complex, diverse backend services (databases, recommender systems, ad systems, etc.).
RobinHood dynamically partition the cache space between the different backend services and continuously optimizes the partition sizes.
RobinHood's goal is to
- repartition cache space such as to minimize the request tail latency
- be compatible with off-the-shelf in-memory caches (such as memcached)
- to facilitate research into different resource allocation policies and tail latency
In our experiments (testbed source code in this repo), RobinHood is effective at reducing P99 request latency spikes.

Presentation at USENIX OSDI (includes audio)
Morning Paper Blog Post by Adrian Colyer
Paper (PDF). Cite as:
RobinHood: Tail Latency Aware Caching - Dynamic Reallocation from Cache-Rich to Cache-Poor
Daniel S. Berger, Benjamin Berg, Timothy Zhu, Siddhartha Sen, Mor Harchol-Balter.
USENIX OSDI, October 2018.
To test RobinHood, we built a testbed that emulates a large webservice like xbox.com.
The testbed consists of:
- a request generator (to replay traces of production traffic)
- an application server, which queries backend systems and aggregates the result (key metrics like request latency are measured here)
- several types of backends, which are either I/O bound or CPU bound
- a resource monitor, which runs on every physical server and reports local CPU, network, etc. statistics
- a central statistics server that aggregates measurements and compiles a live view of the system performance (see below)
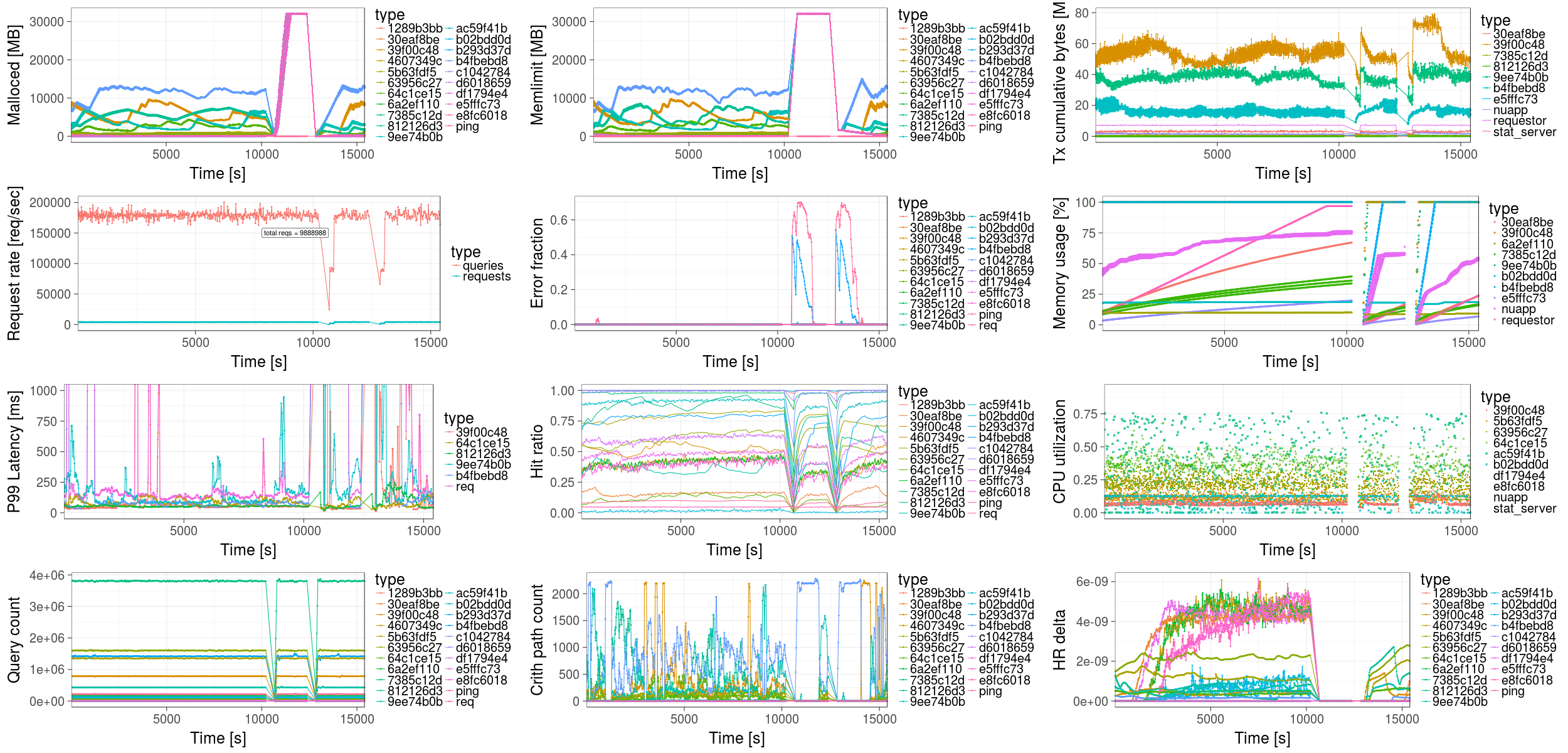
The RobinHood testbed is built on top of Docker Swarm. Each of the components is a separate Docker container. The source code can be found as follows:
- go/src/requestor/: the request generator
- nuapp/src/: the application server, which consists of
- nuapp/src/appserver: the main source code
- nuapp/src/subquery: schedules, tracks, and caches queries to backend servers
- nuapp/src/controller.py: the cache controller which implements RobinHood and several other static and dynamic partitioning policies
- nuapp/src/shadowcache and nuapp/src/statquery: helper libraries to debug the cache state and send information to the stats server
- go/src/mysql_backend: mysql-based I/O-bound database backend
- go/src/fback: source code of a CPU-bound matrix multiplication backend
- monitor/src/monitor: the source code of the resource monitor (integrated with docker)
- go/src/statserver: central statistics server, which keeps the 10 million recent measurements in a ring buffer and calculates key metrics like tail percentiles
To begin, fill in the relevant, testbed-specific information in docker_env.sh . Then type:
source docker_env.sh
./push_images.sh
to compile the testbed and push the images to the specified docker container registry.
A request trace fully describes a sequence of requests, which in themselves consist of queries to backend systems.
In our trace format, a single request is written as a JSON object on a single line. The line includes a time stamp ("t") and a list of the queries ("d"). For a typical fanout, the list has one entry: a dictionary that maps backends to their queries. Backends are identified by a hash, e.g., "b4fbebd8" (backend names correspond to the names of docker swarm services and are resolved automatically inside containers). The backend queries are a dictionary which lists the object sizes ("S"), the hashed object URLs ("U"), and whether the queries are cacheable ("C", 1 means cacheable).
Example trace (longer example and tracegenerator script.
{"t": 0, "d": [{"7385c12d": {"S": [20788], "U": ["8d4d4ec1f020205f3"], "C": [1]}, "b4fbebd8": {"S": [20788, 20881, 398, 25514, 26109], "U": ["48efdeddbe76e5f60", "3430884714871a984", "641d4cc4e0d96de89", "dbe6fc5abbbc078f5", "991459718784f945f"], "C": [1, 1, 1, 1, 1]}, "39f00c48": {"S": [26192, 2414], "U": ["bf2ba48d4c4caa163", "362db55d825e027c2"], "C": [1, 1]}, "b293d37d": {"S": [20884], "U": ["91e4bf1d25652d04b"], "C": [1]}, "812126d3": {"S": [37856, 20705, 424, 34915, 20788], "U": ["f0bd9a2a45492adca", "03eb3847b6c9198d0", "e36470eff6abb2ff2", "c85a93b4541fecf55", "bf2f61f5dfaf86b16"], "C": [1, 1, 1, 1, 1]}}]}
{"t": 0, "d": [{"02129bb8": {"S": [34908], "U": ["dd6bd7c22aa542aeb"], "C": [1]}, "7385c12d": {"S": [37858], "U": ["c142d7ef7415bf3a8"], "C": [1]}, "c1042784": {"S": [37856], "U": ["48dd2200faaaa4a76"], "C": [1]}, "1289b3bb": {"S": [37857], "U": ["427bc1d6a9fe40e0d"], "C": [1]}, "b4fbebd8": {"S": [14060], "U": ["958b74446d06a9d97"], "C": [1]}}]}
{"t": 0, "d": [{"02129bb8": {"S": [34908], "U": ["dd6bd7c22aa542aeb"], "C": [1]}, "7385c12d": {"S": [37858], "U": ["c142d7ef7415bf3a8"], "C": [1]}, "c1042784": {"S": [37856], "U": ["48dd2200faaaa4a76"], "C": [1]}, "1289b3bb": {"S": [37857], "U": ["427bc1d6a9fe40e0d"], "C": [1]}, "b4fbebd8": {"S": [14060], "U": ["958b74446d06a9d97"], "C": [1]}}]}
See docker_env.sh for a description of available parameters.
In addition to these parameters, every deployment uses a set of configs to determine features of the experiment. The default behavior of docker_env.sh is to specify a sample config located here.
To deploy the RobinHood testbed you will need to set up a docker swarm cluster. We used more than 50-100 Azure servers in our experiments, running Ubuntu 17.10 and Docker version 18.03. At least the servers running the backends will need to have a local disk mounted at /ssd. You will also need to set up a Docker container registry. Once all nodes have joined the swarm
- authenticate the swarm manager with the registry
- the swarm manager and every swarm node needs to pull all RobinHood images from your registry (can be automated via docker swarm)
- update the deployment parameters and verify that all containers in the config file (swarm/robinhood-compose.yml) are pulled and ready to go
- the swarm nodes need to be tagged with their roles (i.e., labeled with the type of container that is going to run there)
- finally, you can deploy the docker stack from our compose file
The last two steps are automated by a bash script (swarm/swarm.sh).
We have included a minimial working example that will run a small RobinHood instance locally. This can be helpful for testing and getting a sense of how all the pieces fit together. The first step is to turn your test host into a 1 machine docker swarm by running
docker swarm init
Next, source the included environment for running the local example configuration, as well as utils.sh:
source example_env.sh
source utils.sh
All docker images can be built and accessed locally, so do not be concerned if you do not have a container registry specified. If you have not already done so, make sure you build all the docker images by running:
./push_images.sh
To start the RobinHood example, cd to the swarm directory and run swarm.sh:
cd swarm
./swarm.sh
You should now see the various RobinHood services, as well as 2 backend services, start up. To check the status of the swarm, type:
docker service ls
To get a shell inside any running service, use the docker_ssh function defined in utils.sh as follows:
docker_ssh robinhood_requestor
where robinhood_requestor could be replaced by any service name.
To stop the experiment, run
./stop_swarm.sh
You are welcome to clone this repository and experiment with your own variant of RobinHood. A few pointers for your endeavor.
First, why did we experiment on real servers? We actually tried extensive simulations at first, and found out that it was almost impossible to navigate the huge parameter space. If there is sufficient interest (e.g., in a github issue), we can share the simulator code.
Second, the results in the final paper are based exclusively on the code base in this repo, running on 10s of servers in Azure. As a disclaimer: the deployment to get this all running is somewhat complex. A major fraction of this complexity is due to limitations in Docker Swarm (e.g. container network performance) and memcached (e.g., cache resizing and central mutexes). Anticipate that you will you need to read extensively about these.
Third, for future work, there remain several open questions and loose ends. The discussion section of the RobinHood Paper is a good starting point for these. Additional research time is probably well spent on the infrastructure for a system such as RobinHood, e.g., to make caching systems (such as memcached) better support dynamically resizing of partitions, while receiving high request rates.
This software uses
- Golang
- Memcached
- MySQL
- Our fork of pymemcache
- Several Golang libraries like Go-SQL-Driver and Gomemcache