ATMSeer is an interactive visualization tool for automated machine learning (AutoML). It supports users to monitor an ongoing AutoML process, analyze the searched models, and refine the search space in real-time through a multi-granularity visualization. In this instantiation, we build on top of the ATM AutoML system.
Our paper, "ATMSeer: Increasing Transparency and Controllability in Automated Machine Learning", was presented at CHI 2019 (pdf, site).
{kind=link}
{kind=link}
{kind=link}
Download and install or update VirtualBox and Vagrant.
git clone https://github.com/HDI-Project/ATMSeer.git
Then go to ATMSeer project from the terminal and run
sh install.sh
This will install all the necessary packages in a virtual environment and launch the ATMSeer server.
If you see these messages in terminal:
...
default: [INFO] [13:07:26:werkzeug] * Running on http://0.0.0.0:7777/ (Press CTRL+C to quit)
default: [INFO] [13:07:26:werkzeug] * Restarting with stat
default: [WARNING] [13:07:31:werkzeug] * Debugger is active!
default: [INFO] [13:07:31:werkzeug] * Debugger PIN: 295-249-971
default: No valid rules have been specified for JavaScript files
then ATMSeer is up and running.
Finally, navigate to http://localhost:7779/ in your broswer (preferably Chrome) to see ATMSeer.
In case you experience any issues, please try the following.
- Open a terminal and navigate to ATMSeer project location.
- Run
vagrant upcommand (in case vagrant is not already running). - From the same terminal run
vagrant ssh. - Run
cd /vagrantandsh start.sh.
Open a second terminal and navigate to the ATMSeer project directory.
Run vagrant ssh, cd /vagrant, and npm start.
If you are still experiencing issues, please open an issue and include as much detail as you can on your problem.
To see ATMSeer in action, you will first upload a dataset to use with the AutoML process, create a "datarun", and then monitor and control the ongoing AutoML process.
You first need to upload a dataset to use with the AutoML process. We have provided several example datasets in public/viz. For example, press "Upload" and navigate to your ATMSeer installation and upload public/viz/blood.csv.
To use your own dataset, take care to provide it in the required data format (https://hdi-project.github.io/ATM/readme.html#data-format).
A datarun is a single AutoML process, comprising a dataset, a configuration for the AutoML process, and associated state information.
To create a new datarun, click the add icon, adjust methods, budget type, and budget, and press "Submit". You should not need to adjust advanced settings in most cases. If you do, please see https://hdi-project.github.io/ATM/database.html#dataruns for some details on the setting options.
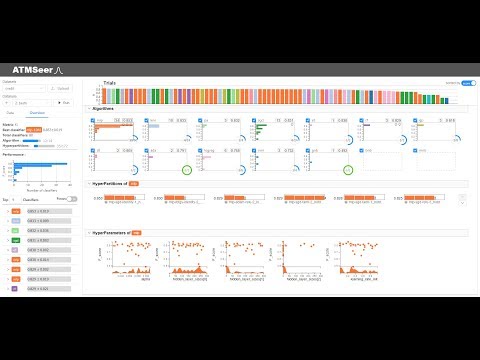
Now, select your datarun from the list and press "Run" to begin the AutoML process. You should see completed trials populate on the top panel and details of algorithms, hyperpartitions, and hyperparameters in the three-level visualization on the right.
If you use ATMSeer, please consider citing our paper:
@inproceedings{wang2019atmseer,
author = {Wang, Qianwen and Ming, Yao and Jin, Zhihua and Shen, Qiaomu and Liu, Dongyu and Smith, Micah J. and Veeramachaneni, Kalyan and Qu, Huamin},
title = {ATMSeer: Increasing Transparency and Controllability in Automated Machine Learning},
booktitle = {Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems},
series = {CHI '19},
year = {2019},
location = {Glasgow, Scotland UK},
publisher = {ACM},
address = {New York, NY, USA},
url = {http://doi.acm.org/10.1145/3290605.3300911}
}