QueryAgent: A Reliable and Efficient Reasoning Framework with Environmental Feedback based Self-Correction
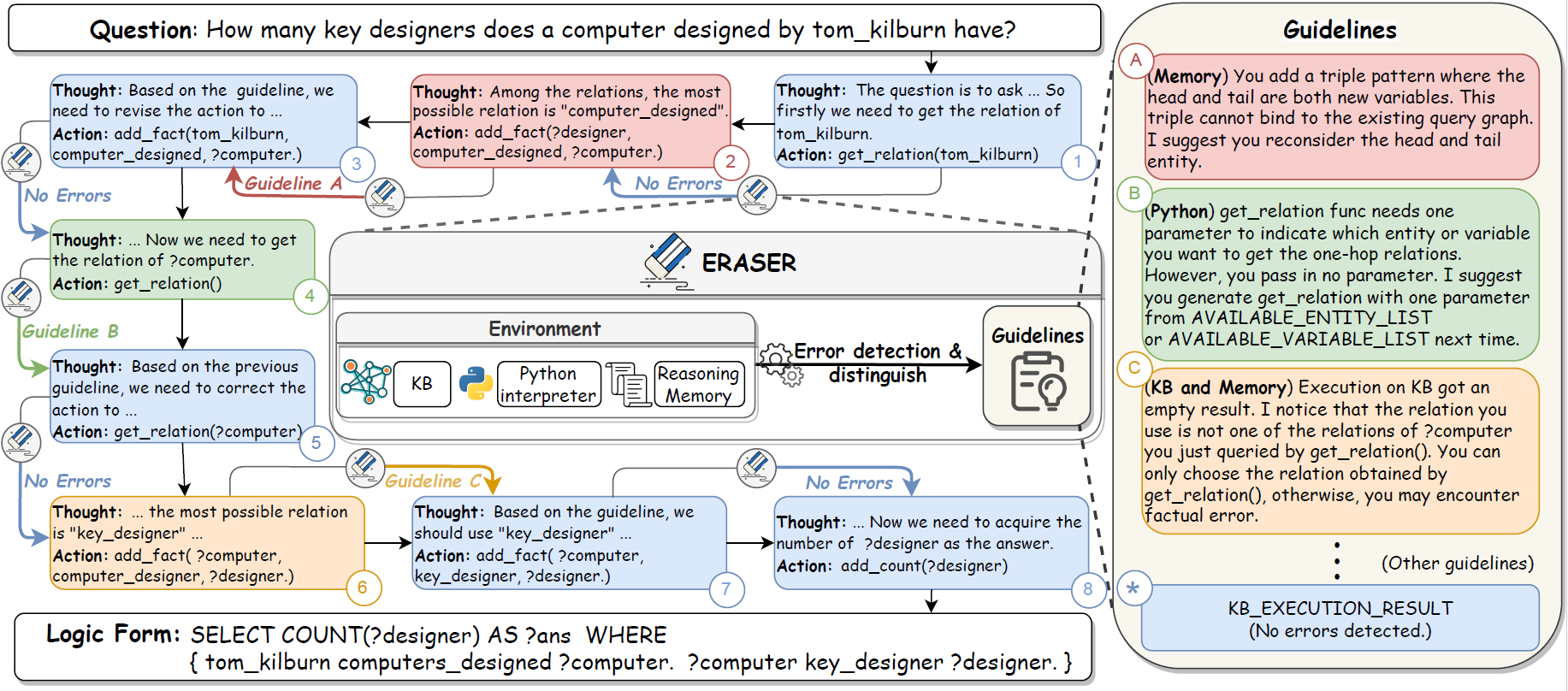
Employing Large Language Models (LLMs) for semantic parsing has achieved remarkable success. However, we find existing methods fall short in terms of reliability and efficiency when hallucinations are encountered. In this paper, we address these challenges with a framework called QueryAgent, which solves a question step-by-step and performs stepwise self-correction. We introduce an environmental feedback-based self-correction method called ERASER. Unlike traditional approaches, ERASER leverages rich environmental feedback in the intermediate steps to perform selective and differentiated self-correction only when necessary. Experimental results demonstrate that QueryAgent notably outperforms all previous few-shot methods using only one example on GrailQA and GraphQ by 7.0 and 15.0 F1. Moreover, our approach exhibits superiority in terms of efficiency, including runtime, query overhead, and API invocation costs. By leveraging ERASER, we further improve another baseline (i.e., AgentBench) by approximately 10 points, revealing the strong transferability of our approach
You can follow this to employee Freebase on your local device:
https://github.com/dki-lab/GrailQA?tab=readme-ov-file#setup
Please remember to modify the SPARQLPATH in ag_src/agent_utils/config to your own endpoint.
Due to some policy restrictions,
we can't open source the openai embedding file(fb_relation_embed.json,grailqa_question_embed.json,graphq_question_embed.json,WebQSP_test_question_embed.json).
You can obtain the embedding yourself based on the code in similarity_search.py->get_openai_embedding.
You need to cache the embedding of all freebase relation (see in data\fb_relation.txt),
and the embedding of all questions.
Make sure the embedding file in a json file(dict), in the format of {question1:emb_ques_1,question2:emb_ques_2,...} and {relation1:emb_rel_1,relation2:emb_rel_2,...}.
An example is : {'base.sa3base.sa3_view.elements_catalog':[-0.00011903620179509744, 0.003563345642760396,...],...}
Please put the embedding file under the data directory.
The cost of this part is very low, less than $1 for all the dataset's relations and questions with the use of cache.
Anyway, If you indeed have any problem in implementing this, please feel free to contact us.
- config the hyper-parameters in
agent_utils/config.py - fill the api-key and the KB query endpoint in
agent_utils/config.py - execute
agent_utils/run_exp.py
QueryAgent/
├── ag_src: source code directory
| ├── agent_utils: some tool functions file
| ├── ag_utils.py: the tool function of Agent framework
| ├── similarity_search.py: the relation ranking module
| ├── run_exp.py: the main function entrance, excute this file to
| └── config.py: the configuration file for experiment
| ├── grail_src: code for GrailQA experiment
| ├── GRAIL.py: the main function of GrailQA experiment
| ├── sparql_generator.py: the PyQL compiler(the action set of QueryAgent) for GrailQA
| └── wikienv.py: the detail function of GrailQA experiment
| ├── graphq_src: code for GraphQ experiment
| └── the file struct of other dataset is similar to grail_src
| ├── webqsp_src: code for WebQSP experiment
| └── meta_src: code for MetaQ experiment
├── data: the dataset for experiment
| ├──GrailQA_v1.0
| ├──GraphQ
| ├──metaQA
| └──WebQSP
@misc{huang2024queryagentreliableefficientreasoning,
title={QueryAgent: A Reliable and Efficient Reasoning Framework with Environmental Feedback-based Self-Correction},
author={Xiang Huang and Sitao Cheng and Shanshan Huang and Jiayu Shen and Yong Xu and Chaoyun Zhang and Yuzhong Qu},
year={2024},
eprint={2403.11886},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2403.11886},
}