| Modelize your interface | Encode the graph | Run the generated machine! |
|---|---|---|
 |
 |
 |


- Features
- Documentation
- Examples
- Tooling
- Motivation
- Install
- Tests
- Integration with UI libraries
- API design
- Visualization tools
- Credits
- Roadmap
- Who else uses state machines
- Annex
This library enables you to implement the behaviour of your user interfaces or components as state machines. The behaviour is the relation between the actions performed on the user interface (button clicks, etc.) and the actions (commands) to perform on the interfaced systems (fetch data, display screens, etc.). You specify the machine as a graph. The library computes a function which implements the state machine which specifies the behaviour. You drive your interface with that function, you display the UI with the UI framework of your choice.
Salient features:
- small size: implementation treeshakeable to 5KB core, compilable to 1KB-2KB
- small API: one function for the state machine 9- just a function!: easy to integrate into any front-end framework
All documentation can be accessed in the dedicated web site.
Kingly has been used to implement large applications such as Conduit, a simplified Medium's clone. On such a large machine, the process has been significantly smoothed by using the free professional graph editor yEd to produce the machine graphs.
In summary, Kingly has the following tools available:
- yEd graph editor (documentation)
- yEd graphs are saved as
.graphmlfiles
- yEd graphs are saved as
- yed2kingly converter (documentation)
- the converter enables the conversion of
.graphmlfiles to Kingly state machines
- the converter enables the conversion of
- compiler (documentation)
- the compiler compiles a
.graphmlfile into small, plain, zero-dependency JavaScript which implements the logic expressed in the graph
- the compiler compiles a
- devtool (devtool)
- traces a Kingly machine computation. The devtool is of invaluable help while testing and debugging.
{kind=link}
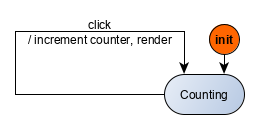
You can review the following examples which have been implemented with the same state machine, across different UI frameworks, with links to the corresponding codesandboxes. Note that the examples may use older versions of Kingly.
| State Machine | Demo | UI library |
|---|---|---|
 |
 |
Vanilla JS |
| State Machine | Demo | UI library |
|---|---|---|
|
 |
Vanilla js Nanomorph Vue |
| State Machine | Demo | UI library |
|---|---|---|
 |
 |
Vue React Ivi Inferno Nerv Svelte |
| State Machine | Demo | UI library |
|---|---|---|
 |
 |
Cycle JS |
This library fundamentally implements computations which can be modelized by a type of state machines called hierarchical extended state transducer. This library offers a way to define, and use such transducers.
The major motivation for this library is the specification and implementation of user interfaces. As a matter of fact, to every user interface can be associated a computation relating inputs to the user interface to an action to be performed on the interfaced systems. That computation often has a logic organized around a limited set of control states, and can be advantageously modelized by a state machine.
This library was born in early 2016 from:
- the absence of existing javascript libraries which satisfy our design criteria
- mostly, we want the state machine library API design to be as close as possible from the mathematical object denoting it. This should allow us to reason about it, compose and reuse it easily.
- most libraries we found either do not feature hierarchy in their state machines, or use a rather imperative API, or impose a concurrency model on top of the state machine's control flow
In the four years of existence and use of this library, we reached an API which should be fairly stable. It has been used succesfully for user-interfaces as well as in other contexts:
- in multi-steps workflows: see an example here, a constant feature of enterprise software today
- for 'smart' synchronous streams, which tracks computation state to avoid useless re-computations
- to implement cross-domain communication protocols, to coordinate iframes with a main window
In such cases, we were able to modelize our computation with an Extended Hierarchical State Transducer in a way that:
- is economical (complexity of the transducer proportional to complexity of the computation)
- is reasonably easy to reason about and communicate (the transducer can be visually represented)
- supports step-wise refinement and iterative development (control states can be refined into a hierarchy of nested states)
npm install kingly --save
To run the current automated tests: npm run test
The machine implementation is just a function. As such it is pretty easy to integrate in any framework. In fact, we have implemented the same interface behaviour over React, Vue, Svelte, Inferno, Nerv, Ivi with the exact same fsm. By isolating your component behaviour in a fsm, you can delay the UI library choice to the last moment.
The key objectives for the API was:
- generality, reusability and simplicity
- there is no explicit provision made to accommodate specific use cases or frameworks
- it must be possible to add a concurrency and/or communication mechanism on top of the current design
- it must be possible to integrate smoothly into React, Angular and your popular framework
- support for both interactive and reactive programming
- parallel and sequential composability of state machines
As a result of this, the following choices were made:
- functional interface: the Kingly state machine is just a function. As such, the machine is a black-box, and only its outputs can be observed
- complete encapsulation of the state of the machine
- no effects performed by the machine
- no exit and entry actions, or activities as in other state machine formalisms
- there is no loss of generality as both entry and exit actions can be implemented with our state machine. There is simply no syntactic support for it in the core API. This can however be provided through standard functional programming patterns (higher-order functions, etc.)
- every computation performed is synchronous (asynchrony is an effect)
- action factories return the updates to the extended state to avoid any
unwanted direct modification of the extended state (API user must provide such update function,
which in turn allows him to use any formalism to represent state - for instance
immutable.js) - no restriction is made on output of state machines, but inputs must follow some conventions (if a machine's output match those conventions, two such machines can be sequentially composed
- parallel composition naturally occurs by feeding two state machines the same input(s))
- as a result, reactive programming is naturally enabled. If
inputsis a stream of well-formatted machine inputs, andfis the fsm, then the stream of outputs will beinputs.map (f). It is so simple that we do not even surface it at the API level.
- as a result, reactive programming is naturally enabled. If
Concretely, our state machine will be created by the factory function createStateMachine, which returns a state machine which:
- immediately positions itself in its configured initial state (as defined by its initial control state and initial extended state)
- will compute an output for any input that is sent to it since that
Let us insist again on the fact that the state machine is not, in general, a pure function of its inputs. However, a given output of the machine depends exclusively on the sequence of inputs it has received so far (causality property). This means that it is possible to associate to a state machine another function which takes a sequence of inputs into a sequence of outputs, in a way that that function is pure. This is what enables simple and automated testing.
We have included two helpers for visualization of the state machine:
- conversion to plantUML:
toPlantUml :: FSM_Def -> PlantUml- the resulting chain of characters can be pasted in plantText or plantUML previewer to get an automated graph representation. Both will produce the exact same visual representation
- conversion to online visualizer format (dagre layout engine): for instructions, cf. github directory:
toDagreVisualizerFormat :: FSM_Def -> JSON

Automated visualization works well with simple graphs, but seems to encounter trouble to generate optimally satisfying complex graphs. The Dagre layout seems to be a least worse option. I believe the best option for visualization is to use professional specialized tooling such as yed. We provide a CLI for conversion to yed graph format to facilitate such workflow (cf. yed2Kingly). The yed's orthogonal and flowchart layout seem to give pretty good results.
- Credit to Pankaj Parashar for the password selector
- Credit to Sari Marton for the original version of the movie search app
- stabilise core API
- state machine as an effectless, impure function with causality properties
- expose only the factory, keep internal state fully encapsulated
- test integration with React
- test integration with Vue
- support model-based testing, and test input generation
- all-paths coverage test case generator
[x] add tracing supportobtained by decorating the machine definition
[x] add entry actions[ ] babel macro for converting yed graphml and yakindu sct files[ ] babel macro to compile away the machine library to reduce bundle size- add support for yEd (professional graph editor)
- dev tool (including documentation)
- compiler (including documentation)
- decide definitively on tricky semantic cases
- transitionning to history states when there is no history
- Qt: use the initial control state for the compound state in that case
- cf. https://www.state-machine.com/qm/sm_hist.html
event delegation
- transitionning to history states when there is no history
- support for live, interactive debugging
- render time machine
- add cloning API (useful for testing, to avoid replaying all machine inputs to get it back to a given state)
- add reset API
- document serialization support (already implemented in core, to implement in compiler too. Cf. #8)
- compiler should generate code optimized for debugging or size (not for speed, I don't believe there is much to gain there). Configurable via flags. Right now it is something in the middle.
- finalize, document and release testing API
- turn the test generation into an iterator(ES6 generator): this allows it to be composed with transducers and manipulate the test cases one by one as soon as they are produced. Will be useful for both example-based and property-based testing. When the generators runs through thousands of test cases, we often have to wait a long time before seeing any result, which is pretty damageable when a failure is located toward the ends of the generated input sequences.
- add other searches that DFS, BFS (add probability to transitions, exclude some transitions, etc.). HINT:
store.pickOnecan be used to select the next transition- pick a random transition
- pick next transition according to ranking (probability-based, prefix-based or else)
The use of state machines is not unusual for safety-critical software for embedded systems. Nearly all safety-critical code on the Airbus A380 is implemented with a suite of tools which produces state machines both as specification and implementation target. The driver here is two-fold. On the one hand is productivity: writing highly reliable code by hand can be done but it is painstakingly slow, while state machines allow to generate the code automatically. On the other hand is reliability. Quoting Gerard Berry, founder of Esterel technologies, << low-level programming techniques will not remain acceptable for large safety-critical programs, since they make behavior understanding and analysis almost impracticable >>, in a harsh regulatory context which may require that every single system requirement be traced to the code that implements it (!). Requirements modeled by state-machines are amenable to formal verification and validation.
State machines have also been used extensively in games of reasonable complexity, and tutorials abound on the subject. Fu and Houlette, in AI Game Programming Wisdom 2 summarized the rationale: "Behavior modeling techniques based on state-machines are very popular in the gaming industry because they are easy to implement, computationally efficient, an intuitive representation of behavior, accessible to subject matter experts in addition to programmers, relatively easy to maintain, and can be developed in a number of commercial integrated development environments".
More prosaically, did you know that ES6 generators compile down to ES5 state machines where no native option is available? Facebook's regenerator is a good example of such.
So state machines are nothing like a new, experimental tool, but rather one with a fairly extended and proven track in both industrial and consumer applications.
We call this library "Kingly" to express it allows developers to rule their UI -- like a king. Developers define rules in the machine, in the form of control states and guards, those rules define what is possible and what is not, and what should happen in response to events.
And also, the other names I wanted were already taken :-).
This library is old and went through several redesigns and a large refactoring as I grew as a programmer and accumulated experience using it. I actually started after toiling with the cyclejs framework and complex state orchestration. I was not an expert in functional programming, and the original design was quite tangled (streams, asynchrony, etc.) and hardly reusable out of cyclejs. The current design resulting from my increased understanding and awareness of architecture, and functional design.
The key influences I want to quote thus are:
- cyclejs, but of course, from which I started to understand the benefits of the separation of effects from logic
- elm - who led me to the equational thinking behind Kingly
- erlang - for forcing me to learn much more about concurrency.
Not like it matters so much but anyways. Feel free to skip that section if you have little interest in computer science.
Alright, let's build the concept progressively.
An automaton is a construct made of states designed to determine if a sequence of inputs should be accepted or rejected. It looks a lot like a basic board game where each space on the board represents a state. Each state has information about what to do when an input is received by the machine (again, rather like what to do when you land on the Jail spot in a popular board game). As the machine receives a new input, it looks at the state and picks a new spot based on the information on what to do when it receives that input at that state. When there are no more inputs, the automaton stops and the space it is on when it completes determines whether the automaton accepts or rejects that particular set of inputs.
State machines and automata are essentially interchangeable terms. Automata is the favored term when connoting automata theory, while state machines is more often used in the context of the actual or practical usage of automata.
An extended state machine is a state machine endowed with a set of variables, predicates (guards) and instructions governing the update of the mentioned set of variables. To any extended state machines it corresponds a standard state machine (albeit often one with a far greater number of states) with the same semantics.
A hierarchical state machine is a state machine whose states can be themselves state machines. Thus instead of having a set of states as in standard state machines, we have a hierarchy (tree) of states describing the system under study.
A state transducer is a state machine, which in addition to accepting inputs, and modifying its state accordingly, may also generate outputs.
We propose here a library dealing with extended hierarchical state transducers, i.e. a state machine whose states can be other state machines (hierarchical part), which (may) associate an output to an input (transducer part), and whose input/output relation follows a logic guided by predefined control states (state machine part), and an encapsulated memory which can be modified through actions guarded by predicates (extended part).
Note that if we add concurrency and messaging to extended hierarchical state transducers, we get a statechart. We made the design decision to remain at the present level, and not to incorporate any concurrency mechanism.1
- statecharts include activities and actions which may produce effects, and concurrency. We are seeking an purely computational approach (i.e effect-less) to facilitate composition, reuse and testing.
- In the absence of concurrency (i.e. absence of parallel regions), a statechart can be turned into a hierarchical state transducer. That is often enough!
- there is no difference in terms of expressive power between statecharts and hierarchical transducers2, just as there is no difference in expressive power between extended state machines and regular state machines. The difference lies in naturalness and convenience: a 5-state extended state machine is easier to read and maintain than the equivalent 50-state regular state machine.
- we argue that convenience here is on the side of being able to freely plug in any concurrent or communication model fitting the problem space. In highly concurrent systems, programmers may have it hard to elaborate a mental model of the statecharts solely from the visualization of concurrent statecharts.
- some statecharts practitioners favor having separate state charts communicating3 in an ad-hoc way rather than an integrated statechart model where concurrent state charts are gathered in nested states of a single statechart. We agree.
Footnotes
-
Our rationale is as follows: ↩
-
David Harel, Statecharts.History.CACM: Speaking in the strict mathematical sense of power of expression, hierarchy and orthogonality are but helpful abbreviations and can be eliminated ↩
-
David Harel, Statecharts.History.CACM: <<I definitely do not recommend having a single statechart for an entire system. (...) concurrency occurs on a higher level.)>> ↩