This challenge is a continuous control problem where the agent must reach a moving ball with a double jointed arm. A reward of +0.1 is provided for each time step that the arm is in the goal position thus incentivizing the agent to be in contact with the ball. The observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector should be a number between -1 and 1. For the purpose of this project, a single agent is trained to perform this activity to achieve an average score of +30 from over 100 consecutive episodes.

The steps below will describe how to get this running on MacOS:
$ git clone https://github.com/aweeraman/reinforcement-learning-continuous-control.git
Using the Anaconda distribution, create a new python runtime and install the required dependencies:
$ conda create -n rl python=3.6
$ source activate rl
$ pip install -r requirements.txt
Download a pre-built environment to run the agent. You will not need to install Unity for this. The environment is OS specific, so the correct version for the operating system must be downloaded.
For MacOS, use this link
After uncompressing, there should be a directory called "Reacher.app" in the root directory of the repository.
To train the agent, execute the following:
$ python train.py --run
To run the trained agent in a multi-agent environment, download and extract the multi-agent version of the of the environment from the link below:
For MacOS, use this link
and run:
$ python reacher.py
For this project, the Deep Deterministic Policy Gradient (DDPG) algorithm was used to train the agent.
Deep Deterministic Policy Gradient (DDPG) is an algorithm which concurrently learns a Q-function and a policy. It uses off-policy data and the Bellman equation to learn the Q-function, and uses the Q-function to learn the policy.
This approach is closely connected to Q-learning, and is motivated the same way.
Some characteristics of DDPG:
- DDPG is an off-policy algorithm.
- DDPG can only be used for environments with continuous action spaces.
- DDPG can be thought of as being deep Q-learning for continuous action spaces.
The model architectures for the two neural networks used for the Actor and Critic are as follows:
Actor:
- Fully connected layer 1: Input 33 (state space), Output 128, RELU activation, Batch Normalization
- Fully connected layer 2: Input 128, Output 128, RELU activation
- Fully connected layer 3: Input 128, Output 4 (action space), TANH activation
Critic:
- Fully connected layer 1: Input 33 (state space), Output 128, RELU activation, Batch Normalization
- Fully connected layer 2: Input 128, Output 128, RELU activation
- Fully connected layer 3: Input 128, Output 1
BUFFER_SIZE = int(1e6) # replay buffer size
BATCH_SIZE = 128 # minibatch size
GAMMA = 0.99 # discount factor
TAU = 1e-3 # for soft update of target parameters
LR_ACTOR = 1e-4 # learning rate of the actor
LR_CRITIC = 1e-4 # learning rate of the critic
WEIGHT_DECAY = 0.0 # L2 weight decay
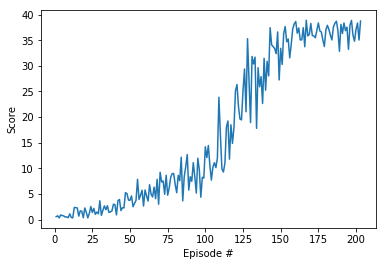
Below is a training run of the above model archicture and hyperparameters:
- Number of agents: 1
- Size of each action: 4
- Environment solved in 103 episodes! Average Score: 30.21
- Training of multiple agents to perform the activity in parallel
- Explore distributed training using
- A3C - Asynchronous Advantage Actor-Critic
- A2C - Advantage Actor Critic
If you run into an error such as the following when training the agent:
ImportError: Python is not installed as a framework. The Mac OS X backend will not be able to function correctly if Python is not installed as a framework. See the Python documentation for more information on installing Python as a framework on Mac OS X. Please either reinstall Python as a framework, or try one of the other backends. If you are using (Ana)Conda please install python.app and replace the use of 'python' with 'pythonw'. See 'Working with Matplotlib on OSX' in the Matplotlib FAQ for more information.
Modify ~/.matplotlib/matplotlibrc and add the following line:
backend: TkAgg
1 - https://spinningup.openai.com/en/latest/algorithms/ddpg.html