
Evaluate And Optimize An Existing Open-Source Speech-To-Text Transcription Tool For Accurately Converting Feedback Calls Related To Citizen Grievances Into English Text. The Goal Is To Benchmark The Tool's Performance And Implement Enhancements To Achieve Measurable Improvements In Transcription Accuracy For Calls In Hindi, English, And Hinglish. This Project Does Not Involve Creating A New System But Rather Focuses On Refining An Already Established Open-Source Solution.
- ATHRVA DESHMUKH (Athrva Deshmukh)
- GOURAV KUSHWAHA ((GOURAV KUSHWAHA)
- UJJWAL GUPTA (Ujjwal Gupta)
- SONU KUSHWAHA (Sonu Kushwaha)
darpg_1146.1.mp4
Online Hackathon on Data-driven Innovation for Citizen Grievance Redressal organized by the Department of Administrative Reforms & Public Grievances (DARPG) of the Ministry of Personnel, Public Grievances & Pensions.
Zero AI Speech-to-Text Transcription



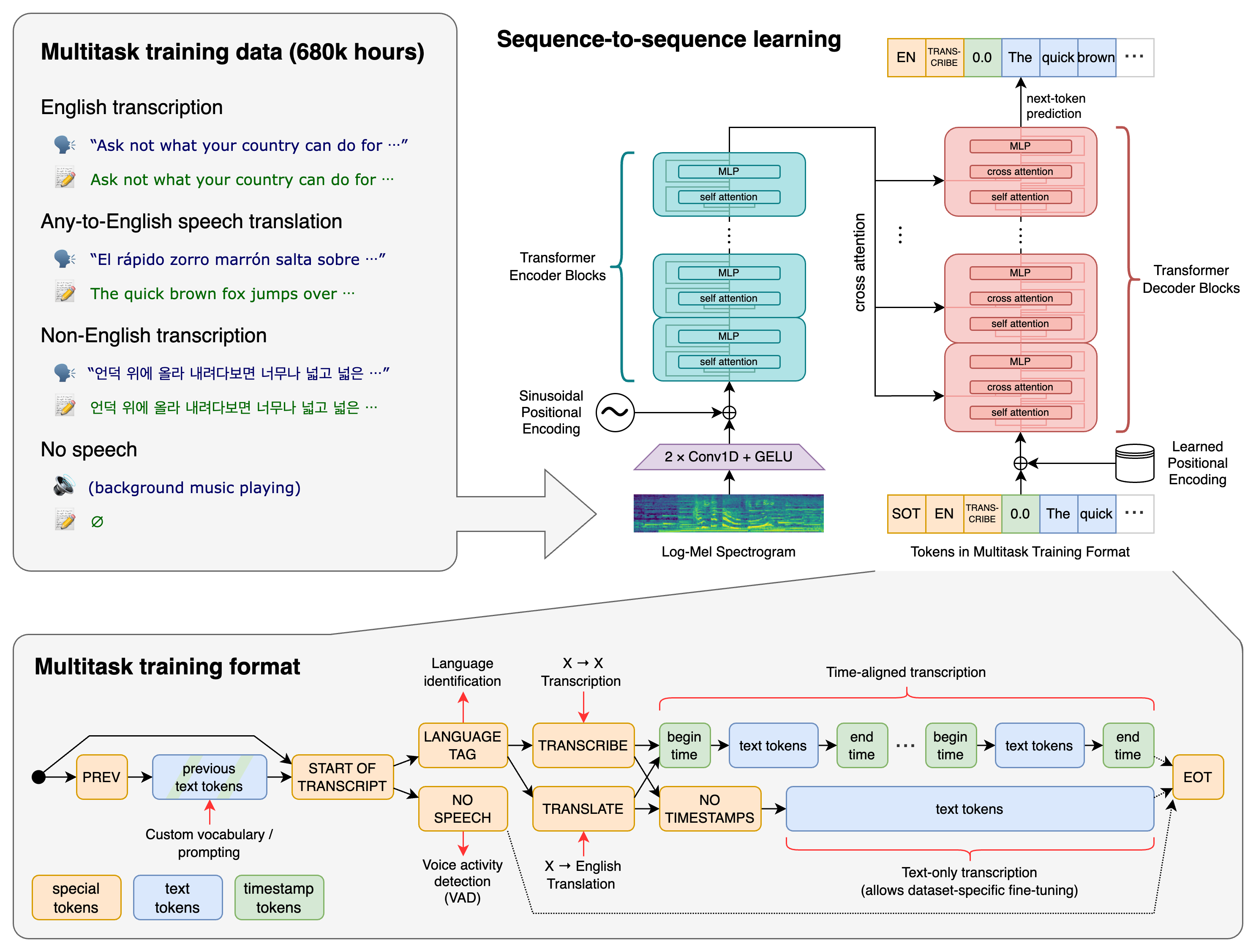
The project aims to evaluate and optimize an existing open-source speech-to-text transcription tool for accurately converting feedback calls related to citizen grievances into English text. The tool under consideration is ZeroAI.py, which utilizes the Whisper library for transcription tasks. The primary objective is to benchmark the tool's performance and implement enhancements to achieve measurable improvements in transcription accuracy for calls in Hindi, English, and Hinglish. The project does not entail creating a new system but rather focuses on refining an already established open-source solution.
The objective of this project is to evaluate and optimize the open-source speech-to-text transcription tool, Whisper, for accurately converting feedback calls related to citizen grievances into English text. The project aims to benchmark the tool’s performance and implement enhancements to achieve measurable improvements in transcription accuracy for calls in Hindi, English, and Hinglish. Rather than creating a new system, the focus is on refining the already established open-source solution provided by Whisper. The proliferation of citizen feedback mechanisms necessitates efficient handling and processing of various communication channels, including voice calls. In contexts where feedback is provided in multilingual formats such as Hindi, English, and Hinglish, automated transcription tools play a crucial role in extracting actionable insights from diverse data sources. This project addresses the optimization of an existing speech-to-text transcription tool to enhance its accuracy and usability in handling feedback calls related to citizen grievances.
- Evaluate the current performance of the open-source speech-to-text transcription tool.
- Identify key areas for improvement in transcription accuracy, particularly for calls in Hindi, English, and Hinglish.
- Implement enhancements and optimizations to the existing tool to achieve measurable improvements.
- Benchmark the performance of the optimized tool against the baseline.
- Provide recommendations for future enhancements and usage scenarios.
Whisper is a general-purpose speech recognition model developed by OpenAI. It is a Transformer sequence-to-sequence model trained on a large dataset of diverse audio. The model is designed to perform multilingual speech recognition, speech translation, spoken language identification, and voice activity detection.
Whisper utilizes a Transformer sequence-to-sequence model trained on various speech processing tasks. These tasks are jointly represented as a sequence of tokens to be predicted by the decoder, enabling a single model to replace many stages of a traditional speech-processing pipeline. The multitask training format employs special tokens that serve as task specifiers or classification targets.
- Python 3.8-3.11
- PyTorch 1.10.1
- ffmpeg
- rust (if required)
The Whisper package can be installed via pip using the following commands:
- Bash:
pip install -U openai-whisper - Windows:
pip install git+https://github.com/openai/whisper.git - Additional dependencies such as ffmpeg and rust may need to be installed based on the system requirements.
- To install all dependencies
pip install -r requirements.txt
Whisper provides several model sizes optimized for different applications and languages. The table below summarizes the available models along with their specifications:
| Size | Parameters | English-only model | Multilingual model | Required VRAM | Relative speed |
|---|---|---|---|---|---|
| tiny | 39 M | tiny.en | tiny | ~1 GB | ~32x |
| base | 74 M | base.en | base | ~1 GB | ~16x |
| small | 244 M | small.en | small | ~2 GB | ~6x |
| medium | 769 M | medium.en | medium | ~5 GB | ~2x |
| large | 1550 M | N/A | large | ~10 GB | 1x |
The performance of Whisper varies based on the language and model size. The .en models are optimized for English-only applications and tend to perform better, especially for smaller models.

Whisper can be used both from the command line and within Python scripts for transcription tasks. The command-line usage allows for transcribing speech in audio files, while Python usage provides more flexibility for integration and customization.
- Bash:
whisper audio.flac audio.mp3 audio.wav --model medium
import whisper
model = whisper.load_model("base")
result = model.transcribe("audio.mp3")
print(result["text"])The Python API enables users to transcribe audio files and provides access to lower-level functionalities for language detection and decoding.
Before proceeding with optimization efforts, it's essential to evaluate the current performance of Whisper on feedback calls related to citizen grievances. The evaluation phase involves several key steps:
- Data Collection
- Annotation
- Evaluation Metrics
- Test Set Preparation
- Baseline Performance
- Error Analysis
To validate the effectiveness of the optimization strategies, a series of controlled experiments should be conducted:
- Experimental Setup
- Hyperparameter Tuning
- Cross-Validation
- Statistical Significance Testing
- Qualitative Analysis
To optimize Whisper for accurately transcribing feedback calls related to citizen grievances, the following strategies can be considered:
- Fine-tuning
- Language-specific Models
- Data Augmentation
- Model Ensemble
- Language Model Integration
- Speaker Adaptation
- Domain Adaptation
- Multimodal Fusion
- Model Ensemble and Fusion
Incorporating mechanisms for continuous improvement and lifelong learning is essential to ensure that Whisper remains relevant, reliable, and effective over time:
- Model Retraining and Update Policies
- Active Learning and Human-in-the-Loop
- Automatic Model Versioning and Rollback
- Benchmarking and Comparative Evaluation
- Experimentation and Innovation
- User Feedback Mechanisms
- Cross-Disciplinary Collaboration
- Community Engagement and Participation
Adopting principles of responsible use and ethical governance is paramount to ensure that Whisper's capabilities are harnessed for positive social impact and ethical outcomes:
- Ethical Use Policies and Guidelines
- Fairness and Equity Considerations
- Privacy and Data Protection
- Algorithmic Accountability and Transparency
- Ethical Review and Oversight
- Community Engagement and Stakeholder Dialogue
- Continuous Education and Awareness
def main():
# Evaluate current performance
evaluate_performance()
# Optimize the transcription tool
optimize_transcription_tool()
# Validate optimization strategies
validate_strategies()
# Ensure responsible use and ethical governance
ensure_responsible_use()
if __name__ == "__main__":
main()The optimization of Whisper for accurately transcribing feedback calls related to citizen grievances represents a significant opportunity to enhance the efficiency and effectiveness of public service delivery mechanisms. By leveraging state-of-the-art speech recognition technologies and adopting a data-driven approach, it is possible to achieve measurable improvements in transcription accuracy and usability. The success of this project depends on collaboration, innovation, and a shared commitment to excellence in citizen-centric governance.
We would like to express our sincere gratitude to the Department of Administrative Reforms & Public Grievances (DARPG) for organizing the hackathon and providing us with this opportunity to contribute to the advancement of citizen-centric governance. We are also thankful to our mentors, colleagues, and fellow participants for their guidance, support, and inspiration throughout the course of this project.
- Whisper Documentation: https://github.com/openai/whisper
- OpenAI: https://openai.com
- Department of Administrative Reforms & Public Grievances (DARPG): https://darpg.gov.in
This project is licensed under the MIT License - see the LICENSE file for details.
