feat(parser): Stream tokens from the lexer #115
Conversation
|
thanks for this @Geal ! I will take a look and review early next week. |
2894c2f to
bc1dfc4
Compare
There was a problem hiding this comment.
Thanks for all the diagnostics!
I really like the idea of a streaming lexer, so I am keen on getting this in.
First I'd like to tighten the implementation a bit, though. Since we are already going for a streaming implementation, we should have the Lexer take a Read and output a Write.
I also think the Lexer is becoming a bit bulky. There is now a LexerIterator, LexerResult and a Cursor. I'd like to see if we can simplify this a bit and make it more readable. Using Read and Write directly is likely going to help with this.
I would also like to see if the parser "navigation" functions, i.e. peek_token, peek_n, pop can be simplified a bit. I think the iteration can be done outside of the individual functions, e.g. parser.parse().
| self.errors.as_slice() | ||
| } | ||
| } | ||
|
|
||
| #[derive(Clone, Debug)] | ||
| pub struct LexerIterator<'a> { |
There was a problem hiding this comment.
Since we are taking the streaming route, I think we should go all the way and have the Lexer take a Read and output a Write, the way a through stream would.
There was a problem hiding this comment.
why a Write? The output is not meant to be written to a byte buffer, it produces tokens to be consumed by the parser.
For Read, it is a bit tricky, because the next step in optimizing things would be to produce tokens that reference input data instead of copying it, so we quickly get into issues like trying to refill the buffer while we still hold some tokens.
Can we assume that the input data will always fit into memory? Are you planning for other input types (like ropes structures, that would make sense for editors)?
I think I can replace the |
bc1dfc4 to
060be55
Compare
|
rebased over main |
I'm looking at it, there are ways to simplify them. I'm not sure iterating should be done outside though, since we'd lose the benefit of streaming: iteration is driven by the needs of the tree builder |
| let token = self | ||
| .tokens | ||
| .pop() | ||
| .expect("Could not eat a token from the AST"); |
There was a problem hiding this comment.
I kept that possible panic, but is it really ok? There might be case where it is triggered. I'll test that through fuzzing
Make the Lexer type public to access it from the benchmarks
Thanks to the peek_* helper methods, this does not change the parser radically, just the way we go through the tokens
this is currently twice as slow as accumulating all tokens then parsing, because we regularly call the peek_* methods. They're basically free if we accumulate in advance the tokens, but in streaming we are recalculating them all the time
the parser is frequently looking at the next token to make a decision. When we stored the list of tokens, that operation was essentially free, but in streaming, we end up reparsing the next token multiple times. By storing it in advance, we avoid that cost
2770b5f to
a9d3277
Compare
|
So I made the iterator the main lexer API now and added a For the Parser I think we can keep the lifetime for now, as the typical use case is to do: let parser = Parser::new(source);
let tree = parser.parse();And then you just use the When we add reparsing we can reconsider that, I think the API (from an ownership view, not the exact parameters) would roughly be this: let mut parser = Parser::new(source); // ← already does the parse
let ast = parser.ast(); // get the already-parsed AST
parser.reparse(new_source);
|
Co-authored-by: Iryna Shestak <[email protected]>
|
awesome! |
this is an exploration of streaming the lexer. The current parser first allocates the list of tokens, then reverses it, then transforms to a syntax tree.
With the benchmark I added, on current main ( 6e8e8a8 ) we're at:
Here's the flamegraph when parsing the supergraph:
We can see that a large part of the time is spent in allocations in the lexing phase.
In 57647fe we see that we can avoid reversing by replacing the token Vec with a VecDeque (I think the errors will be generated in the wrong order here though).
Then we can remove that vec entirely in 81f94f4 by transforming the Lexer into an iterator of Token or Error. The interesting thing here is that it's actually slower:
We can see in the global graph that we removed all allocations in the lexer:
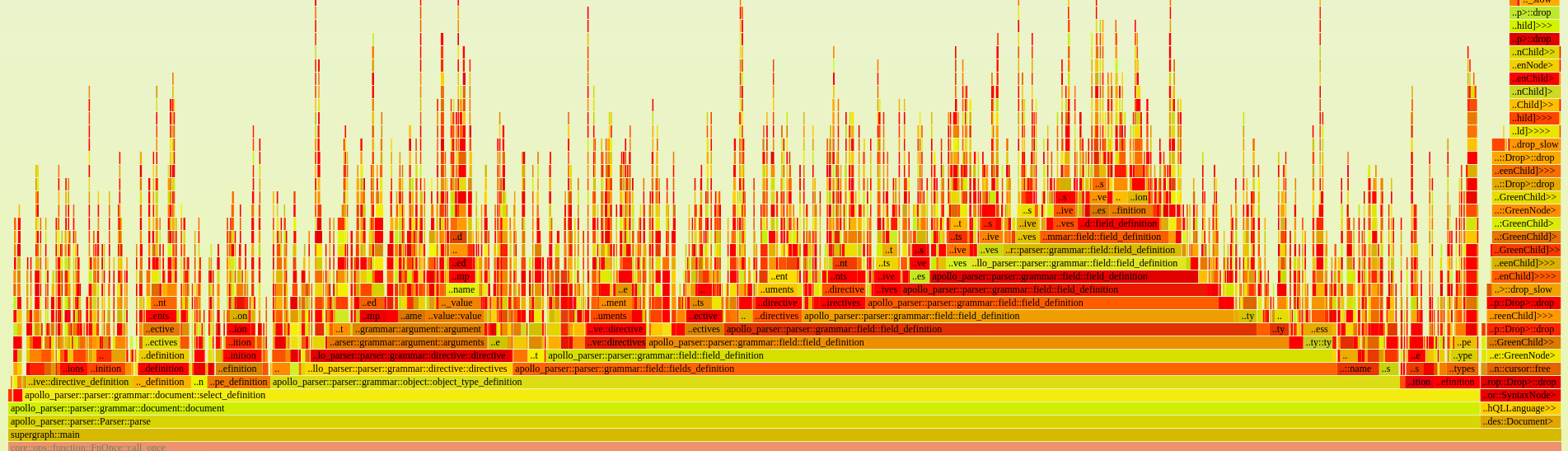
But if we zoom in, we see that the peek function is called very often:
The parser is calling that function regularly to make a decision when parsing the rest of the input. When tokens were preallocated, looking at the next one was nearly free but now we're reparsing it often.
So in e743184 we will store in
Parserthe next token when it is requested, to avoid reparsing it. The cost for that is fixed, it's only enough memory for one token, and we get better performance:The graphs get smaller and we don't call peek as often.
To sump up: less allocations, between 20 and 30% improvement, no change in the syntax tree creation code, I feel good about that :)