[SPARK-26109][WebUI]Duration in the task summary metrics table and the task table are different #23081
Conversation
|
Test build #98984 has finished for PR 23081 at commit
|
|
retest this please |
|
Jenkins, retest this please |
|
Test build #98998 has finished for PR 23081 at commit
|
|
retest this please |
|
Test build #99024 has finished for PR 23081 at commit
|
97bd213 to
a903b40
Compare
a903b40 to
b9a06a9
Compare
There was a problem hiding this comment.
Oh that's good, I think I had noticed the inconsistency and always wondered why. I looked back even to Spark 2.0 and looks like it has been inconsistent since at least then? that is, it doesn't seem like this was an intentional change that was only partly finished. So, looks good.
|
Thank you @srowen . Till Spark2.2, duration (which was 'executorRunTime') in the task table and the summary table were consistent. Apart from the duration, all the metrics in the task table and the summary table are consistent. |
|
Test build #99052 has finished for PR 23081 at commit
|
|
retest this please. |
|
Seems random failure, unrelated to the PR. |
| @@ -996,7 +996,7 @@ private[ui] object ApiHelper { | |||
| HEADER_EXECUTOR -> TaskIndexNames.EXECUTOR, | |||
| HEADER_HOST -> TaskIndexNames.HOST, | |||
| HEADER_LAUNCH_TIME -> TaskIndexNames.LAUNCH_TIME, | |||
| HEADER_DURATION -> TaskIndexNames.DURATION, | |||
| HEADER_DURATION -> TaskIndexNames.EXEC_RUN_TIME, | |||
There was a problem hiding this comment.
Nit: add comment to explain why it should be executor run time here
There was a problem hiding this comment.
Not big deal but there are two spaces after SPARK-26109:
a58da39 to
99b9135
Compare
|
Thank you @gengliangwang |
|
Test build #99053 has finished for PR 23081 at commit
|
|
Test build #99062 has finished for PR 23081 at commit
|
|
It is also a random failure. |
|
Test build #99064 has finished for PR 23081 at commit
|
|
again, failure unrelated to the PR. |
|
Test build #99066 has finished for PR 23081 at commit
|
|
retest this please |
|
Jenkins, add to whitelist |
|
Test build #4435 has finished for PR 23081 at commit
|
|
Test build #99074 has finished for PR 23081 at commit
|
|
Test build #99075 has finished for PR 23081 at commit
|
|
Test build #4436 has finished for PR 23081 at commit
|
…he task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes #23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]>
{kind=link}
{kind=link}
…he task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes #23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]>
|
Merged to master/2.4/2.3 |
|
Thank you @srowen |
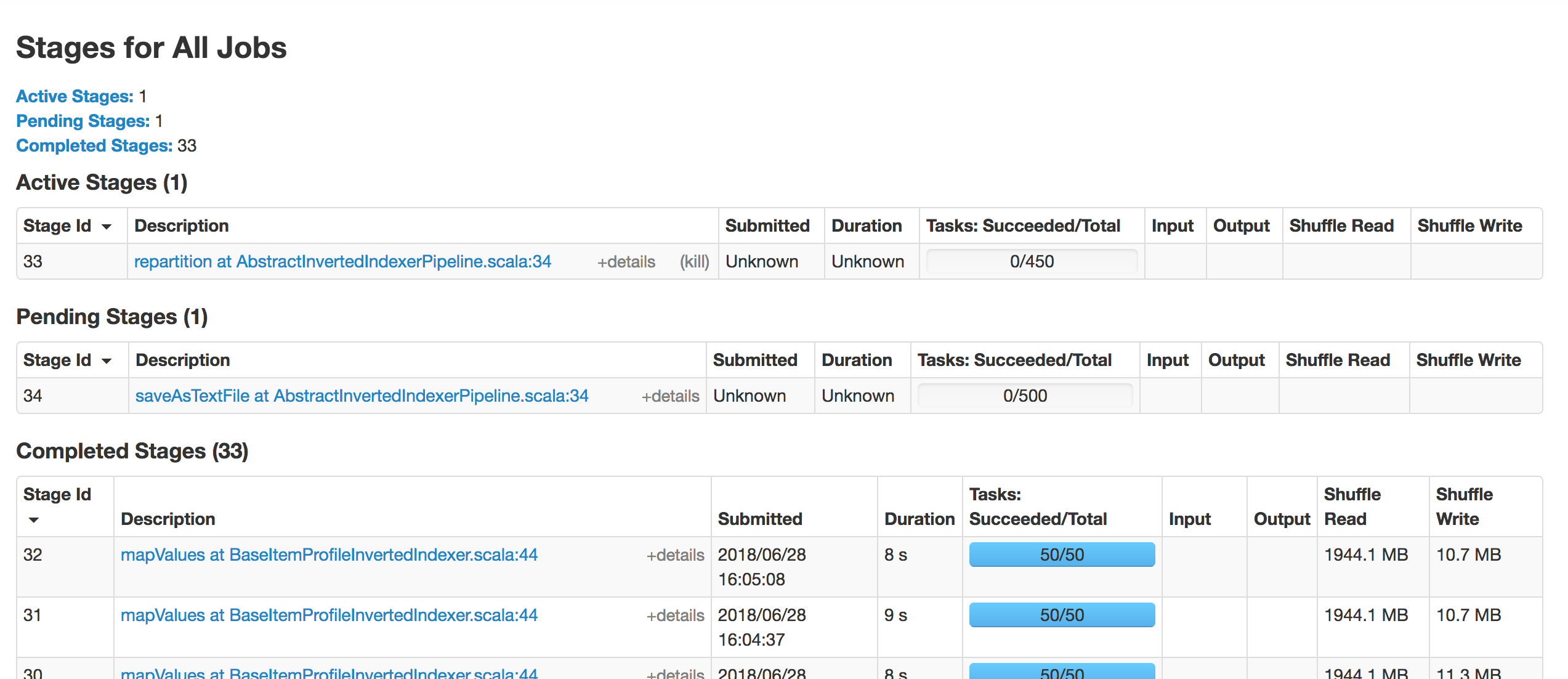
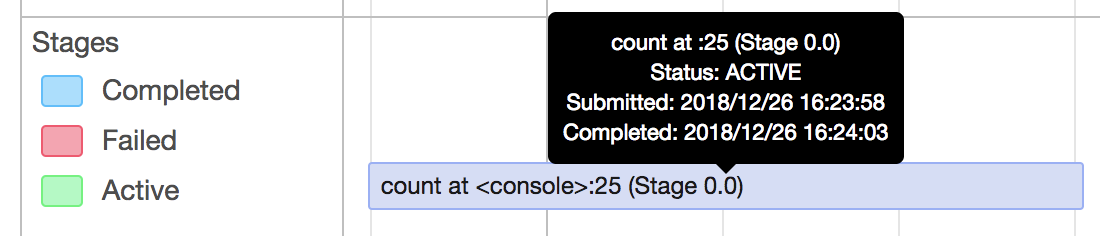
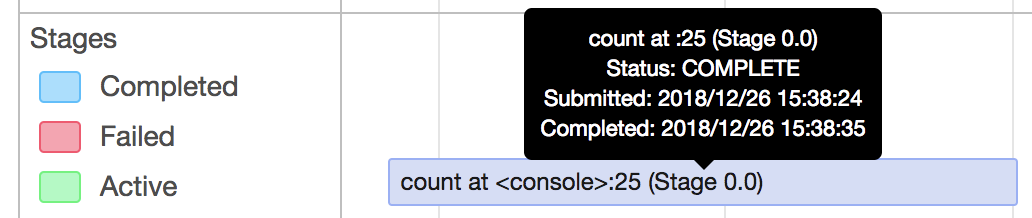
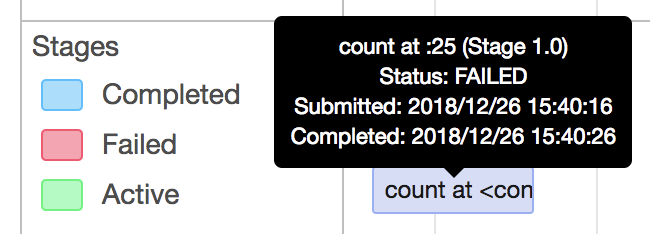
* [SPARK-25837][CORE] Fix potential slowdown in AppStatusListener when cleaning up stages ## What changes were proposed in this pull request? * Update `AppStatusListener` `cleanupStages` method to remove tasks for those stages in a single pass instead of 1 for each stage. * This fixes an issue where the cleanupStages method would get backed up, causing a backup in the executor in ElementTrackingStore, resulting in stages and jobs not getting cleaned up properly. Tasks seem most susceptible to this as there are a lot of them, however a similar issue could arise in other locations the `KVStore` `view` method is used. A broader fix might involve updates to `KVStoreView` and `InMemoryView` as it appears this interface and implementation can lead to multiple and inefficient traversals of the stored data. ## How was this patch tested? Using existing tests in AppStatusListenerSuite This is my original work and I license the work to the project under the project’s open source license. Closes apache#22883 from patrickbrownsync/cleanup-stages-fix. Authored-by: Patrick Brown <[email protected]> Signed-off-by: Marcelo Vanzin <[email protected]> (cherry picked from commit e9d3ca0) Signed-off-by: Marcelo Vanzin <[email protected]> * [SPARK-25933][DOCUMENTATION] Fix pstats.Stats() reference in configuration.md ## What changes were proposed in this pull request? Change ptats.Stats() to pstats.Stats() for `spark.python.profile.dump` in configuration.md. ## How was this patch tested? Doc test Closes apache#22933 from AlexHagerman/doc_fix. Authored-by: Alex Hagerman <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 1a7abf3) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26011][SPARK-SUBMIT] Yarn mode pyspark app without python main resource does not honor "spark.jars.packages" SparkSubmit determines pyspark app by the suffix of primary resource but Livy uses "spark-internal" as the primary resource when calling spark-submit, therefore args.isPython is set to false in SparkSubmit.scala. In Yarn mode, SparkSubmit module is responsible for resolving maven coordinates and adding them to "spark.submit.pyFiles" so that python's system path can be set correctly. The fix is to resolve maven coordinates not only when args.isPython is true, but also when primary resource is spark-internal. Tested the patch with Livy submitting pyspark app, spark-submit, pyspark with or without packages config. Signed-off-by: Shanyu Zhao <shzhaomicrosoft.com> Closes apache#23009 from shanyu/shanyu-26011. Authored-by: Shanyu Zhao <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 9a5fda6) Signed-off-by: Sean Owen <[email protected]> * [SPARK-25934][MESOS] Don't propagate SPARK_CONF_DIR from spark submit ## What changes were proposed in this pull request? Don't propagate SPARK_CONF_DIR to the driver in mesos cluster mode. ## How was this patch tested? I built the 2.3.2 tag with this patch added and deployed a test job to a mesos cluster to confirm that the incorrect SPARK_CONF_DIR was no longer passed from the submit command. Closes apache#22937 from mpmolek/fix-conf-dir. Authored-by: Matt Molek <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 696b75a) Signed-off-by: Sean Owen <[email protected]> * [MINOR][SQL] Fix typo in CTAS plan database string ## What changes were proposed in this pull request? Since [Spark 1.6.0](apache@56d7da1#diff-6f38a103058a6e233b7ad80718452387R96), there was a redundant '}' character in CTAS string plan's database argument string; `default}`. This PR aims to fix it. **BEFORE** ```scala scala> sc.version res1: String = 1.6.0 scala> sql("create table t as select 1").explain == Physical Plan == ExecutedCommand CreateTableAsSelect [Database:default}, TableName: t, InsertIntoHiveTable] +- Project [1 AS _c0#3] +- OneRowRelation$ ``` **AFTER** ```scala scala> sql("create table t as select 1").explain == Physical Plan == Execute CreateHiveTableAsSelectCommand CreateHiveTableAsSelectCommand [Database:default, TableName: t, InsertIntoHiveTable] +- *(1) Project [1 AS 1#4] +- Scan OneRowRelation[] ``` ## How was this patch tested? Manual. Closes apache#23064 from dongjoon-hyun/SPARK-FIX. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: hyukjinkwon <[email protected]> (cherry picked from commit b538c44) Signed-off-by: hyukjinkwon <[email protected]> * [SPARK-26084][SQL] Fixes unresolved AggregateExpression.references exception ## What changes were proposed in this pull request? This PR fixes an exception in `AggregateExpression.references` called on unresolved expressions. It implements the solution proposed in [SPARK-26084](https://issues.apache.org/jira/browse/SPARK-26084), a minor refactoring that removes the unnecessary dependence on `AttributeSet.toSeq`, which requires expression IDs and, therefore, can only execute successfully for resolved expressions. The refactored implementation is both simpler and faster, eliminating the conversion of a `Set` to a `Seq` and back to `Set`. ## How was this patch tested? Added a new test based on the failing case in [SPARK-26084](https://issues.apache.org/jira/browse/SPARK-26084). hvanhovell Closes apache#23075 from ssimeonov/ss_SPARK-26084. Authored-by: Simeon Simeonov <[email protected]> Signed-off-by: Herman van Hovell <[email protected]> (cherry picked from commit db136d3) Signed-off-by: Herman van Hovell <[email protected]> * [SPARK-26109][WEBUI] Duration in the task summary metrics table and the task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes apache#23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26118][BACKPORT-2.3][WEB UI] Introducing spark.ui.requestHeaderSize for setting HTTP requestHeaderSize ## What changes were proposed in this pull request? Introducing spark.ui.requestHeaderSize for configuring Jetty's HTTP requestHeaderSize. This way long authorization field does not lead to HTTP 413. ## How was this patch tested? Manually with curl (which version must be at least 7.55). With the original default value (8k limit): ```bash $ ./sbin/start-history-server.sh starting org.apache.spark.deploy.history.HistoryServer, logging to /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out $ echo -n "X-Custom-Header: " > cookie $ printf 'A%.0s' {1..9500} >> cookie $ curl -H cookie http://458apiros-MBP.lan:18080/ <h1>Bad Message 431</h1><pre>reason: Request Header Fields Too Large</pre> $ tail -1 /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out 18/11/19 21:24:28 WARN HttpParser: Header is too large 8193>8192 ``` After: ```bash $ echo spark.ui.requestHeaderSize=10000 > history.properties $ ./sbin/start-history-server.sh --properties-file history.properties starting org.apache.spark.deploy.history.HistoryServer, logging to /Users/attilapiros/github/spark/logs/spark-attilapiros-org.apache.spark.deploy.history.HistoryServer-1-apiros-MBP.lan.out $ curl -H cookie http://458apiros-MBP.lan:18080/ <!DOCTYPE html><html> <head>... <link rel="shortcut icon" href="/static/spark-logo-77x50px-hd.png"></link> <title>History Server</title> </head> <body> ... ``` (cherry picked from commit ab61ddb) Closes apache#23114 from attilapiros/julianOffByDays-2.3. Authored-by: “attilapiros” <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-25786][CORE] If the ByteBuffer.hasArray is false , it will throw UnsupportedOperationException for Kryo `deserialize` for kryo, the type of input parameter is ByteBuffer, if it is not backed by an accessible byte array. it will throw `UnsupportedOperationException` Exception Info: ``` java.lang.UnsupportedOperationException was thrown. java.lang.UnsupportedOperationException at java.nio.ByteBuffer.array(ByteBuffer.java:994) at org.apache.spark.serializer.KryoSerializerInstance.deserialize(KryoSerializer.scala:362) ``` Added a unit test Closes apache#22779 from 10110346/InputStreamKryo. Authored-by: liuxian <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 7f5f7a9) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26137][CORE] Use Java system property "file.separator" inste… … of hard coded "/" in DependencyUtils ## What changes were proposed in this pull request? Use Java system property "file.separator" instead of hard coded "/" in DependencyUtils. ## How was this patch tested? Manual test: Submit Spark application via REST API that reads data from Elasticsearch using spark-elasticsearch library. Without fix application fails with error: 18/11/22 10:36:20 ERROR Version: Multiple ES-Hadoop versions detected in the classpath; please use only one jar:file:/C:/<...>/spark-2.4.0-bin-hadoop2.6/work/driver-20181122103610-0001/myApp-assembly-1.0.jar jar:file:/C:/<...>/myApp-assembly-1.0.jar 18/11/22 10:36:20 ERROR Main: Application [MyApp] failed: java.lang.Error: Multiple ES-Hadoop versions detected in the classpath; please use only one jar:file:/C:/<...>/spark-2.4.0-bin-hadoop2.6/work/driver-20181122103610-0001/myApp-assembly-1.0.jar jar:file:/C:/<...>/myApp-assembly-1.0.jar at org.elasticsearch.hadoop.util.Version.<clinit>(Version.java:73) at org.elasticsearch.hadoop.rest.RestService.findPartitions(RestService.java:214) at org.elasticsearch.spark.rdd.AbstractEsRDD.esPartitions$lzycompute(AbstractEsRDD.scala:73) at org.elasticsearch.spark.rdd.AbstractEsRDD.esPartitions(AbstractEsRDD.scala:72) at org.elasticsearch.spark.rdd.AbstractEsRDD.getPartitions(AbstractEsRDD.scala:44) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:251) at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:49) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:253) at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:251) at scala.Option.getOrElse(Option.scala:121) at org.apache.spark.rdd.RDD.partitions(RDD.scala:251) at org.apache.spark.SparkContext.runJob(SparkContext.scala:2126) at org.apache.spark.rdd.RDD$$anonfun$collect$1.apply(RDD.scala:945) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:151) at org.apache.spark.rdd.RDDOperationScope$.withScope(RDDOperationScope.scala:112) at org.apache.spark.rdd.RDD.withScope(RDD.scala:363) at org.apache.spark.rdd.RDD.collect(RDD.scala:944) ... at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) at java.lang.reflect.Method.invoke(Method.java:498) at org.apache.spark.deploy.worker.DriverWrapper$.main(DriverWrapper.scala:65) at org.apache.spark.deploy.worker.DriverWrapper.main(DriverWrapper.scala) With fix application runs successfully. Closes apache#23102 from markpavey/JIRA_SPARK-26137_DependencyUtilsFileSeparatorFix. Authored-by: Mark Pavey <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit ce61bac) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26211][SQL] Fix InSet for binary, and struct and array with null. Currently `InSet` doesn't work properly for binary type, or struct and array type with null value in the set. Because, as for binary type, the `HashSet` doesn't work properly for `Array[Byte]`, and as for struct and array type with null value in the set, the `ordering` will throw a `NPE`. Added a few tests. Closes apache#23176 from ueshin/issues/SPARK-26211/inset. Authored-by: Takuya UESHIN <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit b9b68a6) Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-26201] Fix python broadcast with encryption ## What changes were proposed in this pull request? Python with rpc and disk encryption enabled along with a python broadcast variable and just read the value back on the driver side the job failed with: Traceback (most recent call last): File "broadcast.py", line 37, in <module> words_new.value File "/pyspark.zip/pyspark/broadcast.py", line 137, in value File "pyspark.zip/pyspark/broadcast.py", line 122, in load_from_path File "pyspark.zip/pyspark/broadcast.py", line 128, in load EOFError: Ran out of input To reproduce use configs: --conf spark.network.crypto.enabled=true --conf spark.io.encryption.enabled=true Code: words_new = sc.broadcast(["scala", "java", "hadoop", "spark", "akka"]) words_new.value print(words_new.value) ## How was this patch tested? words_new = sc.broadcast([“scala”, “java”, “hadoop”, “spark”, “akka”]) textFile = sc.textFile(“README.md”) wordCounts = textFile.flatMap(lambda line: line.split()).map(lambda word: (word + words_new.value[1], 1)).reduceByKey(lambda a, b: a+b) count = wordCounts.count() print(count) words_new.value print(words_new.value) Closes apache#23166 from redsanket/SPARK-26201. Authored-by: schintap <[email protected]> Signed-off-by: Thomas Graves <[email protected]> (cherry picked from commit 9b23be2) Signed-off-by: Thomas Graves <[email protected]> * [MINOR][DOC] Correct some document description errors Correct some document description errors. N/A Closes apache#23162 from 10110346/docerror. Authored-by: liuxian <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 60e4239) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26198][SQL] Fix Metadata serialize null values throw NPE How to reproduce this issue: ```scala scala> val meta = new org.apache.spark.sql.types.MetadataBuilder().putNull("key").build().json java.lang.NullPointerException at org.apache.spark.sql.types.Metadata$.org$apache$spark$sql$types$Metadata$$toJsonValue(Metadata.scala:196) at org.apache.spark.sql.types.Metadata$$anonfun$1.apply(Metadata.scala:180) ``` This pr fix `NullPointerException` when `Metadata` serialize `null` values. unit tests Closes apache#23164 from wangyum/SPARK-26198. Authored-by: Yuming Wang <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 676bbb2) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26233][SQL][BACKPORT-2.3] CheckOverflow when encoding a decimal value ## What changes were proposed in this pull request? When we encode a Decimal from external source we don't check for overflow. That method is useful not only in order to enforce that we can represent the correct value in the specified range, but it also changes the underlying data to the right precision/scale. Since in our code generation we assume that a decimal has exactly the same precision and scale of its data type, missing to enforce it can lead to corrupted output/results when there are subsequent transformations. ## How was this patch tested? added UT Closes apache#23233 from mgaido91/SPARK-26233_2.3. Authored-by: Marco Gaido <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26307][SQL] Fix CTAS when INSERT a partitioned table using Hive serde This is a Spark 2.3 regression introduced in apache#20521. We should add the partition info for InsertIntoHiveTable in CreateHiveTableAsSelectCommand. Otherwise, we will hit the following error by running the newly added test case: ``` [info] - CTAS: INSERT a partitioned table using Hive serde *** FAILED *** (829 milliseconds) [info] org.apache.spark.SparkException: Requested partitioning does not match the tab1 table: [info] Requested partitions: [info] Table partitions: part [info] at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.processInsert(InsertIntoHiveTable.scala:179) [info] at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.run(InsertIntoHiveTable.scala:107) ``` Added a test case. Closes apache#23255 from gatorsmile/fixCTAS. Authored-by: gatorsmile <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit 3bc83de) Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-26327][SQL][BACKPORT-2.3] Bug fix for `FileSourceScanExec` metrics update ## What changes were proposed in this pull request? Backport apache#23277 to branch 2.3 without the metrics renaming. ## How was this patch tested? New test case in `SQLMetricsSuite`. Closes apache#23299 from xuanyuanking/SPARK-26327-2.3. Authored-by: Yuanjian Li <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26315][PYSPARK] auto cast threshold from Integer to Float in approxSimilarityJoin of BucketedRandomProjectionLSHModel ## What changes were proposed in this pull request? If the input parameter 'threshold' to the function approxSimilarityJoin is not a float, we would get an exception. The fix is to convert the 'threshold' into a float before calling the java implementation method. ## How was this patch tested? Added a new test case. Without this fix, the test will throw an exception as reported in the JIRA. With the fix, the test passes. Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#23313 from jerryjch/SPARK-26315. Authored-by: Jing Chen He <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 860f449) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26352][SQL] join reorder should not change the order of output attributes ## What changes were proposed in this pull request? The optimizer rule `org.apache.spark.sql.catalyst.optimizer.ReorderJoin` performs join reordering on inner joins. This was introduced from SPARK-12032 (apache#10073) in 2015-12. After it had reordered the joins, though, it didn't check whether or not the output attribute order is still the same as before. Thus, it's possible to have a mismatch between the reordered output attributes order vs the schema that a DataFrame thinks it has. The same problem exists in the CBO version of join reordering (`CostBasedJoinReorder`) too. This can be demonstrated with the example: ```scala spark.sql("create table table_a (x int, y int) using parquet") spark.sql("create table table_b (i int, j int) using parquet") spark.sql("create table table_c (a int, b int) using parquet") val df = spark.sql(""" with df1 as (select * from table_a cross join table_b) select * from df1 join table_c on a = x and b = i """) ``` here's what the DataFrame thinks: ``` scala> df.printSchema root |-- x: integer (nullable = true) |-- y: integer (nullable = true) |-- i: integer (nullable = true) |-- j: integer (nullable = true) |-- a: integer (nullable = true) |-- b: integer (nullable = true) ``` here's what the optimized plan thinks, after join reordering: ``` scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}")) |-- x: integer |-- y: integer |-- a: integer |-- b: integer |-- i: integer |-- j: integer ``` If we exclude the `ReorderJoin` rule (using Spark 2.4's optimizer rule exclusion feature), it's back to normal: ``` scala> spark.conf.set("spark.sql.optimizer.excludedRules", "org.apache.spark.sql.catalyst.optimizer.ReorderJoin") scala> val df = spark.sql("with df1 as (select * from table_a cross join table_b) select * from df1 join table_c on a = x and b = i") df: org.apache.spark.sql.DataFrame = [x: int, y: int ... 4 more fields] scala> df.queryExecution.optimizedPlan.output.foreach(a => println(s"|-- ${a.name}: ${a.dataType.typeName}")) |-- x: integer |-- y: integer |-- i: integer |-- j: integer |-- a: integer |-- b: integer ``` Note that this output attribute ordering problem leads to data corruption, and can manifest itself in various symptoms: * Silently corrupting data, if the reordered columns happen to either have matching types or have sufficiently-compatible types (e.g. all fixed length primitive types are considered as "sufficiently compatible" in an `UnsafeRow`), then only the resulting data is going to be wrong but it might not trigger any alarms immediately. Or * Weird Java-level exceptions like `java.lang.NegativeArraySizeException`, or even SIGSEGVs. ## How was this patch tested? Added new unit test in `JoinReorderSuite` and new end-to-end test in `JoinSuite`. Also made `JoinReorderSuite` and `StarJoinReorderSuite` assert more strongly on maintaining output attribute order. Closes apache#23303 from rednaxelafx/fix-join-reorder. Authored-by: Kris Mok <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> (cherry picked from commit 56448c6) Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-26352][SQL][FOLLOWUP-2.3] Fix missing sameOutput in branch-2.3 ## What changes were proposed in this pull request? This is the branch-2.3 equivalent of apache#23330. After apache#23303 was merged to branch-2.3/2.4, the builds on those branches were broken due to missing a `LogicalPlan.sameOutput` function which came from apache#22713 only available on master. This PR is to follow-up with the broken 2.3/2.4 branches and make a copy of the new `LogicalPlan.sameOutput` into `ReorderJoin` to make it locally available. ## How was this patch tested? Fix the build of 2.3/2.4. Closes apache#23333 from rednaxelafx/branch-2.3. Authored-by: Kris Mok <[email protected]> Signed-off-by: Wenchen Fan <[email protected]> * [SPARK-26316][SPARK-21052][BRANCH-2.3] Revert hash join metrics in that causes performance degradation ## What changes were proposed in this pull request? Revert spark 21052 in spark 2.3 because of the discussion in [PR23269](apache#23269) ## How was this patch tested? N/A Closes apache#23319 from JkSelf/branch-2.3-revert21052. Authored-by: jiake <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26394][CORE] Fix annotation error for Utils.timeStringAsMs ## What changes were proposed in this pull request? Change microseconds to milliseconds in annotation of Utils.timeStringAsMs. Closes apache#23346 from stczwd/stczwd. Authored-by: Jackey Lee <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 428eb2a) Signed-off-by: Sean Owen <[email protected]> * [SPARK-24687][CORE] Avoid job hanging when generate task binary causes fatal error ## What changes were proposed in this pull request? When NoClassDefFoundError thrown,it will cause job hang. `Exception in thread "dag-scheduler-event-loop" java.lang.NoClassDefFoundError: Lcom/xxx/data/recommend/aggregator/queue/QueueName; at java.lang.Class.getDeclaredFields0(Native Method) at java.lang.Class.privateGetDeclaredFields(Class.java:2436) at java.lang.Class.getDeclaredField(Class.java:1946) at java.io.ObjectStreamClass.getDeclaredSUID(ObjectStreamClass.java:1659) at java.io.ObjectStreamClass.access$700(ObjectStreamClass.java:72) at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:480) at java.io.ObjectStreamClass$2.run(ObjectStreamClass.java:468) at java.security.AccessController.doPrivileged(Native Method) at java.io.ObjectStreamClass.<init>(ObjectStreamClass.java:468) at java.io.ObjectStreamClass.lookup(ObjectStreamClass.java:365) at java.io.ObjectOutputStream.writeClass(ObjectOutputStream.java:1212) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1119) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1173) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.defaultWriteFields(ObjectOutputStream.java:1547) at java.io.ObjectOutputStream.writeSerialData(ObjectOutputStream.java:1508) at java.io.ObjectOutputStream.writeOrdinaryObject(ObjectOutputStream.java:1431) at java.io.ObjectOutputStream.writeObject0(ObjectOutputStream.java:1177) at java.io.ObjectOutputStream.writeArray(ObjectOutputStream.java:1377)` It is caused by NoClassDefFoundError will not catch up during task seriazation. `var taskBinary: Broadcast[Array[Byte]] = null try { // For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep). // For ResultTask, serialize and broadcast (rdd, func). val taskBinaryBytes: Array[Byte] = stage match { case stage: ShuffleMapStage => JavaUtils.bufferToArray( closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef)) case stage: ResultStage => JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef)) } taskBinary = sc.broadcast(taskBinaryBytes) } catch { // In the case of a failure during serialization, abort the stage. case e: NotSerializableException => abortStage(stage, "Task not serializable: " + e.toString, Some(e)) runningStages -= stage // Abort execution return case NonFatal(e) => abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e)) runningStages -= stage return }` image below shows that stage 33 blocked and never be scheduled. <img width="1273" alt="2018-06-28 4 28 42" src="https://user-images.githubusercontent.com/26762018/42621188-b87becca-85ef-11e8-9a0b-0ddf07504c96.png"> <img width="569" alt="2018-06-28 4 28 49" src="https://user-images.githubusercontent.com/26762018/42621191-b8b260e8-85ef-11e8-9d10-e97a5918baa6.png"> ## How was this patch tested? UT Closes apache#21664 from caneGuy/zhoukang/fix-noclassdeferror. Authored-by: zhoukang <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 7c8f475) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26422][R] Support to disable Hive support in SparkR even for Hadoop versions unsupported by Hive fork ## What changes were proposed in this pull request? Currently, even if I explicitly disable Hive support in SparkR session as below: ```r sparkSession <- sparkR.session("local[4]", "SparkR", Sys.getenv("SPARK_HOME"), enableHiveSupport = FALSE) ``` produces when the Hadoop version is not supported by our Hive fork: ``` java.lang.reflect.InvocationTargetException ... Caused by: java.lang.IllegalArgumentException: Unrecognized Hadoop major version number: 3.1.1.3.1.0.0-78 at org.apache.hadoop.hive.shims.ShimLoader.getMajorVersion(ShimLoader.java:174) at org.apache.hadoop.hive.shims.ShimLoader.loadShims(ShimLoader.java:139) at org.apache.hadoop.hive.shims.ShimLoader.getHadoopShims(ShimLoader.java:100) at org.apache.hadoop.hive.conf.HiveConf$ConfVars.<clinit>(HiveConf.java:368) ... 43 more Error in handleErrors(returnStatus, conn) : java.lang.ExceptionInInitializerError at org.apache.hadoop.hive.conf.HiveConf.<clinit>(HiveConf.java:105) at java.lang.Class.forName0(Native Method) at java.lang.Class.forName(Class.java:348) at org.apache.spark.util.Utils$.classForName(Utils.scala:193) at org.apache.spark.sql.SparkSession$.hiveClassesArePresent(SparkSession.scala:1116) at org.apache.spark.sql.api.r.SQLUtils$.getOrCreateSparkSession(SQLUtils.scala:52) at org.apache.spark.sql.api.r.SQLUtils.getOrCreateSparkSession(SQLUtils.scala) at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ``` The root cause is that: ``` SparkSession.hiveClassesArePresent ``` check if the class is loadable or not to check if that's in classpath but `org.apache.hadoop.hive.conf.HiveConf` has a check for Hadoop version as static logic which is executed right away. This throws an `IllegalArgumentException` and that's not caught: https://github.com/apache/spark/blob/36edbac1c8337a4719f90e4abd58d38738b2e1fb/sql/core/src/main/scala/org/apache/spark/sql/SparkSession.scala#L1113-L1121 So, currently, if users have a Hive built-in Spark with unsupported Hadoop version by our fork (namely 3+), there's no way to use SparkR even though it could work. This PR just propose to change the order of bool comparison so that we can don't execute `SparkSession.hiveClassesArePresent` when: 1. `enableHiveSupport` is explicitly disabled 2. `spark.sql.catalogImplementation` is `in-memory` so that we **only** check `SparkSession.hiveClassesArePresent` when Hive support is explicitly enabled by short circuiting. ## How was this patch tested? It's difficult to write a test since we don't run tests against Hadoop 3 yet. See apache#21588. Manually tested. Closes apache#23356 from HyukjinKwon/SPARK-26422. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit 305e9b5) Signed-off-by: Hyukjin Kwon <[email protected]> * [SPARK-26366][SQL][BACKPORT-2.3] ReplaceExceptWithFilter should consider NULL as False ## What changes were proposed in this pull request? In `ReplaceExceptWithFilter` we do not consider properly the case in which the condition returns NULL. Indeed, in that case, since negating NULL still returns NULL, so it is not true the assumption that negating the condition returns all the rows which didn't satisfy it, rows returning NULL may not be returned. This happens when constraints inferred by `InferFiltersFromConstraints` are not enough, as it happens with `OR` conditions. The rule had also problems with non-deterministic conditions: in such a scenario, this rule would change the probability of the output. The PR fixes these problem by: - returning False for the condition when it is Null (in this way we do return all the rows which didn't satisfy it); - avoiding any transformation when the condition is non-deterministic. ## How was this patch tested? added UTs Closes apache#23350 from mgaido91/SPARK-26366_2.3. Authored-by: Marco Gaido <[email protected]> Signed-off-by: gatorsmile <[email protected]> * Revert "[SPARK-26366][SQL][BACKPORT-2.3] ReplaceExceptWithFilter should consider NULL as False" This reverts commit a7d50ae. * [SPARK-26366][SQL][BACKPORT-2.3] ReplaceExceptWithFilter should consider NULL as False ## What changes were proposed in this pull request? In `ReplaceExceptWithFilter` we do not consider properly the case in which the condition returns NULL. Indeed, in that case, since negating NULL still returns NULL, so it is not true the assumption that negating the condition returns all the rows which didn't satisfy it, rows returning NULL may not be returned. This happens when constraints inferred by `InferFiltersFromConstraints` are not enough, as it happens with `OR` conditions. The rule had also problems with non-deterministic conditions: in such a scenario, this rule would change the probability of the output. The PR fixes these problem by: - returning False for the condition when it is Null (in this way we do return all the rows which didn't satisfy it); - avoiding any transformation when the condition is non-deterministic. ## How was this patch tested? added UTs Closes apache#23372 from mgaido91/SPARK-26366_2.3_2. Authored-by: Marco Gaido <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26444][WEBUI] Stage color doesn't change with it's status ## What changes were proposed in this pull request? On job page, in event timeline section, stage color doesn't change according to its status. Below are some screenshots. ACTIVE: <img width="550" alt="active" src="https://user-images.githubusercontent.com/12194089/50438844-c763e580-092a-11e9-84f6-6fc30e08d69b.png"> COMPLETE: <img width="516" alt="complete" src="https://user-images.githubusercontent.com/12194089/50438847-ca5ed600-092a-11e9-9d2e-5d79807bc1ce.png"> FAILED: <img width="325" alt="failed" src="https://user-images.githubusercontent.com/12194089/50438852-ccc13000-092a-11e9-9b6b-782b96b283b1.png"> This PR lets stage color change with it's status. The main idea is to make css style class name match the corresponding stage status. ## How was this patch tested? Manually tested locally. ``` // active/complete stage sc.parallelize(1 to 3, 3).map { n => Thread.sleep(10* 1000); n }.count // failed stage sc.parallelize(1 to 3, 3).map { n => Thread.sleep(10* 1000); throw new Exception() }.count ``` Note we need to clear browser cache to let new `timeline-view.css` take effect. Below are screenshots after this PR. ACTIVE: <img width="569" alt="active-after" src="https://user-images.githubusercontent.com/12194089/50439986-08f68f80-092f-11e9-85d9-be1c31aed13b.png"> COMPLETE: <img width="567" alt="complete-after" src="https://user-images.githubusercontent.com/12194089/50439990-0bf18000-092f-11e9-8624-723958906e90.png"> FAILED: <img width="352" alt="failed-after" src="https://user-images.githubusercontent.com/12194089/50439993-101d9d80-092f-11e9-8dfd-3e20536f2fa5.png"> Closes apache#23385 from seancxmao/timeline-stage-color. Authored-by: seancxmao <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 5bef4fe) Signed-off-by: Sean Owen <[email protected]> * [SPARK-26496][SS][TEST] Avoid to use Random.nextString in StreamingInnerJoinSuite ## What changes were proposed in this pull request? Similar with apache#21446. Looks random string is not quite safe as a directory name. ```scala scala> val prefix = Random.nextString(10); val dir = new File("/tmp", "del_" + prefix + "-" + UUID.randomUUID.toString); dir.mkdirs() prefix: String = 窽텘⒘駖ⵚ駢⡞Ρ닋 dir: java.io.File = /tmp/del_窽텘⒘駖ⵚ駢⡞Ρ닋-a3f99855-c429-47a0-a108-47bca6905745 res40: Boolean = false // nope, didn't like this one ``` ## How was this patch tested? Unit test was added, and manually. Closes apache#23405 from HyukjinKwon/SPARK-26496. Authored-by: Hyukjin Kwon <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit e63243d) Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-25591][PYSPARK][SQL][BRANCH-2.3] Avoid overwriting deserialized accumulator ## What changes were proposed in this pull request? If we use accumulators in more than one UDFs, it is possible to overwrite deserialized accumulators and its values. We should check if an accumulator was deserialized before overwriting it in accumulator registry. ## How was this patch tested? Added test. Closes apache#23432 from viirya/SPARK-25591-2.3. Authored-by: Liang-Chi Hsieh <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> * [SPARK-26019][PYSPARK] Allow insecure py4j gateways Spark always creates secure py4j connections between java and python, but it also allows users to pass in their own connection. This restores the ability for users to pass in an _insecure_ connection, though it forces them to set the env variable 'PYSPARK_ALLOW_INSECURE_GATEWAY=1', and still issues a warning. Added test cases verifying the failure without the extra configuration, and verifying things still work with an insecure configuration (in particular, accumulators, as those were broken with an insecure py4j gateway before). For the tests, I added ways to create insecure gateways, but I tried to put in protections to make sure that wouldn't get used incorrectly. Closes apache#23337 from squito/SPARK-26019. Authored-by: Imran Rashid <[email protected]> Signed-off-by: Hyukjin Kwon <[email protected]> (cherry picked from commit 1e99f4e) Signed-off-by: Hyukjin Kwon <[email protected]> * [MINOR][NETWORK][TEST] Fix TransportFrameDecoderSuite to use ByteBuf instead of ByteBuffer ## What changes were proposed in this pull request? `fireChannelRead` expects `io.netty.buffer.ByteBuf`.I checked that this is the only place which misuse `java.nio.ByteBuffer` in `network` module. ## How was this patch tested? Pass the Jenkins with the existing tests. Closes apache#23442 from dongjoon-hyun/SPARK-NETWORK-COMMON. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 27e42c1) Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26078][SQL][BACKPORT-2.3] Dedup self-join attributes on IN subqueries ## What changes were proposed in this pull request? When there is a self-join as result of a IN subquery, the join condition may be invalid, resulting in trivially true predicates and return wrong results. The PR deduplicates the subquery output in order to avoid the issue. ## How was this patch tested? added UT Closes apache#23450 from mgaido91/SPARK-26078_2.3. Authored-by: Marco Gaido <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-26545] Fix typo in EqualNullSafe's truth table comment ## What changes were proposed in this pull request? The truth table comment in EqualNullSafe incorrectly marked FALSE results as UNKNOWN. ## How was this patch tested? N/A Closes apache#23461 from rednaxelafx/fix-typo. Authored-by: Kris Mok <[email protected]> Signed-off-by: gatorsmile <[email protected]> (cherry picked from commit 4ab5b5b) Signed-off-by: gatorsmile <[email protected]> * [SPARK-26537][BUILD][BRANCH-2.3] change git-wip-us to gitbox ## What changes were proposed in this pull request? This is a backport of apache#23454 due to apache recently moving from git-wip-us.apache.org to gitbox.apache.org, we need to update the packaging scripts to point to the new repo location. this will also need to be backported to 2.4, 2.3, 2.1, 2.0 and 1.6. ## How was this patch tested? the build system will test this. Closes apache#23472 from dongjoon-hyun/SPARK-26537. Authored-by: shane knapp <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> * [SPARK-25253][PYSPARK][FOLLOWUP] Undefined name: from pyspark.util import _exception_message HyukjinKwon ## What changes were proposed in this pull request? add __from pyspark.util import \_exception_message__ to python/pyspark/java_gateway.py ## How was this patch tested? [flake8](http://flake8.pycqa.org) testing of https://github.com/apache/spark on Python 3.7.0 $ __flake8 . --count --select=E901,E999,F821,F822,F823 --show-source --statistics__ ``` ./python/pyspark/java_gateway.py:172:20: F821 undefined name '_exception_message' emsg = _exception_message(e) ^ 1 F821 undefined name '_exception_message' 1 ``` Please review http://spark.apache.org/contributing.html before opening a pull request. Closes apache#22265 from cclauss/patch-2. Authored-by: cclauss <[email protected]> Signed-off-by: hyukjinkwon <[email protected]> * [MINOR][BUILD] Fix script name in `release-tag.sh` usage message ## What changes were proposed in this pull request? This PR fixes the old script name in `release-tag.sh`. $ ./release-tag.sh --help | head -n1 usage: tag-release.sh ## How was this patch tested? Manual. $ ./release-tag.sh --help | head -n1 usage: release-tag.sh Closes apache#23477 from dongjoon-hyun/SPARK-RELEASE-TAG. Authored-by: Dongjoon Hyun <[email protected]> Signed-off-by: Dongjoon Hyun <[email protected]> (cherry picked from commit 468d25e) Signed-off-by: Dongjoon Hyun <[email protected]>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…he task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes apache#23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]>
… is incorrect when there are failed or killed tasks and update duration metrics ## What changes were proposed in this pull request? This PR fixes 3 issues 1) Total tasks message in the tasks table is incorrect, when there are failed or killed tasks 2) Sorting of the "Duration" column is not correct 3) Duration in the aggregated tasks summary table and the tasks table and not matching. Total tasks = numCompleteTasks + numActiveTasks + numKilledTasks + numFailedTasks; Corrected the duration metrics in the tasks table as executorRunTime based on the PR apache#23081 ## How was this patch tested? test step: 1) ``` bin/spark-shell scala > sc.parallelize(1 to 100, 10).map{ x => throw new RuntimeException("Bad executor")}.collect() ```  After patch:  2) Duration metrics: Before patch:  After patch:  Closes apache#23160 from shahidki31/totalTasks. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
…he task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes apache#23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]>
…he task table are different ## What changes were proposed in this pull request? Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. ## How was this patch tested? Before patch:  After patch:  Closes apache#23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]>
…he task table are different Ref: LIHADOOP-54112 Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary. In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark. Before patch:  After patch:  Closes apache#23081 from shahidki31/duratinSummary. Authored-by: Shahid <[email protected]> Signed-off-by: Sean Owen <[email protected]> (cherry picked from commit 540afc2) Signed-off-by: Sean Owen <[email protected]> RB=2150408 BUG=LIHADOOP-54112 G=spark-reviewers R=yezhou,rhu,ydegani,keshi A=rhu,ydegani
What changes were proposed in this pull request?
Task summary table displays the summary of the task table in the stage page. However, the 'Duration' metrics of 'task summary' table and 'task table' are not matching. The reason is because, in the 'task summary' we display 'executorRunTime' as the duration, and in the 'task table' the actual duration of the task. Except duration metrics, all other metrics are properly displaying in the task summary.
In Spark2.2, used to show 'executorRunTime' as duration in the 'taskTable'. That is why, in summary metrics also the 'exeuctorRunTime' shows as the duration. So, we need to show 'executorRunTime' as the duration in the tasks table to follow the same behaviour as the previous versions of spark.
How was this patch tested?
Before patch:
After patch:
