[Memory Management] GSoC 2024 Final Report
Google Summer of Code' 24 Final Report
[HugeGraph] Support Memory Management Module
| Role: | Open Source Contributor |
|---|---|
| Duration: | 2024.05 - 2024.10 |
| Project: | Apache HugeGraph |
- Name - Junzhi Peng (@Pengzna)
- Mentors - @Imba Jin & @Jermy
- Project Code - https://github.com/apache/incubator-hugegraph/pull/2649
- Project Wiki - GSOC2024 - Apache HugeGraph
- You can checkout my blogs(in Chinese) and my complete proposal!
When the JVM GC performs a large amount of garbage collection, the latency of the request is often high, and the response time becomes uncontrollable. To reduce request latency and response time jitter, the hugegraph-server graph query engine has already used off-heap memory in most OLTP algorithms.
However, at present, hugegraph cannot control memory based on a single request Query, so a Query may exhaust the memory of the entire process and cause OOM, or even cause the service to be unable to respond to other requests. Need to implement a memory management module based on a single Query.
Key goals include:
- Implement a unified memory manager, independently manage JVM off-heap memory, and adapt the memory allocation methods of various native collections, so that the memory mainly used by the algorithm comes from the unified memory pool, and it is returned to the memory pool after release.
- Each request corresponds to a unified memory manager, and the memory usage of a request can be controlled by counting the memory usage of a request.
- Complete related unit tests UT and basic documentation.
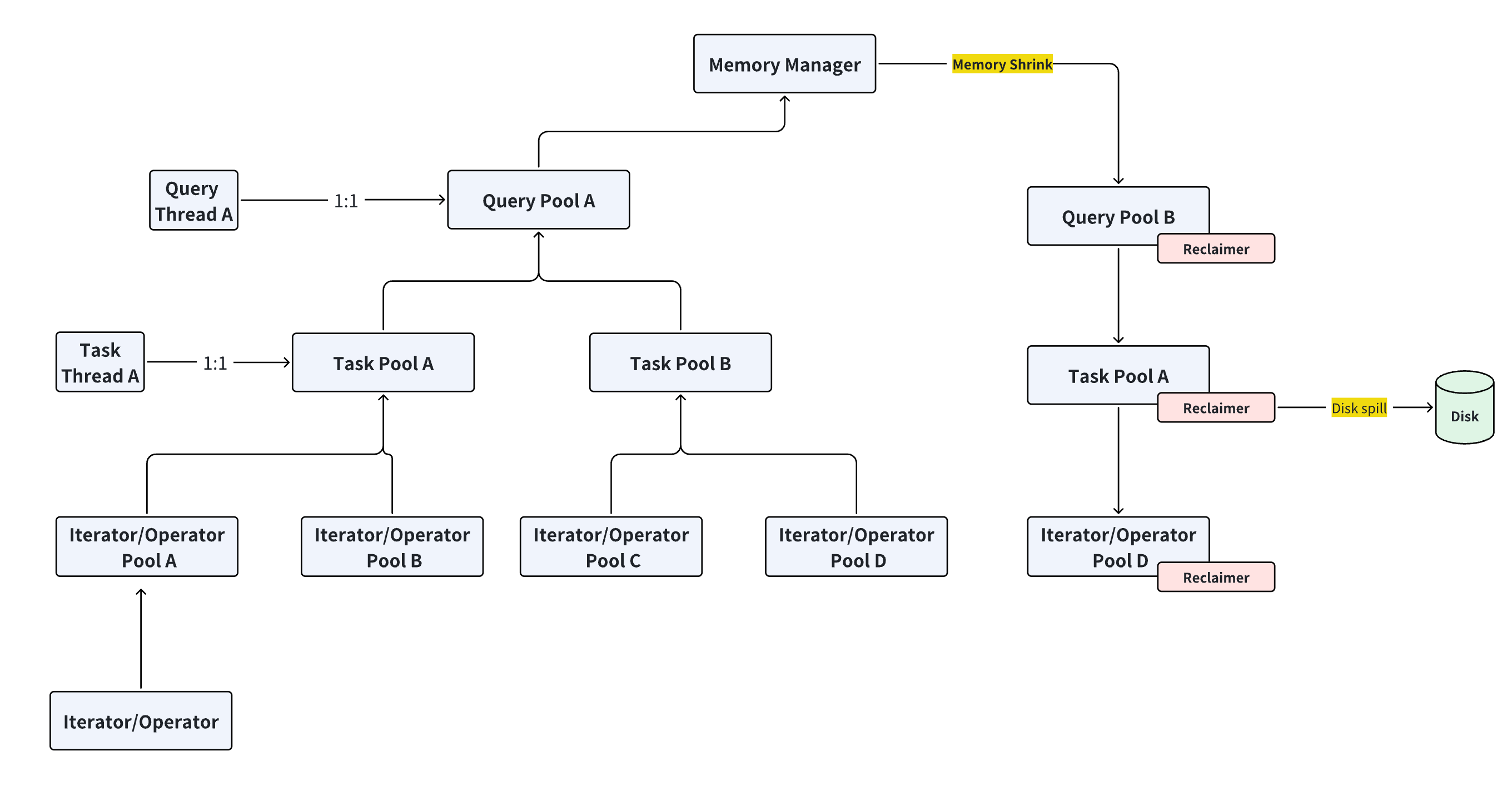
As shown in the figure above, we allocate different levels of MemoryPool (referred to as MemoryContext) for various execution components, corresponding to different layers of memory management:
- Each Query corresponds to a QueryMemoryPool.
- Each Task derived from a Query (representing each thread) has a corresponding TaskMemoryPool.
- Each Operator utilized by a Task (such as iterators in HugeGraph) corresponds to an OperatorMemoryPool.
- The MemoryManager oversees all
MemoryPools. - Objects with similar lifespans are stored within the same
MemoryContextto minimize cross-physical memory access and enable unified memory release.
This structure allows fine-grained tracking of memory usage for each query down to the operator level, enabling optimal control over global memory usage.
These three types of MemoryPools can form a MemoryPool Tree with MemoryManager as the root and OperatorPool as the leaf nodes:
-
Leaf nodes are the actual memory consumers (
OperatorPool). - Higher-level
TaskPoolandQueryPooldo not directly consume memory; instead, they act as aggregators, consolidating the usage of leaf nodes and managing their lifecycle.
MemoryPool Lifecycle:
- QueryMemoryPool: Created at the start of each query (e.g., an HTTP query request). It is released, along with its allocated memory, at the query’s conclusion.
-
TaskMemoryPool: Created when a new thread task is submitted (e.g.,
Executor.submit(() -> doSomething())). It is released, along with its allocated memory, at the end of the thread task. -
OperatorMemoryPool: Created whenever an iterator is instantiated. It is not explicitly released but is automatically released when its parent
TaskMemoryPoolis released.
All memory allocation requests are initiated by the leaf node OperatorPool, which passes the usage upward in a bottom-up manner to the QueryMemoryPool.
- Memory is consumed centrally by the
QueryMemoryPoolfrom theMemoryManager. - The
QueryMemoryPoolhas a capacity limit, so if it lacks sufficient capacity, it requests more memory from theMemoryManager. - Memory allocation follows a two-step process: logical allocation (
requestMemory) and then physical allocation (allocate). Once therequestprocess completes, the statistics in both theMemoryManagerandPoolare updated.
If the QueryMemoryPool has enough memory, it returns the allocation result, which propagates top-down through each layer back to the leaf node.
-
If the
QueryMemoryPoollacks sufficient memory, it initiates a memory arbitration request with the root nodeMemoryManager. -
Each memory allocation uses a "reservation" strategy to reduce the frequency of requests by applying quantization:
- If the requested size is less than 16MB, it rounds up to the nearest 1MB.
- If the requested size is less than 64MB, it rounds up to the nearest 4MB.
- If the requested size is 64MB or more, it rounds up to the nearest 8MB.
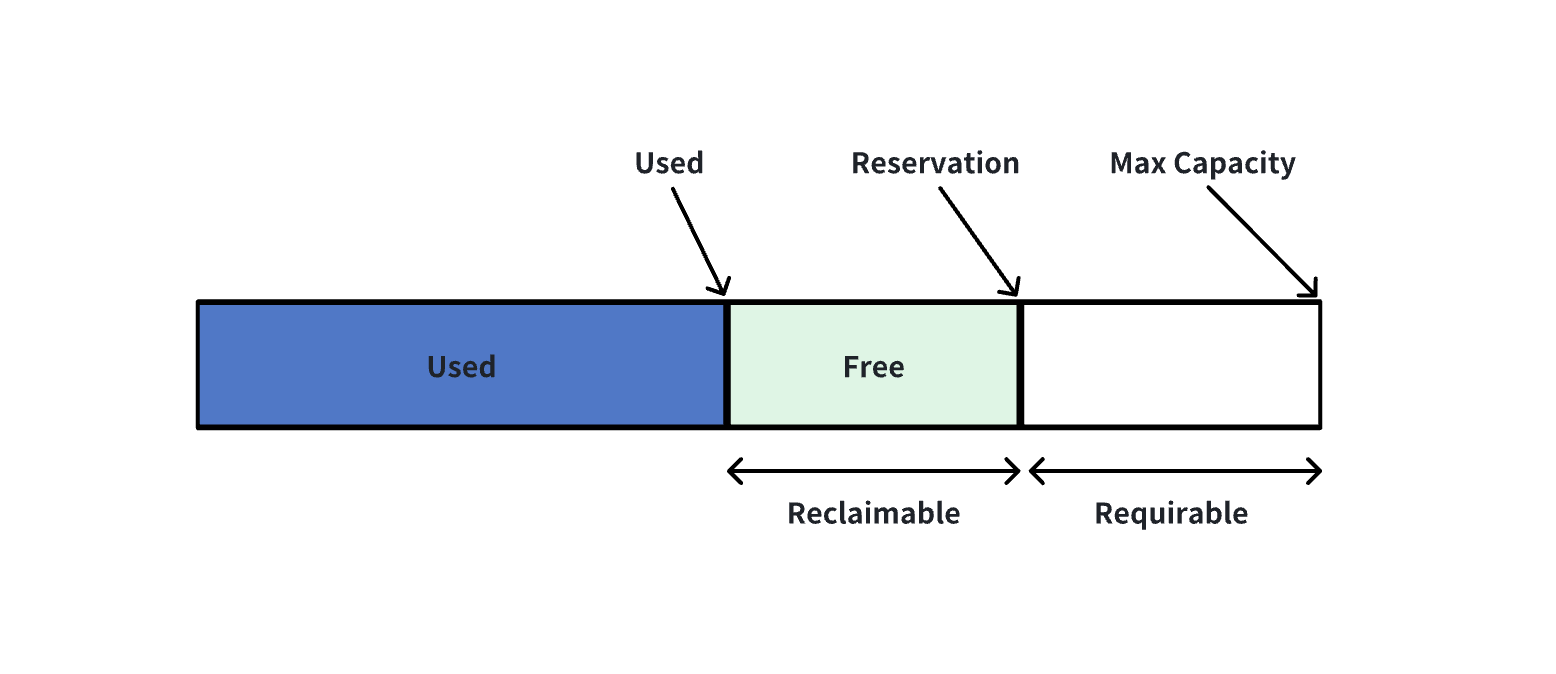
Each MemoryPool has a concept of capacity, representing the maximum capacity of each pool, the currently requested capacity, and the reserved capacity for all leaf nodes from the root pool.
- For instance, if a certain
leaf poolrequires additional memory, it allocates from the available capacity in the green section. If that capacity is insufficient, it expands rightward to request additional capacity. Should global memory still fall short, memory arbitration will be triggered.
The primary role of memory arbitration is to manage the available capacity of all queries and perform arbitration across queries.
- It determines which query or operator's idle capacity should be returned to the corresponding query or operator.
- Alternatively, it may employ spill techniques, offloading capacity and state data used by bi-operators and returning the freed capacity to the query.
A memory arbitration process is triggered by a memory allocation request:
- When a memory allocation request reaches the
QueryPooland finds insufficient memory, theMemoryManagerinitiates an arbitration process. - Essentially, memory arbitration is a memory recovery process, deciding which queries' memory to recover and how to perform the recovery.
- If the memory recovery target is identified, the recovery request propagates top-down to the leaf node.
-
Local Arbitration
If
OperatorAinQueryAtriggers arbitration, the Local strategy only reclaims idle memory within other operators insideQueryA.For instance, if
OperatorAunderQueryArequires memory, all free memory inQueryAexcept that ofOperatorAwill be reclaimed and allocated toOperatorA. -
Global Arbitration
If arbitration is triggered by
QueryA, the local strategy attempts to reclaim idle memory from other queries.- The process follows the same pattern.
- It chooses another query, say
QueryB, to reclaim.- Selection strategy: Queries are sorted by the amount of free memory, with the one having the most free memory chosen for reclamation.
- Default reclamation strategy: Only idle portions of memory are reclaimed.
If an Operator requests memory allocation and, even after one round of memory arbitration, memory is still insufficient, an OOM (Out of Memory) exception will be thrown (custom-defined). This will terminate the current query task (self-abort) and release all allocated memory.
Requirement: For the same pool, memory arbitration, memory allocation, and memory release must all be serialized, with no two processes allowed to run concurrently.
- During memory arbitration, neither allocation nor release of memory is permitted, as arbitration requires the memory state of the pool to remain unchanged. This means Query processes must be “paused” during arbitration (i.e., memory allocation and release are not allowed).
- This "pause" does not need to be an actual pause; only the memory state needs to remain constant, not the execution state.
- This is implemented through a flag: after arbitration is triggered, a flag is set.
- If the pool subsequently attempts to allocate or release memory while the flag is set, it will enter a condition wait (achieving a “paused” state effect for the query task). Once arbitration is complete, a signal will be sent to resume operations.
- Memory allocation shares a lock with memory arbitration to ensure that memory arbitration and memory allocation are serialized (i.e., non-concurrent).
- Memory release in the pool must not be concurrent with any other processes (allocation or arbitration).
- When releasing memory, a
closedflag is set, preventing any concurrent actions with the release process.
- When releasing memory, a
Inspiration: By analyzing the dumped files, it was observed that over 90% of query memory is consumed by labels, properties, edges, and vertices. Memory usage in queries is concentrated within a small number of immutable classes with a large number of instances.
Content: Instead of moving the entire data structure off-heap, the objects in data structures remain on-heap, while certain memory-heavy, immutable member variables (such as label, which is essentially an int) are stored off-heap. The memory management framework then manages this portion of off-heap memory.
- Off-heap management of these immutable member variables facilitates zero-copy read/write operations.

- Identify all objects that are both [memory-intensive] and [immutable] and provide an API for direct access and reading from off-heap memory.
-
Object[]: The main memory usage comes from theHugeEdgelist, so only the modification ofHugeEdgeneeds to be addressed. -
HugeVertex: Its main memory usage also comes from theHugeEdgelist, so only the modification ofHugeEdgeis needed. -
HugeEdge:- A portion of memory is consumed by
id:-
IdGenerator.Id: transformation completed.
-
- Another portion comes from
IntObjectMap, which is mutable and therefore cannot be modified.
- A portion of memory is consumed by
-
label: Essentially anId, so onceIdtransformation is completed, this is also handled. -
HugeProperty: Essentially avalue, which can be stored off-heap.
Implementation: PR Link
- A
Factorywas implemented to replace all instances ofnewfor the objects listed above. - The
Factoryinterface is consistent with the originalnewsyntax. - Within the
Factory, depending on the user-definedmemory_mode, it constructs either the original on-heap version of the object or the off-heap version.
-
We have now completed an independent memory management framework and have successfully moved memory-intensive, immutable objects off-heap in the query path of Apache HugeGraph. Notably, this memory management framework is decoupled from the core of Apache HugeGraph, allowing it to function independently.
-
Next, we need to integrate this memory management framework into the Apache HugeGraph query path. Specifically,
QueryMemoryPool,TaskMemoryPool, andOperatorMemoryPoolshould be allocated at each stage of the query path. For memory allocation points, on-heap objects need to be replaced with off-heap objects. -
After adapting the Apache HugeGraph query path, the plan is to use the
twitter-2010.txtdataset to test Apache HugeGraph’s query performance, including multi-hop queries, kout queries, etc. Memory usage comparisons will be conducted between the original on-heap mode (Baseline) and the off-heap modified version.
I would like to express my heartfelt gratitude to my mentors @Imba Jin and @Jermy for their invaluable support and guidance throughout my Google Summer of Code journey. Their expertise and dedication were essential in navigating the challenges of Apache HugeGraph. Their insights on best practices and deep understanding of the project were instrumental in helping me grow as a developer and contributor. Thanks for this incredible opportunity to learn and collaborate!