{kind=link}
Produce mock meetup.com events to Kafka in and perform real-time stream processing using Flink.
Requirements:
- Docker with Docker Compose
To start all required containers, run make up. To stop them, type make down (this will destroy all volumes to preserve space). Logs from the producer
and the consumer are accessible using make logs.
The dataset will be automatically downloaded from a remote server when the container is being built.
Ports 8081 (Flink) and 9000 (Kafdrop) are exposed to the host.
Containers come with sensible defaults. If you wish to tinker with any of the
parameters, the following can be changed from docker-compose.yml:
ZOOKEEPER_URIspecifies the Zookeeper instance that is usedKAFKA_URIspecifies the Kafka instance that is usedKAFKA_EVENTS_TOPICdecides to which topics the events are pushed toKAFKA_TOP_CITIES_TOPICspecifies to which topic the top cities are outputtedKAFKA_MUNICH_HOTSPOTS_TOPICspecifies the topic for hotspots in MunichKAFKA_PRODUCER_ITERATIONSis the number of times the input file will be pushed to Kafka (note: after EOF is reached, file will be repushed from the start, which will not work with windowed operators).KAFKA_EVENT_CONSUMER_GROUPis the name of the Flink's consumer groupINPUT_FILEis the path to the input file inside the containerFLINK_PARALLELis the parallelism level of the pipeline
The dataset is generated based on an actual distribution of meetups on meetup.com.
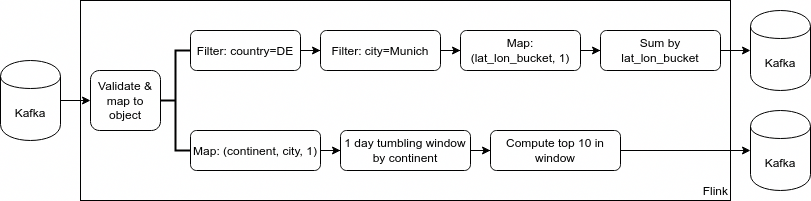
At the early stages of the processing pipeline, data is first filtered (based on the missing fields) and converted to the appropriate form for further processing.
Later, two distinct processing branches are created:
- The first filters out the events in Munich, Germany. Those are then divided into 1km x 1km buckets. Hotspots in Munich are reported based on the count of the events in each bucket (note: aggregation is done in memory for the entire stream so that we don't have to implement the downstream pipeline).
- The second reports the most frequent cities for meetups in Europe. Data is aggregated separately for each day and immediately pushed to Kafka.