Design and/or help review new PoW scheme #25
Comments
"Crazy" ideas with impact beyond Zcash and cryptocurrencies
|
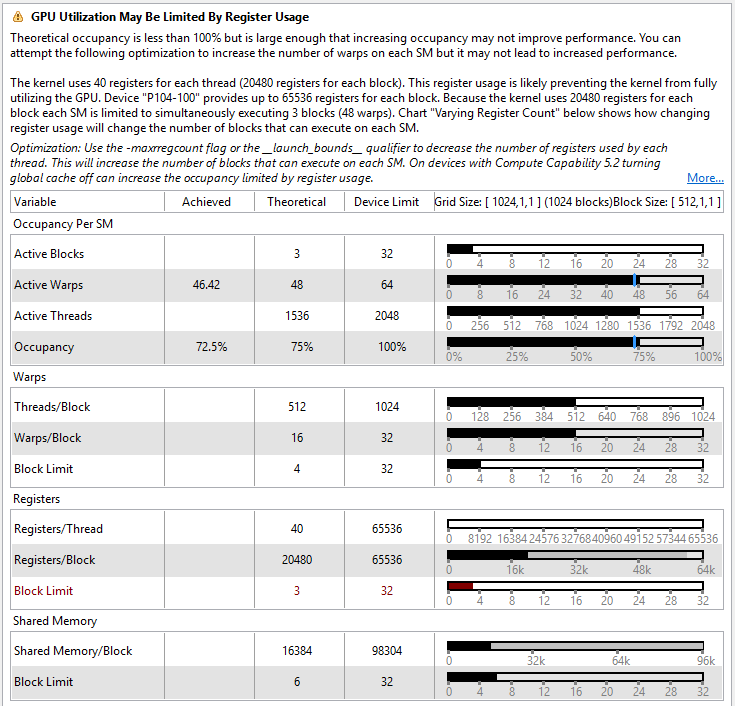
This is exactly what ProgPoW is designed and tuned for. We've done most of the design and tuning on Nvidia cards because they have a really nice profiler, but running on AMD cards gets similar performance characteristics. We've intentionally sized things like the L1 cache portion to fit nicely on modern cards of both architectures. With the current tuning it's maxing out register file, math issue, shared memory bandwidth, and global memory bandwidth. It's using shared memory (aka local memory in OpenCL) to store the cached portion since the performance is relatively deterministic. Here's some performance analysis numbers from a stock P104-100 (Nvidia's mining-specific card that's equivalent to a GTX 1080)
You'll noticed that the "unified cache" (aka L1) and L2 are under utilized. We have not found any way to use them with deterministic performance, so they're currently being ignored. I don't think that's a significant loss in ASIC coverage.
We've researched this direction a lot and come to the conclusion that it's not feasible while defending against specialized ASICs. Any semi-useful computation is not going to map perfectly to any commodity hardware, so there will be opportunities for ASIC specialization efficiency gains. Equihash is a perfect example of a moderately complex problem where an ASIC has significant efficiency gains. For an example outside of the crypto world take a look at the Anton chips for molecular dynamics.
That's exactly why we're targeting GPUs - a significant portion of the Top500 supercomputer list has GPUs attached. How would you suggest tweaking ProgPoW to be more programmable?
David's experience with Obelisk (that you link) I think shows that a small-scale ASIC startup trying to go up against a large-scale ASIC manufacturer is generally futile. https://blog.sia.tech/the-state-of-cryptocurrency-mining-538004a37f9b |


|
@solardiz thanks for the submission! Do you think it is possible to have concrete deliverables in a final submission? Any help needed about that? Please note that this is not a job offer but a grant, so your efforts has a natural limit (bills paid by the grant). |
|
@kushti Thanks for your (expected) request that I clarify this. Yes, it is possible to make this reasonably specific (or alternatively to withdraw it), but for that I need better understanding of who is in a position to authorize a PoW change for Zcash and what they think - and perhaps we'll need to discuss what needs to be done with that group involved. I tried e-mailing Zooko, but he only said he likes my ideas in general. I'm not up to date on how Zcash is currently governed, and without knowing who can make the call on a PoW change and what their thoughts are, I don't know how to optimally focus my potential contribution such that it'd be useful to Zcash in particular rather than "merely" to further research on PoWs in general. Or is Zcash sufficiently interested in funding research on PoWs in general, even without much likelihood of it being directly useful to Zcash? @RadixPi Thank you for your comments. The work you've done on ProgPoW is impressive, but as you realize there's more to do. It's a pity that the caches are under-utilized - especially the L1 caches, which are faster and combined (total for the entire chip) are larger than L2. I guess when you try to use them much more, you might see a reduction in your global memory bandwidth usage, so it'd be a tough trade-off. I think this is significant, but luckily the register files are even larger than the caches. Do you also have any profiling results on usage of the multiply-add units? I expect that those are heavily under-utilized by current ProgPoW. I wouldn't go as far as to say that "ASIC resistance" is necessarily impossible when doing useful work, but I am also currently unaware of an example to the contrary. This is why the example I mentioned goes along with accepting eventual ASICs with a performance advantage on par with those that might be built for Equihash. Those Anton chips are very impressive. I think the designers/users of such useful ASICs could benefit from also building a PoW scheme and a cryptocurrency around those - it'd be a way for them to increase production volume and thus lower per-unit costs, and to buy back obsolete-for-mining ASICs for doing useful computation on.
I'm not ready to suggest specific changes, but I think that your frequent
Yes, which is a reason why I suggested much more than merely "let's get into the PoW ASIC business ourselves" - I suggested getting into a business with relevance way beyond PoW, so that the devices would be relevant even when mining with them is no longer profitable, and many would be acquired for non-mining applications right away. |
The problem is streaming all the data from the global DAG thrashes both the L1 and L2 caches. We haven't found any way to prevent this thrashing, even playing with CUDA's various per-op caching modes. We're still using shared/local memory which is quite large, so that's reasonable coverage.
The profiler is fairly broad, showing ALU usage, it doesn't breakdown MAD vs ADD vs LOP instructions. Again I don't think slightly under-utilizing the multiplier is a huge deal - not using the floating point hardware at all is a much bigger deal, and there's no way around that.
The economics on that are a very fine line. Either the cryptocurrency is significantly more profitable than the base usage, in which case demand and the price of the ASIC spikes - as has happened with GPUs. Or the cryptocurrency isn't as profitable, in which case it has no effect. I can't imagine anyone with a real-world problem to solve would intentionally invite the volatility of cryptocurrencies into their workflow.
Can you expand on this? I'm not quite sure what you mean. It'd be a fairly easy tweak to change the ratio between merge() and math() operations - such as doing 3 ops like math(math(), math()) instead of a single math().
If that business existed wouldn't Bitmain plus Intel, Altera, Xilinx, Nvidia, AMD, IBM, etc already be working on it? |
Yes, that's what I thought. [I have the same problem with yescrypt on CPU. This limits yescrypt's efficient use of L2 cache to roughly one half its size when S-box size is tuned for that cache level - so e.g., 96 or 128 KiB works reasonably well, but 192 KiB is already too slow, on a typical CPU with 256 KiB of L2 cache. And that's on a huge page, so the issue isn't the OS kernel's lack of page coloring. I could mask address bits so that the expected-hit vs. expected-miss accesses never compete for the same cache lines, but this also halves the usable cache size. I wish we had a way to reconfigure a portion of the cache (larger than a half) as local memory on CPU as well.] On some NVIDIA families you can adjust the L1 cache vs. local memory split, IIRC up to setting local memory to be 96 KiB out of 128 KiB total on Volta. Then it could seem that if you tune your algorithm to require 96 KiB of local memory, it won't run efficiently on GPUs with less than that, but that's not necessarily so: you'd probably be limited to using max 32 KiB of local memory per instance of the algorithm anyway, and you'd run multiple warps (the optimal number, and maximum that fits, varying by GPU). Maybe ideally for a GPU-focused PoW we'd introduce moderate locality of reference in our global memory accesses and have moderate amount of cache thrashing. So that the algorithm would actually benefit from having a cache (and of varying size as it does vary across different GPUs) rather than only a local memory. Just thinking out loud.
I think current ProgPoW heavily under-utilizes the multiplier. Not slightly. As I understand, to fully utilize it we need to issue a MAD every clock cycle.
I think prior to Volta the 32-bit integer and FP32 units are shared, so by issuing lots of 32-bit integer MADs we'd be using a large part of the same hardware. However, starting with Volta yes - I think we need to be issuing both integer and FP32 MADs, as the units are separate and usable simultaneously (the documentation says this change in Volta is so that computation on array indices does not slow down FP32 processing).
There might be. IEEE compliance gives us some guarantees. Also, people have been using 64-bit floating point as 53-bit integer, e.g. in hash127 on the original Pentium, and now commonly relying on precise integers within this range in JavaScript. With FP32, it's trickier - we don't want to limit ourselves just to the mantissa as that would be more significant under-utilization of the hardware (worse than 53/64) - but perhaps we can define something operating within IEEE guarantees yet utilizing more of the hardware.
I can, if their task and specific project schedule and budget fits and they think out of the box. For example, their budget for the next year might not permit them to order production of more ASICs than they already have. If they encourage a cryptocurrency using a PoW scheme built around the ASIC design, they might be able to acquire more ASICs a year later at a lower price and without a minimum order quantity. You refer to a GPU price spike, but actually it was very minor - much less than the reduction in per-unit pricing for producing, say, 1k vs. 100k ASICs.
I mean that none of the 4 kinds of
I think this still wouldn't allow for efficient general-purpose computation while it'd expose the problem with small intermediate results (the outer I really don't expect to have a suggestion to you in the form of "just make this simple change" while we're discussing these pre-proposals. It'd take significant effort to possibly arrive at a good solution.
Not necessarily. In late 1990s, we could say "if Google's algorithms and business model were potentially profitable, wouldn't AltaVista be doing the same already?" and now we see by counter-example that a statement like this isn't necessarily true. |
The honest answer is that everybody is still figuring this out and trying to find both the best governance structure/dynamics involving ZcashCo, the Zcash Foundation, and various members of the Zcash community. A first step is for the Zcash Foundation's new Community Governance Panel to vote on measures to be taken by the Foundation regarding ASIC resistance. This is intentionally open ended. Well-reasoned, well-executed results from this process are likely to be integrated into ZcashCo's spec and The upshoot for this, answering your questions: the parameters and even definition of the ASIC-resistance goal are not dictated, but are left to your discretion (hopefully informed by community discussion and collaboration). It is perfectly reasonable to say "my goal will be foo, which is the best we can hope for in optimizing for bar given the technology constraints quux.". Of course, ground these choices as well as can in underlying goals such as consensus stability, decentralization, censorship-resistance, privacy, etc. Also yes, this remains perfectly acceptable and within scope for the grants, even if (for whatever reason) the particular approach ends up not integrated into Zcash. If it informs people on good ways to achieve important goals, and may be picked up by other privacy-preserving cryptocurrencies, then it's within scope. That said... Yes, we definitely need to see a concrete proposal and with deliverables -- as specific as you can, with the understanding that tentative directions may be adjusted as you learn more. |
|
The Zcash Foundation Grant Review committee has reviewed your pre-proposal, including the above discussion, to evaluate its potential and competitiveness relative to other proposals. Every pre-proposal was evaluated by at least 3 (and typically more than 4) committee members . The committee's opinion is that your pre-proposal is a promising candidate funding in this round, and the committee therefore invites you to submit a full proposal. |
|
Full proposal: openwall-zcash-grant-proposal-20180615.txt |
|
I just took a look at a few other (unrelated) proposals with the full-submission label, and I realize the $250k fund is probably going to be insufficient for all that would ideally be funded. As this proposal would be eating up a significant fraction of that (especially combined with the related ProgPoW proposal), I would be totally fine with it not getting funded for that reason. A reason why I make this proposal at all is that Zcash community appears to be desperate about the ASICs now, so I am reluctantly willing to temporarily switch away from my work on other projects (which are of greater long-term relevance to me and to Openwall) to GPU-friendly PoWs. But if this actually hurts the community through taking funds away from other desirable projects, then maybe I should not? Ideally, I think Zcash Foundation should look into allocating budget on top of the $250k for the PoW change related proposals. The need for PoW change and its urgency is a Zcash core issue, and IMHO it shouldn't disrupt the normal grants process for other projects building around Zcash. Just thinking out loud. |
|
#15, #25, and #38 combined will probably need $200k+ (there's no dollar figure for #38 yet, but based on 9 person-months I expect it's at least $100k). And they're complementary. While this is a lot of money on its own, it doesn't sounds to me like it's too much given the importance of PoW choice to Zcash and its current market capitalization. Yet it's certainly too much given the $250k grants budget and the many other interesting grant proposals (unrelated to PoW). There's also the declined #14, which doesn't need much money, but unfortunately it looks unsuitable for Zcash (as I understand, it wouldn't allow for verification on small devices, nor in smart contracts). |
|
I hear you. The final funding decisions are up to the Board, but the grant review committee will convey the topic clustering in its recommendations, is aware that studying PoW is of great importance, and has raised the matter of tight funding. The relevant ballot measures on ASIC resistance and embracing ASIC will provide further guidance on priorities. To be continued after we've reviewed the full submissions... |
|
Disclosure/update: I started to contribute to a not-yet-public Zcash fork that uses my yespower as the PoW scheme. Depending on funding I might receive from whichever project and the conditions for use of such funding, I'd like to proceed with further research and experiments in an attempt to improve yespower to make use of much more RAM in sequential memory-hard manner (not as pre-initialized ROM, which is already supported in yescrypt but doesn't achieve as much) while resisting DoS attacks on the network through a novel way to early-reject invalid proofs. The biggest drawback appears to be very low rate of accepted shares per day per user of a mining pool or higher cost to maintain a pool (and thus maybe higher fees, although I think 1% would be enough to cover the costs). If successful, this will get us closer to meeting Zcash’s original assumption of “how much mining you can do is mostly determined by how much RAM you have” (as the "Why Equihash blog post" in April 2016 said, but Equihash mostly didn't have that property). With the existing GPU mining community around Zcash, I think this new project is mostly orthogonal to Zcash proper, and my GPU-focused proposal as submitted here still stands. However, these new thoughts I have will likely replace the (unlikely) fallback to MTP that I included in my proposal - the fallback would be to this new approach instead. Also, it was said that Zcash could be interested in funding work relevant to other privacy-preserving coins, so in that context, depending on the grant review committee's preference, I wouldn't mind partially or fully re-focusing my proposal to work on the CPU+RAM focused PoW. |
|
@solardiz, we are about to finalize the grant funding recommendations. Are there any updates in your status or plans that we should be aware of? |
|
@tromer My proposal as submitted is focused on helping finalize ProgPoW (with only possible unlikely fallbacks to alternatives if there are major issues), so its current validity depends on the ProgPoW folks' project/proposal status and plans (I notice you're asking them for an update as well - great!) I doubt there's any change preventing the work as planned, my own proposal is still valid, and I can work on it if needed. That said, as I wrote in the comment above my own research interest is currently focused around improving CPU+RAM PoW. I not only "wouldn't mind" (as I wrote above), but would prefer "to work on the CPU+RAM focused PoW" instead of what's in my original proposal here. Same budget, similar schedule, different PoW finalization project (can provide more detail on request), different kind of PoW as the outcome (CPU+RAM friendly, GPU unfriendly, moderately ASIC unfriendly - to a lesser extent than ProgPoW because a typical computer's RAM bandwidth is lower than a GPU card's and because CPU+RAM is only a fraction of the production cost of a computer). You choose. |
|
@solardiz, current sentiment suggest that for it's best to keep this proposal focused on ProgPoW. However, can the scope explicitly include a systematic comparison with other prominent GPU-friendly ASIC-resistant PoW, such as updated Equihash (to be studied at more depth by #38) and Cuckoo? For those, it would be reasonable to cite others' analysis/claims rather than doing your own in-depth evaluation as you propose for ProgPoW; but putting things in comparative context will be very helpful. |
|
@tromer Thanks for relaying the current sentiment, it helps with my planning. Yes, I can include a comparison with Equihash especially if #38 is also funded and worked on. I know enough about Equihash to sanity-check others' analyses/claims. As to Cuckoo, while I happen to be credited in its source code for my suggestion to implement prefetching, which helped significantly speed it up, I don't understand its overall properties well. I don't expect to readily be able to sanity-check others' analyses/claims on Cuckoo. Yet, as you correctly imply, to keep my work focused and within schedule and budget, I'd have to rely on "others' analysis/claims rather than doing [my] own in-depth evaluation". Sure I can cite others' results (if/as available - I don't know what's actually available for Cuckoo now) and include a comparison if you ask me to, and fit it in the schedule and budget proposed here, but for Cuckoo I'd consider such comparison results unreliable unless I spend considerable effort studying Cuckoo on my own. |
|
I'm thrilled to inform you that the Grant Review Committee and the Zcash Foundation Board of Directors have approved your proposal, pending a final compliance review. Congratulations, and thank you for the excellent submission! Next steps: Please email [email protected] from an email address that will be a suitable point of contact going forward. We plan to proceed with disbursements following a final confirmation that your grant is within the strictures of our 501(c)(3) status, and that our payment to you will comply with the relevant United States regulations. We also wish to remind you of the requirement for monthly progress updates to the Foundation’s general mailing list, as noted in the call for proposals. Before the end of this week, the Zcash Foundation plans to publish a blog post announcing grant winners to the public at large, including a lightly edited version of the Grant Review Committee’s comments on your project. The verbatim original text of the comments can be found below. Congratulations again! Grant Review Committee comments:
|
|
@solardiz Hi! I wanted to reach out to see if you already have a channel you're using to work with/ask questions of the Zcash Company engineers regarding this project. If not, would you like for me to help you get some lines of communication opened via Rocketchat? |
|
Per formal grant agreement requirements, I'm posting here my e-mail address for community members to be able to easily contact me: <solar at openwall.com>. I'm also @solardiz on Twitter, but I don't use other social media much. @mms710 Hi, and thanks. Right now, my priority is actually receiving this funding, which is rapidly diminishing in value in the cryptocurrency market decline (as the amount is fixed in ZEC), whereas KYC for a business account with a major cryptocurrency exchange is time-consuming. (Note to self and wisdom to future Zcash grant applicants: should have prepared in advance.) My next priorities are "research on ProgPoW's heritage (such as the original Dagger Hashimoto and the codebase the current implementation of ProgPoW has been forked from)" (as the proposal says) and simultaneously communication with the ProgPoW folks (via the ifdefelse protonmail e-mail address they helpfully gave in their proposal comments, and which we've already used to communicate) to find out their current status and coordinate with their work. After the above is done (or at least the funding is received and further work is in progress), yes, I would also like to establish closer contact with the Zcash Company engineers who are specifically interested in this project. I do have some contacts, but if you can help find out who specifically is interested this time, that could help. This project doesn't look like it'd require close coordination, so perhaps e-mail will work most of the time (also to ensure all parties receive the communication), and only occasionally chat? Thanks again. |
|
@solardiz Thanks for the info! I would be your main point of contact so I can pull in engineers as needed for questions or help depending on who is available and interested. If you'd prefer email, you can email me at [email protected]. Otherwise, you can ping me (@mms) in the zcash-dev room in Rocketchat, depending on what you'd prefer. I would say that I'm more responsive via email than Rocketchat, but I'm trying to get better at that! |
|
The grant recipients are expected to deliver and post in here "a more comprehensive report 6 months after receiving funding", so here's one for this project summarizing the 6 monthly reports. Executive summary and personal impression: The project validated ProgPoW, improved understanding of its strengths and weaknesses, provided a plain C implementation of it, slightly cleaned up the upstream GPU implementation, and identified areas for further tweaks. Overall, ProgPoW is viable, but its use of GPU compute resources is far from optimal and its biggest advantage over Ethash isn't its "programmability" but rather its different than Ethash's reads from the DAG. The design and implementation of ProgPoW could both still use some invasive tweaks and enhancements for much better results, but the community's motivation to work on those (or even to accept them) appears to have waned. It's hard to stay motivated not knowing whether one's work would actually be made use of (by a major project like Ethereum) or not, and it's hard not to declare development done and not to move on since ProgPoW was introduced (with much enthusiasm) over a year ago. People appear to have mostly moved on. Monthly technical reports and their summaries:
|
|
@solardiz okay to close this issue, or do you anticipate wanting to comment here again? |
|
@sonyamann OK to close this issue. I might or might not comment here again, but there's no problem adding a comment to a closed issue if that is ever needed. |
I am creating this pre-proposal primarily to get something in by the deadline, without being sure whether this proposals/grants mechanism is the most appropriate for this specific problem given its scope and importance (to me, it feels like it may very well be beyond these grant rounds, but I don't know whether other funding mechanisms are currently possible). In other words, having this in buys us time to consider my/our (Openwall) involvement under this grants framework, and decide for or against it later.
Background/introduction
To provide some background/introduction, I previously worked on/for Zcash in 2016 resulting in this article published in November 2016:
http://www.openwall.com/articles/Zcash-Equihash-Analysis
where I predicted the ASICs as follows:
Please see the article for a lot more detail, including on different possible approaches to design of Equihash ASICs. "[A] factor of 10 to 100 improvement in energy efficiency and hardware cost over the most suitable commodity hardware" remains my current guesstimate as well. Thus, what happened now with the ASICs appearing given Zcash's high market capitalization is no surprise to me. In fact, I think they'll continue to improve into and along the 10x to 100x range.
Also in 2016, I helped define the terms of and was one of 3 judges for Zcash Miner Challenge:
https://zcashminers.org
I think that challenge was a success: we got much improved speeds of both CPU and GPU miners just in time for Zcash launch, all of those miners were Open Source, and as far as I'm aware there were no complaints about the process and judging. Although shortly thereafter even faster GPU miners appeared and those tended to be closed source with a dev fee, their additional improvement was relatively minor (the Challenge provided a 10x to 100x improvement over previous best implementations, whereas the post-Challenge improvement was 2x'ish) and the dev fees were small (IIRC, a popular miner had it at 2.5%). Surely things would have been way worse without the Challenge.
I haven't been involved in Zcash since then (not even as a user, and not mining), but I've been occasionally looking at it curiously from a distance. And I do just a little bit more than that by writing this now.
My other (indirect) involvement in cryptocoins / PoW is that I am the designer of yescrypt (which builds upon scrypt, but is also very different from scrypt), which is primarily a password hashing scheme and KDF, and we've released version 1.0 earlier this year:
http://www.openwall.com/yescrypt/
As it happens, 11 or so altcoins use an older revision of yescrypt, based off yescrypt 0.5 which was our first submission to Password Hashing Competition in 2014, as those coins' PoW scheme. They do this primarily for GPU resistance, although being GPU resistant does make them more susceptible to specialized ASICs (which would only have to compete with CPUs). I guess for minor altcoins have ASICs developed for them would be a good problem to have, as it'd only happen after reaching significant market capitalization.
Indeed, yescrypt is also used to hash passwords, and we (Openwall) assisted with some large deployments of yescrypt 0.9.x shortly prior to the 1.0 release, and we work on more. As you're reading this, quite possibly some of your passwords on some popular Internet services are currently hashed with yescrypt.
yescrypt is very flexible, with lots of tunable parameters (some of them are not exposed externally, but exist as compile-time low-level parameters of its underlying pwxform algorithm, also of my design). Although yescrypt was intended to be GPU-resistant (which is good for password hashing and key derivation on computers that don't necessarily have GPUs anyway), setting of those parameters differently can make it GPU-friendly (which is better for "ASIC-resistant" PoW of a cryptocoin with high market capitalization) while making extensive use of the GPUs' hardware (computation, on-die memories, on-card global memory).
I am also the original author of John the Ripper (JtR) password cracker, first released in 1996 and maintained ever since - now by a community for so-called "jumbo" versions of JtR. This is relevant since it's also about high-performance computation and attacks ("can you crack these hashes faster?"), and we currently support CPUs, GPUs (via OpenCL; previously also via CUDA, but we dropped that since OpenCL with occasional inline PTX asm mostly works just as well on NVIDIA), and FPGAs (currently reusing ZTEX 1.15y quad-FPGA boards, almost all of which started their life as Bitcoin miners back when this was profitable, but we'll need to re-target this to newer/larger boards and/or AWS F1 instances).
Of course, I worked on lots of other projects as well, but the above seem most relevant. Sorry for the bragging. I actually find it unfortunate that at this point I have more of a relevant background than of an actual ready-to-implement proposal.
I also briefly interacted with Zooko prior to Zcash, including online in Password Hashing Competition (where Zooko and I were among the many panel members) and in person at an event unrelated to cryptocurrencies. But I am not affiliated with Zcash.
What can realistically be achieved
As some of you noticed, I helped pre-review the nearby and much more complete pre-proposal of ProgPoW (#15), and I did this on my own time. I actually like a lot about that pre-proposal. I also dislike quite some things about it. And there are some I am not yet familiar with and would need to learn if I proceed to help review ProgPoW for real (which would require funding) or work on a new PoW for Zcash on my own or teaming up with others (which would also require funding). I need to more fully understand the current alternatives/competition to make an own even more competitive proposal, or to make an informed decision not to play. There are also specific criteria I have in mind that I'd subject a GPU-friendly PoW to if I were asked (and paid) to review one for real. (Yes, my GitHub comments, although they took me a few hours total as I needed to look up the source code, etc., are not a real review yet, by far.)
That pre-proposal claims "little opportunity for specialized ASICs to gain efficiency", and specifically "up to 1.2x gains in efficiency". I find this unrealistic, although that depends on what exactly we compare and in what terms, and how high the perceived incentive and budget of ASIC producers would be. For cryptocoin mining, we should ultimately be talking monetary returns vs. costs. In those terms, we'd need to factor in the supply chain inefficiencies/middlemen/markups associated with gaming GPU production and sales, vs. those of potential specialized ASICs for our PoW. I think this difference alone is at least 2x.
Realistically, I think we may target the 2x to 10x range of eventual specialized ASIC advantage (in energy consumption and hardware cost) over then-current most suitable gaming GPUs. It is possible that potential Zcash ASIC miner market is not yet large enough (especially under threat of [another] PoW change) to reach even the 2x mark given that we do our best job at a GPU-specific PoW, but we should not count on it long-term.
If we're within 10x, I'd consider that a project success anyway ("within expectations"), although I understand that many people mining Zcash with GPUs would be very unhappy (like they're unhappy about the current ASIC miner, which didn't even reach 10x yet). This means that this whole project might not be worth it, although OTOH we might never reach that 10x point or it might take long enough to get there for this PoW change to be worthwhile - this depends on many unknowns - so we could just go ahead and hope for the better while also being realistic about the worse.
Relevant reading:
https://blog.sia.tech/the-state-of-cryptocurrency-mining-538004a37f9b
What may need to be done (pre-proposal)
Off the top of my head:
Figure out Zcash's current goals and priorities
Identify what expertise is needed for further steps and build a team for this project
Re-research the currently available options for asymmetric PoW, along with their pros and cons
Consider, among other things, yescrypt ROM or alikes such as ASIC Resistant PoW #14 (con: also requires lots of memory for validation), building upon Dagger Hashimoto as in ProgPoW: A programmatic (dynamic) Proof-of-Work algorithm tuned for commodity hardware #15, creating an yescrypt-MTP or the like, and/or other options we might identify
Design, implement, tune/test the lower-level components such as yescrypt's pwxform settings or ProgPoW's math/merge chain specifics. This includes trying and making sure we get close to current GPUs' theoretical peak processing speeds (GB/s from/to global memory, "GMADs" as analogous to GFLOPS if we use 32-bit integer math instead of FP32, although per documentation for NVIDIA Volta we'd need to use both at once or we leave half the processing power unused) while nearly-fully occupying the register files and local/shared memories and having reasonable cache hit rates (really tough, especially across a wide variety of GPUs at once).
Work on other relevant components as well: integration into a full GPU miner with its host CPU code, validation on CPU
Some of these are sequential steps, some can/should proceed partially in parallel.
The text was updated successfully, but these errors were encountered: