最近在研究Raft共识算法,Raft算法大多数人应该也都了解,github上也有很多实现,但大多数都是使用Golang语言较多,比较出名的就是etcd
在这之前,需要了解一些概念:
- StateaMchines状态机
- RPC通信
- Term任期
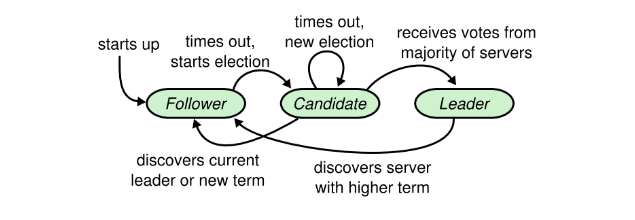
在给定的时刻,每个node的状态处于以下三种状态:
- leader
- follower
- candidate。
正常状态下集群中只有一个leader,其他都是follower
follower都是被动的,他们不会主动发出请求,只会简单的响应leader和candidate
leader负责处理所有客户端的请求:如果一个客户端向follwer发起请求,follwer会将请求重定向到leade
candidate顾名思义就是选举者的意思,只有follwer在超时时间内没有收到leader的请求的时候,会认为leader已经G了,follwer就自己化身选举者想成为leader
下面是paper里面的原图:
Raft node 之间的通信是通过RPC进行的,基础的共识算法只需要两种RPC:
- RequestVote:candidates在选举期间发起的
- AppendEntries:leader发起,用于replicate log entries 并作为一种 heartbeat 方式
Raft将时间划分为长度不固定的任期,任期用连续的整数表示,如下图:
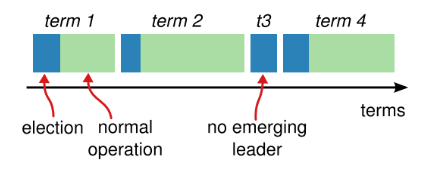
- 每个任期都是从选举开始
- 一个term内,最多只会有一个leader,这也是Raft比Paxos简单的原因之一,避免了多个网络分区有多个leader的复杂情况
- 有时候选举会失败,这种情况下该Term内就没有leader,上面也说了,“最多一个leader”
Raft使用一种heartbeat的机制来出发leader的election
node启动的时候是follower的状态;只要能从leader或candidate收到合法的RPC请求,就会一直保持在 follwer 状态
对于一个follower来说,开始选举的时候,
- 先增大Term
- 化身candidate
- 为自己投票,同时并发的向集群其他node发送RequestVote请求
- 它会处于Candidate状态,直到:
- 这个follower成功获选,-> leader
- 其他follower更快,-> follower
- 选举超时,再一次化身 -> candidate,
成功获选的条件
获取了集群中大多数node针对同一term的投票,那么这个candidate就获选成为leader
在等待投票期间,一个candidate可能会从其他node收到e一个AppendEntries RPC声称自己和leader,如果这个leader(log/entry中)的term:
- 大于等于当前candidate的currentTerm:承认是合法的就乖乖回归follower
- 小于当前candidate的currentTerm:拒绝这个RPC
避免无限循环的投票分裂
Raft会从一些固定时长(paper中是150-300ms)中选择一个选举的超时时间,这样就使每个node的超时时间分散
随机化机制也同样用于处理投票分裂。每个candidate在一轮选举开始时,会随机重置它的election timeout,等到timeout之后才开始发起新一轮的选举
现在选出一个leader了,可以开始服务客户端请求了:
- 每个客户端请求中都包含一条命令,将由状态机执行
- leader会将这个命令复制到自己的log,然后并发的发送RPC复制给其他node
- 复制success后,leader才会将这个 entry apply到自己的状态机,将执行结果返回给客户端
- 如果follower挂了,或者很慢,导致最终丢包:leader会无限重试AppendEntries的RPC请求,直到所有的follower都存储了所有的log entries
原图所示:
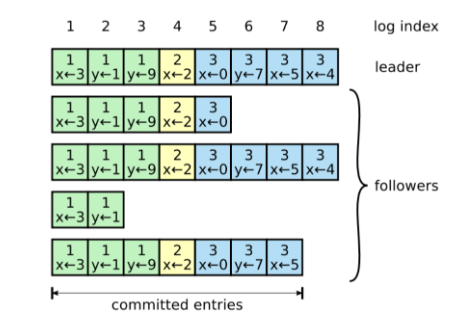
Log由log entry组成,每个entry都是顺序编号的
有这样一个经典的面试题:
Raft 是 如何保证一致性的
Raft保证commit的log都是持久化的。如何理解这句话呢
- leader将entry成功的复制到大多数follower上了,就算这个entry提交
- 这条被commit的
log entry前面的所有entry也将被commit
其实,Raft的log机制是为了保持各个node的log的高度一致性,它不仅简化的系统的行为,而且是保证安全(无冲突)的重要组件
如果两个log中的两个entry有完全相同的index和term,那么:
- 这两个entry包含了相同的命令:leader在任意给定的
term和log index的情况下,最多只会创建一个entry,并且其中在log中的位置永远不会发生变化(其实这里就应该明白entry和log的区别了:log就是上面图中一串的东西;而entry是发送来的包,里面是log中的一部分) - 这两个log中,从该index往前的所有entry都分别相同。这一点是通过AppendEntries中简单的一致性检查实现的:
- 在RPCh请求中,leader会带上log中前一个entry的index和term信息
- 如果
follower log中相同的index位置没有entry,或者有entry但是term不同,follower就会拒绝新的entry
上面所述都是在follower/leader正常的情况下进行,但是 leader 挂掉就会 导致logh不一致(leader还没有将其log中的entry都复制到其他node就挂了),以下就说说几种 follower log 和 leader log 不一致的几种可能性:
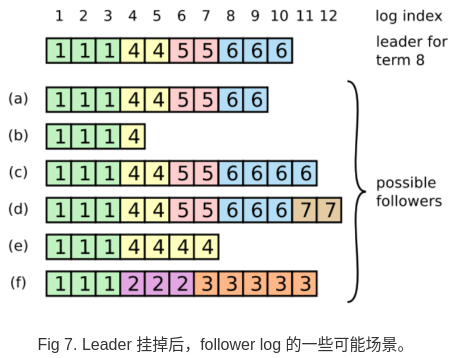
包括的情况有:
- 丢失记录 a-b
- 有额外的未提交的记录 c-d
- 或者以上两种情况 e-f
- log 中丢失或多出来的记录可能会跨多个term
Raft处理不一致的方法是:强制follower复制一份leader的log
这就意味着 follower log 中冲突的entry会被leader log中的entryu覆盖,其具体流程是:
- 找到leader和follower的最后一个共同认可的entry
- 将follower log中从这条entry,往后面的entries全部删掉
- 将leader log中从这条entry,往后面的entries全部同步给follower
整个过程都发生在AppendEntries RPC中的一致性检查环节
确保状态机以相同顺序执行相同命令
前面介绍了Raft如何选举leader以及如何replicate log entry的,但是到目前为止,已经描述了这些机制,还是不足以确保每个状态机以相同的顺序执行相同的命令(流),例如:
- 一个follower挂了
- 故障期间,leader提交了几个log entry
- leader挂了
- 这个follower恢复后被选举称了成的leader
就会导致:不同的状态机可能会执行不同的命令(流)
为了解决这个问题:
确保任何Terme内的leader都包含了前面所有Term内提交的entries
我们来给leader election加一个限制条件
包含前面所有Term内以提交entry的node才能被选举为leader
Raft采取了一种简单的方式:除非前面的所有term内的以提交的entry都已经在某个node上了(哪怕是没有提交),否则这个node不能成为leader。这意味着log entries只能从leader -> follower
这是如何做到的呢:
candidate发出的RequestVote RPC请求:
保证选出来的leader拥有集群的所有已提交的entries
具体实现上:判断哪个log更加的新:
- 如果term不同,term新的log新
- 如果term相同,index更大的log新
当前term+replicate数量过半,entry才能提交
新的leader如何提交之前term内遗留下来的,没有提交的,副本数量达到我们一直说的大多数的 entries 呢?
之前所说过:
只要entry已经存储到集群中大多数node上,leader就认为这个entry已经提交成功,准备应用到自己的状态机上了。
但是如果leader在应用的过程中就G了,下一个leader将承担这个entry的提交任务,这里就有一些新的问题,先看原图:
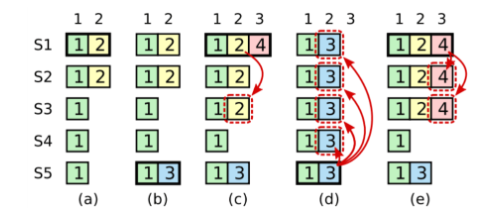
假如:
- a:S1是leader,他把entry复制到了S2上
- b:S1挂了,S5变成了新的leader,term=3;然后收到一条req
- c:收到过后还没来得及复制,就挂了;S1又变成了下一任的leader,term=4;然后S1继续同步之前那条没有提交的entry,这个时候,成功被同步到了S1/S2/S3上,还没有提交
接下来分为两种情况:
-
d:S1又G了,S5又成了新的leader,这种情况下,term=2的entry会被term=3的entry覆盖掉(这也就说明了,前面的term=2的entry不能commit,不然会被覆盖掉,就是不会commit就是了。如图) 必须要等S5再次收到req之后才能用后面的term=5的entry保护一起commit。如图:
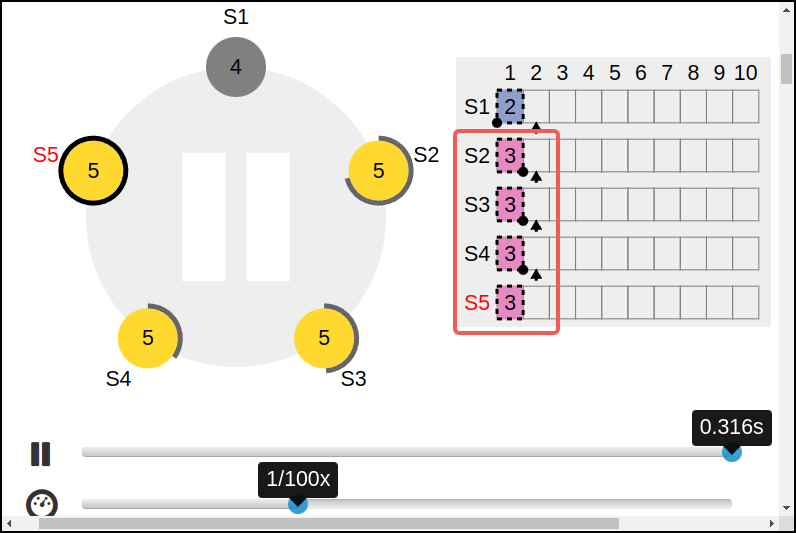
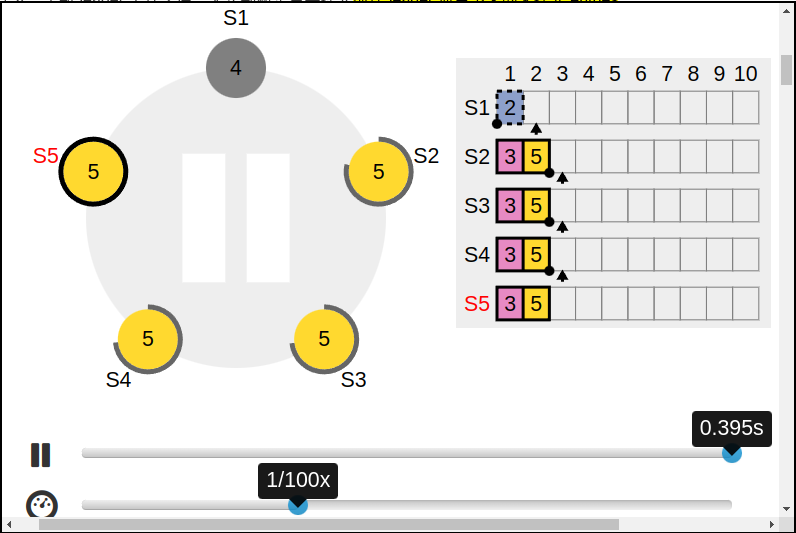
-
e:S1在挂点之前将term=4的一条新记录也成功的复制到大多数node上,这种情况下,即使S1挂了之后,S5也是无法赢得选举的:
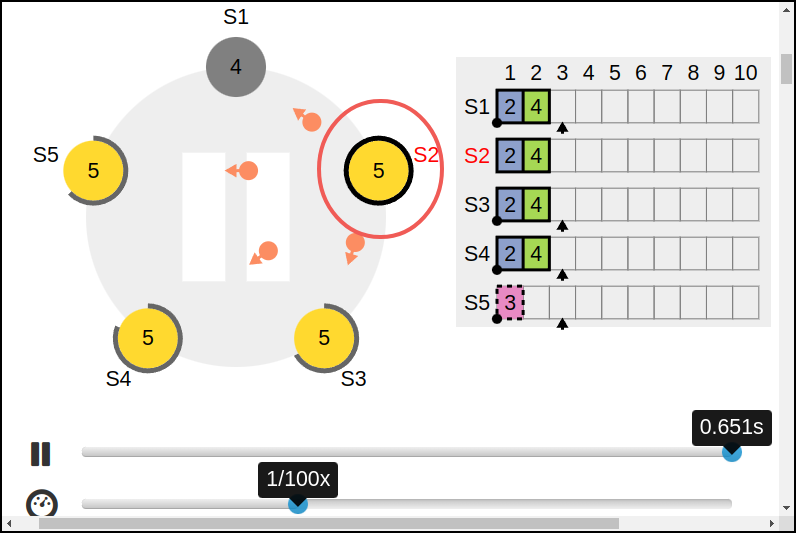
所以说Raft在解决上述:
term=2的entry不能commit,不然会被覆盖掉,就是不会commit就是了
的问题的时候,做了一个限制:
只有提交当前term的记录的时候,才能用 副本数量到达大多数 的方式
下面是关于代码的一些落地:
在初始化Raft的时候,会创建并初始化状态机:
val stateMachine = KVStateMachine(singleThreadVertx, this)
fun init(): Future<Unit> {
val promise = Promise.promise<Unit>()
**vertx.setTimer(5000) { logDispatcher.sync() }**
logDispatcher.recoverLog {
logs = it
vertx.runOnContext { promise.complete() }
}
return promise.future()
}
@NonBlocking
@SwitchThread(LogDispatcher::class)
fun sync() {
executor.execute {
**rf.metaInfo.force()
logFile.force(true)**
}
}会创建于一个定时器,每5s过去,就会执行sync()方法来落盘
注释解释的比较清楚了,部署Verticel过后执行了以下过程:
- 首先尝试向目标地址发送addServer请求
- 如果收到的响应表示请求失败(可能是因为目标不是leader)那么会更新目标地址并重新发送请求,直到请求成功为止
- 成功后,更新leaderId和对等node信息
- 初始化状态机和RPC处理器,并开始超时选举。如果发生错误,启动Promise失败并退出进程。
override fun start(startPromise: Promise<Void>) {
//预先触发缺页中断
raftLog("node recover")
CoroutineScope(context.dispatcher()).launch {
try {
if (addModeConfig != null) {
raftLog("start in addServerMode")
var targetAddress = addModeConfig.SocketAddress()
//首先尝试向目标地址发送addServer请求
var response = rpc.addServer(
targetAddress,
AddServerRequest(RaftAddress(raftPort, "localhost", httpPort), me)
).await()
while (!response.ok) {
//如果收到的响应表示请求失败(可能是因为目标不是领导者)
//那么会更新目标地址并重新发送请求,直到请求成功为止
targetAddress = response.leader.SocketAddress()
response = rpc.addServer(
targetAddress,
AddServerRequest(RaftAddress(raftPort, "localhost", httpPort), me)
).await()
}
raftLog("get now leader info $response")
//成功后,更新领导者ID和对等node信息
leadId = response.leaderId
peers.putAll(response.peer)
peers[response.leaderId] = RaftAddress(targetAddress).apply { httpPort = response.leader.httpPort }
}
} catch (t: Throwable) {
raftLog("addServerMode start error")
startPromise.fail(t)
exitProcess(1)
}
//初始化状态机和RPC处理器,并开始检查超时。如果发生错误,启动Promise失败并退出进程。
stateMachine.init()
.compose { rpcHandler.init(singleThreadVertx, raftPort) }
.onSuccess { startTimeoutCheck() }
.onSuccess { startPromise.complete() }
.onFailure(startPromise::fail)
}
}首先是超时过程:
新起一个协程执行
private fun startTimeoutCheck() {
CoroutineScope(context.dispatcher() as CoroutineContext).launch {
while (true) {
//超时时间设置为300-450之间
val timeout = (ElectronInterval + Random.nextInt(150)).toLong()
val start = System.currentTimeMillis()
delay(timeout)
if (lastHearBeat < start && status != RaftStatus.leader) {
//开始超时选举
startElection()
}
}
}
}超时过后就开始执行选举过程:
private fun startElection() {
becomeCandidate()
raftLog("start election")
val buffer =
RequestVote(currentTerm, stateMachine.getNowLogIndex(), stateMachine.getLastLogTerm())
//法定人数为一半+1 而peer为不包含当前节点的集合 所以peer.size + 1为集群总数
val quorum = (peers.size + 1) / 2 + 1
//-1因为自己给自己投了一票
val count = AtomicInteger(quorum - 1)
val allowNextPromise = Promise.promise<Unit>()
if (count.get() == 0) {
allowNextPromise.complete()
}
val allowNext = AtomicBoolean(false)
val allFutures = mutableListOf<Future<RequestVoteReply>>()
for (address in peers) {
val requestVoteReplyFuture = rpc.requestVote(address.value.SocketAddress(), buffer)
.onSuccess {
val raft = this
if (it.isVoteGranted) {
raftLog("get vote from ${address.key}, count: ${count.get()} allowNex: ${allowNext}}")
if (count.decrementAndGet() == 0 && allowNext.compareAndSet(false, true)) {
allowNextPromise.complete()
}
return@onSuccess
}
if (it.term > currentTerm) {
becomeFollower(it.term)
}
}
allFutures += requestVoteReplyFuture
}
allowNextPromise.future()
.onComplete {
raftLog("allow to next, start checking status")
val raft = this
if (status == RaftStatus.candidate) {
raftLog("${me} become leader")
becomeLead()
}
}
}选举过程就很简单了
-
先把自己变成candidate:
fun becomeCandidate() { currentTerm++ votedFor = me lastHearBeat = System.currentTimeMillis() status = RaftStatus.candidate }
-
发送RequestVoteRpc投票请求,当前node向peers里所有的node发送请求,这个过程是在for循环里执行的。先来看看RequestVoteRpc吧
override fun requestVote( remote: SocketAddress, requestVote: RequestVote ): Future<RequestVoteReply> { return try { raftRpcClient.post(remote.port(), remote.host(), requestVoteReply_path) .putHeader(server_id_header, rf.me) .`as`(BodyCodec.buffer()) .sendBuffer(requestVote.toBuffer()) .map { RequestVoteReply(it.body()) } } catch (e: Exception) { Future.failedFuture(e) } }
其实就是WebClient发起一次post请求。然后follower接收方将处理请求:
private fun requestVote(msg: RequestVote): RequestVoteReply { rf.lastHearBeat = System.currentTimeMillis() rf.raftLog("receive request vote, msg :${msg}") if (msg.term < rf.currentTerm) { return RequestVoteReply(rf.currentTerm, false) } val lastLogTerm = rf.getLastLogTerm() val lastLogIndex = rf.getNowLogIndex() rf.currentTerm = msg.term //若voteFor为空或者已经投给他了 //如果 votedFor 为空或者为 candidateId,并且候选人的日志至少和自己一样新,那么就投票给他(5.2 节,5.4 节) if ((rf.votedFor == null || rf.votedFor == msg.candidateId) && msg.lastLogTerm >= lastLogTerm) { if (msg.lastLogTerm == lastLogTerm && msg.lastLogIndex < lastLogIndex) { return RequestVoteReply(rf.currentTerm, false) } rf.votedFor = msg.candidateId rf.raftLog("vote to ${msg.candidateId}") return RequestVoteReply(rf.currentTerm, true) } return RequestVoteReply(rf.currentTerm, false) }
这个过程主要进行两个判断:
- term的判断
- 自己是否已经vote给其他的candidate
返回reply过后,candidate校验:
if (it.isVoteGranted) { //如果节点投了赞成票 isVoteGranted为true //显示已经得到的赞成票数量和是否允许进入下一轮 raftLog("get vote from ${address.key}, count: ${count.get()} allowNex: ${allowNext}}") //如果赞成票数量降到0,并且还没有进入下一轮,那么就会解锁allowNextPromise,允许进入下一轮。 if (count.decrementAndGet() == 0 && allowNext.compareAndSet(false, true)) { allowNextPromise.complete() } return@onSuccess }
至此,选举完成,变成leader:
allowNextPromise.future().onComplete { raftLog("allow to next, start checking status") val raft = this if (status == RaftStatus.candidate) { raftLog("${me} become leader") becomeLead() } } fun becomeLead() { status = RaftStatus.leader lastHearBeat = System.currentTimeMillis() nextIndexes = mutableMapOf() matchIndexes = mutableMapOf() peers.forEach { nextIndexes[it.key] = IntAdder(stateMachine.getNowLogIndex() + 1) matchIndexes[it.key] = IntAdder(0) } leadId = me; //添加一个空日志 论文要求的 addLog(NoopCommand()) //不断心跳 CoroutineScope(context.dispatcher() as CoroutineContext).launch { while (status == RaftStatus.leader) { broadcastLog() delay(heartBeat) } } }
/**
* 外部调用的一个接口所以要确保线程安全
*/
@NonBlocking
@SwitchThread(Raft::class)
fun addLog(command: Command, promise: Promise<Unit>) {
if (leadId != me) {
promise.fail(
NotLeaderException(
"not leader!",
peers[leadId]
)
)
return
}
stateMachine.addLog(command, promise::complete)
}
/**
* leader状态时client请求附加日志
*/
@NonBlocking
@SwitchThread(Raft::class)
fun addLog(command: Command, callback: () -> Unit) {
vertx.runOnContext {
//获取当前的日志索引
val index = getNowLogIndex() + 1
//创建一个新的日志条目并将其添加到日志中
val log = Log(index, rf.currentTerm, command.toByteArray())
logs.add(log)
//将这个日志条目添加到日志分发器中
logDispatcher.appendLogs(listOf(log))
if (command !is ServerConfigChangeCommand) {
//如果命令不是ServerConfigChangeCommand,那么将索引和回调函数添加到等待队列中
applyEventWaitQueue.offer(index to callback)
} else {
//这里特殊直接就apply
handleServerConfigChangeCommand(command, callback, index)
}
}
}