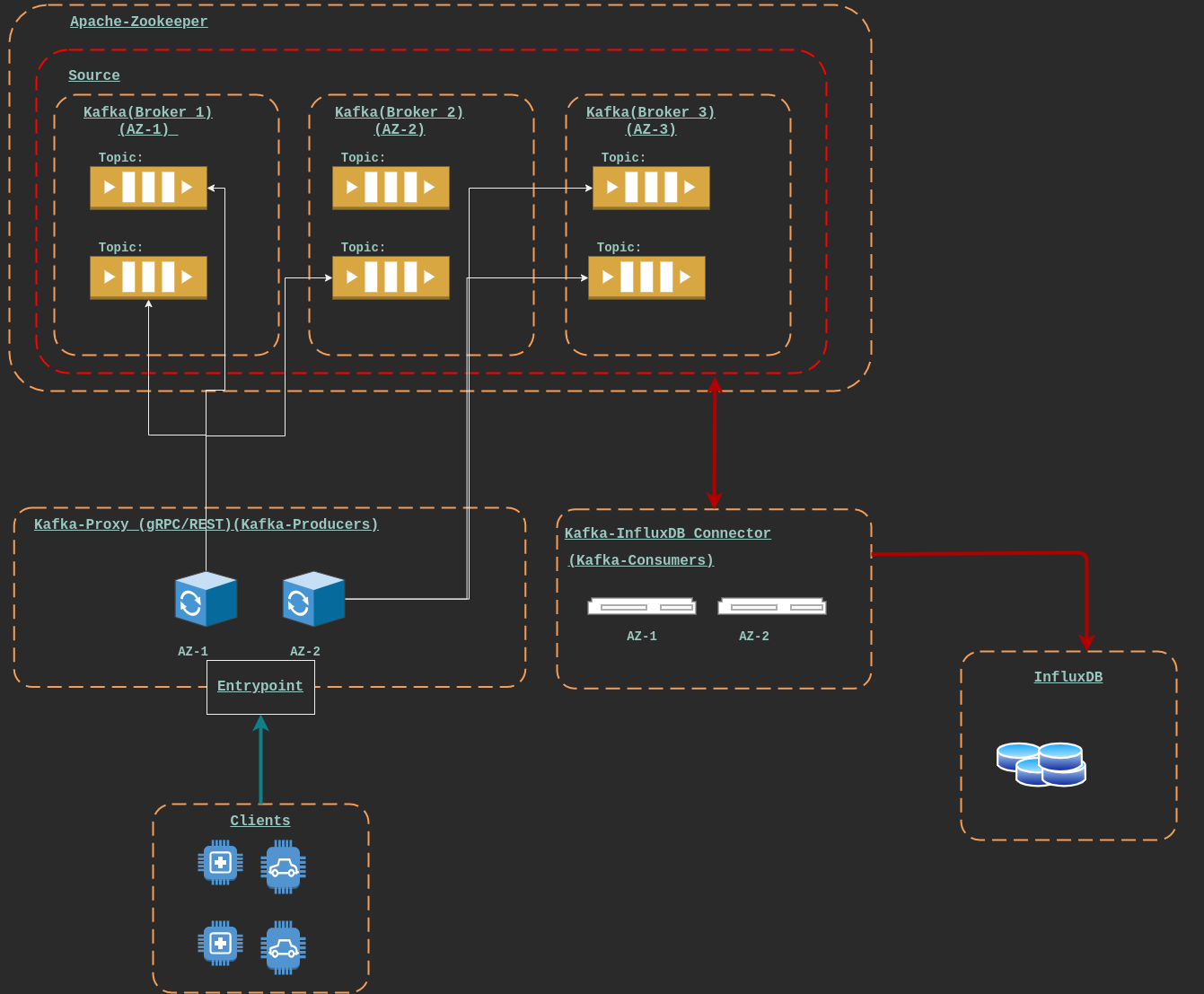
Hippo is a data ingestor service for gRPC and REST based clients. It publishes your messages on a kafka queue and eventually saves them to influxDB, it is build to be easily scalable and prevent SPOF for your mission-critical data collection.
High speed data ingestion is a big problem if you ask me, lets take the example of server level logs, say you have multiple microservices deployed in production and all of them are producing high quantity of logs and at a very large rate, how would you make sure that you capture each and every packet without loosing any of them and more importantly save them to a place where you can actually query them at a later stage for analysing, this is where hippo will shine, the gRPC/REST proxy and kafka brokers can be scaled, based on the load and then they will eventually save them to a write intensive InfluxDB and then take advantage of all the services build on top for analysing InfluxDB data check this
Also, while making this project I learnt so many things and it gave me an excuse to solve one of the problems that I face a lot, dealing with server logs.
These data points were obtained by running 1 instance of each service on a quad-core , 16 GB RAM pc.
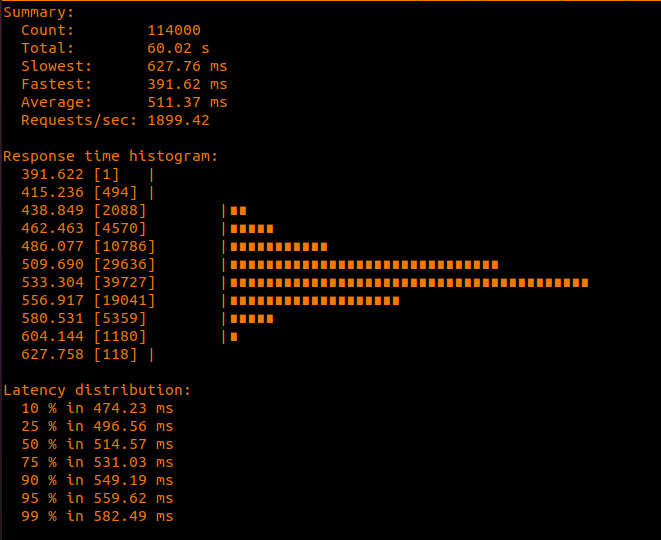
I used ghz as a benchmarking tool
ghz --insecure --proto kafka-pixy.proto --call KafkaPixy/Produce
-d "{\"topic\":\"foo\",\"message\":\"SSBhdGUgYSBjbG9jayB5ZXN0ZXJkYXksIGl0IHdhcyB2ZXJ5IHRpbWUtY29uc3VtaW5nLg==\"}" -c 1000 -n 100 -z 5m 127.0.0.1:19091| Tech | Use |
|---|---|
| apache-zookeeper | It manages different kafka brokers, choosing leader node , replacing nodes during failover. |
| apache-kafka | Messaging queue, queue of messages are stored as a TOPIC topics can span across different partitions and you have consumers to consume those messages and producers to put them on the queue |
| kafka-pixy | The gRPC/REST based proxy server to contact the kafka-queue on behalf of your applications |
| timberio/vector | A very generic software to take data from your SOURCE(files,Kafka,statsD etc. ) does aggregation , enrichment etc . on it and saves them to the SINK(DB, S3 , files etc.) |
| influxDB | A timeseries based DB |
These are just what I can think of right on top of my head.
-
Use a 3rd party paid service for managing your data collection pipeline but, in the long run you will become dependent and as the data grows your cost will increase manifold.
-
Create a proxy and start dumping everything on cache(Redis etc.) and create a worker to feed that to the database but, cache is expensive to maintain and there is only so much that you can store on the cache.
-
Directly feed to the database but, you will be bounded by query/secs and will not receive reliable gRPC support for major databases.
In order to run hippo, you need to configure the following-
kafka-pixy/kafka-pixy.yaml
Point to your kafka broker(s)
kafka:
seed_peers:
- kafka-server1:9092Point to your zookeeper
zoo_keeper:
seed_peers:
- zookeeper:2181vector/vector.toml
This .toml file will be used by timberio/vector (which is ❤️ btw) to configure your source (apache-kafka) and your sink(influxDB)
The proxy (kafka-pixy) opens up 2 ports for the communication.
| Port | Protocol |
|---|---|
| 19091 | gRPC |
| 19092 | HTTP |
The official repository does a great job ❤️ in explaining how to connect with the proxy server but for the sake of simplicity, let me explain here.
It can be done like this (here foo is the topic name and bar is the group_id)
- Produce a message on a topic
curl -X POST localhost:19092/topics/foo/messages?sync -d msg='sample message'
- Consume a message from a topic
curl -G localhost:19092/topics/foo/messages?group=bar
The official repository(which is awesome, btw) provides the .proto file for the client, just produce the stub for the language of your choice(they have helper libraries for go and python) and you will be ready to go.
For the sake of simplicity, I have provided a sample client.
Simply run docker-compose up to setup the whole thing
Some things that I can think of on top of my head -
-
Add a reverse-proxy(a load balancer maybe (?) ) that can communicate over to the pixy instances in different AZs
-
Configure
TLSin the pixy , add password protection tozookeeperand configure proper policies forinfluxdb -
Use any container orchestration tool (kubernetes or docker-swarm and all the fancy jazz) to scale up the servers whenever required.
Hippo can be used to handle high volume streaming data, some of the usecases that I can think of are -
-
Logging server logs produced by different microservices
-
IoT devices that generate large amount of data
-
Right now, the messages sent do not enforce any schema, this feature will be very useful while querying the influxdb (Add an enrichment layer to the connector itself, maybe (?))
-
Provide benchmarks
This project wouldn't have been possible without some very very kickass os projects 🔥


if(repo.isAwesome || repo.isHelpful){
StarRepo();
}