This repository implements a neural network-based model for road segmentation of images from the KITTI Road dataset using an approach based on the U-NET (encoder-decoder) architecture. In this Jupyter Notebook code, we have all the processes, from model creation to dataset splitting, training, validation, and testing on images and videos.
VGG-16 is a deep convolutional neural network originally designed for image classification tasks. In this implementation, we use VGG-16 as the encoding part (encoder) of our U-Net architecture to leverage VGG-16's feature extraction capabilities.
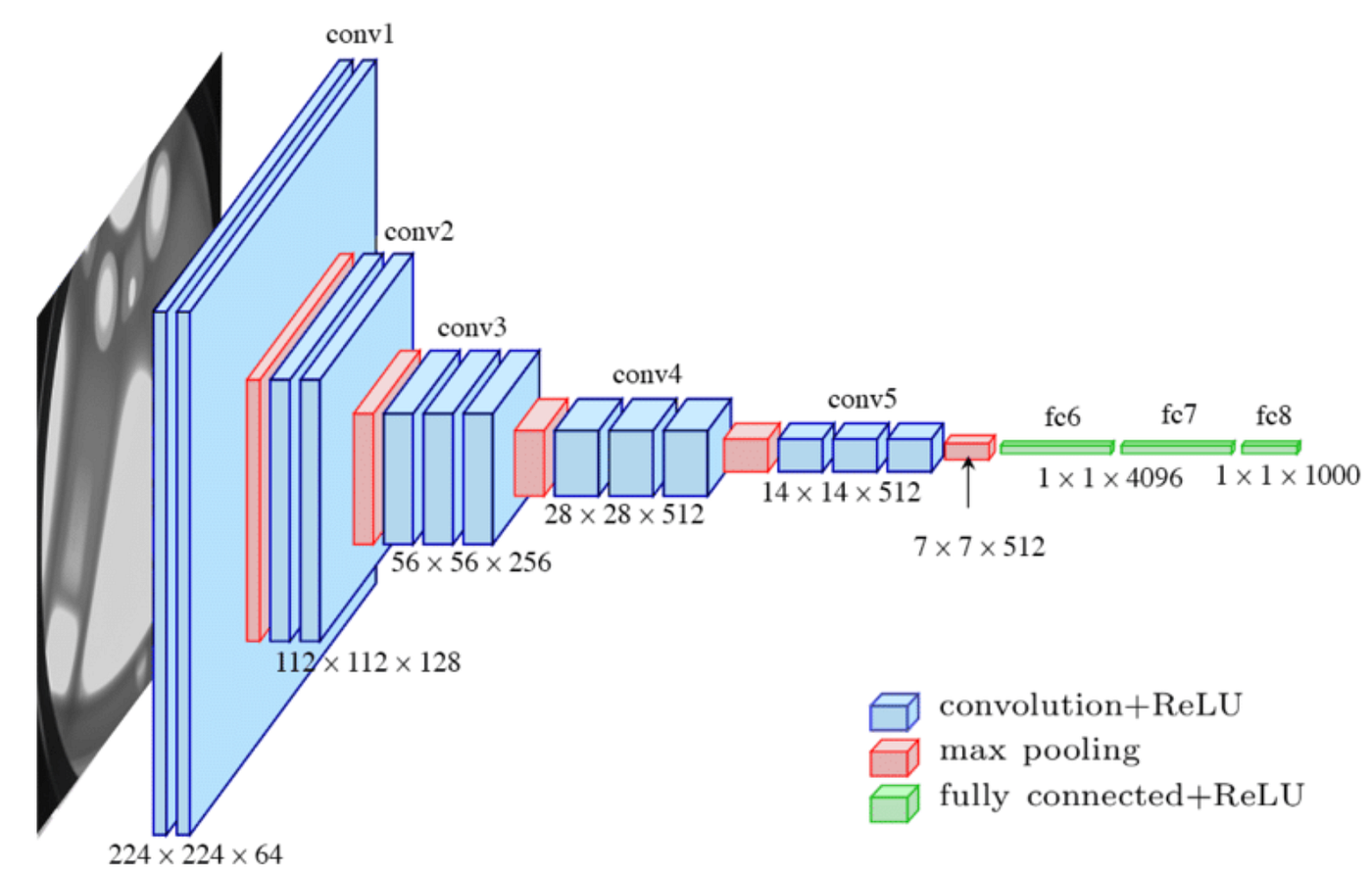
The U-Net architecture consists of two main parts: an encoder and a decoder. The encoder applies a series of convolutions and pooling to capture features from the image, while the decoder applies convolutions and upsampling to reconstruct the segmented image.
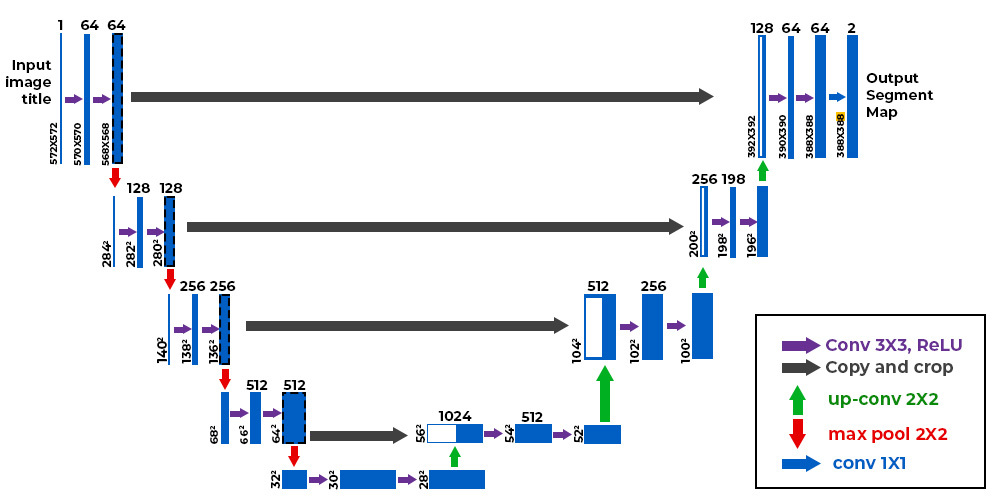
To facilitate training with limited computational resources, we used 128x128 pixel images. Below are examples of segmentation results:




- TensorFlow
- OpenCV
- Matplotlib
- Tqdm
Contributions are welcome! Feel free to open issues or pull requests.