{kind=link}
The Multiple Object Tracking (MOT) metrics "multiple object tracking precision" (MOTP) and "multiple object tracking accuracy" (MOTA) allow for objective comparison of tracker characteristics [0]. The MOTP shows the ability of the tracker to estimate precise object positions, independent of its skill at recognizing object configurations, keeping consistent trajectories, and so forth [0]. The MOTA accounts for all object configuration errors made by the tracker, false positives, misses, mismatches, over all frames [0].
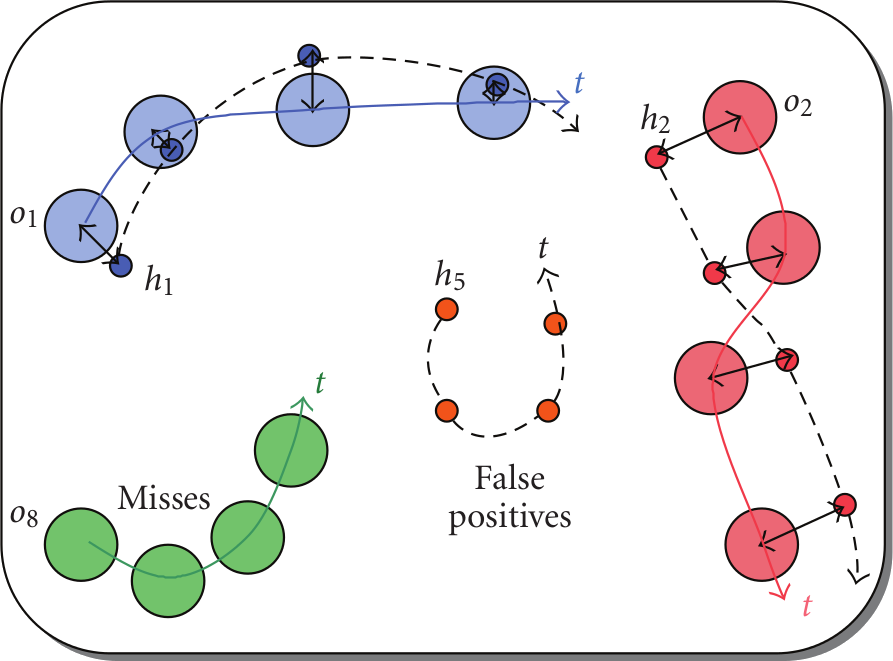
This is a python implementation which determines the MOTP and MOTA metrics from a set of ground truth tracks and a set of hypothesis tracks given by the tracker to be evaluated.
pymot can be used both as a script and a python class to use from your own code.
$ pymot.py -h
usage: pymot.py [-h] -a GROUNDTRUTH -b HYPOTHESIS [-c] [-v VISUAL_DEBUG_FILE]
optional arguments:
-h, --help show this help message and exit
-a GROUNDTRUTH, --groundtruth GROUNDTRUTH
-b HYPOTHESIS, --hypothesis HYPOTHESIS
-c, --check_format
-v VISUAL_DEBUG_FILE, --visual_debug_file VISUAL_DEBUG_FILE
-i IOU, --iou IOU iou threshold
You have to feed pymot.py with a groundtruth file and a hypothesis file.
Given groundtruth tracks and hypotheses according to input formats, pymot.py can be used as a script.
pymot comes with a MOTEvaluation class. Sample usage:
from pymot import MOTEvaluation
groundtruth = <see format below>
hypotheses = <see format below>
evaluator = MOTEvaluation(groundtruth, hypotheses)
evaluator.getMOTA()
evaluator.getMOTP()
evaluator.getRelativeStatistics()
evaluator.getAbsoluteStatistics()pymot.py expects json input files.
The groundtruth json format looks like this and is sloth compatible:
[
{
"frames": [
{
"timestamp": 0.054,
"num": 0,
"class": "frame",
"annotations": [
{
"dco": true,
"height": 31.0,
"width": 31.0,
"id": "sheldon",
"y": 105.0,
"x": 608.0
}
]
},
{
"timestamp": 3.854,
"num": 95,
"class": "frame",
"annotations": [
{
"dco": true,
"height": 31.0,
"width": 31.0,
"id": "sheldon",
"y": 105.0,
"x": 608.0
},
{
"dco": true,
"height": 38.0,
"width": 29.0,
"id": "leonard",
"y": 145.0,
"x": 622.0
}
]
}
],
"class": "video",
"filename": "/cvhci/data/multimedia/bigbangtheory/bbt_s01e01/bbt_s01e01.idx"
}
]The frames list contains a list of annotated frames. Frames from groundtruth and hypothesis are synchronized by the timestamp. Each annotation in the annotation list consists of bounding box values (x, y, width, height), and an id. The dco flag stands for do not care and can be used to mark hard to track targets, e.g. because of occlusion. Thus, a tracker which does not find the target will not be penalized, whereas a tracker which finds the target won't be punished (with a false positive) either.
[
{
"frames": [
{
"timestamp": 0.054,
"num": 0,
"class": "frame",
"hypotheses": [
{
"height": 31.0,
"width": 31.0,
"id": "sheldon",
"y": 105.0,
"x": 608.0
}
]
},
{
"timestamp": 3.854,
"num": 95,
"class": "frame",
"hypotheses": [
{
"height": 31.0,
"width": 31.0,
"id": "sheldon",
"y": 105.0,
"x": 608.0
},
{
"height": 38.0,
"width": 29.0,
"id": "leonard",
"y": 145.0,
"x": 622.0
}
]
}
],
"class": "video",
"filename": "/cvhci/data/multimedia/bigbangtheory/bbt_s01e01/bbt_s01e01.idx"
}
]The hypotheses json file format is equal to the groundtruth json file format, despite the missing dco attribute and the annotations key got renamed to hypotheses.
Besides MOTA and MOTP, pymot calculates the following performance measures:
- Lonely ground truth tracks (ground truth tracks without any overlapping hypothesis)
- Lonely hypothesis tracks (hypothesis tracks without any overlapping ground truth)
- False positives
- Misses
- Mismatches
- Recoverable mismatches. One ground truth track is covered by two different hypothesis tracks. Later steps in a tracking pipeline can easily fuse the two hypothesis tracks, e.g. by using identification. This is a novel performance measure.
- Non-recoverable mismatches. Two ground truth tracks are covered by a single hypothesis track. It is harder to split the hypothesis track into two tracks in later pipeline steps. This is a novel performance measure.
Lonely ground truth tracks 0
Total ground truth tracks 2
Lonely hypothesis tracks 0
Total hypothesis tracks 2
getAbsoluteStatistics()
{
"correspondences": 3,
"covered ground truth tracks": 2,
"covering hypothesis tracks": 2,
"false positives": 0,
"ground truth tracks": 2,
"ground truths": 3,
"hypothesis tracks": 2,
"lonely ground truth tracks": 0,
"lonely hypothesis tracks": 0,
"mismatches": 0,
"misses": 0,
"non-recoverable mismatches": 0,
"recoverable mismatches": 0,
"total overlap": 3.0
}
getRelativeStatistics()
{
"MOTA": 1.0,
"MOTP": 1.0,
"false positive rate": 0.0,
"mismatch rate": 0.0,
"miss rate": 0.0,
"non-recoverable mismatch rate": 0.0,
"recoverable mismatch rate": 0.0,
"track precision": 1.0,
"track recall": 1.0
}Corresponding ground truth annotations and hypotheses can be found if they are nearby in time. The sync_delta defaults to 0.001s to compensate for floating point rounding errors.
The best matching of all ground truth annotations to all hypotheses is found by Munkre's algorithm (also know as the Hungarian algorithm). It uses the intersection-over-union (IOU) ratio of bounding boxes. By default only bounding boxes with an IOU of more than 0.2 are considered for matching.
The subdirectory 3d contains a collection of scripts for 3D MOT scoring developed by Keni Bernardin for the CLEAR2007 evaluation [1].
MOTScore.pl computes the performance measures in the same way as pymot does, except for mapping groundtruth and hypothesis based on Euclidean distance.
The file format differs from pymot's. Please refer to the readme file and this whitepaper for the file format specification.
scoreAll.py is a wrapper around MOTScore.pl to work on a set of groundtruth label files and hypothesis files.
Please refer to its readme file.
pymot and the 3D MOT scoring script use the same underlying algorithm for tracking evaluation. We thus aim to make pymot capable of scoring 3D trackers and replace the 3D MOT scoring script. Please feel free to contribute.
- Markus Roth ([email protected])
- Martin Bäuml ([email protected])
- Mika Fischer ([email protected])
- Keni Bernardin ([email protected])
Feel free to report bugs and contribute new features.
[0] Keni Bernardin and Rainer Stiefelhagen. "Evaluating multiple object tracking performance: the CLEAR MOT metrics" J. Image Video Process. 2008, Article 1 (January 2008), 10 pages. DOI=10.1155/2008/246309 http://dx.doi.org/10.1155/2008/246309
[1] Stiefelhagen, Rainer, et al. "The CLEAR 2007 evaluation." Multimodal Technologies for Perception of Humans. Springer Berlin Heidelberg, 2008. 3-34. DOI=10.1007/978-3-540-68585-2_1 http://dx.doi.org/10.1007/978-3-540-68585-2_1