TechEmpower Performance Rating (TPR)
The following is a work-in-progress feature for the TFB project. This page will be moved within this Wiki if and when the feature described here is completed.
Using the upcoming composite scores for frameworks as a basis, we will be providing a new measurement of the performance of the hardware environment used to run our tests. Some lightweight arithmetic will massage the existing results to yield a simple numeric representation of an environment's relative performance. For example, the current Citrine environment used for our official results currently is measured at "416" with the current arithmetic (with placeholder weights), which is detailed in a later section of this page.
This hardware performance measurement may be of interest to a new audience of users who want to assess the abstract capacity of hardware in a web application server role. The utility of this is, at present, unknown. But the level of effort necessary to compute a hardware score is relatively minor, so we plan to offer it and see if it finds interest.
The following is a work-in-progress rendering of Citrine's TPR-3 score.
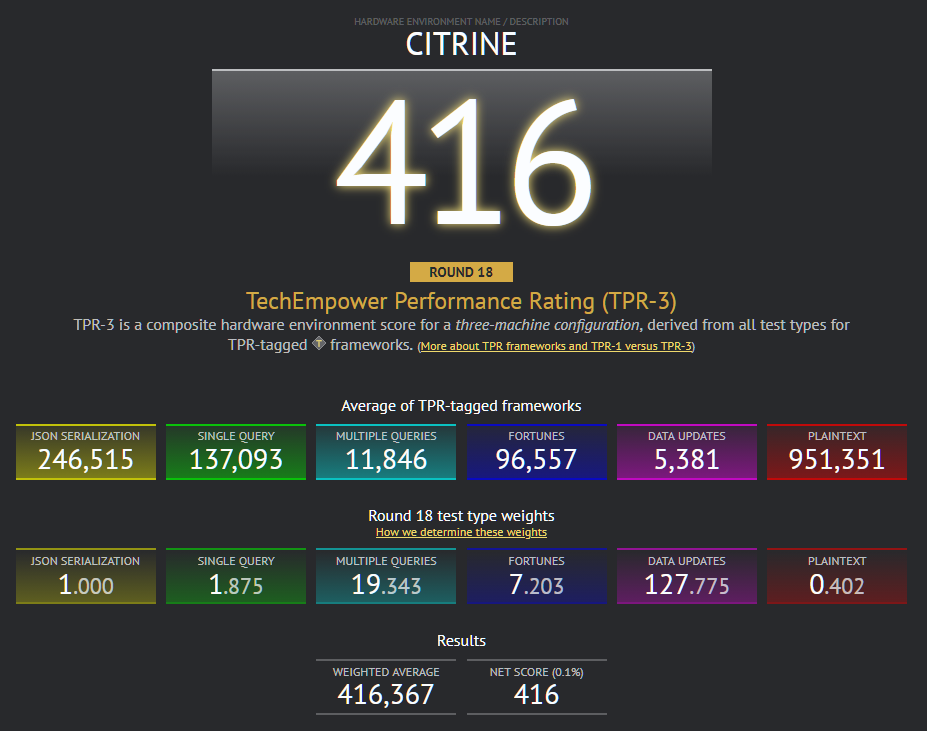
As a placeholder name that may or may not be replaced later, we are calling the resulting score a TechEmpower Performance Rating (TPR).
Historically, we have recommended that any measurement of web app framework performance be conducted in a three-machine configuration (application server, database server, and load generator) for two reasons:
- Separating application servers from their databases is a common practice.
- Load generation is simulating a client, so it should not be executing on the same machine and impacting the performance of the application server.
However, for a hardware performance measurement, these constraints no longer apply. Conversely, hardware measurement often has a different constraint: You often only have one unit of the machine being tested. So for hardware testing, we will encourage a single-machine configuration.
Scores from three-machine and single-machine configurations should not be compared. So we will identify them as two separate measurements:
- TPR-1, hardware performance measurement from a single-machine configuration.
- TPR-3, hardware performance measurement from a three-machine configuration.
Hardware performance scores will be associated with a specific "Round" of this benchmarking project. Unlike the traditional framework performance side of the house, where dynamism and continuous changes to the implementations are expected, the hardware measurement side will rely on a fair degree of stasis.
We will be separating the toolset from the framework implementations, creating two GitHub repositories where there is presently one. Doing so will allow us to create tooling that can pull a specific Round from the frameworks repository based on a commit label (e.g., "Round 19").
In other words, we want to be able to measure hardware using the very latest tooling, but using framework implementations as they existed at the time of an official Round. We'll encourage people to measure using the very latest published round. It is likely only Round 19 and above will be supported.
Currently, the full benchmark suite takes approximately 100 hours to complete, regardless of the hardware environment. This is due to the very large number of frameworks and permutations that exist today thanks to numerous community contributions. However, for measuring hardware performance, we want to provide a execution scenario that completes in less than 1 work day (less than 8 hours).
In order to reduce the total execution time in the hardware-testing scenario, we will introduce a new notion of flagging the frameworks that should be included when executing the hardware performance measurement scenario.
We have the following goals for TPR-tagging frameworks:
- We'd like approximately 10 such frameworks. This is a rough goal set to minimize execution time.
- The frameworks should cover a broad spectrum of languages and platforms.
- The implementations should be relatively steady, though they are not expected to be static. As described above, implementations will evolve between Rounds, and that is okay. Even the list of TPR-flagged frameworks may change between Rounds. But we nevertheless have a soft goal of some steadiness here. All else being equal, we'd rather not select highly-volatile frameworks for this purpose.
- Selected frameworks must implement all test types.
- The relative performance of the framework is not important for the purposes of hardware performance measurement, so we do not need to select the highest-performance framework for each language.
We seek community input on selecting frameworks for TPR. But a tentative list is:
- ASP.NET Core / C#
- Django / Python
- Express / JavaScript
- Laravel / PHP
- Phoenix / Elixir
- Rails / Ruby
- Spring / Java/JVM
- ?? / C++ or C
- ?? / Go
- ?? / Rust
It remains TBD whether the TPR-tagging will be at a framework/project level or at a permutation level. Presently, the TPR scoring algorithm will select the best performance for each test type from all permutations provided for a framework. However, supporting the full set of permutations may run counter to our effort to minimize execution time, so we may move the flagging to the permutations (e.g., allowing a framework's "Postgres" permutation to be indicated as part of TPR, skipping its MySQL permutation).
We will include a small icon to indicate frameworks that are TPR tagged and are therefore included in the hardware scoring.
In addition to migrating the toolset to a new separate repository, we will modify the toolset to allow for hardware measurement:
- Limit execution to a set of frameworks tagged by any tag ("TPR" will be used for this scenario).
- Provide a holding area in tfb-status, allowing results to be uploaded and visualized on the results web site. See Issue #19 in tfb-status.
- Changes to metadata generated for use by the results web site.
- Prompting for additional information about the execution scenario and hardware environment. We expect to ask for a name of the environment and a brief description, both of which would be rendered on the results web site.
- Recognize/understand the TPR-1 versus TPR-3 execution scenarios.
In addition to the obvious new "Composite scores" section and rendering of the TPR score, the results web site will see some minor changes:
- Current support for cross-round alignment of attributes and frameworks may be conceded. Right now, if you set your filters to view only frameworks written in Dart, for example, and navigate through previous Rounds, the filters will continue to apply. This is achieved by maintaining a consistent identifier for each attribute through time. This has been a cause for continuous challenges in this project and we may concede this capability to gain the ability to more easily render any arbitrary set of metadata at will.
- Revisiting the "None" framework. Potentially replacing the results' web site's notion of "Framework" with the concept known as "Project" within the Github source.
The TPR scoring algorithm is intended to be fairly simple.
We have the following goals for scoring hardware performance:
- Make the scores comparable on a per-Round basis. Results from environment A should be comparable to environment B as long as both measured the implementations from the same Round (e.g., Round 19).
- Fairly easy to reproduce by hand.
- Emphasize some tests, de-emphasize others. Specifically, we want to boost the importance of Fortunes and Updates while decreasing the importance of Single-Query, Multi-Query, and Plaintext. Single-Query and Multi-Query are very similar and without reducing their importance somewhat, the performance of database querying alone would drive a large portion of the score. Plaintext is reduced in performance because it's the least "real-world" among our test types.
Note these goals come from both the needs of TPR hardware scoring and composite scoring for frameworks.
As a result of the goals above, we are tentatively considering the following bias coefficients per test type:
- json: 1
- single query: 0.75
- 20-query: 0.75
- fortunes: 1.5
- updates: 1.25
- plaintext: 0.75
We will use the official results from our Citrine hardware environment as a "reference" environment. From these official reference results, we will:
- Filter down to the TPR-tagged frameworks.
- Compute an average RPS for each test type.
-
Normalize the magnitude of each of the test types to align with the JSON test type. E.g., if the JSON average were
150,000and the Fortunes average were10,000, the Fortunes test would be given a normalizing coefficient of15(10,000 x 15 = 150,000). - Apply the semi-fixed biases above. Taking the Fortunes example above, the resulting weight for Fortunes would be
15 x 1.5 = 22.5.
These per-round weights will be rendered on the results web site, along with a link to a wiki entry (like this one) describing the scoring algorithm.
From the above weighted scores for each test type, we:
- Sum and average the weighted scores for each test type.
- Divide by
1,000to yield a smaller number. E.g., 416. This is the final score for the hardware.