![]()
Ideal use is for datasets that can be managed within a pandas dataframe. Labels are applied to the selected number of records. Timestamped annotations can be saved in a dataframe for future use in any NLP/sentiment analysis project.
- Data practitioners
- Researchers
- Students
- Data enthusiasts
Anyone in need of a simple and intuitive product to label text data easily and efficiently will benefit from tortus.
Run the following to install:
pip install tortus
jupyter nbextension enable --py widgetsnbextensionImport the necessary modules into a Jupyter Notebook.
import pandas as pd
from tortus import TortusRead your dataset into a pandas dataframe.
movie_reviews = pd.read_csv('movie_reviews.csv')Create an instance of Tortus class. You are required to enter the dataframe and the name
of the column of the text to be annotated. Optional parameters include num_records,
id_column, annotations, random and labels.
tortus = Tortus(movie_reviews, 'reviews', num_records=3, id_column='review_id')Call the annotate method to begin annotations.
tortus.annotate()At any time, annotations can be stored into an object. This can be passed to annotations if further
annotations are required at a later time.
annotations = tortus.annotations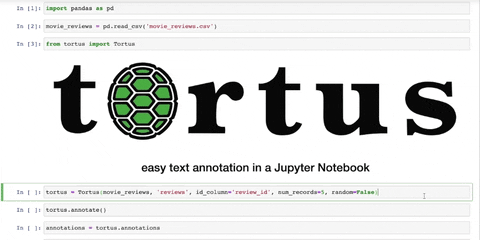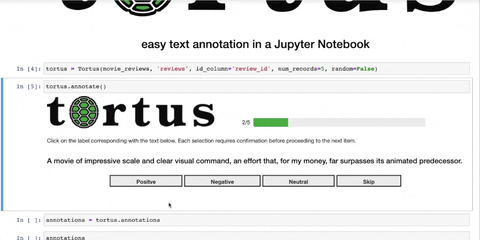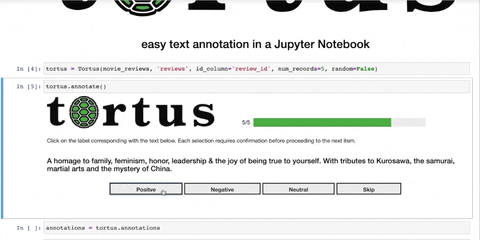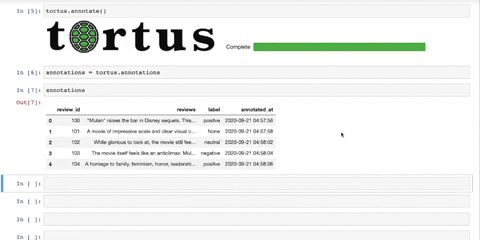
Click here to see a sample project using tortus.