Hagidoop is a lightweight version of Apache Hadoop developed by Jules Aubry and Robin Augereau (myself) as part of our Computer Science Engineering Degree at École Nationale Supérieure d'Électrotechnique, d'Électronique, d'Informatique, d'Hydraulique et des Télécommunications (ENSEEIHT).
The codes HdfsClient, HdfsServer, JobLauncher, Worker can be used independently.
For testing purposes, the scripts directory contains 2 scripts:
aio.sh: launches an instance ofHdfsServerandWorkerImplon each machine described in the configuration file located insrc/config/main.cfg, after copying the Java project and compiling it remotely on one of the machines.down.sh: stops the instances ofWorkerImplandHdfsServeron each machine and cleans the/tmp/datadirectory.
NB: These scripts only work with machines from ENSEEIHT for now.
The configuration file can be modified as follows:
- The first line contains the names of the machines.
- The second line contains the HDFS ports of the servers.
- The third line contains the RMI ports of the workers.
- The fourth line contains the size of the fragments in characters.
On each line, values must be separated by commas.
It is necessary to modify the name of the main machine in JobLauncher.java line 25 with the one from which you launch the usage scripts.
To evaluate the performance of this data distribution system, we conducted a series of tests:
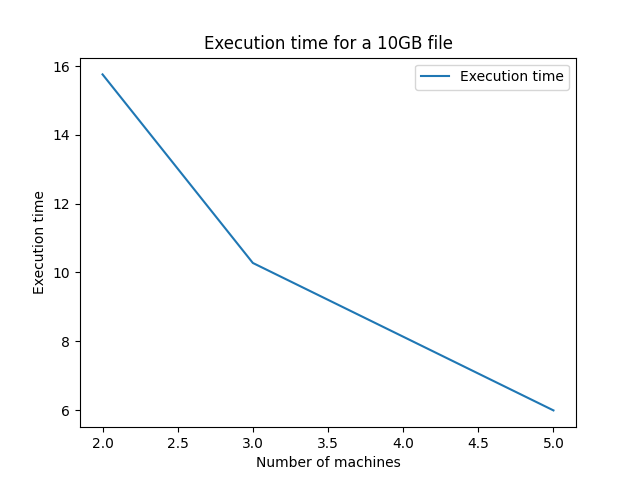
This figure shows the variation of the execution time of Hagidoop based on the number of machines used for fragment distribution. The size of the files and fragments was kept constant. It can be observed that distributing the workload across a greater number of computers results in faster execution. This confirms the relevance of the adage "divide and conquer."
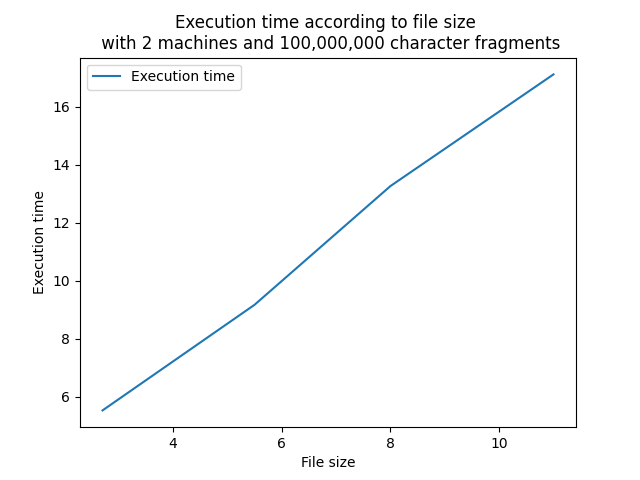
This graph represents the evolution of the size of the main files sent to HDFS. A linear trend is observable, which seems logical given that the execution time evolves linearly with the size of the files. The larger the file, the longer the execution time. The slope of the curve, calculated at 1.303, confirms this linear relationship between file size and execution time.
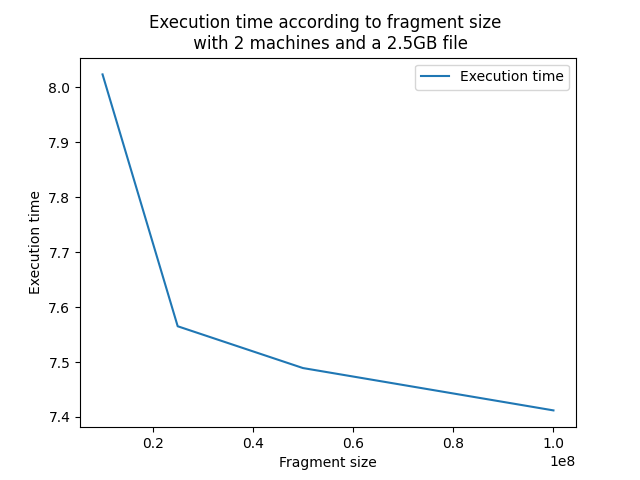
This graphical representation examines the variation in the size of the fragments sent for processing to the machines. It can be observed that the larger the size of the fragments, the faster the execution. This can be interpreted by considering that increasing the size of the fragments leads to a decrease in the number of threads on the different machines, thereby freeing up more resources. However, it is interesting to note that simply creating more threads of smaller size does not necessarily accelerate execution. It is crucial to find an optimal balance between the number of threads and the size of the fragments.