- MASTER-Paddle
基于 RNN 的编码器-解码器结构在场景文本识别方面已经取得了巨大成功,然而,基于 RNN 的局部注意机制由于编码特征之间的高度相似性会导致注意力混淆,从而导致注意力漂移问题(attention-drift problem)。
此外,基于 RNN 的方法由于并行性差,所以训练效率较低。受 GCNet 中采用的全局上下文的有效性以及 Transformer 在 NLP 和 CV 中取得的巨大成功的启发,我们提出了 MASTER(MultiAspect non-local network for irregular Scene TExt Recognition),以实现对不规则场景的高效准确的文本识别。
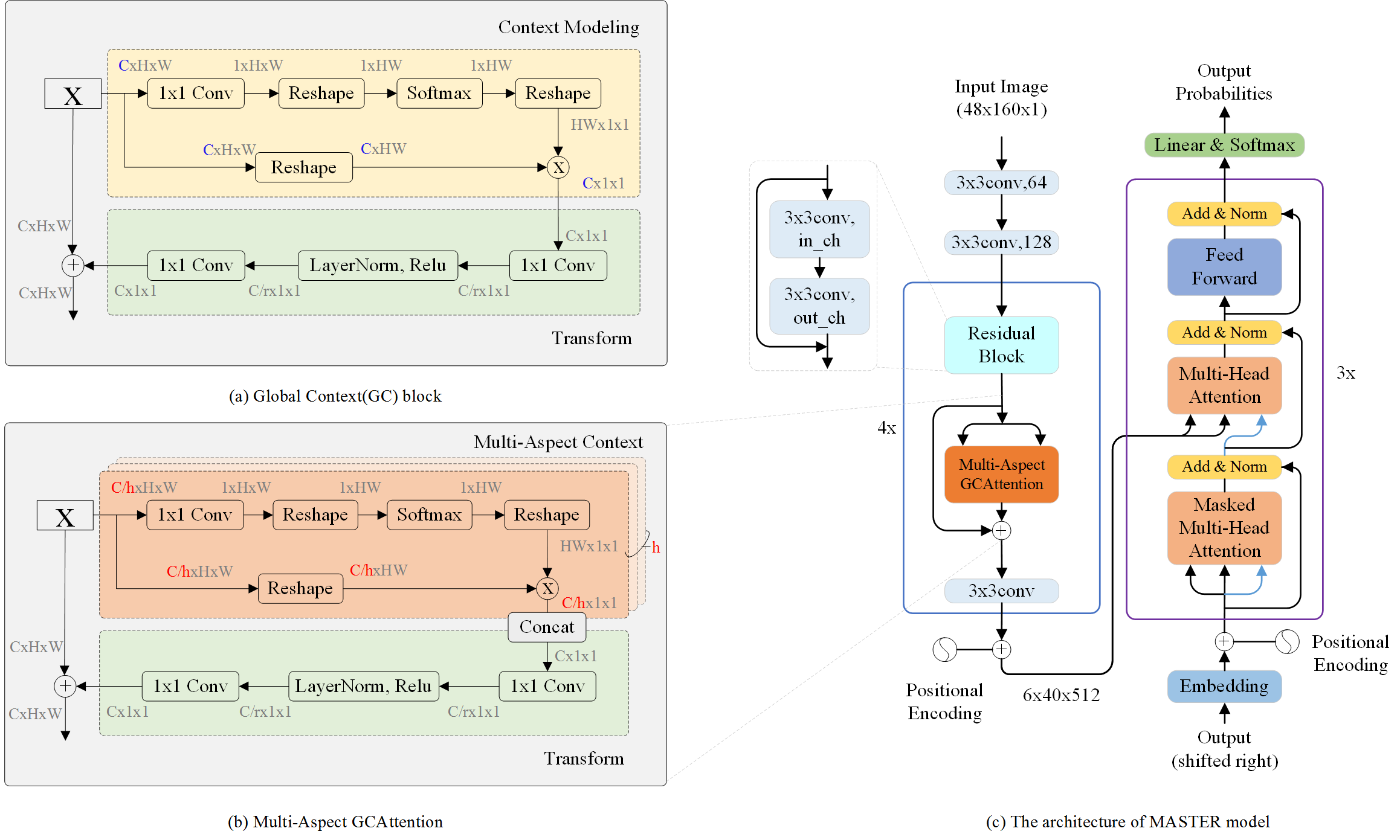
- 本文提出了一种新的多头注意力模块,并将其融合到传统的 CNN backbone(ResNet-31)中,从而使特征提取器能够对全局上下文建模。
- 在推理阶段,本文引入了基于内存缓存的解码策略,以加快解码过程。主要方法是删除不必要的计算并缓存以前解码的一些中间结果。
论文链接:MASTER: Multi-Aspect Non-local Network for Scene Text Recognition
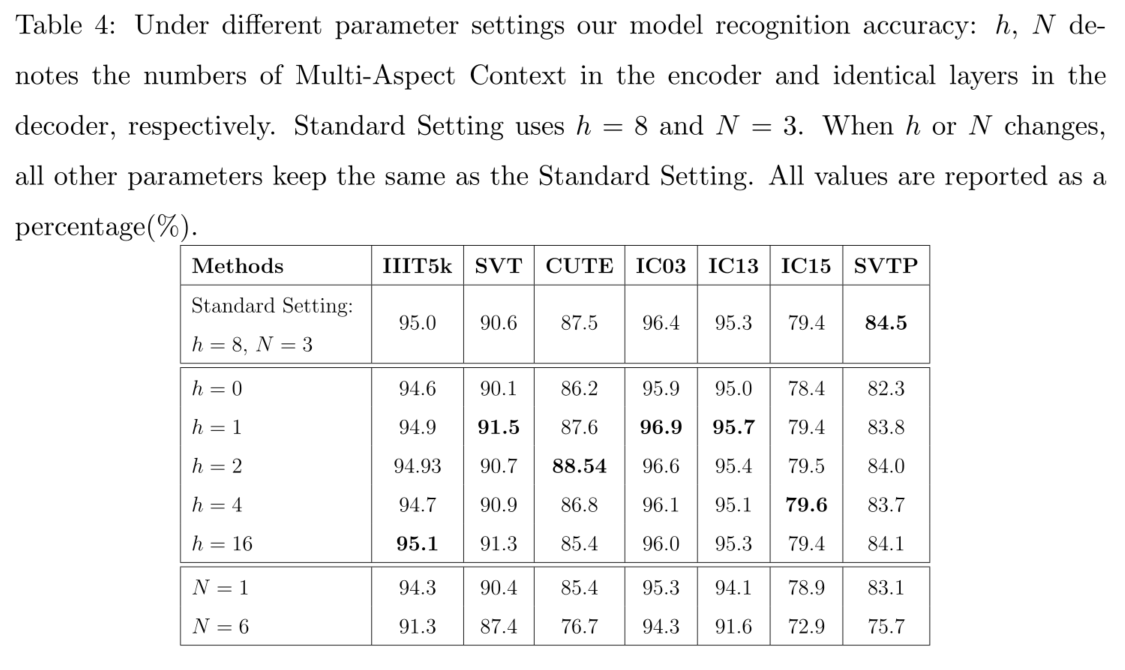
参考官方开源的 pytorch 版本代码 https://github.com/wenwenyu/MASTER-pytorch,基于 paddlepaddle 深度学习框架,对文献算法进行复现后,本项目达到的测试精度,如下表所示:
| 数据集 | IIIT5K | SVT | IC03 | IC13 | IC15 | SVTP | CUTE | avg |
|---|---|---|---|---|---|---|---|---|
| paddle 版本精度 | 93.6 | 91.5 | 96.16 | 96.1 | 82.7 | 84.96 | 84.4 | 89.89 |
| 参考文献精度 | 95.0 | 90.6 | 96.4 | 95.3 | 79.4 | 84.5 | 87.5 | 89.81 |
超参数配置如下:
详见
MASTER-Paddle/configs/config_lmdb_dist.json
| 超参数名 | 设置值 | 说明 |
|---|---|---|
| distributed | true | 强烈推荐使用多卡训练 |
| local_world_size | 4 | 4 卡刚刚好 |
| local_rank | 0 | 主卡 |
| n_class | 62 | 文本类数:10 个阿拉伯数字 + 52 个区分大小写的英文字母 + 4 个文档描述符 |
| with_encoder | false | with_encoder? false |
| model_size | 512 | 编码器的输出尺寸 |
| ratio | 0.0625 | |
| dropout | 0.2 | dropout |
| feed_forward_size | 2048 | dff 前馈模块设置为 2048 |
| multiheads | 8 | 多头注意力数是 8 |
| batch_size | 128 | bs = 128 单卡占用不到 16 GB 显存 |
| num_workers | 2 | dataloader workers,太大会内存溢出 |
| epochs | 16 | 论文说训了 12 个 epoch,事实上 5 个 epoch 之后训练基本稳定 |
| lr | 0.0004 | 4 卡并行情况下 lr=0.0004。单卡情况下 lr=0.0001,全程保持不变 |
| lr_scheduler | null | lr 全程保持不变 |
| img_w | 160 | 图片裁剪宽度 |
| img_h | 48 | 图片裁剪高度 |
数据集链接:百度网盘 data_lmdb_release.zip,提取码:rryk,下载整个 data_lmdb_release 文件夹。
本项目使用的是原文作者制作的文本识别数据集合集:data_lmdb_release.zip,其中包含以下内容:
- training datasets:MJSynth (MJ) 和 SynthText (ST),总数 12747394 个。
- validation datasets:训练集 IC13、IC15、IIIT 和 SVT 的合集。
- evaluation datasets:基准评估数据集,包括 IIIT、SVT、IC03、IC13、IC15、SVTP 和 CUTE。
- 硬件:
-
x86 cpu(RAM >= 16 GB)
-
4 × Tesla V100 GPU(VRAM per node >= 16 GB)
宽油劝退:单卡训练会好久 🐶,最多是用于 debug
-
CUDA + cuDNN
-
- 框架:
- paddlepaddle-gpu==2.1.2
- 其它依赖项:
- pandas==1.0.5
- numpy==1.19.2
- tqdm==4.47
- lmdb==1.2.1
- Distance==0.1.3
- Pillow==7.2.0
解压 data_lmdb_release/data_lmdb_reupload.zip,然后会得到如下的数据集目录:
├── data_lmdb_release # 解压出来的根目录
├── evaluation # 测试集
├── CUTE80
├── IC03_860
├── IC03_867
├── IC13_857
├── IC13_1015
├── IC15_1811
├── IC15_2077
├── IIIIT5k_3000
├── SVT
├── SVTP
├── training # 训练集
├── MJ
├── MJ_test
├── MJ_train
├── MJ_valid
├── ST # 训练集
├── data.mdb
├── lock.mdb
├── validation # 验证集
├── data.mdb
├── lock.mdb
在 configs/config_lmdb_dist.json 中修改训练配置
PyTorch 源码的默认配置是跑不起来的,比如
local_rank=-1在多卡训练的时候代码会对这个变量做判断,然后跳过创建输出文件夹的一段代码,导致模型没有保存任何东西。一开始n_class=-1也是不对的,这个变量要指定训练集中出现的所有字符的类数,论文指出有 66 类。lr=0.0004是 4 卡训练的配置,单卡是 0.0001。epochs=16,论文指出 4 卡训练 12 个 epochs 即可完成。若要单卡训练(debug),只需设置"distributed":false。
准备好 4 张 V100,运行以下命令从零开始训练 MASTER:
python -m paddle.distributed.launch train.py -c configs/config_lmdb_dist.json
如果你使用 AI Studio 脚本训练,需要在 shell 脚本中在运行训练之前把数据集解压:
#!/bin/bash
pip install lmdb distance
SRC_DIR=/root/paddlejob/workspace/train_data/datasets/data111037/data_lmdb_release.zip
TO_DIR=/root/paddlejob/workspace/train_data/datasets/
unzip -d $TO_DIR $SRC_DIR
python -m paddle.distributed.launch --gpus '0,1,2,3' MASTER/train.py -c MASTER/configs/config_lmdb_dist.json如果训练中断,并且保存了模型,重启训练时可以加上 --resume path/to/checkpoint,训练会从指定的模型重启训练。
比较耗时,需要使用 GPU。使用 V100 预测完测试集大约耗费 13 分钟。
训练好的模型以及测试集可到百度网盘自取:ckpts/model_best.pdparams,提取码:opkk。
其中的 evaluations.zip 是从 data_lmdb_release 数据集的 evaluation 中读取出来的 jpg 图片及其标签,用于测试。
指定模型的路径和解压后的 evaluations 文件夹:
# test
python MASTER-paddle/test.py --checkpoint path/to/model_best.pdparams \
--evaluation path/to/evaluations \
--is_lmdb_folder 0 \
--output_folder test_output/ \
--num_workers 4 \
--batch_size 512预测完测试集中一个子集的结果会输出到 [subset]_pred.json,保存在 output_folder 指定的文件夹下(test_output),其结果示例如下:
[{"filename": "001.jpg", "result": "BEACH", "pred_score": 0.9915353655815125}, {"filename": "002.jpg", "result": "RONALDON", "pred_score": 0.8017494082450867}]最新预测结果及其标签文件详见 MASTER-paddle/test_output/
需要先运行上面的 Testing 得到测试集的预测结果之后才能运行 Evaluation 来计算准确率。也可以直接使用 MASTER-paddle/test_output/ 中的最新预测结果验证精度。
运行:
# evaluation
!python MASTER-paddle/utils/calculate_metrics.py --predict-path test_output/ --label-path path/to/evaluations/
├── assets # 图片
├── configs # 配置文件
├── data # 一些 examples
├── data_utils # 加载数据集的工具代码
├── logger # 日志 logger 工具代码
├── logs # 日志
├── models # 网络结构定义
│ ├── backbone.py # 骨干 CNN 网络 ResNet-31
│ ├── context_block.py # context_block
│ ├── initializers.py # 借鉴 pytorch 的参数初始化函数
│ ├── master.py # MASTER 主网络
│ ├── transformer.py # transformer 模块
├── tests # 测试代码
├── trainer # 训练代码
├── utils # 工具代码
├── LICENSE # 开源协议
├── README.md # 主页 readme
├── requirements.txt # 项目的其它依赖
├── test.py # 启动预测
├── train.py # 启动训练
见 二、复现精度
见 五、快速开始
训练的 log 详见 train_logs/trainer-0.log,
执行训练开始后,将得到类似如下的输出:
[2021-10-12 18:46:00,739 - train - INFO] - Distributed GPU training model start...
[2021-10-12 18:46:00,739 - train - WARNING] - You have chosen to benchmark training. This will turn on the CUDNN benchmark settingwhich can speed up your training considerably! You may see unexpected behavior when restarting from checkpoints due to RandomizedMultiLinearMap need deterministic turn on.
[2021-10-12 18:46:00,739 - train - INFO] - [Process 2578] world_size = 4, rank = 0
[2021-10-12 18:46:27,278 - train - INFO] - Dataloader instances have finished. Train datasets: 12747394 Val datasets: 6992 Train_batch_size/gpu: 128 Val_batch_size/gpu: 128.
[2021-10-12 18:46:28,274 - train - INFO] - Model created, trainable parameters: 54653557.
[2021-10-12 18:46:28,275 - train - INFO] - Optimizer and lr_scheduler created.
[2021-10-12 18:46:28,275 - train - INFO] - Max_epochs: 16 Log_step_interval: 1 Validation_step_interval: 12000.
[2021-10-12 18:46:28,275 - train - INFO] - Training start...
[2021-10-12 18:46:28,275 - trainer - INFO] - [Process 2578] world_size = 4, rank = 0, n_gpu/process = 1, device_ids = [0]
[2021-10-12 18:46:40,308 - trainer - INFO] - Train Epoch:[1/16] Step:[1/24898] Loss: 5.889343 Loss_avg: 5.889343 LR: 0.00040000
[2021-10-12 18:46:41,351 - trainer - INFO] - Train Epoch:[1/16] Step:[2/24898] Loss: 6.429784 Loss_avg: 6.659563 LR: 0.00040000
[2021-10-12 18:46:42,409 - trainer - INFO] - Train Epoch:[1/16] Step:[3/24898] Loss: 5.376784 Loss_avg: 5.565304 LR: 0.00040000
[2021-10-12 18:46:43,452 - trainer - INFO] - Train Epoch:[1/16] Step:[4/24898] Loss: 5.122001 Loss_avg: 5.404478 LR: 0.00040000
[2021-10-12 18:46:44,505 - trainer - INFO] - Train Epoch:[1/16] Step:[5/24898] Loss: 4.696676 Loss_avg: 4.262918 LR: 0.00040000
...
[2021-10-29 22:29:25,506 - trainer - INFO] - Train Epoch:[3/16] Step:[23998/24898] Loss: 0.023410 Loss_avg: 0.018408 LR: 0.00040000
[2021-10-29 22:29:26,575 - trainer - INFO] - Train Epoch:[3/16] Step:[23999/24898] Loss: 0.020146 Loss_avg: 0.018408 LR: 0.00040000
[2021-10-29 22:29:27,641 - trainer - INFO] - Train Epoch:[3/16] Step:[24000/24898] Loss: 0.014127 Loss_avg: 0.018408 LR: 0.00040000
validate in epoch 3
[2021-10-30 06:14:34,656 - trainer - INFO] - [Step Validation] Epoch:[3/16] Step:[24000/24898] Word_acc: 0.961988 Word_acc_case_ins 0.976946Edit_distance_acc: 0.980846
[2021-10-30 06:14:36,834 - trainer - INFO] - Saving checkpoint: /root/paddlejob/workspace/output/models/MASTER_Default/example_1027_102421/checkpoint-epoch3-step24000.pdparams ...
[2021-10-30 06:14:42,358 - trainer - INFO] - Saving current best (at 3 epoch): model_best.pdparams Best word_acc: 0.961988
[2021-10-30 06:14:43,426 - trainer - INFO] - Train Epoch:[3/16] Step:[24001/24898] Loss: 0.004725 Loss_avg: 0.018407 LR: 0.00040000
[2021-10-30 06:14:44,489 - trainer - INFO] - Train Epoch:[3/16] Step:[24002/24898] Loss: 0.016075 Loss_avg: 0.018407 LR: 0.00040000
[2021-10-30 06:14:45,540 - trainer - INFO] - Train Epoch:[3/16] Step:[24003/24898] Loss: 0.021404 Loss_avg: 0.018407 LR: 0.00040000
见 五、快速开始
Test 输出如下:
Loading checkpoint: /home/aistudio/data/data111037/checkpoint-epoch8.pdparams
with saved best metric 0.962424
subset IC13_1015 size: 1015 steps: 2
0%| | 0/2 [00:00<?, ?it/s]/opt/conda/envs/python35-paddle120-env/lib/python3.7/site-packages/paddle/fluid/framework.py:706: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here.
Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
elif dtype == np.bool:
100%|█████████████████████████████████████████████| 2/2 [01:02<00:00, 31.32s/it]
Predict results has written to test_out/IC13_1015_pred.json
subset IC15_1811 size: 1811 steps: 4
100%|█████████████████████████████████████████████| 4/4 [01:51<00:00, 27.95s/it]
Predict results has written to test_out/IC15_1811_pred.json
subset IC03_860 size: 860 steps: 2
100%|█████████████████████████████████████████████| 2/2 [00:53<00:00, 26.70s/it]
Predict results has written to test_out/IC03_860_pred.json
subset SVT size: 647 steps: 2
100%|█████████████████████████████████████████████| 2/2 [00:41<00:00, 20.51s/it]
Predict results has written to test_out/SVT_pred.json
subset IC13_857 size: 857 steps: 2
100%|█████████████████████████████████████████████| 2/2 [00:53<00:00, 26.81s/it]
Predict results has written to test_out/IC13_857_pred.json
subset CUTE80 size: 288 steps: 1
100%|█████████████████████████████████████████████| 1/1 [00:18<00:00, 18.24s/it]
Predict results has written to test_out/CUTE80_pred.json
subset SVTP size: 645 steps: 2
100%|█████████████████████████████████████████████| 2/2 [00:40<00:00, 20.32s/it]
Predict results has written to test_out/SVTP_pred.json
subset IC03_867 size: 867 steps: 2
100%|█████████████████████████████████████████████| 2/2 [00:53<00:00, 26.77s/it]
Predict results has written to test_out/IC03_867_pred.json
subset IC15_2077 size: 2077 steps: 5
100%|█████████████████████████████████████████████| 5/5 [02:10<00:00, 26.02s/it]
Predict results has written to test_out/IC15_2077_pred.json
subset IIIT5k_3000 size: 3000 steps: 6
100%|█████████████████████████████████████████████| 6/6 [03:06<00:00, 31.01s/it]
Predict results has written to test_out/IIIT5k_3000_pred.json
Evaluation 输出如下:
2021-11-14 18:19:00,079 root INFO Script being executed: MASTER-paddle/utils/calculate_metrics.py
calculating metrics of IC13_857_pred
current sample idx: 0
2021-11-14 18:19:00,097 root INFO Sequence Accuracy: 0.308051 Case_ins: 0.961494
2021-11-14 18:19:00,097 root INFO Edit Distance Accuracy: 0.294415
=============================================================================
calculating metrics of SVT_pred
current sample idx: 0
2021-11-14 18:19:00,112 root INFO Sequence Accuracy: 0.825348 Case_ins: 0.918083
2021-11-14 18:19:00,112 root INFO Edit Distance Accuracy: 0.870653
=============================================================================
calculating metrics of IIIT5k_3000_pred
current sample idx: 0
current sample idx: 1000
current sample idx: 2000
2021-11-14 18:19:00,133 root INFO Sequence Accuracy: 0.815000 Case_ins: 0.920667
2021-11-14 18:19:00,133 root INFO Edit Distance Accuracy: 0.862663
=============================================================================
calculating metrics of IC15_1811_pred
current sample idx: 0
current sample idx: 1000
2021-11-14 18:19:00,158 root INFO Sequence Accuracy: 0.723909 Case_ins: 0.823854
2021-11-14 18:19:00,158 root INFO Edit Distance Accuracy: 0.819207
=============================================================================
calculating metrics of SVTP_pred
current sample idx: 0
2021-11-14 18:19:00,162 root INFO Sequence Accuracy: 0.781395 Case_ins: 0.857364
2021-11-14 18:19:00,162 root INFO Edit Distance Accuracy: 0.858463
=============================================================================
calculating metrics of CUTE80_pred
current sample idx: 0
2021-11-14 18:19:00,171 root INFO Sequence Accuracy: 0.684028 Case_ins: 0.815972
2021-11-14 18:19:00,171 root INFO Edit Distance Accuracy: 0.779937
=============================================================================
calculating metrics of IC03_860_pred
current sample idx: 0
2021-11-14 18:19:00,185 root INFO Sequence Accuracy: 0.380233 Case_ins: 0.959302
2021-11-14 18:19:00,185 root INFO Edit Distance Accuracy: 0.361711
=============================================================================
2021-11-14 18:19:00,186 root INFO Evaluation finished
原文的实验细节说明作者使用 4 卡(Tesla V100)并行,优化器选择 Adam 从零开始训练,总共训练 12 个 epochs,每个 epoch 大概费时 3 个小时。batch_size 为 128 × 4,learning_rate 全程保持为 0.0004,我使用了同样的设置,在百度 AI Studio 平台提交 4 个 V100 GPU 并行训练脚本。但是每个 epoch 大概耗时 6 个小时,训练到了中期启动 valid_epoch(训练过程验证) 之后耗时更长。
单卡时 learning_rate 设为 0.0001,原文提到 learning_rate 的大小应该与 GPU 数量相关联,这也是以往做过的研究。多卡时得益于 paddle.DataParallel 的多进程并行,在保持单卡 bs = 128 的情况下,4 个 Trainer 进程的 paddle.io.DataLoader 分别加载 bs = 128 的 samples,等价于 bs = 128 × 4;所以,根据 linear scale rule,lr 需要等价倍增。
torch.nn.DataParallel是一个进程多个线程并行,受制于 Python 的 GIL 锁,所以 PyTorch 官方已经不推荐使用,而是主推更好更快的多进程并行:torch.nn.parallel.DistributedDataParallel。paddle.DataParallel 是对应 PyTorch 的 DDP 😄
我把 model/master.py 中所有的 torch.script.jit. 的代码全部去掉了,只要是网络模型类全部继承自 nn.Layer。因为 paddle 似乎没有 TorchScript 的替代品,所以咱们不需要? 😄 。
| 信息 | 说明 |
|---|---|
| 发布者 | 石华榜、杨瑞智 |
| 时间 | 2021.11 |
| 框架版本 | paddlepaddle==2.1.2 |
| 应用场景 | 多场景文本识别 |
| 支持硬件 | GPU × 4 |
| data_lmdb_release 数据集下载 | 百度网盘 data_lmdb_release.zip,提取码:rryk |
| 预训练模型下载 | 百度网盘 ckpts/model_best.pdparams,提取码:opkk |
| AI Studio 地址 | MASTER-Paddle |
@article{Lu2021MASTER,
title={{MASTER}: Multi-Aspect Non-local Network for Scene Text Recognition},
author={Ning Lu and Wenwen Yu and Xianbiao Qi and Yihao Chen and Ping Gong and Rong Xiao and Xiang Bai},
journal={Pattern Recognition},
year={2021}
}
#encoding=utf8
# Copyright (c) 2021 PaddlePaddle Authors. All Rights Reserved.
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
# http://www.apache.org/licenses/LICENSE-2.0
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.