Paddle cluster design #1696
Paddle cluster design #1696
Conversation
doc/design/cluster_design.md
Outdated
| <img src="images/trainer.png"/> | ||
|
|
||
| 为了完成一个深度学习的训练任务,集群中会运行多个trainer和parameter server,集群会把模型的参 | ||
| 数分布式的存储在多个parameter server上,trainer完成每个mini-batch数据训练之后会把梯度发送 |
There was a problem hiding this comment.
"trainer完成每个mini-batch数据训练之后会把梯度发送 给parameter server,parameter server将某个分片的模型参数和梯度执行整合和优化。然后trainer 从所有的parameter server下载模型参数并开始下一轮mini-batch的训练。":这个是synchronous SDG,即trainer每一轮计算完了立即与parameter server同步所有的gradient,parameter等所有trainer计算完一起更新parameter,然后trainer再进行下一轮。
现在咱们parameter server架构支持的另一种方法是asynchronous SDG,parameter同步并不是每一轮计算都需要进行,单个trainer也不需要等待其他trainer。这里面讲的比较详细,data parallel部分:

建议这里可以不这么详细的说更新过程,或者分两类synchronous SDG, asynchronous SDG来详细的说更新过程。
There was a problem hiding this comment.
分synchronous SGD, asynchronous SGD分别描述了更新过程。
doc/design/cluster_design.md
Outdated
| 1. 模型的参数是保存在parameter server进程的内存中的。在一个训练任务过程中任意一台 | ||
| parameter server不能异常退出,否则训练不能继续执行 | ||
| 1. 不能在一个训练任务中动态的增加Trainer个数或parameter个数 | ||
| 1. parameter server保存模型参数考虑多个备份防止单点故障 |
There was a problem hiding this comment.
为了简单起见,能否parameter server的模型参数定期存到分布式文件系统中,又分布式文件系统负责多个备份。
There was a problem hiding this comment.
+1, 但如果在pserver层实现一个基于内存的分布式存储不如直接使用外部的存储服务,例如Redis的主从。
There was a problem hiding this comment.
如果训练任务参数同步会占满网络带宽,使用分布式存储则会和训练任务互相抢占带宽。使用不同的物理网卡区分训练网络带宽和存储网络带宽又会带来额外成本。所以还是改成一个可配置参数?或者要求用户自己mount一个分布式存储?
There was a problem hiding this comment.
@typhoonzero 赞同分布式存储作为一个补充的选项。
pserver的存储的数据会被分为多个shard,每个shard会存在0到多个replic,要保证每次更新都能使集群中的数据达成一致,同时保证高可用性,建议分为两种方式:
- 默认不启动checkpointing机制,采用本地磁盘做存储
可以不需要外置的分布式存储服务,pserver的存储直接挂在某个节点的磁盘上,使用多replic的机制保证数据的高可用

更新pserver数据的过程分为写入master shad=>master shard同步至slave shard=>返回master shard=>返回trainer
为了保证数据在内存和磁盘的一致性,每个shard的写入过程需要写入buffer=>写入tranlog=>flush到磁盘=>写入成功。
- 启动checkpointing机制
通过 @typhoonzero 提到的每个pserver挂载到一个分布式的Volume,可定期将数据snapshot到存储服务上,这个分布式存储服务会存储每个shard的数据信息,为了保证数据能够恢复到每个pserver上,所以还需要元数据信息。元数据信息中保存了shard数量,pserver的数量等信息。

doc/design/cluster_design.md
Outdated
| "sync": true, | ||
| } | ||
| ``` | ||
| 1. mini-batch计数器,记录此id对应的parameter server正在执行的mini batch id |
There was a problem hiding this comment.
为何parameter server需要跟mini batch有相关性?照我理解它只用管gradient和parameter。trainer负责mini batch。
There was a problem hiding this comment.
我理解错了,在sync SGD是记录的batchid只用来打印性能记录的日志 。
doc/design/cluster_design.md
Outdated
| ``` | ||
|
|
||
| ## 数据一致性 | ||
| 存在多个副本数据的情况下就需要考虑,多个副本之间的数据一致性。如果使用数据强一致性(例如paxos/raft或两段式提交), |
There was a problem hiding this comment.
有没有可能不用多个副本。比如一个parameter server挂了之后,对应这些parameter的更新暂停,先算其它的parameter。
There was a problem hiding this comment.
可以的,在下面有介绍。可以配置只使用一个副本,并开启检查点。或者都不开
doc/design/cluster_design.md
Outdated
| 成功。如果使用异步同步(最终一致性),则在重新选举"master"副本时,可能得到的副本并没有完成数据同步。 | ||
|
|
||
| 本文档讨论使用两阶段提交实现模型副本数据的更新。 | ||
| * 每个副本通常由多个parameter block组成,多个block之间可以并发更新,但更新同一个block需要保证顺序性。 |
There was a problem hiding this comment.
parameter block是什么,需要给出定义。
There was a problem hiding this comment.
在附录中增加了术语,也在这里增加了简要的解释
doc/design/cluster_design.md
Outdated
| <img src="images/two_phase_commit.png"/> | ||
|
|
||
| ## 模型数据检查点(Checkpointing) | ||
| 模型数据检查点,可以在磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的本地磁盘保存检查点快照达到容灾的目的,比如每个pass保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 |
There was a problem hiding this comment.
感觉还需要每隔一段时间(比如几分钟)存一次,覆盖上一次的。每个pass存一次有点太慢了,比如百度的语音数据很大,一个pass就可能需要1天。
There was a problem hiding this comment.
checkpoint序列化出来的数据最好也是在一个分布式的存储上,防止磁盘或者raid卡坏掉导致无法恢复到某检查点的状态。
There was a problem hiding this comment.
修改了描述,可以配置检查点存储周期。
doc/design/cluster_design.md
Outdated
|
|
||
| <img src="images/more_trainer.png"/> | ||
|
|
||
| * 当trainer < 数据分片 |
There was a problem hiding this comment.
这个可能性不是特大,这本书里的figure1.8总结了一下常见的数据集尺寸。10^4条样本已经算很小的数据集了。小数据集分片不多,但一般也不需要大量机器训练。
There was a problem hiding this comment.
明白了。这个先保留?毕竟无法确定使用时用户究竟会怎么配置?
doc/design/cluster_design.md
Outdated
| ## 模型数据检查点(Checkpointing) | ||
| 模型数据检查点,可以在磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的本地磁盘保存检查点快照达到容灾的目的,比如每个pass保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 | ||
|
|
||
| ## 训练数据的存储和分发 |
There was a problem hiding this comment.
感觉咱们可以考虑一下master怎么自动把数据集分片:
如果是用户自定义格式,master如何知道怎么分片。
如果是我们定义格式,接口是什么(用户如何把他们的数据转换成我们的格式)。
There was a problem hiding this comment.
我理解这里分两个部分:数据接入和数据分片
-
数据接入
考虑到数据源可能会有Kafka,HDFS,图片或者用户自定义的文件,所以需要支持自定义数据处理的函数,参考之前reader的设计,提供一个支持RPC调用的reader:
def dist_reader(trainerid): return data- trainerid:
每个trainer启动时会拥有一个trainerid,reader根据trainerid来决策返回什么数据 - RPC:
trainer通过RPC的方式远程调用reader,获取训练数据。 - 线程安全:
dist_reader会同时被多个trainer进行调用,必须保证线程安全
- trainerid:
-
数据分片
在数据接入层里,我们需要自定义数据分片的方式(可以在Paddle中提供一些常用的分片方式),一般的理解,trainer读取到的数据可以通过:traienr_count(trainer进程数量),trainerid(当前请求数据trainerID)来确定,以读取一个大文件举例:
queue_list = [] trainer_count = 4 queue_list = [Queue.Queue(maxsize=10) for i in xrange(trainer_count)] def load_file(): global trainer_count global queue_list line_count = 0 with open("data.txt", "r") as f: for line in f: line_count += 1 queue_list[line_count%trainer_count].put(line) t = threading.Thread(target=load_file, args=()) t.start() def dist_read(trainer_id): return queue_list[trainer_id].get() -
结构图

There was a problem hiding this comment.
实际应用中,用户会根据自己的需求分片数据么?这里不太了解。目前只考虑了直接使用HDFS的的分片机制,trainer就近寻找HDFS分片好的数据副本。
There was a problem hiding this comment.
@typhoonzero 实际应用中,用户上传了一个大的数据集到云上,默认情况咱们集群无法知道这个数据是怎么存的,也就不知道怎么分片。需要用户以某种方法指定。(比如训练图像分类的时候,要是用户指定了一个列表文件,每一行是一个图像的相对路径以及label,集群就能自动根据行数来分片)
另一种方法,是先让用户把数据全部提供给集群一次,集群把数据存成自己的格式。因为是自己的格式,就知道怎么分片,并且可以把格式设计成对顺序读取有利的格式、甚至设计成支持hdfs自动分片的格式。这里一种实现方法。
There was a problem hiding this comment.
@Yancey1989 我要是没理解错的话,这个方法是单点读数据再通过rpc serve数据。感觉这个可以是一种读数据的方法,不过要是把它作为读数据的默认方法,我有点担心网络性能:那个读数据的单点很容易成为瓶颈。
There was a problem hiding this comment.
@helinwang 不好意思回复晚了,后来和 @typhoonzero 线下讨论的时候也提到这个问题了,一种理想的情况是分布式存储部署在计算节点之中,Trainner启动在数据片所在的节点上(或是同一交换机下的节点),但是这么做需要直接读取分布式存储的元数据信息,可能无法同时支持多种分布式存储。我再想一下,然后更新这个doc吧:)
doc/design/cluster_design.md
Outdated
| 用户只要根据实际训练任务场景,配置parameter server和trainer的初始节点个数,最大节点个数和最小节点个数,模型副本个数,是否开启检查点等配置项,即可配置并启动一个可以容灾的训练集群。具体的过程如下: | ||
|
|
||
| 1. 配置parameter server和trainer的初始节点个数、最大节点个数、最小节点个数、模型副本个数、是否开启检查点等配置以及训练任务相关配置。 | ||
| 1. 启动parameter server和trainer,每个实例会在etcd中注册一个临时节点。这样当某个parameter server或trainer失效是,etcd中的节点会反应这个示例的状态。每个parameter server在所有的parameter server上会使用etcd watcher监听节点的变化状态,已完成后续处理。 |
There was a problem hiding this comment.
对etcd不是特熟悉,"etcd中的节点会反应这个示例的状态"是不是指etcd的lock是lease方式实现的(我的猜测),所以能够知道parameter server或trainer的实例的状态(挂了没有)?
There was a problem hiding this comment.
etcd中可以创建一个节点(文件?)并设置一个较短的TTL过期时间。客户端会不断的写入这个节点并更新TTL,这样如果客户端故障(挂掉),这个节点会很快消失,用于判断客户端的存活状态。和心跳类似。
doc/design/cluster_design.md
Outdated
| 1. parameter server如果开启了检查点,则先判断是否已经存在本地检查点快照数据,如果有,则从快照数据中加载状态和数据,并开始提供服务。如果没有则执行初始化启动步骤。 | ||
| 1. 提交用户定义的深度学习网络(topology),并根据网络中参数完成pre-sharding,将参数block哈希到512或1024个slot中,每个slot即为一个参数分片。根据实际存在的parameter server个数,将slot和parameter server完成对应的映射,使slot可以平均存储在这些parameter server上。 | ||
| 1. parameter server开始监听端口并接收数据。每次接收到数据,都使用两段式提交方式同步到所有的副本。如果需要存储检查点,则在同步所有副本之后,保存检查点。 | ||
| 1. 当故障发生后,parameter server会收到etcd发送的watcher信号,此时将暂停trainer的训练(此时要检查最后一次更新的mini_batch id,如果处于不同步状态,需要执行rollback),执行re-sharding步骤: |
There was a problem hiding this comment.
能否举个例子,什么故障发生,以及watcher信号的内容是什么。
doc/design/cluster_design.md
Outdated
| 1. 提交用户定义的深度学习网络(topology),并根据网络中参数完成pre-sharding,将参数block哈希到512或1024个slot中,每个slot即为一个参数分片。根据实际存在的parameter server个数,将slot和parameter server完成对应的映射,使slot可以平均存储在这些parameter server上。 | ||
| 1. parameter server开始监听端口并接收数据。每次接收到数据,都使用两段式提交方式同步到所有的副本。如果需要存储检查点,则在同步所有副本之后,保存检查点。 | ||
| 1. 当故障发生后,parameter server会收到etcd发送的watcher信号,此时将暂停trainer的训练(此时要检查最后一次更新的mini_batch id,如果处于不同步状态,需要执行rollback),执行re-sharding步骤: | ||
| 1. 根据现有存活的parameter server的个数,找出丢失master分片的参数slot,重新标记成为master,然后确保集群中一个分片只选择出一个master。 |
doc/design/cluster_design.md
Outdated
| 1. 支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理 | ||
|
|
||
| ## 模型参数数据备份 | ||
| 为了实现parameter server集群可以容忍单点故障,必须将每个模型参数的分片在集群中存储多个副本。虽然 |
There was a problem hiding this comment.
我的理解:parameterserver保存多个备份是不经济的。比如两备份。主从备份的参数是要同步更新的,这个参数量比较大的情况下,加大网络传输压力。
采用单副本,checkpoint恢复的方式是不是更好一些?可以隔一段时间生成一个checkpoint,网络传输压力小很多
doc/design/cluster_design.md
Outdated
| 模型数据检查点,可以在磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的本地磁盘保存检查点快照达到容灾的目的,比如每个pass保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 | ||
|
|
||
| ## 训练数据的存储和分发 | ||
| 生产环境中的训练数据集通常体积很大,并被存储在诸如Hadoop HDFS, Ceph, AWS S3之类的分布式存储之上。这些分布式存储服务通常会把数据切割成多个分片分布式的存储在多个节点之上,而多个trainer通常也需要预先完成文件的切割。但通常的方法是从HDFS上将数据拷贝到训练集群,然后切割到多个trainer服务器上,如图(Mount/Copy): |
There was a problem hiding this comment.
预先拷贝数据,如果数据量比较大,trainer节点就变成了有状态的重节点,不利于trainer的迅速启动。
是否采用master分片,分发数据handle, trainer拉取数据,在计算的过程中cache需要的部分,把网络流量隐藏在计算过程中会更好一些?
There was a problem hiding this comment.
这个是现状的描述,设计参考图下面的描述。
|
按照今天上午讨论的结果更新了~ |
doc/design/cluster_design.md
Outdated
|
|
||
| 这样,通过trainer和parameter server的分布式协作,可以完成神经网络的SGD方法的训练。Paddle可以同时支持同步SGD(synchronize SGD)和异步(asynchronize SGD)。 | ||
|
|
||
| 在使用同步SGD训练神经网络时,Paddle使用同步屏障(barrier),使梯度的提交和参数的更新按照顺序方式执行。在异步SGD中,则并不会等待所有trainer提交梯度才更新参数,这样极大的提高了计算的并行性:parameter server不之间不相互依赖并行的接收梯度和更新参数,parameter server也不会等待trainer全部都提交梯度之后才开始下一步,trainer之间也不会相互依赖,并行的执行模型的训练。可以看出,虽然异步SGD方式会使参数的更新并不能保证参数的顺序的同步的更新,在任意时间某一台parameter server上保存的参数可能比另一台要更新,这样反而会给参数优化过程带来更多的随机性。在实践中,异步SGD在带来更高效率的同时并没有特别影响算法的准确性。 |
There was a problem hiding this comment.
parameter server不之间不相互依赖并行的接收梯度和更新参数
parameter server之间不相互依赖,并行的接收梯度和更新参数
There was a problem hiding this comment.
虽然异步SGD方式会使参数的更新并不能保证参数的顺序的同步的更新,在任意时间某一台parameter server上保存的参数可能比另一台要更新
虽然异步SGD方式会使参数更新, 但是并不能保证参数同步更新,在任意时间某一台parameter server上保存的参数可能比另一台要更新
|
#594 也可以参考以前的一些讨论,是有master节点来做动态扩容的。 |
doc/design/cluster_design.md
Outdated
|
|
||
| 参考上面所描述的Paddle实现细节,可以进一步的优化以下方面: | ||
| 1. 目前模型的参数是保存在parameter server进程的内存中的。在同步SGD或异步SGD训练过程中任意一台parameter server不能异常退出,否则参数丢失,训练不能继续执行。需要考虑每个模型分片(model shard)保存多个副本(replica)防止parameter server单点故障。 | ||
| 1. 不能在一个训练任务中动态的增加或减少Trainer个数或parameter个数(异步SGD是否可以增加Trainer?) |
There was a problem hiding this comment.
不能在一个训练任务中动态的增加或减少Trainer个数或parameter个数(异步SGD是否可以增加Trainer?)
这句话不太理解,是希望做到可以在训练任务中增减trainer或者ps的个数?
There was a problem hiding this comment.
嗯。动态扩容/缩容,这样就可以支持抢占式调度。比如有一个100个节点低优先级训练训练任务在运行,此时如果调度了一个50节点的高优先级任务,就可以缩容低优先级任务,提供资源而不是杀掉低优先级任务,优先执行高优先级任务。
doc/design/cluster_design.md
Outdated
|
|
||
| <img src="images/trainer.png" width="500"/> | ||
|
|
||
| 为了完成一个深度学习的训练任务,集群中会运行多个trainer和parameter server,每个trainer启动时,会先尝试从parameter server集群下载最新的参数,然后以mini-batch为单位读取训练数据集中的一部分数据(Data shard)。在完成这个mini-batch数据的神经网络前馈和反向传播计算后,将参数梯度发送给对应的parameter server。随后trainer开始下一轮计算。 |
There was a problem hiding this comment.
在完成这个mini-batch数据的神经网络前馈和反向传播计算后,将参数梯度发送给对应的parameter server。随后trainer开始下一轮计算。
这个是synchronous SGD的方法,而这里是对sync SGD和async SGD的总体叙述。我觉得写在这里不是很合适。
考虑改成:
trainer会在训练过程中持续与parameter server通讯,上传计算出来的梯度以及下载最新的模型。
doc/design/cluster_design.md
Outdated
|
|
||
| 每个parameter server保存所有parameter的一个分片(Global model shard),并负责接受所有trainer发送的梯度,完成SGD和优化算法,然后发送更新后的parameter到每个trainer。 | ||
|
|
||
| 这样,通过trainer和parameter server的分布式协作,可以完成神经网络的SGD方法的训练。Paddle可以同时支持同步SGD(synchronize SGD)和异步(asynchronize SGD)。 |
doc/design/cluster_design.md
Outdated
|
|
||
| 这样,通过trainer和parameter server的分布式协作,可以完成神经网络的SGD方法的训练。Paddle可以同时支持同步SGD(synchronize SGD)和异步(asynchronize SGD)。 | ||
|
|
||
| 在使用同步SGD训练神经网络时,Paddle使用同步屏障(barrier),使梯度的提交和参数的更新按照顺序方式执行。在异步SGD中,则并不会等待所有trainer提交梯度才更新参数,这样极大的提高了计算的并行性:parameter server不之间不相互依赖并行的接收梯度和更新参数,parameter server也不会等待trainer全部都提交梯度之后才开始下一步,trainer之间也不会相互依赖,并行的执行模型的训练。可以看出,虽然异步SGD方式会使参数的更新并不能保证参数的顺序的同步的更新,在任意时间某一台parameter server上保存的参数可能比另一台要更新,这样反而会给参数优化过程带来更多的随机性。在实践中,异步SGD在带来更高效率的同时并没有特别影响算法的准确性。 |
There was a problem hiding this comment.
可以看出,虽然异步SGD方式会使参数的更新并不能保证参数的顺序的同步的更新,在任意时间某一台parameter server上保存的参数可能比另一台要更新,这样反而会给参数优化过程带来更多的随机性。在实践中,异步SGD在带来更高效率的同时并没有特别影响算法的准确性。
我读上去感觉有点对于ASGD太乐观了,写成:
异步SGD方式更加容错(单个trainer出错并不会中断其他trainer的参数更新),数据吞吐速度也更快。但与同步SGD相比,梯度会有噪声。
可能更中肯。
There was a problem hiding this comment.
根据昨天 @helinwang 在群里提到的google的应用情况,只修改了最后一句的描述。
doc/design/cluster_design.md
Outdated
| 1. 支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理 | ||
|
|
||
| ## 模型参数检查点(Checkpointing) | ||
| 模型数据检查点的实现,可以有效的避免parameter server的单点或多点同时故障。模型参数检查点通过定期向磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像,来保证训练过程可以从中间状态重新启动。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的 ***本地磁盘/分布式存储挂载点*** 保存检查点快照达到容灾的目的,比如每个pass或每n个mini-batch保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 |
There was a problem hiding this comment.
本地磁盘/分布式存储挂载点
简单起见,建议一开始先只支持分布式存储吧。存在本地磁盘对parameter server调度有更高的要求(挂掉之后需要调度到同一个节点上)。
对于怕使用分布式存储太多占用网络资源的问题,我觉得不必过于担心。往磁盘上存最新模型的频率不会太频繁:10分钟左右应该就足够了。
doc/design/cluster_design.md
Outdated
| 1. 支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理 | ||
|
|
||
| ## 模型参数检查点(Checkpointing) | ||
| 模型数据检查点的实现,可以有效的避免parameter server的单点或多点同时故障。模型参数检查点通过定期向磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像,来保证训练过程可以从中间状态重新启动。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的在每个parameter server的 ***本地磁盘/分布式存储挂载点*** 保存检查点快照达到容灾的目的,比如每个pass或每n个mini-batch保存一次快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 |
There was a problem hiding this comment.
比如每个pass或每n个mini-batch保存一次快照
觉得按时间来存最新的模型最符合使用需求。
另外,”保存一次快照“写成”覆盖上一次的快照“可能更减少歧意:我们不需要每一次快照都存着,只需要拿最后一次的快照来做故障恢复。
There was a problem hiding this comment.
改成了“比如每隔10分钟或1小时保存最新的快照,并删除更早的快照。”
由于在快照保存过程中也可能出现故障,所以这里并不是直接覆盖的,而是保存一个新的快照文件,并且同步所有pserver的保存状态,都保存完成之后才会删除上一个快照。如果保存过程中出现故障,在恢复时,会忽略只保存了部分pserver节点的快照,而使用上一个完整的快照。
doc/design/cluster_design.md
Outdated
| * 支持流式数据接口和常规文件接口 | ||
| * 对不同的分布式存储,需要实现不同的reader wrapper | ||
|
|
||
| ## 动态扩容/缩容 |
There was a problem hiding this comment.
动态扩容第一个貌似版本不需要支持。咱们可以先把前面的讨论清楚,实现第一个版本,之后有空了再讨论这些。
doc/design/cluster_design.md
Outdated
|
|
||
| master不会直接发送数据给Trainer而是负责协调训练数据的分配,并以ETCD为协调中心。所以master是一个无状态程序,任务运行过程中,master停止后只需要重新启动即可。 | ||
|
|
||
| ### 推测执行/加速执行(TODO) |
There was a problem hiding this comment.
感觉这个有点远。第一个版本应该也不会支持。
可以考虑建一个标题
### 第一版**不需要**支持的
#### 推测执行/加速执行(TODO)
#### 动态扩容/缩容
这里面放以后考虑支持的。我们就不需要放很多笔墨/仔细讨论这些。
@gangliao 看了#594 有不少相似的地方。主要的区别在于:
|
|
感觉有以下几点大家可以继续讨论:
可以参考这一篇paper:https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf |
doc/design/cluster_design.md
Outdated
|
|
||
| 程序流程: | ||
| 1. 满足条件""每个pass或每n个mini-batch"时,parameter server原子写入`/paddle/trainers/pause`暂停所有trainer上传新的梯度 | ||
| 2. parameter server在etcd服务中创建`/paddle/checkpoints/[snapshot uuid]/[parameter server id]`TTL节点,标识快照开始更新。然后开始向磁盘/存储服务中一个新的文件写入快照数据,并在写入过程中定时更新 etcd的checkpoint TTL节点已保证心跳。 |
There was a problem hiding this comment.
Tensorflow用的默认的checkpointing是非常relaxed consistency model: 完全没有考虑data race,一个参数都有可能在更新到一半的时候被snapshot下来(见末尾的截图)。
咱们这里提出的是很strong的consistency:parameter server / trainer之间需要协作,暂停训练,然后一起checkpoint。
介于这两种之间的是不需要全局协作(/paddle/trainers/pause),每个parameter server snapshot的时候atomically存自己的模型。
我觉得因为深度学习模型貌似不需要strong consistency(http://papers.nips.cc/paper/4390-hogwild-a-lock-free-approach-to-parallelizing-stochastic-gradient-descent.pdf ),以及stochastic gradient decent本来就是高随机性的,为了简单起见,可以考虑snapshot的时候不全局协作。
https://www.usenix.org/system/files/conference/osdi16/osdi16-abadi.pdf :


There was a problem hiding this comment.
记得之前也和 @reyoung 讨论过。对于同步SGD来说,N个parameter server会同步N个参数的分片;对于异步SGD来说是同步1个参数分片(完全不考虑分片同步);可以考虑在N个分片中考虑M个分片的同步。 实现最后一个方式会更加通用。
There was a problem hiding this comment.
@typhoonzero 没有很看明白
对于异步SGD来说是同步1个参数分片(完全不考虑分片同步)
中的“1个参数分片”是什么意思?
我的理解同步SGD和异步SGD都是N个parameter server一起存同一个model。所以在checkpoint的时候貌似需要干的事情是一样的,所以不是很理解为何“异步SGD来说是同步1个参数分片”,而"对于同步SGD来说,N个parameter server会同步N个参数的分片"。
There was a problem hiding this comment.
@helinwang 同步SGD和异步SGD都是N个parameter server 分布式的存储同一个model。每个parameter server只存储model的一部分,即一个分片
There was a problem hiding this comment.
补充:可以提供选项,让用户配置每次parameter等待M个trainer上传完成梯度,N是trainer总个数。这样更通用点。配置M=1则是async SGD,M=N则是sync SGD, 1<M<N则是介于两者中间的状态。
|
有几个疑问:
这个PR merge进去了之后应该是两篇详细的设计:
感觉可以分成两个文件(现在可以不着急改,merge之前分也可以) |
|
关于每个题目我有这几个疑问:
训练数据的存储和分发:
|
已更新,不需要全局同步了,这样实现会更简单。
对。
只有写入完成才会更新etcd中的checkpoint数据,而恢复过程是从checkpoint中读取checkpoint的id
按照今天讨论的内容更新~ 感谢 @helinwang @Yancey1989 @gongweibao 线下提出的很多建议,都很有帮助! |
| 1. 支持训练任务的前置任务和后置任务,支持训练任务的定时调度和对在线流式数据的处理 | ||
|
|
||
| ## 模型参数检查点(Checkpointing) | ||
| 模型数据检查点的实现,可以有效的避免parameter server的单点或多点同时故障。模型参数检查点通过定期向磁盘上保存一份存储在parameter server内存中的模型数据的完整镜像,来保证训练过程可以从中间状态重新启动。在一个不可中断并缺少备份的训练任务中,可以通过阶段性的保存每个parameter server的数据快照(snapshot)到 ***分布式存储服务/分布式存储挂载点*** 达到容灾的目的,比如每隔10分钟或1小时保存最新的快照,并删除更早的快照。在出现单点故障时,只需要恢复这台节点,或者将这台节点迁移到另一个节点并启动即可恢复训练任务。 |
There was a problem hiding this comment.
比如每隔10分钟或1小时保存最新的快照
这里说的是ps(parameter server)进程做checkpointing吧,这块实际实现时觉得可能需要仔细思考下。 同步SGD,是完全同步的状态,如果是每个ps进程保存一个分片,一个完整的模型通常保存的是同一个batch_id(感觉说时间不是特别准确)的参数。 异步SGD,ps的参数还分片吗?checkpointing机制会和同步SGD完全一样吗?
There was a problem hiding this comment.
@qingqing01 感谢评论~
目前sync SGD和async SGD保存checkpoint的方式是一样的。
在之前的版本中是考虑了sync SGD情况下的多个ps之间的checkpoint同步的机制的,即在每n个min_batch时,触发训练暂停,然后等待所有ps完成checkpoint保存,再开始训练。这个方式相对现在的实现比较复杂。由于checkpoint恢复如果不是恢复到一个全局同步的状态,而是有的ps的参数更新,有的ps的参数相对较老,会引入更多随机性,实际对训练的影响也不会很大(参考async SGD的思路)。所以先选择简单的实现方式。我会把checkpoint同步机制放在TODO中。
对于触发方式,还是觉得每n个mini_batch触发checkpoint会合适点? @helinwang
doc/design/cluster_train/README.md
Outdated
| @@ -132,6 +130,8 @@ When the trainer is started by the Kubernetes, it executes the following steps a | |||
|
|
|||
| If trainer's etcd lease expires, it will try set key `/trainer/<unique ID>` again so that the master process can discover the trainer again. | |||
|
|
|||
| Whenever a trainer fails, the master process is responsible to schedule the failed task back to "todo queue". then kubernetes will try to start the trainer somewhere else, then the recovered trainer will try to fetch new task to continue the training. | |||
There was a problem hiding this comment.
the master process is responsible to schedule the failed task back to "todo queue"
这个之前貌似已经讲过了:
If a task timeout. the master process will move it back to the todo queue
为了避免混淆是不是可以去掉它,变成:
Whenever a trainer fails, then kubernetes will try to start the trainer somewhere else, then the recovered trainer will try to fetch new task to continue the training.
There was a problem hiding this comment.
一点儿英语建议:
When a trainer fails, Kuberentes would try to restart it. The recovered trainer would fetch tasks from the TODO queue and go on training.
- Whenever 是个很强的语气。这里不需要。
- “万一。。。挂了”是个虚拟语气,应用用would而不是will。
| * Paddle训练任务 | ||
| * 在线模型预测服务 | ||
|
|
||
| <img src="src/data_dispatch.png" width="500"/> |
There was a problem hiding this comment.
这个图中的"mount API"和"Storage API"是指的同一个东西吗?如果是的话能否用同一个名字?
There was a problem hiding this comment.
除了 @helinwang 的问题之外:
- 这个图没有对应的说明。自成一段。
- Paddle cluster 是什么?我理解不存在这个一个集群?
- online cluster 是什么?我理解也不存在这样一个集群?
我把我画过的一些图上传到一个repo,供大家复用。
There was a problem hiding this comment.
@typhoonzero 这里这个图是不是想表示一个Kubernetes机群上可以跑多种jobs?如果是,可以复用 PaddlePaddle/talks#1 这里的图
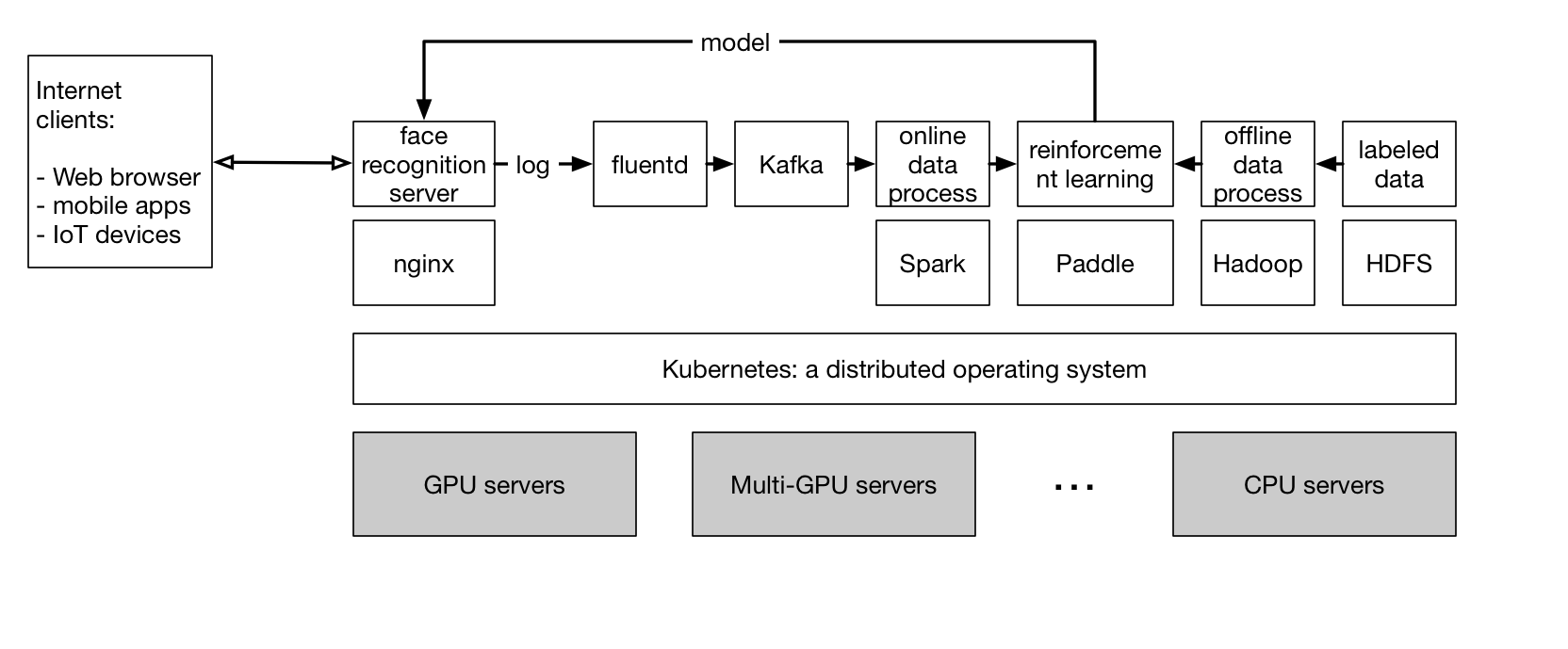
There was a problem hiding this comment.
@wangkuiyi 是的,可以直接用这个图👍。
两个问题:
- 为什么是reinforcement learning?
- 这里假定了训练数据都是来自于log,是否能加上用户自己上传的数据?比如使用
paddle upload <filename>
|
|
||
| 选择GlusterFS作为训练数据的存储服务(后续的实现考虑HDFS)。 | ||
|
|
||
| 在Kubernetes上运行的不同的计算框架,可以通过Volume或PersistentVolume挂载存储空间到每个容器中。 |
There was a problem hiding this comment.
请问Volume是指单机挂载node上的文件系统吗?上一行说了用GlusterFS,是不是这里只能用PersistenVolume(我对PersistenVolume的理解是:挂载分布式文件系统只能用它。可能理解有误。)?
There was a problem hiding this comment.
Kubernetes支持两种方式挂载存储:Volume和PV。Volume是直接调用存储的API把存储挂载到Pod上,PV的方式是在kubernetes集群中先建立一个存储的池子,然后使用PVC申请。
|
|
||
| 在Kubernetes上运行的不同的计算框架,可以通过Volume或PersistentVolume挂载存储空间到每个容器中。 | ||
|
|
||
| 在存储中的共享位置,需要保存PaddlePaddle book中的所有dataset数据,并且可以被提交的job直接使用。 |
There was a problem hiding this comment.
-
“PaddlePaddle book中的所有dataset数据”是不是用“公开数据集”更合适?比如咱们会把imagenet数据集放进去,但是imagenet并不在paddle book里面。
-
"在存储中的共享位置"貌似不是很通顺?
| paddle upload train_data.list | ||
| ``` | ||
|
|
||
| 其中`.list`文件描述了训练数据的文件和对应的label,对于图像类数据,`.list文件`样例如下,每一行包含了图片文件的路径和其label: |
There was a problem hiding this comment.
需要加上用什么分隔符,可以考虑tab,比如:
其中.list文件样例如下,每一行包含了图片文件的路径和其label(用tab分隔开)
| 其中`.list`文件描述了训练数据的文件和对应的label,对于图像类数据,`.list文件`样例如下,每一行包含了图片文件的路径和其label: | ||
|
|
||
| ``` | ||
| /data/image1.jpg 1 |
There was a problem hiding this comment.
我们需要支持绝对路径吗?如果要支持的话,咱们上传的list文件需要把绝对路径替换成相对路径。绝对路径传到集群上不认识。
| * parameter server在集群中启动后,自动挂载分布式存储目录,并把快照保存到这个目录下。 | ||
| * 所有parameter server和trainer在etcd上注册自己的id节点为TTL节点`/ps/[id]`和`/trainer/[id]`,并保持心跳。 | ||
| * ***注:trainer在故障恢复后,master会将失败的task重新分配给恢复的trainer执行。这样会引入更大的随机性。*** | ||
| * ***注:parameter server在保存检查点时,利用了Linux内核的“写时复制”技术,在fork的进程中保存检查点,原进程可以继续接收trainer的梯度更新请求,而不影响检查点数据的保存。*** |
There was a problem hiding this comment.
我觉得直接加一个read write lock就好了,写磁盘的时候获取read lock,不允许内存写入。
如果使用“写时复制”,写磁盘的时候基本肯定会有并发的内存写入,会引入复制,增加内存开销,感觉并没有引入什么好处。
There was a problem hiding this comment.
好处是:
- 写入checkpoint的时候不需要lock内存。写磁盘的时候获取read lock,参数更新需要获取write lock,此时是不能同时参数更新的,pserver智能等待checkpoint写完。
- 程序开发简单。
但也想到:如果pserver用golang编写,fork进程会导致go routine无法复制的问题。也会比较麻烦。修改成等待的方式。
| * 所有parameter server和trainer在etcd上注册自己的id节点为TTL节点`/ps/[id]`和`/trainer/[id]`,并保持心跳。 | ||
| * ***注:trainer在故障恢复后,master会将失败的task重新分配给恢复的trainer执行。这样会引入更大的随机性。*** | ||
| * ***注:parameter server在保存检查点时,利用了Linux内核的“写时复制”技术,在fork的进程中保存检查点,原进程可以继续接收trainer的梯度更新请求,而不影响检查点数据的保存。*** | ||
| * ***注:每个parameter server的检查点各自独立保存,暂时不考虑多个parameter server同步的保存一个特定时间点的全局检查点,同样会引入随机性。*** |
There was a problem hiding this comment.
好像“同样会引入随机性”改成“因为这样做也没法保证消除随机性”)更容易理解。
|
|
||
| 检查点保存程序流程: | ||
|
|
||
| 1. 如果满足条件""每个pass或每n个mini-batch"时,parameter server会`fork`自己,子进程中执行保存检查点任务,父进程继续工作。如果已经有子进程在进行保存检查点工作,则忽略。 |
There was a problem hiding this comment.
-
如果使用read write lock就不用fork了。
-
这里其实需要取得etcd的对应parameter server index的保存snapshot的lock(比如:
/snapshot_lock/ps0。(防止同时多个同一个index的parameter server保存同一个文件。)
There was a problem hiding this comment.
如果使用read write lock就不用fork了。
同上,使用golang不方便fork。但是也得锁住parameter的内存,并停止接收更新参数。参数更新在获取write lock的时候就会等待了。
这里其实需要取得etcd的对应parameter server index的保存snapshot的lock
我理解不需要,parameter server只需要写入到glusterfs的不同目录比如:/pservers/0下。
There was a problem hiding this comment.
有可能发生有两个parameter server同时以为自己的index是0,也有可能有两个master同时存在(即使只指定了1个master):因为如果replicaset说要4个pserver pod,在某一个时间可能会有6个pod存在。(这也是为什么master往etcd写入他的状态的时候需要用lock + transaction,防止同时多个master存在。bigtable paper里面的master也虽然设计成只有一个,但是还是需要用lock确保自己是唯一的一个)。
具体原因请看上次在gopher k8s非官方的slack channel(600人的群)得到的这个回答:

| 检查点保存程序流程: | ||
|
|
||
| 1. 如果满足条件""每个pass或每n个mini-batch"时,parameter server会`fork`自己,子进程中执行保存检查点任务,父进程继续工作。如果已经有子进程在进行保存检查点工作,则忽略。 | ||
| 2. parameter server生成一个UUID,向指定的目录中一个新的文件(文件名为此UUID)写入快照数据。在快照写入完成后,计算这个文件的MD5 sum。然后在etcd的`/checkpoints/[pserver_id]`中写入json内容:`{"uuid": [UUID], "md5", "MD5 sum", "timestamp": xxxx}`。 |
There was a problem hiding this comment.
我的感觉(可能是错误的)是能不要用etcd的地方就不要用了。这里可以考虑设计成:
- 向目录中的文件
checkpoint.tmp写入快照数据。 mv checkpoint.tmp checkpoint(这个操作是原子操作)。
There was a problem hiding this comment.
mv在mv单个文件并且是本地文件系统时时原子操作(这里也不确定不同文件系统是否表现相同?),在挂载的分布式文件系统中不一定是原子的操作,参考: https://bugzilla.redhat.com/show_bug.cgi?id=762766 。(不确定最新的版本是否可以支持)
如果将来考虑使用其他的分布式存储系统,也得考虑这些系统的各种操作是否原子。比较通用的情况还是写etcd了。
There was a problem hiding this comment.
对不起,我用原子这个词不是很恰当,我想要表达的其实是mv只要执行了,最终就一定会成功,不会出现mv到一半的状况(不会一半文件是正确的,另一半文件是垃圾,没有这个中间状态)。
关于atomic,我仔细想了一下,mv如果不是atomic的,遇到race的话(读文件和mv在非常接近的时间发生)会出现这种情况:读取的人会读到旧的文件。
首先,mv和读在非常接近的时间发生可能性应该很低:而mv是pserver存checkpoint的时候发生的,而读checkpoint是这个pserver被重启之后发生的,重启需要一定时间的。
其次,貌似发生了这个情况也不会影响数据的正确性(不会一半文件是正确的,另一半文件是垃圾),只是读到了旧的模型。
There was a problem hiding this comment.
经讨论大家同意 @typhoonzero 的方法好。
|
|
||
| 在parameter server第一次启动或任意时间parameter server故障后被Kubernetes重新启动,则需要回滚到上一个检查点: | ||
|
|
||
| 1. 从etcd中读取节点:`/checkpoints/[pserver_id]`获取最新的检查点的文件uuid |
There was a problem hiding this comment.
如果使用前面提到的checkpoint.tmp方法,这里可以改成:
- 从
checkpoint文件恢复模型。 - 开始提供服务。
There was a problem hiding this comment.
决定用PR里提出的方法,即使parameter server存到一半挂掉也没事。
|
Added more description of reader implement. |
doc/design/cluster_train/README.md
Outdated
|
|
||
| Their relation is illustrated in the following graph: | ||
|
|
||
| <img src="src/paddle-model-sharding.png"/> | ||
|
|
||
| By coordinate these processes, paddle can complete the procedure of training neural networks using SGD. Paddle can support both "synchronize SGD" and "asynchronize SGD". |
There was a problem hiding this comment.
在第一个缩写出现之前最好写一下全称。
using SGD -> Stochastic Gradient Descent (SGD)
doc/design/cluster_train/README.md
Outdated
|
|
||
| Their relation is illustrated in the following graph: | ||
|
|
||
| <img src="src/paddle-model-sharding.png"/> | ||
|
|
||
| By coordinate these processes, paddle can complete the procedure of training neural networks using SGD. Paddle can support both "synchronize SGD" and "asynchronize SGD". | ||
|
|
||
| When training with "sync SGD", paddle parameter servers use barriers to wait for all trainers to finish gradients update. When using "async SGD", parameter servers would not wait for all trainers, so training and parameter optimize will run in parallel. parameter servers will not depend on each other, they will receive the gradients update in parrallel; Also trainers will not depend on each other, run training jobs in parrallel. Using asyc SGD will be faster when training, but parameters on one of the parameter server will be newer than the other, but this will introduce more Randomness. |
There was a problem hiding this comment.
我改了一下,请看看可以不可以:
By coordinating these processes, PaddlePaddle supports both Synchronize Stochastic Gradient Descent (sync SGD) and Asynchronous Stochastic Gradient Descent (async SGD).
When training with sync SGD, parameter servers wait for all trainers to finish gradients update and then send the updated parameters to trainers, training can not proceed until the trainer received the updated parameters. This creates a synchronization point between trainers. When training with async SGD, each trainer upload gradient and download new parameters individually, without the synchronization with other trainers. Using asyc SGD will be faster in terms of time per pass, but have more noise in gradient since trainers are likely to have a stale model.
引号需要加吗?我好像很少读到英文里有引号。貌似没有引号意思也对?
paddle -> PaddlePaddle
parrallel -> parallel
. parameter servers -> . Parameter servers
but this will introduce more Randomness -> but this will introduce more noise in the gradient.
"parameter servers will not depend on each other, they will receive the gradients update in parrallel",感觉sync SGD里pserver也不会相互依赖,也是"receive the gradients update in parallel"?
run training jobs in parrallel 感觉可以改成 gradient upload and model download are run in parallel.
Using asyc SGD will be faster when training -> Using asyc SGD will be faster in time per pass.
There was a problem hiding this comment.
前面一段感觉没有说完?
By coordinating these processes, PaddlePaddle supports use both Synchronize Stochastic Gradient Descent (sync SGD) and Asynchronous Stochastic Gradient Descent (async SGD) to train user-defined neural network topologies.
|
|
||
| 检查点保存程序流程: | ||
|
|
||
| 1. 如果满足条件""每个pass或每n个mini-batch"时,parameter server会锁住保存parameter的内存,开始保存检查点。如果已经正在执行保存检查点的任务,则忽略。 |
There was a problem hiding this comment.
"如果已经正在执行保存检查点的任务,则忽略。"这个不是很理解,如果是自己安排的话,合适会出现“正在执行保存检查点的任务”?
There was a problem hiding this comment.
保存检查点应该是在一个线程中。已经增加更详细的描述。
|
|
||
| 检查点保存程序流程: | ||
|
|
||
| 1. 如果满足条件""每个pass或每n个mini-batch"时,parameter server会锁住保存parameter的内存,开始保存检查点。如果已经正在执行保存检查点的任务,则忽略。 |
There was a problem hiding this comment.
可以考虑换成读锁定(trainer下载parameter是读,只有上传gradient之后做的操作才是写)。
There was a problem hiding this comment.
的确。pserver是有多个线程在同时更新parameter的,使用读写锁会方便些。
|
|
||
| ``` | ||
| def paddle.train(batch_reader): | ||
| r = batch_reader() # create a interator for one pass of data |
There was a problem hiding this comment.
对不起,我之前interator打错了,应该是iterator。
| ## 训练数据的存储和分发 | ||
|
|
||
| ### 流程介绍 | ||
| 生产环境中的训练数据集通常体积很大,并被存储在诸如Hadoop HDFS, Ceph, AWS S3之类的分布式存储之上。这些分布式存储服务通常会把数据切割成多个分片分布式的存储在多个节点之上。这样就可以在云端执行多种数据类计算任务,包括: |
There was a problem hiding this comment.
能否吧"Hadoop HDFS, Ceph, AWS S3"改成"Hadoop HDFS,Ceph,AWS S3":)
对不起这个我有点挑刺了:),只是想让这个文档在每个细节都完美。
要是可以的话,括号也麻烦都用中文的全码括号:)
| 使用下面命令,可以把本地的训练数据上传到存储集群中 | ||
|
|
||
| ``` | ||
| paddle upload train_data.list |
There was a problem hiding this comment.
需要能够指定dataset name这个参数,因为之后reader是通过dataset name引用这个数据集的。
|
|
||
| ### 实现reader | ||
|
|
||
| reader的实现需要考虑本地训练程序实现之后,可以不修改程序直接提交集群进行分布式训练。要达到这样的目标,需要实现下面的功能: |
There was a problem hiding this comment.
坦白的说,下一段有些复杂我没看懂。如果为了追求不修改程序直接提交集群进行分布式训练,而把理解和使用变得复杂了,我觉得有点得不偿失。
另一种可能性是只用改reader,用户可以把local的reader注释掉,用新的reader:
reader = paddle.dist.reader("dataset-name")|
@typhoonzero Could you take a looks at these comments? Maybe you missed them: |
|
@typhoonzero 赞👍这么耐心的做修改! |
There was a problem hiding this comment.
LGTM++, some issue please fix before merging: #1696 (comment)
Inspired by #1620 added some of my thoughts.
Here may be better to view.