This repository contains the MPOSE2021 Dataset for short-time Human Action Recognition (HAR).

MPOSE2021 is developed as an evolution of the MPOSE Dataset [1-3]. It is made by human pose data detected by OpenPose [4] and Posenet [11] on popular datasets for HAR, i.e. Weizmann [5], i3DPost [6], IXMAS [7], KTH [8], UTKinetic-Action3D (RGB only) [9] and UTD-MHAD (RGB only) [10], alongside original video datasets, i.e. ISLD and ISLD-Additional-Sequences [1]. Since these datasets had heterogenous action labels, each dataset labels were remapped to a common and homogeneous list of 20 actions.
This repository allows users to directly access the POSE dataset (Section A.) or generate RGB and POSE data for MPOSE2021 in a python-friendly format (Section B.). Generated RGB and POSE sequences have a number of frames between 20 and 30. Sequences are obtained by cutting the so-called "precursor videos" (videos from the above-mentioned datasets), with non-overlapping sliding windows. Frames where OpenPose/PoseNet cannot detect any subject are automatically discarded. Resulting samples contain one subject at the time, performing a fraction of a single action.
Overall, MPOSE2021 contains 15429 samples, divided into 20 actions performed by 100 subjects. The overview of the action composition of MPOSE2021 is provided in the following image:
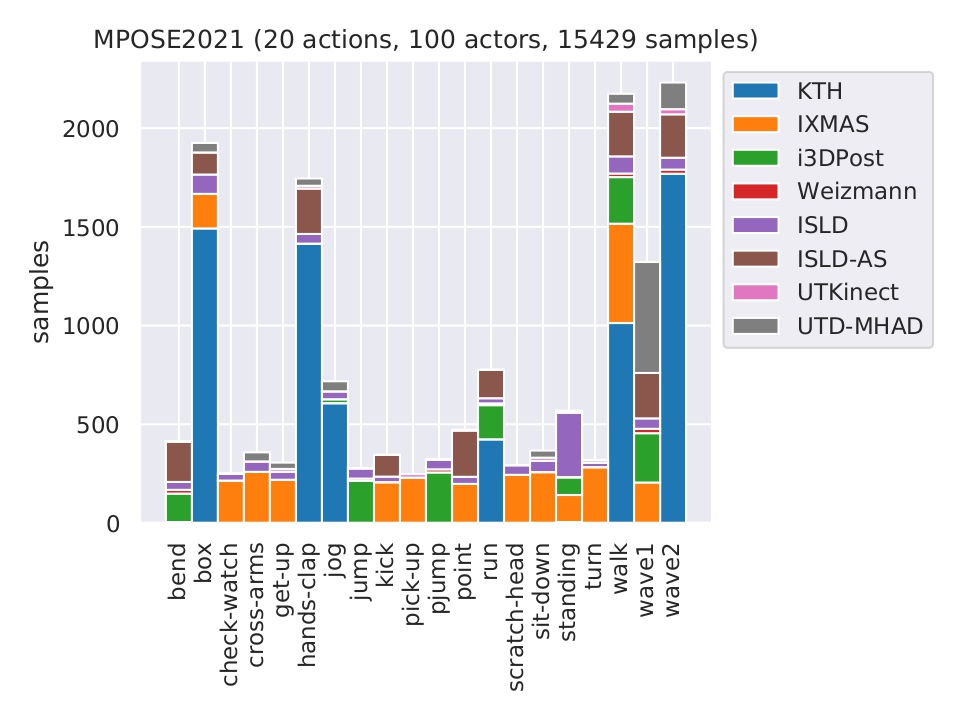
To get only MPOSE2021 POSE data, install our light and simple pip package
pip install mpose
And use the MPOSE class to download, extract, and process POSE data (Openpose/PoseNet).
# import package
import mpose
# initialize and download data
dataset = mpose.MPOSE(pose_extractor='openpose',
split=1,
transform='scale_and_center',
data_dir='./data/')
# print data info
dataset.get_info()
# get data samples (as numpy arrays)
X_train, y_train, X_test, y_test = dataset.get_dataset()Check out the package documentation and this Colab Notebook Tutorial for more hands-on examples . The source code can be found in the mpose_api subfolder.
The following requirements are needed to generate RGB data for MPOSE2021 (tested on Ubuntu):
- around 340 GB free disk space (330 GB for archives and temporary files, 10 GB for VIDEO, RGB and POSE data)
- Python 3.6+
You can get both RGB and the corresponding POSE data running a simple python script. For licence-related reasons, the user must manually download precursor dataset archives from the original sources, as explanined in the following steps.
-
Clone this repository.
-
Create a virtual environment (optional, but recommended).
-
Download RGB archives from the following third-party repositories:
- IXMAS Dataset
- Download "original IXMAS ROIs" archive
- Save the archive into "archives_path"/ixmas/
- Weizmann Dataset
- Download actions: Walk, Run, Jump, Bend, One-hand wave, Two-hands wave, Jump in place
- Save the archives into "archives_path"/weizmann/
- i3DPost Dataset
- Request ID and Password to the authors
- Download all archives related to actions: Walk, Run, Jump, Bend, Hand-wave, Jump in place
- Save the archives into "archives_path"/i3DPost/
- KTH Dataset
- Download archives "walking.zip", "jogging.zip", "running.zip", "boxing.zip", "handwaving.zip", "handclapping.zip"
- Save the archives into "archives_path"/kth/
- ISLD Dataset
- Download archive
- Save the archive into "archives_path"/isld/
- ISLD-Additional-Sequences Dataset
- Download archive
- Save the archive into "archives_path"/isldas/
- UTKinect-Action3D Dataset
- Download archive (RGB images only)
- Save the archive into "archives_path"/utkinect/
- UTD-MHAD Dataset
- Downlad archive (RGB images only)
- Save the archive into "archives_path"/utdmhad/
- IXMAS Dataset
-
Download POSE archives:
- OpenPose (obtained by using OpenPose v1.6.0 portable demo for Windows to process MPOSE2021 precursor VIDEO data)
- Download "json.zip" archive
- Save the archive into "archives_path"/json/
- PoseNet (obtained by using PoseNet ResNet-50 (288x416x3) running on a Coral accelerator to process MPOSE2021 precursor VIDEO data)
- Download "posenet.zip" archive
- Save the archive into "archives_path"/posenet/
- OpenPose (obtained by using OpenPose v1.6.0 portable demo for Windows to process MPOSE2021 precursor VIDEO data)
-
Install python requirements:
pip install -r requirements.txt
-
Setup variables in "init_vars.py":
- "dataset_path": where you want the dataset to be exported
- "data_path": where you want to store all the data (leave as default)
-
Run dataset extraction and processing:
python main.py- Arguments:
--mode-m: operation to performinit: initialize folders, files and variablesextract: init + extract archives and prepare them for dataset generationgenerate: extract + generate RGB and POSE data (+ 3 different .csv files for train/test splitting)check: init + check data integrity and generate summary figures
--pose-p: pose detectoropenpose: OpenPoseall: OpenPose + PoseNet
--force-f: force the execution of unnecessary operations--verbose-v: print more information
MPOSE2021 is intended for scientific research purposes. If you want to use MPOSE2021 for publications, please cite our work (Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition) as well as [1-11].
@article{mazzia2021action,
title={Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition},
author={Mazzia, Vittorio and Angarano, Simone and Salvetti, Francesco and Angelini, Federico and Chiaberge, Marcello},
journal={Pattern Recognition},
pages={108487},
year={2021},
publisher={Elsevier}
}
[1] Angelini, F., Fu, Z., Long, Y., Shao, L., & Naqvi, S. M. (2019). 2D Pose-Based Real-Time Human Action Recognition With Occlusion-Handling. IEEE Transactions on Multimedia, 22(6), 1433-1446.
[2] Angelini, F., Yan, J., & Naqvi, S. M. (2019, May). Privacy-preserving Online Human Behaviour Anomaly Detection Based on Body Movements and Objects Positions. In ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 8444-8448). IEEE.
[3] Angelini, F., & Naqvi, S. M. (2019, July). Joint RGB-Pose Based Human Action Recognition for Anomaly Detection Applications. In 2019 22th International Conference on Information Fusion (FUSION) (pp. 1-7). IEEE.
[4] Cao, Z., Hidalgo, G., Simon, T., Wei, S. E., & Sheikh, Y. (2019). OpenPose: Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. IEEE transactions on pattern analysis and machine intelligence, 43(1), 172-186.
[5] Gorelick, L., Blank, M., Shechtman, E., Irani, M., & Basri, R. (2007). Actions as Space-Time Shapes. IEEE transactions on pattern analysis and machine intelligence, 29(12), 2247-2253.
[6] Starck, J., & Hilton, A. (2007). Surface Capture for Performance-Based Animation. IEEE computer graphics and applications, 27(3), 21-31.
[7] Weinland, D., Özuysal, M., & Fua, P. (2010, September). Making Action Recognition Robust to Occlusions and Viewpoint Changes. In European Conference on Computer Vision (pp. 635-648). Springer, Berlin, Heidelberg.
[8] Schuldt, C., Laptev, I., & Caputo, B. (2004, August). Recognizing Human Actions: a Local SVM Approach. In Proceedings of the 17th International Conference on Pattern Recognition, 2004. ICPR 2004. (Vol. 3, pp. 32-36). IEEE.
[9] Xia, L., Chen, C. C., & Aggarwal, J. K. (2012, June). View Invariant Human Action Recognition using Histograms of 3D Joints. In 2012 IEEE computer society conference on computer vision and pattern recognition workshops (pp. 20-27). IEEE.
[10] Chen, C., Jafari, R., & Kehtarnavaz, N. (2015, September). UTD-MHAD: A Multimodal Dataset for Human Action Recognition utilizing a Depth Camera and a Wearable Inertial Sensor. In 2015 IEEE International conference on image processing (ICIP) (pp. 168-172). IEEE.
[11] Papandreou, G., Zhu, T., Chen, L. C., Gidaris, S., Tompson, J., & Murphy, K. (2018). Personlab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model. In Proceedings of the European Conference on Computer Vision (ECCV) (pp. 269-286).
[12] Mazzia, V., Angarano, S., Salvetti, F., Angelini, F., & Chiaberge, M. (2021). Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition. Pattern Recognition, 108487.