by Zhaowei Cai, Xiaodong He, Jian Sun and Nuno Vasconcelos.
This implementation is written by Zhaowei Cai at UC San Diego.
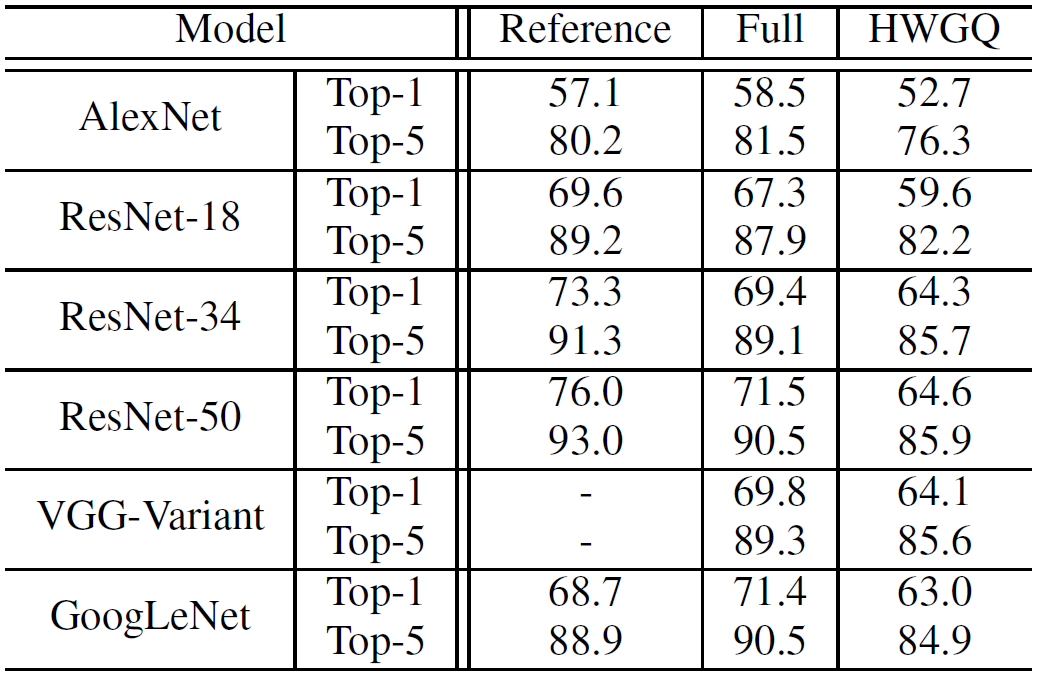
HWGQ-Net is a low-precision neural network with 1-bit binary weights and 2-bit quantized activations. It can be applied to many popular network architectures, including AlexNet, ResNet, GoogLeNet, VggNet, and achieves closer performance to the corresponding full-precision networks than previously available low-precision networks. Theorectically, HWGQ-Net has ~32x memory and ~32x convoluational computation savings, suggesting that it can be very useful for the deployment of state-of-the-art neural networks in real world applications. More details can be found in our paper.
If you use our code/model/data, please cite our paper:
@inproceedings{cai17hwgq,
author = {Zhaowei Cai and Xiaodong He and Jian Sun and Nuno Vasconcelos},
Title = {Deep Learning with Low Precision by Half-wave Gaussian Quantization},
booktitle = {CVPR},
Year = {2017}
}
-
Clone the HWGQ repository, and we'll call the directory that you cloned HWGQ into
HWGQ_ROOTgit clone https://github.com/zhaoweicai/hwgq.git
-
Build HWGQ
cd $HWGQ_ROOT/ # Follow the Caffe installation instructions here: # http://caffe.berkeleyvision.org/installation.html # If you're experienced with Caffe and have all of the requirements installed # and your Makefile.config in place, then simply do: make all -j 16
-
Set up ILSVRC2012 dataset following Caffe ImageNet instruction.
You can start training HWGQ-Net. Take AlexNet for example.
cd $HWGQ_ROOT/examples/imagenet/alex-hwgq-3ne-clip-poly-320k/
sh train_alexnet_imagenet.shThe other network architectures are available, including ResNet-18, ResNet-34, ResNet-50, GoogLeNet and VggNet. To train deeper networks, you need multi-GPU training. If multi-GPU training is not available to you, consider to change the batch size and the training iterations accordingly. You can get very close performance as in our paper.
Most of the ablation experiments in the paper can be reproduced. The training scripts for running BW+sign ($HWGQ_ROOT/examples/imagenet/alex-sign-step-160k) in Table 2 and 2-bit non-uniform/uniform BW+HWGQ ($HWGQ_ROOT/examples/imagenet/alex-hwgq-2n-clip-step-160k and $HWGQ_ROOT/examples/imagenet/alex-hwgq-3ne-clip-step-160k) in Table 4 of AlexNet are provided here for reproduction.
-
These models are compatible with the provided training/finetuning scripts. The weights of the models here are not binarized yet. Binarization happens during running.
-
The weights of the models here are already binarized, and are compatible with standard convolutions. The deploy_bw.prototxt can be found in the corresponding folders. These models can be used for deployment.
If you encounter any issue when using our code/model, please let me know.