[WIP] Tutorial completo sobre versionamento com GIT
Nos primórdios, uma equipe de desenvolvimento trabalhava de forma rustica, programando com o notepad e compartilhando o trabalho com a equipe via disquete (ewwww). Imagina o trabalho de juntar manualmente dois códigos que se complementavam, porém feitos por duas pessoas distintas. É de se imaginar que dava um certo trabalho.
Com o tempo vieram novas tecnologias para ajudar o pobre programador em suas tarefas diarias, como IDEs (ferramentas de desenvolvimento que substituem absolutamente o notepad na hora de programar) e também vieram ferramentas de versionamento. E é exatamente sobre esta última ferramenta que este guia irá se direcionar.
De forma sucinta, é uma ferramenta que gerencia toda a vida de um dado projeto, guardando o histórico, ou versão, de cada documento do projeto. Lembrando que documento pode ser qualquer coisa, uma imagem, um código, um pdf, etc.
O GIT é uma ferramenta de versionamento amplamente utilizada em projetos com grande número de colaboradores, sem contar que é a plataforma na qual roda o GITHUB, serviço online que provê um servidor GIT gratuito para projetos opensource. Assim sendo, este será a ferramenta utilizada no projeto.
Agora, sem mais delongas, vamos ao real tutorial de como utilizar o GIT.
O GIT trabalha com um servidor principal, o que no nosso caso será github, e inúmeros sub-servidores, para cada um que estiver trabalhando no projeto. A idéia é que tu tenha um servidor em sua máquina e que vá trabalhando nele, e quando tiver terminando teu trabalho, tu suba suas alterações então para o servidor principal. Difícil de entender? Então deixe-me ver se uma imagem ajuda:
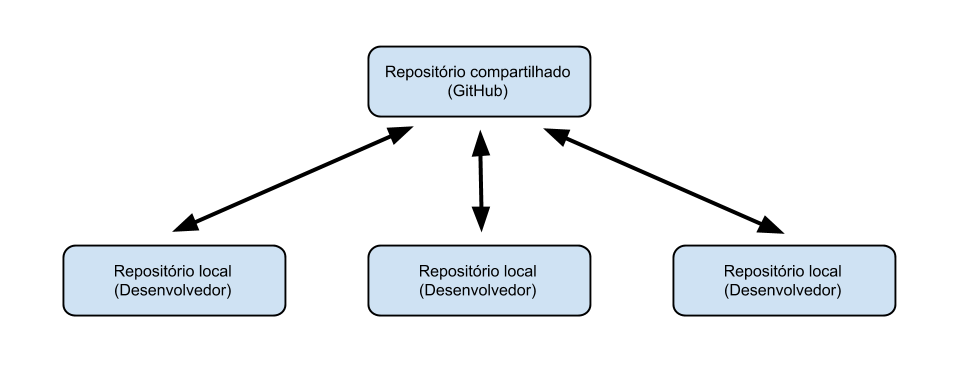
Cada um destes servidores, é chamado de repositório e te da direito a manter um histórico de versões de seus documentos.
Antes de explicar para vocês qual o fluxo para se trabalhar no GIT, vou passar rapidamente pelos principais comandos e conceitos da ferramenta. Se agora ficar um pouco confusão, continue a leitura nas próximas seções e sinta-se livre para voltar a esta seção quando desejar. Ah sim, estarei utilizando o termo em inglês, pois é o termo mais utilizado no ramo. Enfim, vamos lá:
- Clone: Não, não voltamos a tentativa de clonar o seres vivos, este comando serve para criar um repositório na sua máquina local que seja uma cópia de um repositório em um servidor, no caso o github. Em outras palavras, o comando clone faz download do código que está no servidor, mas ao mesmo tempo cria um repositório na sua máquina. Lembra da imagem da estrutura di GIT? Então, com este comando você está criando uma nova caixinha "Repositório local (Desenvolvedor" na sua máquina.
- Branch: Branch seria uma vertente do teu código. O melhor paralelo que posso usar explicar, seria Universos paralelos! Uma branch seria um universo paralelo onde o seu arquivo/diretório existe. Isto também é um comando, e quando este comando é executado adivinha? Exato, você cria um novo Universo paralelo! (E ainda dizem que minha profissão não é divertida hahahahaha) Esse novo Universo paralelo irá conter um novo código enquanto na principal vertente, chamada master, o código pode continuar a "vida" normalmente.
- Checkout: Este comando serve para você escolher em qual Branch (ou Universo paralelo hehe) você está agindo agora. Ou seja, você configura qual a Branch vigente no Repositório local.
- Add: Este comando adiciona um arquivo ou diretório no Repositório local, na Branch vigente do mesmo, é como você disesse pro repositório "Hey repositório, eu tenho um arquivo/diretório novo aqui e quero que você guarde ele para mim, segura ele, mas não guarda ainda não tá?". Repare que o repositório não terá ainda teu arquivo, ele apenas saberá que ele existe.
- Commit: Agora sim, você está entregando o arquivo/diretório para que o repositório guarde-o. Mas novamente, vale notar que este arquivo só está versionado (guardado), no Repositório local, na Branch vigente.
- Revert: Apesar de não ser exatamente o nome de um comando no GIT, este é um conceito importante, que diz respeito a você desfazer algo no repositório. Vamos supor que o desenvolvedor começou a fazer um código na máquina local, porém após horas e horas com aquilo, ele se depara que a idéia ou lógica pela qual ele estava se guiando não era boa e que era melhor jogar fora apenas esse pedaço de código que ele criou até então e recomeçar do zero. Neste cenário ele precisaria então fazer um revert no código para a versão que o repositório guardou, e então recomeçar a trabalhar.
- Pull: Este comando baixa os documentos mais atuais do servidor, no caso o github, para o Repositório local e Branch vigente (eu sei, ta ficando repetitivo esta combinação de palavras, mas é importante enfatizar isso hehe).
- Push: E agora, não menos importante, o grande comando push. Este comando é semelhante ao comando commit, mas agora ele envia tudo que está no seu Repositório local e Branch vigente para o repositório do servidor (github). Ou seja, só após você executar este comando é que as pessoas do projeto conseguirá ver o que tu fez até então!
E esses são os principais comandos e conceitos do GIT. Agora que sabemos o que cada um significa, temos que ver como que eles funcionando na prática, certo? Então segure-se bem e me acompanhe ;P
Nesta seção irei detalhar agora com calma alguns dos fluxos de trabalho utilizando o GIT. Eu dominio muito mais o primeiro da lista, que é o mais básico, no caso, o Fluxo de Trabalho Centralizado, mas nada impede de usarmos outro fluxo no projeto. Lembrando que estes fluxos são descritos no próprio manual do GIT.
O fluxo de trabalho centralizado é o mais familiar para aqueles que vieram de outras ferramentas de versionamento mais antigas, como o CVS ou SVN. Nele você tem apenas um único servidor, e diversas pessoas trabalhando em seus repositórios locais e enfim subindo os documentos para o repositório principal (servidor).
Explicando detalhadamente desde o inicio da vida de um repositório com Fluxo de trabalho centralizado, ele funcionaria desta forma:
- É criado um repositório novo no servidor para o projeto X.
- Cada membro da equipe clona o repositório em sua máquina local.
- Para cada tarefa ou subtarefa que for feita, cada membro da equipe cria uma nova branch em seu repositório local (lembrando de dar um nome intuitivo para a branch) e logo em seguida efetua um checkout para a nova branch criada.
- Então cada um segue com sua atividade e a medida que desejar, a pessoa adiciona e realiza commit de suas alterações, para que o repositório local guarde o histórico do que foi feito. Este passo é executado até que a tarefa ou subtarefa esteja concluida.
- Após a tarefa estar concluido e feito o commit no repositório local, o membro da equipe faz checkout para a branch principal, no caso, a branch master e realiza o comando pull para atualizar seu repositório local com os documentos mais novos feitos pela equipe.
- Feito o pull, deve-se então realizar o merge da branch criada no 3º passo com a branch master, juntando assim os documentos em seu repositório local.
- Por fim, é realizado o comando push para que suas alterações sejam enviadas ao repositório central, o que no nosso caso seria o github.
- Após feito o push, a pessoa pode apagar a branch criada (se desejar) e então deve escolher uma nova tarefa ou subtarefa e voltar ao 3º passo. E isso continua até que o projeto esteja concluído.
Este fluxo se chama Fluxo de Trabalho Centralizado, pois temos um único repositório servidor servindo como centralizador do código entre as equipes de desenvolvimento. É um fluxo bastante utilizado em mundo corporativo onde temos uma equipe pequena trabalhando. Porém mostra-se inviável em grandes projetos opensource, como por exemplo o projeto do kernel do GNU Linux.
O legal é que o GIT, mesmo sendo mais novo, lida melhor com conflitos se for usado este fluxo, do que se você usar um versionador puramente centralizado, como o CVS ou SVN. O que quero dizer com isso é que se este fluxo for seguido da maneira descrita acima (existem outras formas de seguir com este fluxo), dificilmente a pessoa irá se deparar com um conflito, que nada mais é do que quando mais de uma pessoa altera um mesmo arquivo ao mesmo tempo em paralelo, e uma sobe primeiro e quando a segunda atualiza seus documentos para só então subir suas alterações, o versionador não permite pois não sabe dizer qual arquivo é o correto, e então a pessoa tem que fazer merge manualmente entre os dois arquivos para só então subir no servidor.