The application uses gaze detection points with the use of deep learning model to estimate the gaze of user's eyes to move the mouse pointer position. It supports camera video stream and video file as input.
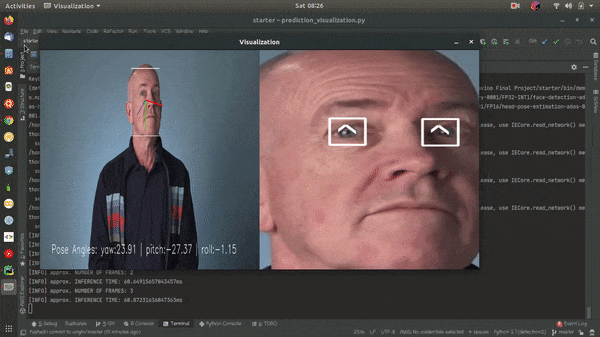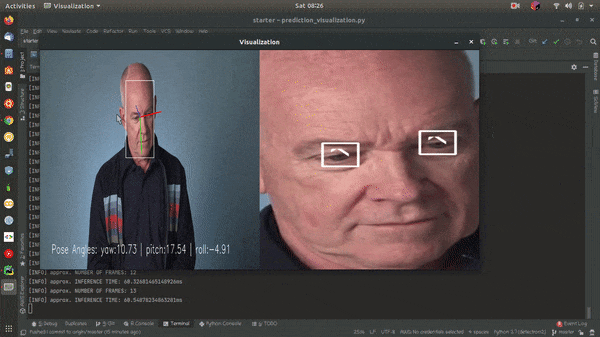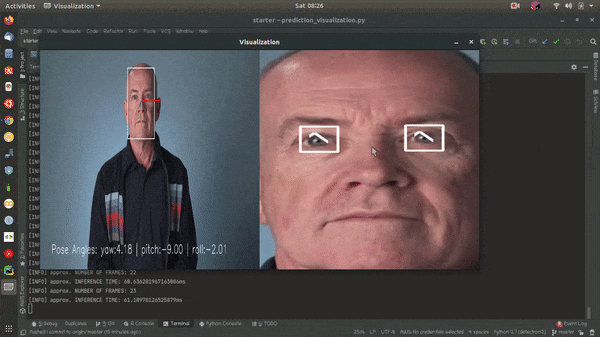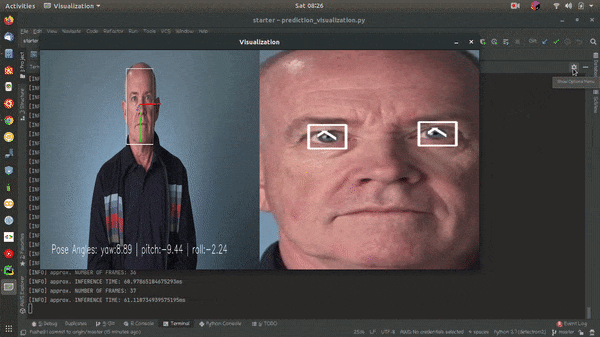
OpenVINO™ toolkit and its dependencies must be installed to run the application. OpenVINO 2020.2.130 is used on this project.
Installation instructions may be found at:
- https://software.intel.com/en-us/articles/OpenVINO-Install-Linux
- https://github.com/udacity/nd131-openvino-fundamentals-project-starter/blob/master/linux-setup.md
There are certain pretrained models you need to download after initializing the openVINO environment:
source /opt/intel/openvino/bin/setupvars.sh
- Face Detection Model
- Facial Landmarks Detection Model
- Head Pose Estimation Model
- Gaze Estimation Model
To download the above pretrained model, run the following commands after creating model folder in the project directory and cd into it:
Face Detection
$ python3 /opt/intel/openvino/deployment_tools/tools/model_downloader/downloader.py --name "face-detection-adas-binary-0001"
Head Pose Estimation
$ python3 /opt/intel/openvino/deployment_tools/tools/model_downloader/downloader.py --name "head-pose-estimation-adas-0001"
Gaze Estimation Model
$ python3 /opt/intel/openvino/deployment_tools/tools/model_downloader/downloader.py --name "gaze-estimation-adas-0002"
Facial Landmarks Detection
$ python3 /opt/intel/openvino/deployment_tools/tools/model_downloader/downloader.py --name "landmarks-regression-retail-0009"
Install the requirements
Install the requirements
Project structure
|--bin
|--demo.mp4
|--model
|--src
|--base.py
|--prediction_visualization
|--face_detection.py
|--facial_landmarks_detection.py
|--gaze_estimation.py
|--head_pose_estimation
|--input_feeder.py
|--main.py
|--mouse_controller.py
|--README.md
|--requirements.txt
Use the following command to run the application
python3 src/main.py -i 'bin/demo.mp4' -fld 'models/intel/landmarks-regression-retail-0009/FP16/landmarks-regression-retail-0009.xml' -fd 'models/intel/face-detection-adas-binary-0001/FP32-INT1/face-detection-adas-binary-0001.xml' -ge 'models/intel/gaze-estimation-adas-0002/FP16/gaze-estimation-adas-0002.xml' -hp 'models/intel/head-pose-estimation-adas-0001/FP16/head-pose-estimation-adas-0001.xml'
command line parameters
$ python3 main.py --help
usage: main.py [-h] -fd FACE_DETECTION_MODEL -fld FACIAL_LANDMARK_MODEL -ge
GAZE_ESTIMATION_MODEL -hp HEAD_POSE_MODEL -i INPUT
[-l CPU_EXTENSION] [-prob PROB_THRESHOLD] [-d DEVICE]
[-v VISUALIZATION]
optional arguments:
-h, --help show this help message and exit
-fd FACE_DETECTION_MODEL, --face_detection_model FACE_DETECTION_MODEL
Path to .xml file of Face Detection model.
-fld FACIAL_LANDMARK_MODEL, --facial_landmark_model FACIAL_LANDMARK_MODEL
Path to .xml file of Facial Landmark Detection model.
-ge GAZE_ESTIMATION_MODEL, --gaze_estimation_model GAZE_ESTIMATION_MODEL
Path to .xml file of Gaze Estimation model.
-hp HEAD_POSE_MODEL, --head_pose_model HEAD_POSE_MODEL
Path to .xml file of Head Pose Estimation model.
-i INPUT, --input INPUT
Path to video file or enter cam for webcam
-l CPU_EXTENSION, --cpu_extension CPU_EXTENSION
path of extensions if any layers is incompatible with
hardware
-prob PROB_THRESHOLD, --prob_threshold PROB_THRESHOLD
Probability threshold for model to identify the face .
-d DEVICE, --device DEVICE
Specify the target device to run on: CPU, GPU, FPGA or
MYRIAD is acceptable. Sample will look for a suitable
plugin for device (CPU by default)
-v VISUALIZATION, --visualization VISUALIZATION
Set to True to visualization all different model
outputs
Measuring performance (Start inference asyncronously, 4 inference requests using 4 streams for CPU, limits: 60000 ms duration)
Hardware Configuration: Intel® Core™ i5-6200U CPU @ 2.30GHz × 4
face-detection-adas-binary-0001
FP32
- Count: 5320 iterations
- Duration: 60037.26 ms
- Latency: 42.58 ms
- Throughput: 88.61 FPS
gaze-estimation-adas-0002
FP16-INT8
- Count: 78160 iterations
- Duration: 60002.77 ms
- Latency: 2.89 ms
- Throughput: 1302.61 FPS
FP16
- Count: 51312 iterations
- Duration: 60007.48 ms
- Latency: 4.43 ms
- Throughput: 855.09 FPS
FP32
- Count: 48736 iterations
- Duration: 60007.04 ms
- Latency: 4.48 ms
- Throughput: 812.17 FPS
head-pose-estimation-adas-0001
FP16
- Count: 62812 iterations
- Duration: 60004.12 ms
- Latency: 3.55 ms
- Throughput: 1046.79 FPS
FP16-INT8
- Count: 81888 iterations
- Duration: 60004.36 ms
- Latency: 2.79 ms
- Throughput: 1364.70 FPS
FP32
- Count: 55084 iterations
- Duration: 60005.58 ms
- Latency: 3.63 ms
- Throughput: 917.98 FPS
landmarks-regression-retail-0009
FP16
- Count: 335108 iterations
- Duration: 60001.13 ms
- Latency: 0.68 ms
- Throughput: 5585.03 FPS
FP16-INT8
- Count: 295848 iterations
- Duration: 60000.93 ms
- Latency: 0.72 ms
- Throughput: 4930.72 FPS
FP32
- Count: 322800 iterations
- Duration: 60000.69 ms
- Latency: 0.67 ms
- Throughput: 5379.94 FPS
From the above results, the best model precision combination is that of Face detection 32 bits precision with other models in 16 bits. This reduce the model size and load time, although models with lower precision gives low accuracy but better inference time.
- I enabled user to select video or camera as input to the application.
- I used openvino benchmark to discover the best model precision combination to use, in order to improve inference time and accuracy
If you have used Async Inference in your code, benchmark the results and explain its effects on power and performance of your project.
There will be certain situations that will break your inference flow. For instance, lighting changes or multiple people in the frame. Explain some of the edge cases you encountered in your project and how you solved them to make your project more robust.