{kind=link}
{kind=link}
{kind=link}
{kind=link}
Jojona , SarishiNoHara , safiyashen , LayNeverGiveUp.
Owner: Web Information Systems (Jie Yang)
Unlike traditional software systems, recommender systems are automated by machine learning programs. These programs are created mainly to train recommendation models that can learn statistical patterns – what is relevant to whom – from historical data, and later on to generate relevant recommendations to users. A largely neglected issue is the lack of model and algorithmic transparency, which can lead to a vital concern of trust. On the one hand, users may not trust the recommendations if they do not understand the reasons behind the recommendations. On the other hand, the difficulty in assessing trust makes it risky when developers choose to deploy a new recommendation model. Human can be the key to address the transparency issue in recommender systems: while machines are computational efficient and scalable, humans excel at generating ideas and verbalizing explanation.
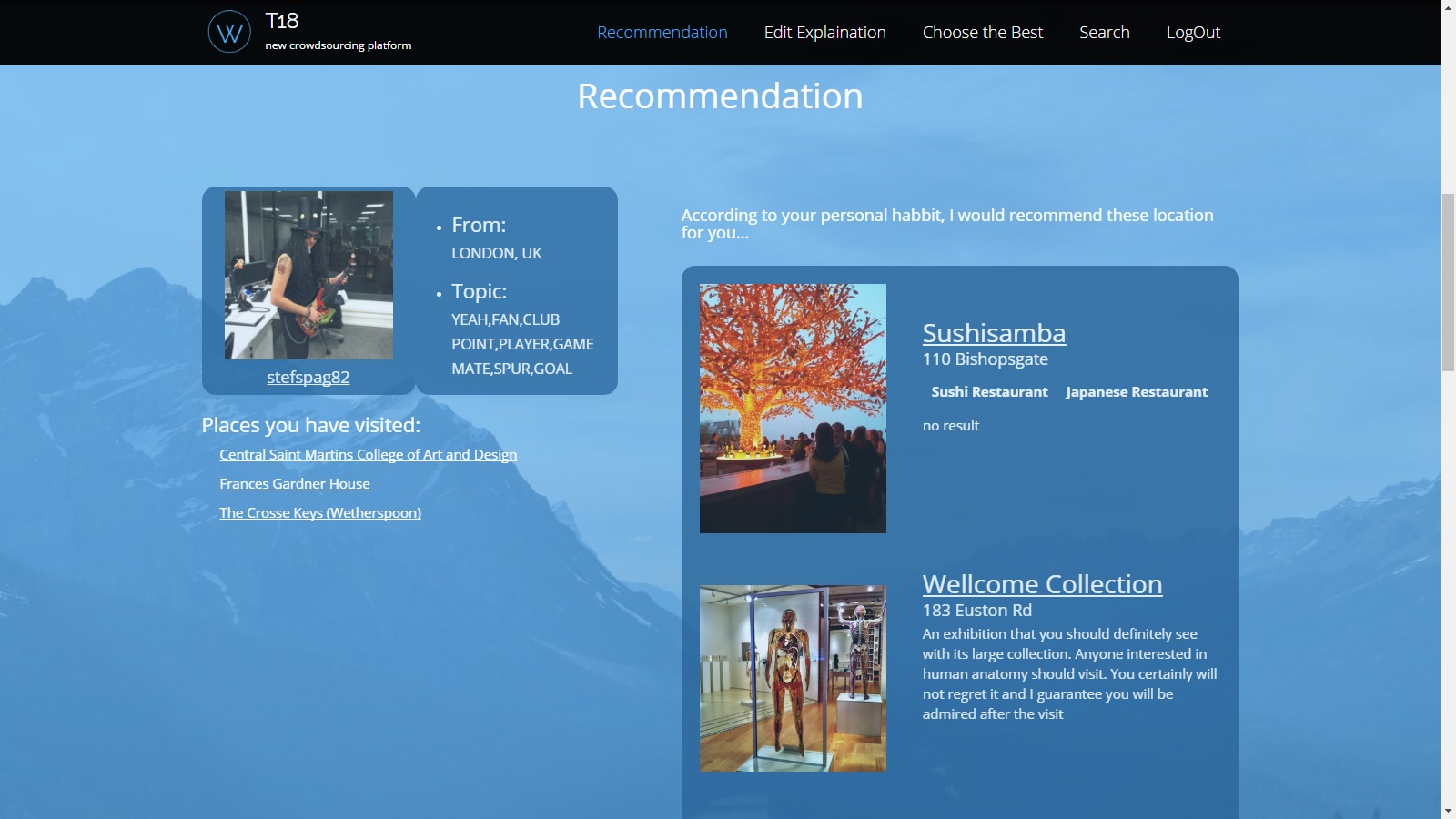
Assignment: design and implement a recommender system that actively involves humans in generating explanations.
Datasources: Data to be used should come from public data sources. Following are two available datasets on cities and online products, respectively. POI recommendation. This dataset contains user visits to POI in four major European cities (Amsterdam, Paris, Rome, London), crawled from two platforms (Twitter, Instagram), over three weeks. Amazon product data. This dataset contains user ratings and reviews to Amazon online products, organized in categories (Clothing, Electronics, Sports, etc.). Link: http://jmcauley.ucsd.edu/data/amazon/. Note: this dataset is only available by request. Please contact Julian McAuley ([email protected]) to obtain a link.
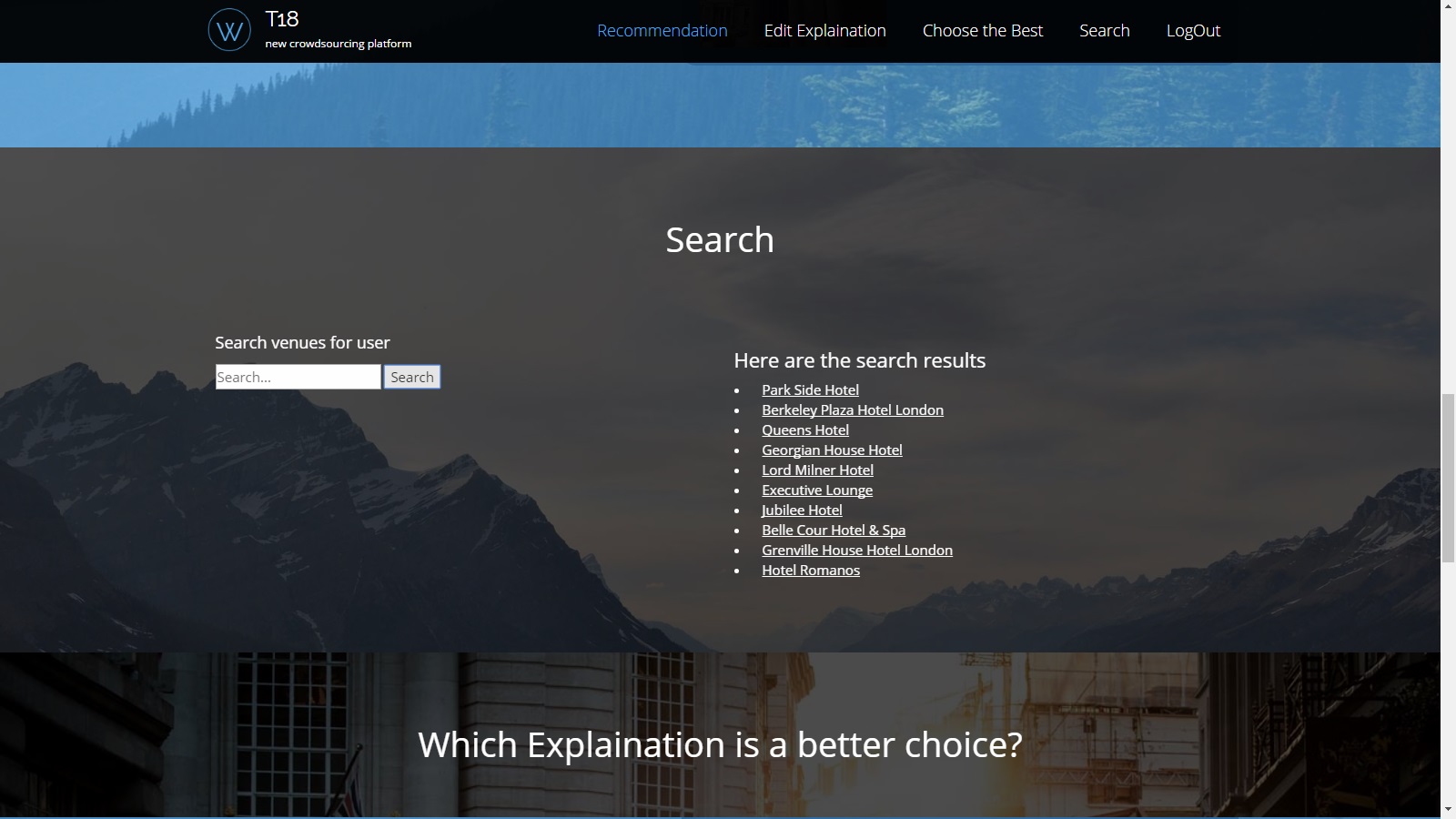
Processing pipeline: Each project should design, develop, and implement a data processing pipeline that involves the preprocessing, indexing and enrichment of data. In order to generate reasonable explanations, the data should contain a rich set of features of users/items as the input for humans to generate explanations. For example, the city dataset can be enriched with user profile & posts that can be retrieved from Twitter and Instagram, and POI attributes retrieved from Foursquare.
Recommendation: Information will be retrieved from an ElasticSearch instance. Use open-source recommendation libraries (e.g. LibRec, GraphLab) for generating recommendations.
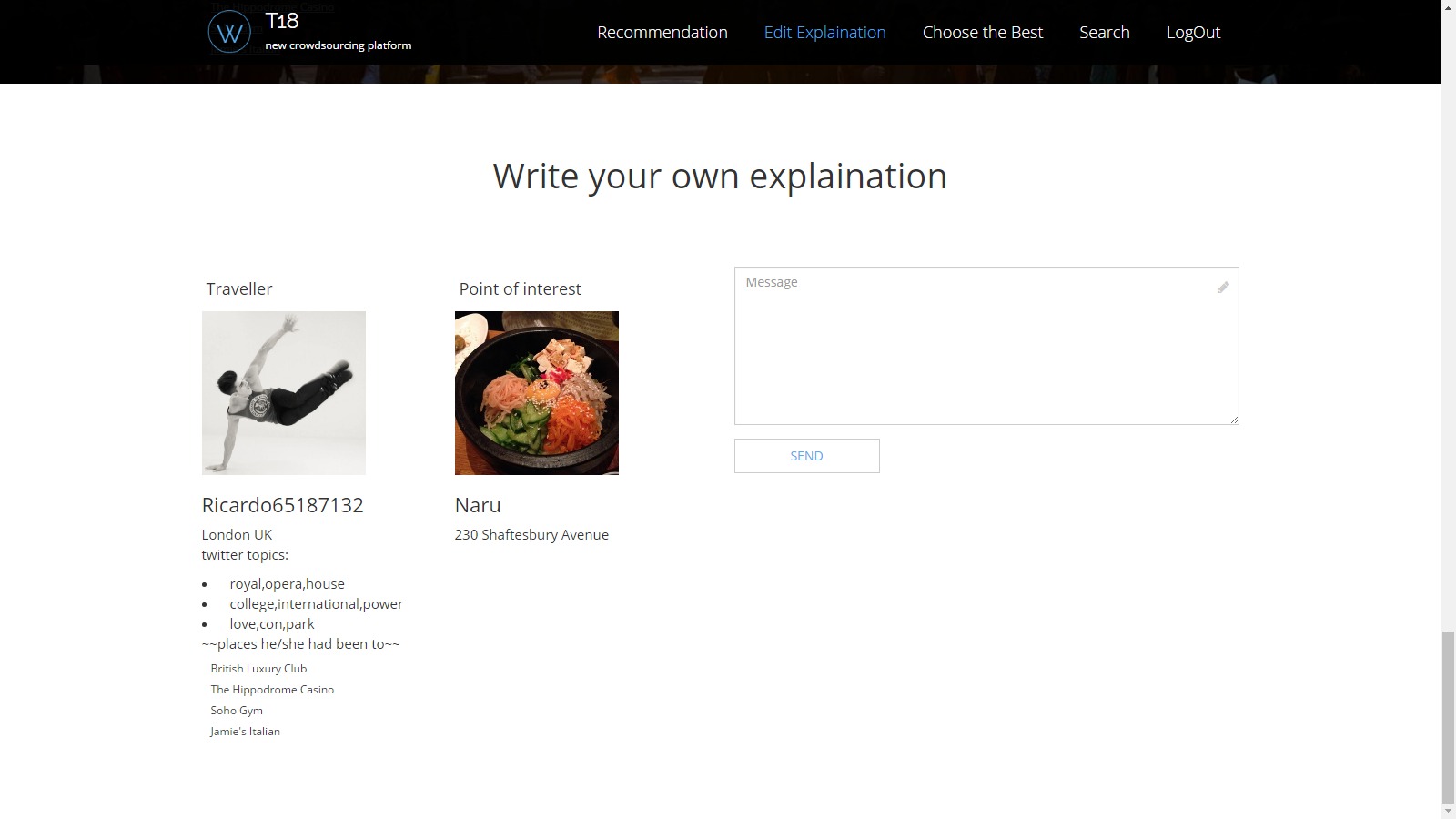
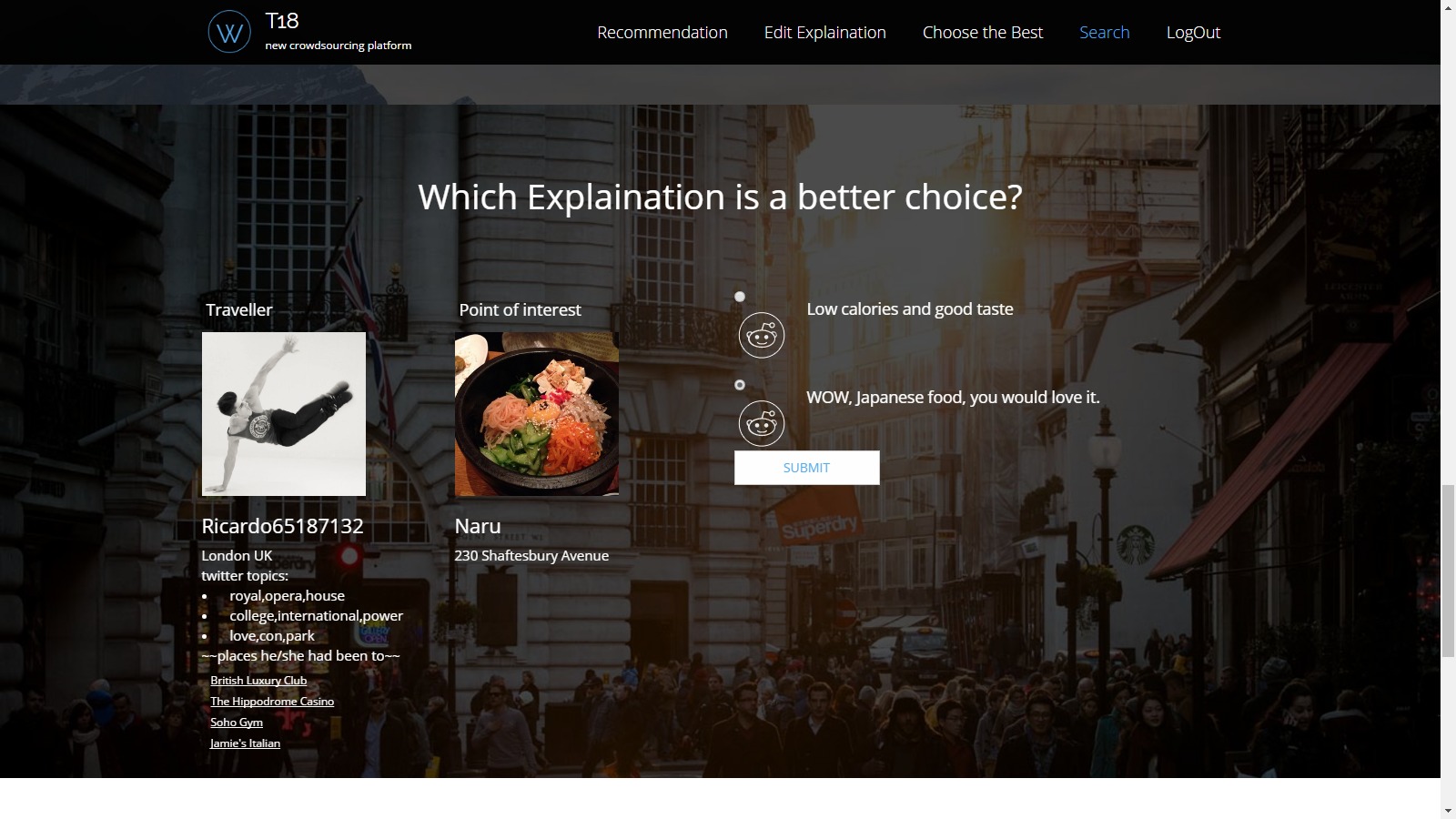
Human computation: Design a human computation task to involve humans in generating explanations. The task should be available for execution through a Web interface that can either be part of the recommender system itself or hosted on crowdsourcing platforms (however the results can be seamlessly plugged into the recommender system).