Project Page: http://guanghan.info/projects/ROLO/
ROLO is short for Recurrent YOLO [1], aimed at simultaneous object detection and tracking.
With the regression capability of LSTMs both spatially and temporally, ROLO is able to interpret a series of high-level visual features directly into coordinates of tracked objects. By concatenating high-level visual features with YOLO detection results, ROLO is spatially supervised into specific targets.
The regression is two-folds: (1) The regression within one unit, i.e., between the visual features and the concatenated region representations. LSTM is capable of inferring region locations from the visual features when they are concatenated to be one unit. (2) The regression over the units of a sequence, i.e., between concatenated features over a sequence of frames.
The supervision is helpful in two aspects: (1) When LSTM interpret the high-level visual features, the preliminary location inference helps to regress the features into the location of a certain visual elements/cues. The spatially supervised regression acts as an online appearance model. (2) Temporally, the LSTM learns over the sequence units to restrict the location prediction to a spatial range.
ROLO is currently an offline approach, and is expected to gain a performance boost with proper online model updating. It is still a single object tracker, and data association techniques are not yet explored for the simultaneous tracking of multiple targets.
- Python 2.7 or Python 3.3+
- Tensorflow
- Scipy
As a generic object detector, YOLO can be trained to recognize arbitrary objects. Nevertheless, as the performance of ROLO depends on the YOLO part, we choose the default YOLO small model in order to provide a fair comparison. We believed it unfair to give credit to the tracking module if we train a customized YOLO model. The model is pre-trained on ImageNet dataset and finetuned on VOC dataset, capable of detecting objects of only 20 classes. We therefore picked 30 out of 100 videos from the benchmark OTB100, where the tracking targets belong to these classes. The subset is so-called OTB30.
DATA
Models
Evaluation
Reproduce the results with the pre-trained model:
python ./experiments/testing/ROLO_network_test_all.py
Or download the results at Results.
Run video Demo:
./python ROLO_demo_test.py
As deep learning applications get mature, it will be more efficient to have multi-functional networks consisted of orthogonal modules. Feature representation, in this case, had better be trained separately to provide shared features. Pre-training of visual features from ImageNet are skipped, as were discussed already in YOLO. We focus on training the LSTM module.
Experiment 1:
The limitation of offline tracking is that the offline models need to be trained with large amounts of data, which is hard to find in publicly available object tracking benchmarks. Even considering the whole 100 videos of OTB100 [2], the amount is still smaller than that of image recognition tasks by order of magnitudes. Therefore trackers are prone to over-fitting.
In order to test the generalization ability of ROLO, we conduct experiment 1. Training on 22 videos and testing on the rest 8 videos of OTB30, the model is able to outperform all the traditional trackers from the benchmark [2].
We also test on 3 additional videos that are not selected for OTB30, as their ground truth is face but not human body. Since face is not included in the default YOLO model, YOLO will detect human body instead and ROLO will be supervised to track the human body. Demo videos are available here. Video 1, Video 2, Video 3.
<iframe width="420" height="315" src="https://www.youtube.com/embed/7dDsvVEt4ak" frameborder="0" allowfullscreen></iframe>To reproduce experiment 1:
-
Training:
python ./experiments/training/ROLO_step6_train_20_exp1.py -
Testing:
python ./experiments/testing/ROLO_network_test_all.py
Experiment 2:
If the model is inevitably trained with limited data, one way to remedy this is to train the model with similar dynamics. (Same strategy is used by trackers that employ online model updating). We train a 2nd LSTM model with the first 1/3 frames of OTB30 and test on the rest frames. Results show that performance has improved. We find that, once trained on auxiliary frames with the similar dynamics, ROLO will perform better on testing sequences. This attribute makes ROLO especially useful in surveillance environments, where models can be trained offline with pre-captured data.
To reproduce experiment 2:
-
Training:
python ./experiments/training/ROLO_step6_train_30_exp2.py -
Testing:
python ./experiments/testing/ROLO_network_test_all.py
Experiment 3:
Considering this attribute observed in experiment 2, we experiment incrementing training frames. Training with full frames but using only 1/3 ground truths will give an additional boost to the performance.
To reproduce experiment 3:
-
Training:
python ./experiments/training/ROLO_step6_train_30_exp3.py -
Testing:
python ./experiments/testing/ROLO_network_test_all.py
Limitations
Note that experiment 2&3 use 1/3 training frames. Upon evaluation, we should exclude these frames. Note also that using different frames from the same video sequences for training and testing can still be problematic. An online updating scheme for ROLO will be very useful in the future.
We will update experiments using customized YOLO models, in order to be able to detect arbitrary objects and therefore test on the whole OTB100 dataset, where we will also be able to train and test on different datasets to perform cross-validation.
Parameter Sensitivity
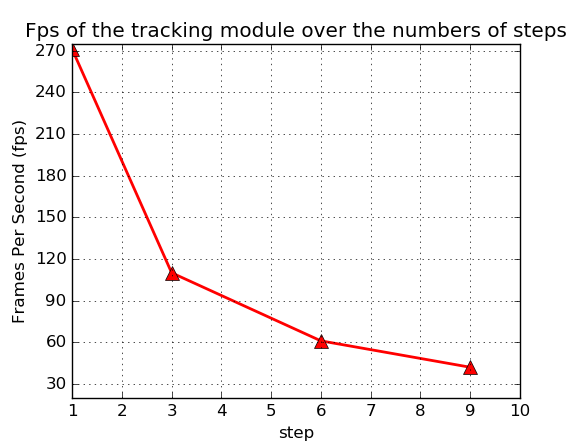
Repeat experiment 2 with different step sizes: [1, 3, 6, 9]
python ./experiments/testing/ROLO_step1_train_30_exp2.py
python ./experiments/testing/ROLO_step3_train_30_exp2.py
python ./experiments/testing/ROLO_step6_train_30_exp2.py
python ./experiments/testing/ROLO_step9_train_30_exp2.py

- Demo:
python ./ROLO_demo_heat.py - Training:
python ./heatmap/ROLO_heatmap_train.py - Testing:
python ./heatmap/ROLO_heatmap_test.py


- Blue: YOLO detection
- Red: Ground Truth
python ./ROLO_evaluation.py
More Qualitative results can be found in the project page. Quantitative results please refer to the arxiv paper.


- Blue: YOLO detection
- Green: ROLO Tracking
- Red: Ground Truth
ROLO is released under the Apache License Version 2.0 (refer to the LICENSE file for details).
The details are published as a technical report on arXiv. If you use the code and models, please cite the following paper: arXiv:1607.05781.
@article{ning2016spatially,
title={Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking},
author={Ning, Guanghan and Zhang, Zhi and Huang, Chen and He, Zhihai and Ren, Xiaobo and Wang, Haohong},
journal={arXiv preprint arXiv:1607.05781},
year={2016}
}
[1] Redmon, Joseph, et al. "You only look once: Unified, real-time object detection." CVPR (2016).
[2] Wu, Yi, Jongwoo Lim, and Ming-Hsuan Yang. "Object tracking benchmark." IEEE Transactions on Pattern Analysis and Machine Intelligence 37.9 (2015): 1834-1848.