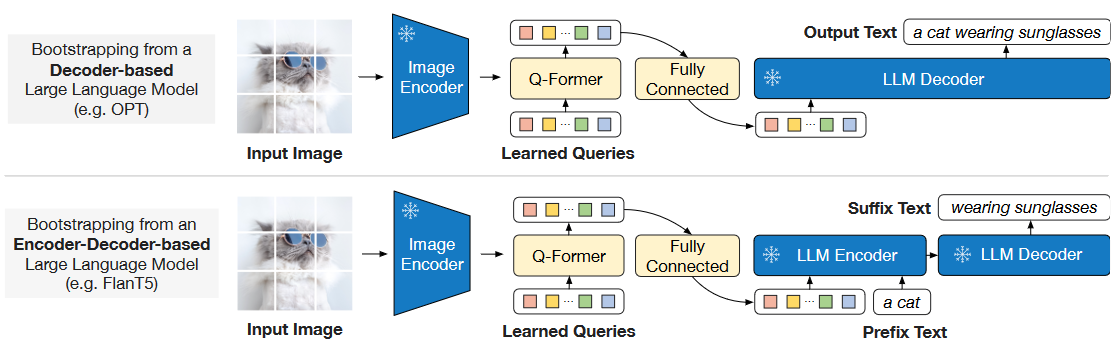
The cost of vision-and-language pre-training has become increasingly prohibitive due to end-toend training of large-scale models. This paper proposes BLIP-2, a generic and efficient pretraining strategy that bootstraps vision-language pre-training from off-the-shelf frozen pre-trained image encoders and frozen large language models. BLIP-2 bridges the modality gap with a lightweight Querying Transformer, which is pretrained in two stages. The first stage bootstraps vision-language representation learning from a frozen image encoder. The second stage bootstraps vision-to-language generative learning from a frozen language model. BLIP-2 achieves state-of-the-art performance on various visionlanguage tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model’s emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions.
Use the model
from mmpretrain import inference_model
result = inference_model('blip2-opt2.7b_3rdparty-zeroshot_caption', 'demo/cat-dog.png')
print(result)
# {'pred_caption': 'a dog and a cat sitting on a blanket'}Test Command
Prepare your dataset according to the docs.
Test:
python tools/test.py configs/blip2/blip2_8xb32_retrieval.py https://download.openmmlab.com/mmclassification/v1/blip2/blip2_3rdparty_pretrain_20230505-f7ef4390.pth| Model | Params (M) | BLEU-4 | CIDER | Config | Download |
|---|---|---|---|---|---|
blip2-opt2.7b_3rdparty-zeroshot_caption* |
3770.47 | 32.90 | 111.10 | config | model |
| Model | Params (M) | Accuracy | Config | Download |
|---|---|---|---|---|
blip2-opt2.7b_3rdparty-zeroshot_vqa* |
3770.47 | 53.50 | config | model |
| Model | Params (M) | Recall@1 | Config | Download |
|---|---|---|---|---|
blip2_3rdparty_retrieval* |
1173.19 | 85.40 | config | model |
Models with * are converted from the official repo. The config files of these models are only for inference. We haven't reproduce the training results.
@article{beitv2,
title={Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models},
author={Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven},
year={2023},
eprint={2301.12597},
archivePrefix={arXiv},
primaryClass={cs.CV}
}