-
Notifications
You must be signed in to change notification settings - Fork 2.5k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat: add agentic rag vertex ai search pattern
- Loading branch information
1 parent
7918e9a
commit 3ea3225
Showing
49 changed files
with
3,691 additions
and
756 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
154 changes: 154 additions & 0 deletions
154
...e2e-gen-ai-app-starter-pack/app/patterns/agentic_rag_vertex_ai_search/README.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,154 @@ | ||
| # Agentic RAG with Vertex AI Search | ||
|
|
||
| This pattern enhances the Gen AI App Starter Pack with a production-ready data ingestion pipeline, enriching your Retrieval Augmented Generation (RAG) applications. Using Vertex AI Search's state-of-the-art search capabilities, you can ingest, process, and embed custom data, improving the relevance and context of your generated responses. | ||
|
|
||
| The pattern provides the infrastructure to create a Vertex AI Pipeline with your custom code. Because it's built on Vertex AI Pipelines, you benefit from features like scheduled runs, recurring executions, and on-demand triggers. For processing terabyte-scale data, we recommend combining Vertex AI Pipelines with data analytics tools like BigQuery or Dataflow. | ||
|
|
||
| ## Architecture | ||
|
|
||
| The pattern implements the following architecture: | ||
|
|
||
| 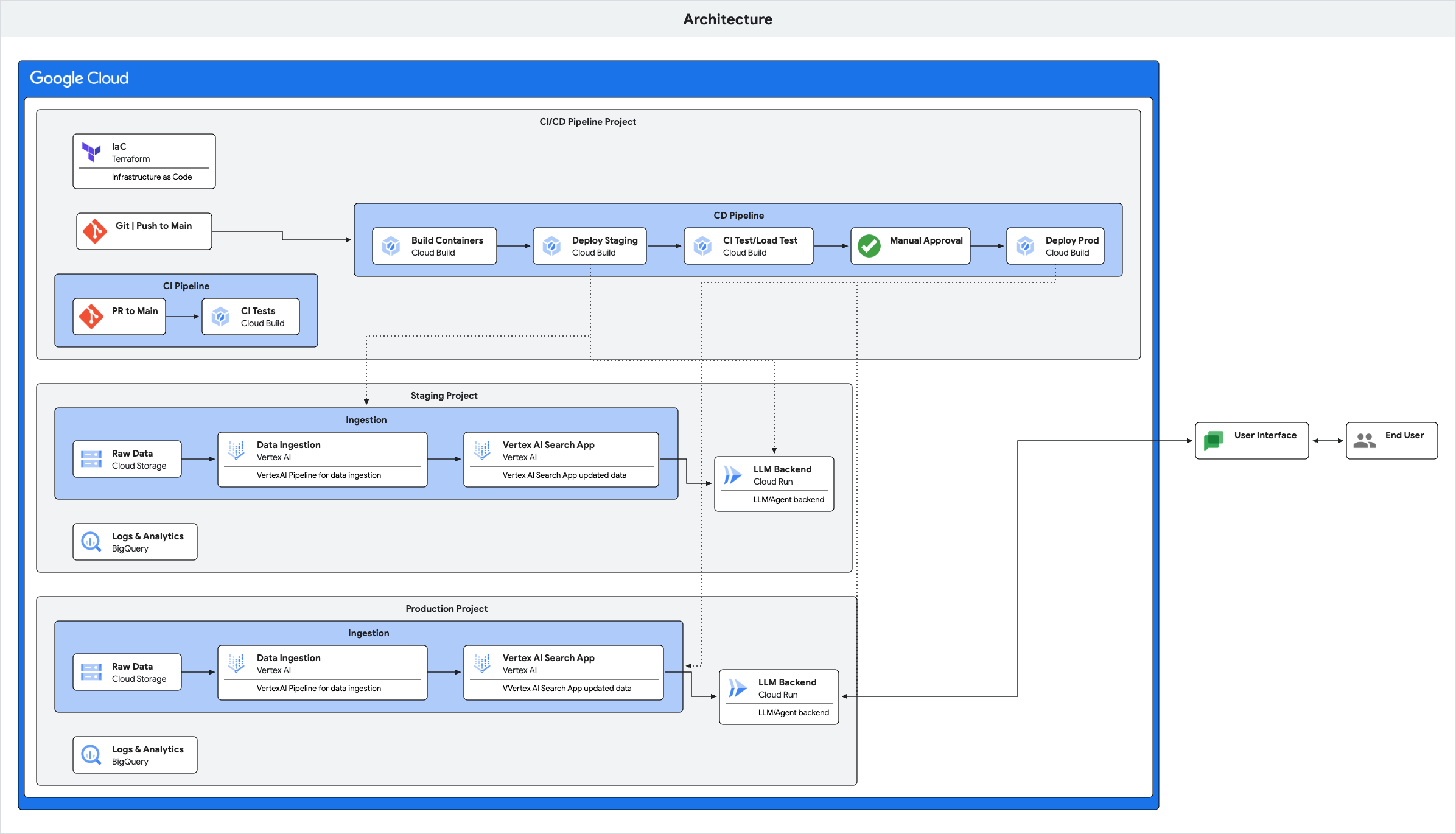 | ||
| The main addition to the base pattern is the addition of the ingestion components. | ||
|
|
||
| ### Key Features | ||
|
|
||
| - **Vertex AI Search Integration:** Utilizes Vertex AI Search for efficient data storage and retrieval. | ||
| - **Automated Data Ingestion Pipeline:** Automates the process of ingesting data from input sources. | ||
| - **Custom Embeddings:** Generates embeddings using Vertex AI Embeddings and incorporates them into your data for enhanced semantic search. | ||
| - **Terraform Deployment:** Ingestion pipeline is instantiated with Terraform alongside the rest of the infrastructure of the starter pack. | ||
| - **Cloud Build Integration:** Deployment of ingestion pipelines is added to the CD pipelines of the starter pack. | ||
| - **Customizable Code:** Easily adapt and customize the code to fit your specific application needs and data sources. | ||
|
|
||
| From an infrastructure point of view, a _Vertex AI Agent Builder Datastore_ and _Search App_ are being initialised in both staging and prod environments. You can learn more about these [here](https://cloud.google.com/generative-ai-app-builder/docs/enterprise-search-introduction). | ||
|
|
||
| When a new build is triggered through a commit to the main branch, in addition to updating the backend application, the data ingestion pipeline is also updated. | ||
|
|
||
| The data ingestion is orchestrated through a Vertex AI [Pipeline](https://cloud.google.com/vertex-ai/docs/pipelines/introduction) which in its simplest form comprises of a two processing step. | ||
| The pipeline reads data from a source (e.g., a PDF document) located at a configurable location. The data is then divided into smaller chunks, processed, and ingested into the Vertex AI Agent Builder Datastore. Upon ingestion completion, the connected Search App is automatically updated with the new data without any downtime. | ||
|
|
||
| Please note that the ingestion in the example is set to run automatically once per week. You may change the frequency of the update or the triggering mechanism altogether to match your needs. Look into the `data_processing/data_processing_pipeline/pipeline.py` and `deployment/cd/deploy-to-prod.yaml` files as the starting point for these changes. | ||
|
|
||
| ## Getting Started | ||
|
|
||
| 1. **Prepare the pattern:** First, prepare the pattern for data ingestion. In a clean instance of the starter pack, navigate to the `agentic_rag_vertex_ai_search` directory and execute the following command: | ||
|
|
||
| ```bash | ||
| python app/patterns/agentic_rag_vertex_ai_search/pattern_setup/prepare_pattern.py | ||
| ``` | ||
|
|
||
| 2. **Setup Dev Terraform:** Follow the instructions in the parent [deployment/README.md - Dev Deployment section](../../../deployment/README.md#dev-deployment) to set up the development environment using Terraform. This will deploy a datastore and configure the necessary permissions in your development project. | ||
|
|
||
| Refer to the [Terraform Variables section](#terraform-variables) to learn about the additional variables required for this pattern. | ||
|
|
||
| 3. **Test the Data Ingestion Pipeline:** | ||
|
|
||
| After successfully deploying the Terraform infrastructure, you can test the data ingestion pipeline. This pipeline is responsible for loading, chunking, embedding, and importing your data into the Vertex AI Search datastore. | ||
|
|
||
| > Note: The first pipeline execution may take additional time as your project is being configured to use Vertex AI Pipelines. | ||
| **a. Navigate to the Data Processing Directory:** | ||
|
|
||
| Change your working directory to the location of the data processing scripts: | ||
|
|
||
| ```bash | ||
| cd data_processing | ||
| ``` | ||
|
|
||
| **b. Install Dependencies:** | ||
|
|
||
| Ensure you have the necessary Python dependencies installed by running: | ||
|
|
||
| ```bash | ||
| poetry install | ||
| ``` | ||
|
|
||
| **c. Execute the Pipeline:** | ||
|
|
||
| Use the following command to execute the data ingestion pipeline. Replace the placeholder values with your actual project details: | ||
|
|
||
| ```bash | ||
| PROJECT_ID="YOUR_PROJECT_ID" | ||
| REGION="us-central1" | ||
| REGION_VERTEX_AI_SEARCH="us" | ||
| poetry run python data_processing_pipeline/submit_pipeline.py \ | ||
| --project-id=$PROJECT_ID \ | ||
| --region=$REGION \ | ||
| --region-vertex-ai-search=$REGION_VERTEX_AI_SEARCH \ | ||
| --data-store-id="sample-datastore" \ | ||
| --service-account="vertexai-pipelines-sa@$PROJECT_ID.iam.gserviceaccount.com" \ | ||
| --pipeline-root="gs://$PROJECT_ID-pipeline-artifacts" \ | ||
| --pipeline-name="data-ingestion-pipeline" | ||
| ``` | ||
|
|
||
| **Explanation of Parameters:** | ||
|
|
||
| - `--project-id`: Your Google Cloud Project ID. | ||
| - `--region`: The region where Vertex AI Pipelines will be executed (e.g., `us-central1`). | ||
| - `--region-vertex-ai-search`: The region for Vertex AI Search operations (e.g., `us` or `eu`). | ||
| - `--data-store-id`: The ID of your Vertex AI Search data store. | ||
| - `--service-account`: The service account email used for pipeline execution. | ||
| - `--pipeline-root`: The GCS bucket name for storing pipeline artifacts. | ||
| - `--pipeline-name`: A display name for your pipeline. | ||
| - `--schedule-only`: _(Optional)_ If true, only schedules the pipeline without immediate execution. Must be used with `--cron-schedule`. | ||
| - `--cron-schedule`: _(Optional)_ A cron schedule to run the pipeline periodically (e.g., `"0 9 * * 1"` for every Monday at 9 AM UTC). | ||
|
|
||
| **d. Pipeline Execution Behavior:** | ||
|
|
||
| The pipeline executes immediately. Use the `--schedule-only` flag with a `cron_schedule` to only schedule the pipeline without immediate execution. If no schedule exists, one is created. If a schedule exists, its cron expression is updated. | ||
|
|
||
| **e. Monitoring Pipeline Execution:** | ||
|
|
||
| The pipeline will output its configuration and execution status to the console. For detailed monitoring, you can use the Vertex AI Pipeline dashboard in your Google Cloud Console. This dashboard provides insights into the pipeline's progress, logs, and any potential issues. | ||
|
|
||
| 4. **Test the Application in the Playground** | ||
|
|
||
| You are now ready to test your RAG application with Vertex AI Search locally. | ||
| To do that you can follow the instructions in the [root readme](../../../README.md#installation). | ||
|
|
||
| 1. Navigate to the root folder & install the required dependencies: | ||
|
|
||
| ```bash | ||
| poetry install --with streamlit,jupyter | ||
| ``` | ||
|
|
||
| 2. Configure your Google Cloud environment: | ||
|
|
||
| ```bash | ||
| export PROJECT_ID="YOUR_PROJECT_ID" | ||
| gcloud config set project $PROJECT_ID | ||
| gcloud auth application-default login | ||
| gcloud auth application-default set-quota-project $PROJECT_ID | ||
| ``` | ||
|
|
||
| 3. Check your [app/chain.py](../../../app/chain.py) file to understand its content and verify the datastore ID and region are configured properly. | ||
|
|
||
| 4. Launch the playground: | ||
|
|
||
| ```bash | ||
| make playground | ||
| ``` | ||
|
|
||
| 5. Test your application! | ||
|
|
||
| > **Note:** If you encounter the error `"google.api_core.exceptions.InvalidArgument: 400 The embedding field path: embedding not found in schema"` after the first ingestion, please wait a few minutes and try again. | ||
|
|
||
| 5. **Setup Staging and Production:** Once you've validated the setup in your development environment, proceed to set up the Terraform infrastructure for your staging and production environments. Follow the instructions provided in the [deployment/README.md](../../../deployment/README.md) to configure and deploy the necessary resources. | ||
| This ensures that your data ingestion pipeline is integrated into your CI/CD workflow. Once the setup is complete, any commit to the main branch will trigger the pipeline, updating your Vertex AI Search application with the latest data, and deploying the updated application and tests. | ||
| Your CI/CD pipeline is now configured - any new commits will trigger the data ingestion, testing and deployment process automatically. | ||
| ## Terraform Variables | ||
| This pattern introduces the following additional Terraform variables: | ||
| | Variable | Description | Default Value | | ||
| | --------------------------- | ---------------------------------------------------------------------------------- | ----------------------- | | ||
| | `search_engine_name` | The name of the Vertex AI Search engine. | `sample-search-engine` | | ||
| | `datastore_name` | The name of the Vertex AI Agent Builder Datastore. | `sample-datastore` | | ||
| | `vertexai_pipeline_sa_name` | The name of the service account used for Vertex AI Pipelines. | `vertexai-pipelines-sa` | | ||
| | `region_vertex_ai_search` | The region for the Vertex AI Search engine. Can be one of "global", "us", or "eu". | `us` | | ||
| | `pipeline_cron_schedule` | A cron expression defining the schedule for automated data ingestion. | `0 0 * * 0` | | ||
| These variables are defined in the `deployment/terraform/variables.tf` and `deployment/terraform/dev/variables.tf` files and can be customized in your `deployment/terraform/vars/env.tfvars` and `deployment/terraform/dev/vars/env.tfvars` files respectively. |
134 changes: 134 additions & 0 deletions
134
...p-starter-pack/app/patterns/agentic_rag_vertex_ai_search/pattern_setup/prepare_pattern.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,134 @@ | ||
| # Copyright 2024 Google LLC | ||
| # | ||
| # Licensed under the Apache License, Version 2.0 (the "License"); | ||
| # you may not use this file except in compliance with the License. | ||
| # You may obtain a copy of the License at | ||
| # | ||
| # http://www.apache.org/licenses/LICENSE-2.0 | ||
| # | ||
| # Unless required by applicable law or agreed to in writing, software | ||
| # distributed under the License is distributed on an "AS IS" BASIS, | ||
| # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. | ||
| # See the License for the specific language governing permissions and | ||
| # limitations under the License. | ||
|
|
||
| import shutil | ||
| from pathlib import Path | ||
|
|
||
|
|
||
| def replace_in_file( | ||
| file_path: Path, search_str: str, replacement_file_path: Path | ||
| ) -> None: | ||
| """Replace a string in a file with contents from another file.""" | ||
| with open(replacement_file_path, "r") as f: | ||
| replacement_content = f.read() | ||
|
|
||
| with open(file_path, "r") as f: | ||
| content = f.read() | ||
|
|
||
| with open(file_path, "w") as f: | ||
| f.write(content.replace(search_str, replacement_content)) | ||
|
|
||
|
|
||
| def append_file_contents(source_file: Path, target_file: Path) -> None: | ||
| """Append contents of one file to another.""" | ||
| with open(source_file, "r") as source, open(target_file, "a") as target: | ||
| target.write(source.read()) | ||
|
|
||
|
|
||
| def main() -> None: | ||
| """Set up the agentic RAG pattern by copying and updating Terraform files. | ||
| Makes a backup of the deployment folder, then updates various Terraform files | ||
| with pattern-specific configurations by replacing content and appending updates. | ||
| """ | ||
| base_path = Path( | ||
| "app/patterns/agentic_rag_vertex_ai_search/pattern_setup/resources_to_copy" | ||
| ) | ||
| terraform_path = base_path / "deployment/terraform" | ||
| deployment_path = Path("deployment/terraform") | ||
| # Make backup copy of deployment folder | ||
| deployment_backup_path = Path(".deployment_backup") | ||
| if deployment_backup_path.exists(): | ||
| shutil.rmtree(deployment_backup_path) | ||
| print(f"Creating backup of deployment folder at '{deployment_backup_path}'") | ||
| shutil.copytree("deployment", deployment_backup_path, dirs_exist_ok=True) | ||
|
|
||
| # Replace content in build_triggers.tf | ||
| build_triggers_replacements = { | ||
| "# Your other CD Pipeline substitutions": terraform_path | ||
| / "substitute__cd_pipeline_triggers.tf_updates", | ||
| "# Your other Deploy to Prod Pipeline substitutions": terraform_path | ||
| / "substitute__deploy_to_prod_pipeline_triggers.tf_updates", | ||
| } | ||
|
|
||
| for search_str, replacement_file in build_triggers_replacements.items(): | ||
| replace_in_file( | ||
| deployment_path / "build_triggers.tf", search_str, replacement_file | ||
| ) | ||
|
|
||
| # Append contents to various tf files | ||
| tf_files_to_append = { | ||
| "iam.tf": "append__iam.tf_updates", | ||
| "service_accounts.tf": "append__service_accounts.tf_updates", | ||
| "storage.tf": "append__storage.tf_updates", | ||
| "variables.tf": "append__variables.tf_updates", | ||
| } | ||
|
|
||
| for target_file, source_file in tf_files_to_append.items(): | ||
| append_file_contents( | ||
| terraform_path / source_file, deployment_path / target_file | ||
| ) | ||
|
|
||
| # Append to env.tfvars | ||
| append_file_contents( | ||
| terraform_path / "vars/append__env.tfvars_updates", | ||
| deployment_path / "vars/env.tfvars", | ||
| ) | ||
|
|
||
| # Copy files | ||
| shutil.copy( | ||
| terraform_path / "data_store.tf_updates", deployment_path / "data_store.tf" | ||
| ) | ||
| shutil.copytree(base_path / "deployment/cd", "deployment/cd", dirs_exist_ok=True) | ||
| # Additional operations on dev folder | ||
| # Define files to append in dev directory | ||
| dev_files_to_append = { | ||
| "dev/vars/env.tfvars": "dev/vars/append__env.tfvars_updates", | ||
| "dev/variables.tf": "dev/append__variables.tf_updates", | ||
| "dev/iam.tf": "dev/append__iam.tf_updates", | ||
| "dev/service_accounts.tf": "dev/append__service_accounts.tf_updates", | ||
| "dev/storage.tf": "dev/append__storage.tf_updates", | ||
| } | ||
|
|
||
| # Append contents to each file | ||
| for target_file, source_file in dev_files_to_append.items(): | ||
| append_file_contents( | ||
| terraform_path / source_file, deployment_path / target_file | ||
| ) | ||
| shutil.copy( | ||
| terraform_path / "dev/data_store.tf_updates", | ||
| deployment_path / "dev/data_store.tf", | ||
| ) | ||
|
|
||
| # Setup data ingestion | ||
| data_processing_path = Path("data_processing") | ||
| data_processing_path.mkdir(exist_ok=True) | ||
| shutil.copytree( | ||
| base_path / "data_processing", data_processing_path, dirs_exist_ok=True | ||
| ) | ||
| for filename in ("chain.py", "retrievers.py", "templates.py"): | ||
| shutil.copy(base_path / "app" / filename, Path("app") / filename) | ||
|
|
||
| # Setup tests | ||
| test_integration_path = Path("tests/integration") | ||
| shutil.copy( | ||
| base_path / "tests/integration/test_chain.py", | ||
| test_integration_path / "test_chain.py", | ||
| ) | ||
|
|
||
| print("Successfully copied pattern files") | ||
|
|
||
|
|
||
| if __name__ == "__main__": | ||
| main() |
Oops, something went wrong.