Transformer模型的PyTorch实现
学习博主这篇文章的代码。
本项目使用
- python 3.6
- pytorch 1.3.1

上图的左半边用Nx框出来的,就是我们的encoder的一层。encoder一共有6层这样的结构。
上图的右半边用Nx框出来的,就是我们的decoder的一层。decoder一共有6层这样的结构。
输入序列经过word embedding和positional encoding相加后,输入到encoder。
输出序列经过word embedding和positional encoding相加后,输入到decoder。
最后,decoder输出的结果,经过一个线性层,然后计算softmax。
Encoder由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:
熟悉attention原理的童鞋都知道,attention可由以下形式表示:
multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来:
self-attention则是取Q,K,V相同。
Position-wise feed-forward networks 这层主要是提供非线性变换。Attention输出的维度是[bszseq_len, num_headshead_size],第二个sub-layer是个全连接层,之所以是position-wise是因为过线性层时每个位置i的变换参数是一样的。
Decoder和Encoder的结构差不多,但是多了一个attention的sub-layer,这里先明确一下decoder的输入输出和解码过程:
输出:对应i位置的输出词的概率分布 输入:encoder的输出 & 对应i-1位置decoder的输出。所以中间的attention不是self-attention,它的K,V来自encoder,Q来自上一位置decoder的输出 解码:这里要特别注意一下,编码可以并行计算,一次性全部encoding出来,但解码不是一次把所有序列解出来的,而是像rnn一样一个一个解出来的,因为要用上一个位置的输入当作attention的query 明确了解码过程之后最上面的图就很好懂了,这里主要的不同就是新加的另外要说一下新加的attention多加了一个mask,因为训练时的output都是ground truth,这样可以确保预测第i个位置时不会接触到未来的信息。
加了mask的attention原理如图(另附multi-head attention):
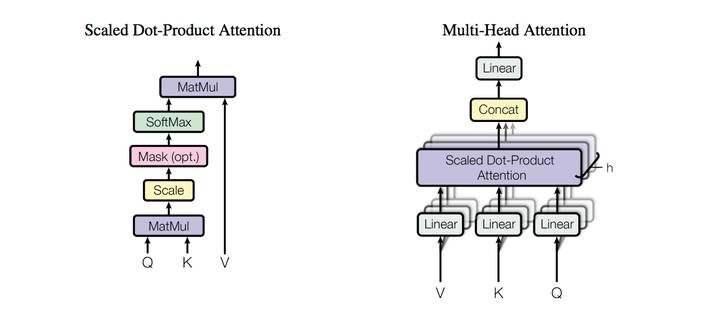
除了主要的Encoder和Decoder,还有数据预处理的部分。Transformer抛弃了RNN,而RNN最大的优点就是在时间序列上对数据的抽象,所以文章中作者提出两种Positional Encoding的方法,将encoding后的数据与embedding数据求和,加入了相对位置信息。