-
Notifications
You must be signed in to change notification settings - Fork 266
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
feat: Docs: Add foundational concepts, ACIR and Sequencer pages (#2716)
This PR adds several new pages to the docs: - It updates the Foundational Concepts main page to provide more context, adds a diagram with explanation as well as links to relevant pages - Adds a page on ACIR simulation to the Advanced Concepts section - Updates the content on the Transactions page to be more legible (although this page could still use some work) - Adds a page about the role of the Sequencer to the Foundational Concepts section - Adds a page about Fernet to the Advanced Concepts section - updates the dependencies in package.json in the Sandbox Getting Started page to always get the `latest` aztec packages (so we don't have to update this again) - Removes the Disclaimer from the pages that had it Closes #2653 #2655 # Checklist: Remove the checklist to signal you've completed it. Enable auto-merge if the PR is ready to merge. - [ ] If the pull request requires a cryptography review (e.g. cryptographic algorithm implementations) I have added the 'crypto' tag. - [x] I have reviewed my diff in github, line by line and removed unexpected formatting changes, testing logs, or commented-out code. - [x] Every change is related to the PR description. - [x] I have [linked](https://docs.github.com/en/issues/tracking-your-work-with-issues/linking-a-pull-request-to-an-issue) this pull request to relevant issues (if any exist).
- Loading branch information
1 parent
bbb0b60
commit 9d10326
Showing
12 changed files
with
289 additions
and
53 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,35 @@ | ||
| --- | ||
| title: ACIR Simulator | ||
| --- | ||
|
|
||
| The ACIR Simulator is responsible for simulation Aztec smart contract function execution. This component helps with correct execution of Aztec transactions. | ||
|
|
||
| Simulating a function implies generating the partial witness and the public inputs of the function, as well as collecting all the data (such as created notes or nullifiers, or state changes) that are necessary for components upstream. | ||
|
|
||
| ## Simulating functions | ||
|
|
||
| It simulates three types of functions: | ||
|
|
||
| ### Private Functions | ||
|
|
||
| Private functions are simulated and proved client-side, and verified client-side in the private kernel circuit. | ||
|
|
||
| They are run with the assistance of a DB oracle that provides any private data requested by the function. You can read more about oracle functions in the smart contract section [here](../../dev_docs/contracts/syntax/functions.md#oracle-functions). | ||
|
|
||
| Private functions can call other private functions and can request to call a public function. The public function execution will be performed by the sequencer asynchronously, so private functions don't have direct access to the return values of public functions. | ||
|
|
||
| ### Public Functions | ||
|
|
||
| Public functions are simulated and proved on the [sequencer](../foundation/nodes_clients/sequencer.md) side, and verified by the [public kernel circuit](./circuits/kernels/public_kernel.md). | ||
|
|
||
| They are run with the assistance of an oracle that provides any value read from the public state tree. | ||
|
|
||
| Public functions can call other public functions as well as private functions. Public function composability can happen atomically, but public to private function calls happen asynchronously (the private function call must happen in a future block). | ||
|
|
||
| ### Unconstrained Functions | ||
|
|
||
| Unconstrained functions are used to extract useful data for users, such as the user balance. They are not proved, and are simulated client-side. | ||
|
|
||
| They are run with the assistance of a DB oracle that provides any private data requested by the function. | ||
|
|
||
| At the moment, unconstrained functions cannot call any other function. It is not possible for them to call constrained functions, but it is on the roadmap to allow them to call other unconstrained functions. |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,100 @@ | ||
| --- | ||
| title: Sequencer Selection | ||
| --- | ||
|
|
||
| ## Fernet | ||
|
|
||
| _A protocol for random sequencer selection for the Aztec Network. Prior versions:_ | ||
|
|
||
| - [Fernet 52 (Aug 2023)](https://hackmd.io/0cI_xVsaSVi7PToCJ9A2Ew?view) | ||
| - [Sequencer Selection: Fernet (Jun 2023)](https://hackmd.io/0FwyoEjKSUiHQsmowXnJPw?both) | ||
| - [Sequencer Selection: Fernet (Jun 2023, Forum)](https://discourse.aztec.network/t/proposal-sequencer-selection-fernet/533) | ||
|
|
||
| ## Introduction | ||
|
|
||
| _Fair Election Randomized Natively on Ethereum Trustlessly_ (**Fernet**) is a protocol for random _sequencer_ selection. In each iteration, it relies on a VRF to assign a random score to each sequencer in order to rank them. The sequencer with the highest score can propose an ordering for transactions and the block they build upon, and then reveal its contents for the chain to advance under soft finality. _Provers_ must then assemble a proof for this block and submit it to L1 for the block to be finalised. | ||
|
|
||
| ## Staking | ||
|
|
||
| Sequencers are required to stake on L1 in order to participate in the protocol. Each sequencer registers a public key when they stake, which will be used to verify their VRF submission. After staking, a sequencer needs to wait for an activation period of N L1 blocks until they can start proposing new blocks. Unstaking also requires a delay to allow for slashing of dishonest behaviour. | ||
|
|
||
| ## Randomness | ||
|
|
||
| We use a verifiable random function to rank each sequencer. We propose a SNARK of a hash over the sequencer private key and a public input, borrowing [this proposal from the Espresso team](https://discourse.aztec.network/t/proposal-sequencer-selection-irish-coffee/483#vrf-specification-4). The public input is the current block number and a random beacon value from RANDAO. The value sourced from RANDAO should be old enough to prevent L1 reorgs from affecting sequencer selection on L2. This approach allows each individual proposer to secretly calculate the likelihood of being elected for a given block with enough anticipation. | ||
|
|
||
| Alternatively, we can compute the VRF over the _public_ key of each sequencer. This opens the door to DoS attacks, since the leader for each block becomes public in advance, but it also provides clarity to all sequencers as to who the expected leader is, and facilitates off-protocol PBS. | ||
|
|
||
| ## Protocol phases | ||
|
|
||
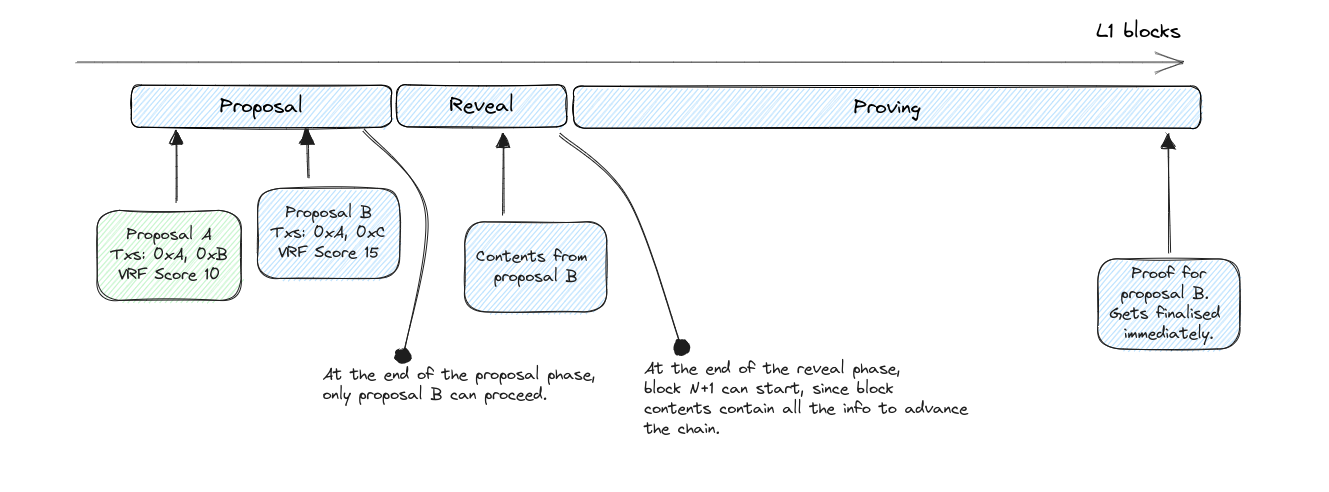
| Each block goes through three main phases in L1: proposal, reveal, and proving. Transactions can achieve soft finality at the end of the reveal phase. | ||
|
|
||
|  | ||
|
|
||
| ### Proposal phase | ||
|
|
||
| During the initial proposal phase, proposers submit to L1 a **block commitment**, which includes a commitment to the transaction ordering in the proposed block, the previous block being built upon, and any additional metadata required by the protocol. | ||
|
|
||
| **Block commitment contents:** | ||
|
|
||
| - Hash of the ordered list of transaction identifiers for the block (with an optional salt). | ||
| - Identifier of the previous block in the chain. | ||
| - The output of the VRF for this sequencer. | ||
|
|
||
| At the end of the proposal phase, the sequencer with the highest score submitted becomes the leader for this cycle, and has exclusive rights to deciding the contents of the block. Note that this plays nicely with private mempools, since having exclusive rights allows the leader to disclose private transaction data in the reveal phase. | ||
|
|
||
| > _In the original version of Fernet, multiple competing proposals could enter the proving phase. Read more about the rationale for this change [here](https://hackmd.io/0cI_xVsaSVi7PToCJ9A2Ew?both#Mitigation-Elect-single-leader-after-proposal-phase)._ | ||
| ### Reveal phase | ||
|
|
||
| The sequencer with the highest score in the proposal phase must then upload the block contents to either L1 or a verifiable DA layer. This guarantees that the next sequencer will have all data available to start building the next block, and clients will have the updated state to create new txs upon. It should be safe to assume that, in the happy path, this block would be proven and become final, so this provides early soft finality to transactions in the L2. | ||
|
|
||
| > _This phase is a recent addition and a detour from the original version of Fernet. Read more about the rationale for this addition [here](https://hackmd.io/0cI_xVsaSVi7PToCJ9A2Ew?both#Mitigation-Block-reveal-phase)._ | ||
| Should the leading sequencer fail to reveal the block contents, we flag that block as skipped, and the next sequencer is expected to build from the previous one. We could consider this to be a slashing condition for the sequencer. | ||
|
|
||
|  | ||
|
|
||
| ### Proving phase | ||
|
|
||
| During this phase, provers work to assemble an aggregated proof of the winning block. Before the end of this phase, it is expected for the block proof to be published to L1 for verification. | ||
|
|
||
| > Prover selection is still being worked on and out of scope of this sequencer selection protocol. | ||
| Once the proof for the winning block is submitted to L1, the block becomes final, assuming its parent block in the chain is also final. This triggers payouts to sequencer and provers (if applicable depending on the proving network design). | ||
|
|
||
| **Canonical block selection:** | ||
|
|
||
| - Has been proven during the proving phase. | ||
| - Its contents have been submitted to the DA layer in the reveal phase. | ||
| - It had the highest score on the proposal phase. | ||
| - Its referenced previous block is also canonical. | ||
|
|
||
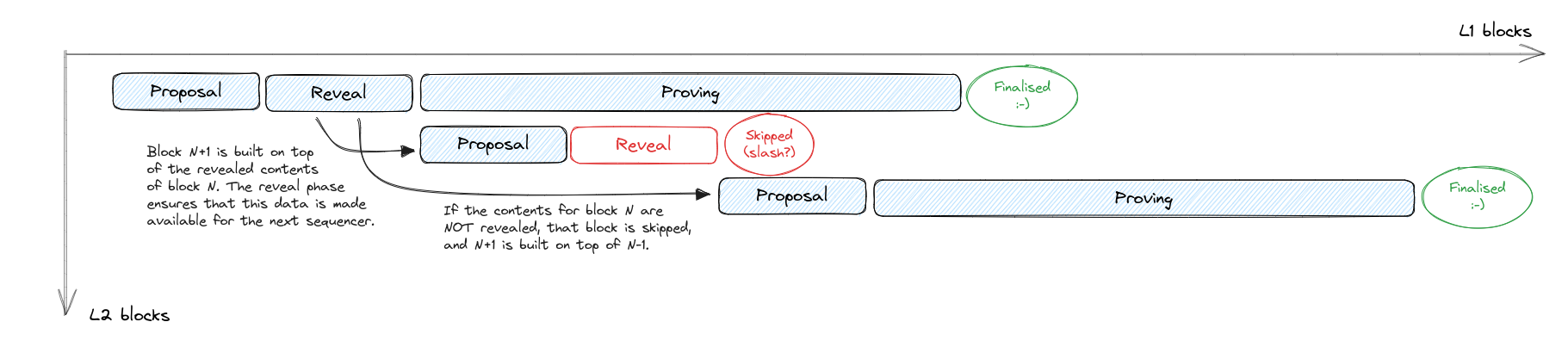
| ## Next block | ||
|
|
||
| The cycle for block N+1 (ie from the start of the proposal phase until the end of the proving phase) can start at the end of block N reveal phase, where the network has all data available on L1 or a DA to construct the next block. | ||
|
|
||
|  | ||
|
|
||
| The only way to trigger an L2 reorg (without an L1 one) is if block N is revealed but doesn't get proven. In this case, all subsequent blocks become invalidated and the chain needs to restart from block N-1. | ||
|
|
||
|  | ||
|
|
||
| To mitigate the effect of wasted effort by all sequencers from block N+1 until the reorg, we could implement uncle rewards for these sequencers. And if we are comfortable with slashing, take those rewards out of the pocket of the sequencer that failed to finalise their block. | ||
|
|
||
| ## Batching | ||
|
|
||
| > _Read more approaches to batching [here](https://hackmd.io/0cI_xVsaSVi7PToCJ9A2Ew?both#Batching)._ | ||
| As an extension to the protocol, we can bake in batching of multiple blocks. Rather than creating one proof per block, we can aggregate multiple blocks into a single proof, in order to amortise the cost of verifying the root rollup ZKP on L1, thus reducing fees. | ||
|
|
||
| The tradeoff in batching is delayed finalisation: if we are not posting proofs to L1 for every block, then the network needs to wait until the batch proof is submitted for finalisation. This can also lead to deeper L2 reorgs. | ||
|
|
||
| In a batching model, proving for each block happens immediately as the block is revealed, same as usual. But the resulting proof is not submitted to L1: instead, it is aggregated into the proof of the next block. | ||
|
|
||
|  | ||
|
|
||
| Here all individual block proofs are valid as candidates to finalise the current batch. This opens the door to dynamic batch sizes, so the proof could be verified on L1 when it's economically convenient. | ||
|
|
||
| ## Resources | ||
|
|
||
| - [Excalidraw diagrams](https://excalidraw.com/#json=DZcYDUKVImApNjj17KhAf,fMbieqJpOysX9obVitUDEA) |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1,5 +1,48 @@ | ||
| import DocCardList from '@theme/DocCardList'; | ||
| --- | ||
| title: Foundational Concepts | ||
| --- | ||
|
|
||
| # Foundational Concepts | ||
| As a layer 2 rollup on Ethereum, the Aztec network includes components that look similar to other layer 2 networks, but since it handles private state it also includes many new components. | ||
|
|
||
| <DocCardList /> | ||
| On this page we will introduce the high level network architecture for Aztec with an emphasis on the concepts that are core to understanding Aztec, including: | ||
|
|
||
| - [The state model](./state_model.md) | ||
| - [Accounts](./accounts/main.md) | ||
| - [Aztec Smart Contracts](./contracts.md) | ||
| - [Transactions](./transactions.md) | ||
| - [Communication between network components](./communication/main.md) | ||
|
|
||
| ## High level network architecture | ||
|
|
||
| An overview of the Aztec network architecture will help contextualize the concepts introduced in this section. | ||
|
|
||
| <img src="/img/aztec_high_level_network_architecture.svg" alt="network architecture" /> | ||
|
|
||
| ### Aztec.js | ||
|
|
||
| A user of the Aztec network will interact with the network through Aztec.js. Aztec.js is a library that provides APIs for managing accounts and interacting with smart contracts (including account contracts) on the Aztec network. It communicates with the [Private eXecution Environment (PXE)](../../apis/pxe/interfaces/PXE) through a `PXE` implementation, allowing developers to easily register new accounts, deploy contracts, view functions, and send transactions. | ||
|
|
||
| ### Private Execution Environment | ||
|
|
||
| The PXE provides a secure environment for the execution of sensitive operations, ensuring private information and decrypted data are not accessible to unauthorized applications. It hides the details of the [state model](./state_model.md) from end users, but the state model is important for Aztec developers to understand as it has implications for [private/public execution](./communication/public_private_calls.md) and [L1/L2 communication](./communication/cross_chain_calls.md). The PXE also includes the [ACIR Simulator](../advanced/acir_simulator.md) for private executions and the KeyStore for secure key management. | ||
|
|
||
| Procedurally, the PXE sends results of private function execution and requests for public function executions to the [sequencer](./nodes_clients/sequencer.md), which will update the state of the rollup. | ||
|
|
||
| ### Sequencer | ||
|
|
||
| The sequencer aggregates transactions into a block, generates proofs of the state updates (or delegates proof generate to the prover network) and posts it to the rollup contract on Ethereum, along with any required public data for data availability. | ||
|
|
||
| ## Further Reading | ||
|
|
||
| Here are links to pages with more information about the network components mentioned above: | ||
|
|
||
| - Aztec.js | ||
| - [Dapp tutorial](../../dev_docs/tutorials/writing_dapp/main.md) | ||
| - [API reference](../../apis/aztec-js) | ||
| - Private Execution Environment (PXE) | ||
| - [Dapp tutorial](../../dev_docs/tutorials/writing_dapp/pxe_service.md) | ||
| - [API reference](../../apis/pxe/index.md) | ||
| - [Private Kernel Circuit](../advanced/circuits/kernels/private_kernel.md) | ||
| - [Sequencer](./nodes_clients/sequencer.md) | ||
| - Prover Network (coming soon<sup>tm</sup>) | ||
| - [Rollup Circuit](../advanced/circuits/rollup_circuits/main.md) -- a component of the rollup contract |
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,43 @@ | ||
| --- | ||
| title: Sequencer | ||
| --- | ||
|
|
||
| The sequencer is a module responsible for creating and publishing new rollup blocks. This involves fetching txs from the P2P pool, ordering them, executing any public functions, running them through the rollup circuits, assembling the L2 block, and posting it to the L1 rollup contract along with any contract deployment public data. | ||
|
|
||
| On every new block assembled, it modifies the world state database to reflect the txs processed, but these changes are only committed once the world state synchronizer sees the new block on L1. | ||
|
|
||
| ## Components | ||
|
|
||
| The **block builder** is responsible for assembling an L2 block out of a set of processed transactions (we say a tx has been processed if all its function calls have been executed). This involves running the txs through the base, merge, and rollup circuits, updating the world state trees, and building the L2 block object. | ||
|
|
||
| The **prover** generates proofs for every circuit used. For the time being, no proofs are being actually generated, so the only implementation is an empty one. | ||
|
|
||
| The **publisher** deals with sending L1 transactions to the rollup and contract deployment emitter contracts. It is responsible for assembling the Ethereum tx, choosing reasonable gas settings, and monitoring the tx until it gets mined. Note that the current implementation does not handle unstable network conditions (gas price spikes, reorgs, etc). | ||
|
|
||
| The **public processor** executes any public function calls in the transactions. Unlike private function calls, which are resolved in the client, public functions require access to the latest data trees, so they are executed by the sequencer, much like in any non-private L2. | ||
|
|
||
| The **simulator** is an interface to the wasm implementations of the circuits used by the sequencer. | ||
|
|
||
| The **sequencer** pulls txs from the P2P pool, orchestrates all the components above to assemble and publish a block, and updates the world state database. | ||
|
|
||
| ## Circuits | ||
|
|
||
| What circuits does the sequencer depend on? | ||
|
|
||
| The **public circuit** is responsible for proving the execution of Brillig (public function bytecode). At the moment, we are using a fake version that actually runs ACIR (intermediate representation for private functions) and does not emit any proofs. | ||
|
|
||
| The **public kernel circuit** then validates the output of the public circuit, and outputs a set of changes to the world state in the same format as the private kernel circuit, meaning we get a standard representation for all txs, regardless of whether public or private functions (or both) were run. The kernel circuits are run iteratively for every recursive call in the transaction. | ||
|
|
||
| The **base rollup circuit** aggregates the changes from two txs (more precisely, the outputs from their kernel circuits once all call stacks are emptied) into a single output. | ||
|
|
||
| The **merge rollup circuit** aggregates two outputs from base rollup circuits into a single one. This circuit is executed recursively until only two outputs are left. This setup means that an L2 block needs to contain always a power-of-two number of txs; if there are not enough, then empty txs are added. | ||
|
|
||
| The **root rollup circuit** consumes two outputs from base or merge rollups and outputs the data to assemble an L2 block. The L1 rollup contract then verifies the proof from this circuit, which implies that all txs included in it were correct. | ||
|
|
||
| ## Source code | ||
|
|
||
| You can view the current implementation on Github [here](https://github.com/AztecProtocol/aztec-packages/tree/master/yarn-project/sequencer-client). | ||
|
|
||
| ## Further Reading | ||
|
|
||
| - [Sequencer Selection](../../advanced/sequencer_selection.md) |
Empty file.
Oops, something went wrong.