This repository is a fork of Greg Kamradt code https://twitter.com/GregKamradt
Original Repository: https://github.com/gkamradt/LLMTest_NeedleInAHaystack
This is Greg's original brainchild. Greg put an amazing amount of thought and work into this. Huge shout out to him for the original implementation and visualizing the results in such a compelling way. We can't thank Greg enough for his original contribution to the AI Engineering community!
Our goal is to add another level of rigor to the original tests and test more models.
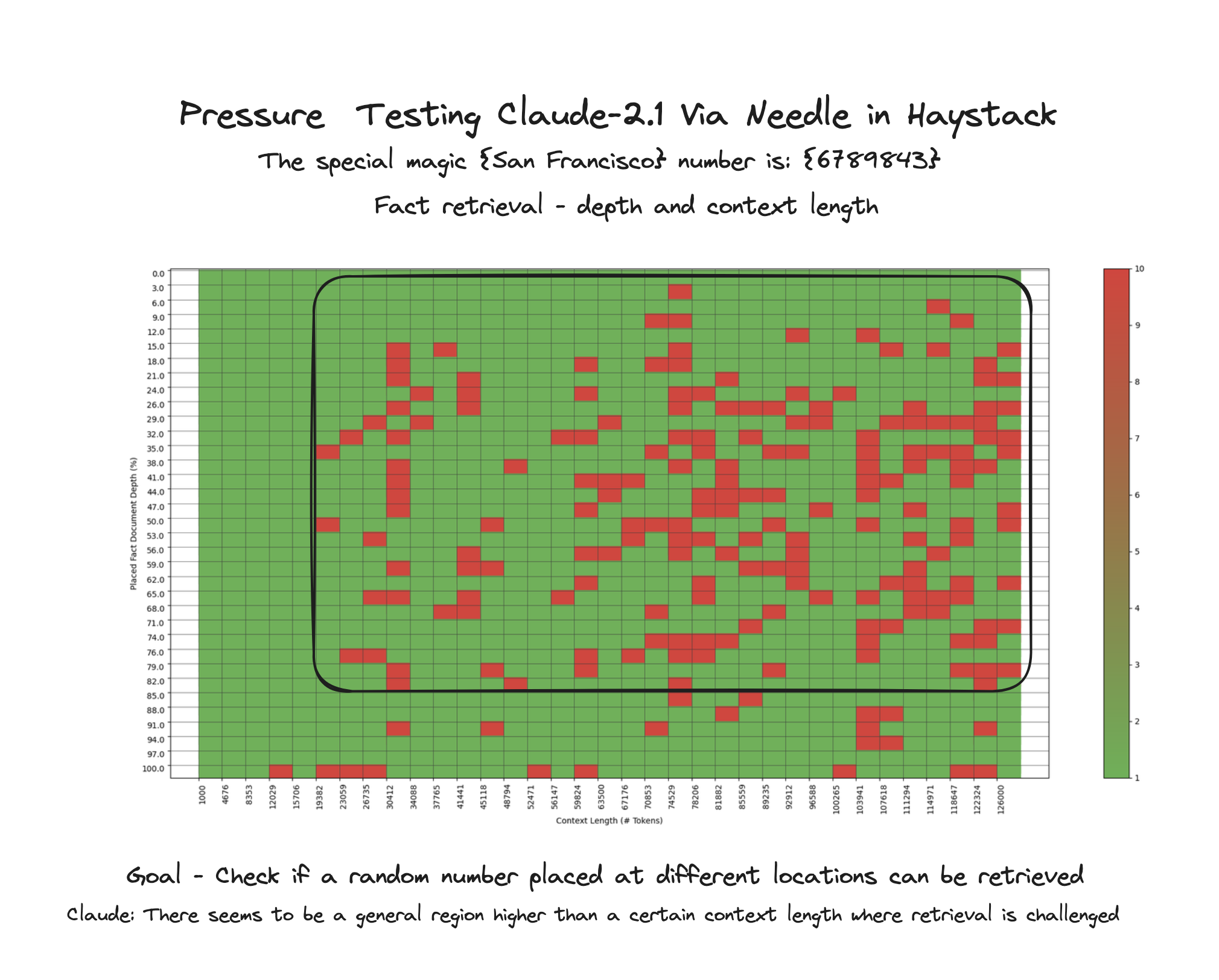
WHY DOES THIS TEST MATTER? Most people are using retrieval to connect private facts or private information into a model's context window. It's the way teams are running LLMs on their private data. The ability for a LLM to make use of this data and recall facts correctly is important for use in RAG.

git clone https://github.com/Arize-ai/LLMTest_NeedleInAHaystack.git
We've switched out the Evals to use Phoenix: https://github.com/Arize-ai/phoenix
- The Evaluations which in the original took 3-4 days to run now run in 2 hours (Phoenix is fast on batches)
- The Evaluation was modified so that the needle uses a different random number for every generation.
- We also added a random city, so the question changes as does the random number
- The random number and city were designed to make sure responses were not cached and retrievals were "real"
- The model must retrieve that number from random locations in the context window.
- The output is binary - "correct random number" or "unanswerable"
- Only if the model retrieves the number correctly does it score a 10, if not it scores a 1 (we only have 2 outcomes)
- We also test the negative case as a separate test, we don't include the needle at all, but ask it the same question
- Phoenix also rails the output, meaning it searches through the text string for exactly the "number" or "unanswerable" strings
- The original version of this test did a string Eval, which is a rough comparison of a text sentences, this can be problematic for results
- Auto generates the PNG Visualization based on the needle haystack
Supported model providers: OpenAI, Anthropic, Others coming soon
A simple 'needle in a haystack' analysis to test in-context retrieval ability of long context LLMs.
Example of random fact: The special magic {city} number is: {rnd_number}
The correct answer is rnd_number
- Place a sentence with a random number (the 'needle') in the middle of a long context window (the 'haystack')
- Ask the model to retrieve this statement
- Iterate over various document depths (where the needle is placed) and context lengths to measure performance
This is the code that backed
If ran and save_results = True, then this script will populate a result/ directory with evaluation information. Due to potential concurrent requests each new test will be saved as a file.
The key parameters:
needle- The statement or fact which will be placed in your context ('haystack')haystack_dir- The directory which contains the text files to load as background context. Only text files are supportedretrieval_question- The question with which to retrieve your needle in the background contextresults_version- You may want to run your test multiple times for the same combination of length/depth, change the version number if socontext_lengths_min- The starting point of your context lengths list to iteratecontext_lengths_max- The ending point of your context lengths list to iteratecontext_lengths_num_intervals- The number of intervals between your min/max to iterate throughdocument_depth_percent_min- The starting point of your document depths. Should be int > 0document_depth_percent_max- The ending point of your document depths. Should be int < 100document_depth_percent_intervals- The number of iterations to do between your min/max pointsdocument_depth_percent_interval_type- Determines the distribution of depths to iterate over. 'linear' or 'sigmoidmodel_provider- 'OpenAI' or 'Anthropic'model_name- The name of the model you'd like to test. Should match the exact value which needs to be passed to the api. Ex:gpt-4-1106-previewsave_results- Whether or not you'd like to save your results to file. They will be temporarily saved in the object regardless. True/Falsesave_contexts- Whether or not you'd like to save your contexts to file. Warning these will get very long. True/False
Other Parameters:
context_lengths- A custom set of context lengths. This will override the values set forcontext_lengths_min, max, and intervals if setdocument_depth_percents- A custom set of document depths lengths. This will override the values set fordocument_depth_percent_min, max, and intervals if setopenai_api_key- Must be supplied. GPT-4 is used for evaluation. Can either be passed when creating the object or an environment variableanthropic_api_key- Only needed if testing Anthropic models. Can either be passed when creating the object or an environment variablefinal_context_length_buffer- The amount of context to take off each input to account for system messages and output tokens. This can be more intelligent but using a static value for now. Default 200 tokens.print_ongoing_status- Default: True, whether or not to print the status of test as they complete