In this notebook, you will build a deep neural network that functions as part of an end-to-end automatic speech recognition (ASR) pipeline!
We begin by investigating the LibriSpeech dataset that will be used to train and evaluate your models. Your algorithm will first convert any raw audio to feature representations that are commonly used for ASR. You will then move on to building neural networks that can map these audio features to transcribed text. After learning about the basic types of layers that are often used for deep learning-based approaches to ASR, you will engage in your own investigations by creating and testing your own state-of-the-art models. Throughout the notebook, we provide recommended research papers for additional reading and links to GitHub repositories with interesting implementations.
The tasks for this project are outlined in the vui_notebook.ipynb in three steps. Follow all the instructions, which include implementing code in sample_models.py, answering questions, and providing results. The following list is a summary of the required tasks.
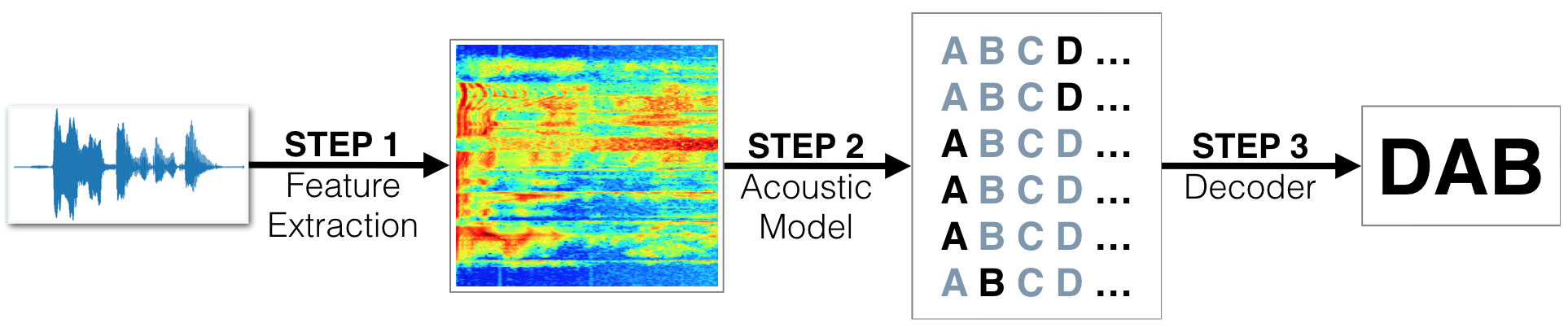
- Execute all code cells to extract features from raw audio
- Implement the code for Models 1, 2, 3, and 4 in
sample_models.py - Train Models 0, 1, 2, 3, 4 in the notebook
- Execute the comparison code in the notebook
- Answer Question 1 in the notebook regarding the comparison
- Implement the code for the Final Model in
sample_models.py - Train the Final Model in the notebook
- Answer Question 2 in the notebook regarding your final model
- Execute the prediction code in the notebook
Written with StackEdit.