| created_at | updated_at | slug | tags | ||
|---|---|---|---|---|---|
2021-10-14 05:38:21 -0700 |
2021-10-14 05:38:21 -0700 |
serialization-jackson |
|
写这篇文章时,我一度陷入了纠结与不安,再次体会到了聚焦的重要性。Jackson看似简单,实则功能强大,这两天有些迷失,不知道要看些什么,要写些什么。但路得一步一步走,饭得一口一口吃,纵使它可供探索的点繁如星辰,我也得将焦点拉回,否则就叫失控。至于其它的点,以后再说。因此,本文将聚焦如下几点
- Jackson的能力
- 基本原理
- module工作原理
Jackson文档怎么看,是一个问题。如果初次接触Jackson,看主项目的介绍半个小时,多半还是云里雾里,我认为这是Jackson文档做的很不好的一点,并没有一个Guide,而是需要自己一个一个项目看,而如果你恰巧点到了第三方module,就更不知道它在说什么了。
总的说来,Jackson由三部分组成
- Jackson-core:提供低层级的流式API,灵活程度高,效率高,但易用性差
- Jackson-annotations:提供注解定义,这些注解是与我么打交道最多的
- Jackson-databind:在前两个部分的基础上封装了一层,提供序列化和反序列化功能,我们直接使用的API,基本都来自于此。
在jackson-databind中,提供了可插入的module机制,允许第三方定义自己的类型转换库,通过ObjectMapper().registerModule的方式注册,常见的有
- 针对java.time包下的时间的类型库
- 针对kotlin的类型库
- 好多其它的
又,Jackson并非仅仅针对Json,还支持Protobuf、TOML、Yaml等诸多格式,他们是通过自定义jackson-core提供的流式API和Codec实现的。
还有,Jackson中的很多概念都和kotlinx.serialization类似,学习过程中可做类比,加深印象。
Jackson提供三种方式进行序列化和反序列化
- 低层级的流式API,直接控制基础token的写入(要理解Jackson所谓的token,一个字符、一个起始符,都是token)
- ObjectMapper,直接进行POJO和json之间的转换,也可以进行POJO和POJO之间的转换,但原理是一样的。
- 基于TreeModel,脱离POJO直接构建json结构
要想快,就用流式API,只需引入jackson-core,这里简单展示
class ResourceWithStream {
var resourceId: String? = null
var resourceType: String? = null
var usn: Long? = null
override fun toString(): String {
return "ResourceWithStream(resourceId=$resourceId, resourceType=$resourceType, usn=$usn)"
}
}
private fun JsonGenerator.encoding(resource: ResourceWithStream) {
this.writeStartObject()
this.writeStringField("resourceId", resource.resourceId)
this.writeStringField("resourceType", resource.resourceType)
resource.usn.let { usn ->
this.writeFieldName("usn")
if (usn == null) this.writeNull()
else this.writeNumber(usn)
}
this.writeEndObject()
this.close()
}
private fun JsonParser.decoding(): ResourceWithStream {
if (this.nextToken() != JsonToken.START_OBJECT) throw Exception("没有以对象起头")
return ResourceWithStream().also {
while (this.nextToken() != JsonToken.END_OBJECT) {
when (this.currentName) {
"resourceId" -> it.resourceId = this.valueAsString
"resourceType" -> it.resourceType = this.valueAsString
"usn" -> it.usn = this.valueAsLong
}
}
this.close()
}
}
fun main() {
val resource = ResourceWithStream().apply {
this.resourceId = "1"
this.resourceType = "record"
this.usn = 123456
}
val bos = ByteArrayOutputStream()
val jsonFactory = JsonFactoryBuilder().build()
// 序列化
val jsonGenerator = jsonFactory.createGenerator(bos)
jsonGenerator.encoding(resource)
println(bos.toString())
// 反序列化
val jsonParser = jsonFactory.createParser(bos.toByteArray())
println(jsonParser.decoding())
}输出
{"resourceId":"1","resourceType":"record","usn":123456}
ResourceWithStream(resourceId=1, resourceType=record, usn=123456)Jackson的注解可就多了去了,一个简单而骚气的展示:序列化时将Map类型的数据提取到顶层,反序列化时再将这些数据塞回去。
class Resource2 {
var resourceId: String? = null
@JsonIgnore
var data: MutableMap<String, Any>? = mutableMapOf()
@JsonAnySetter
fun add(key: String, value: String) {
data?.put(key, value)
}
@JsonAnyGetter
fun getOther(): MutableMap<String, Any>? = data
override fun toString(): String {
return "Resource2(resourceId=$resourceId, data=$data)"
}
}
fun main() {
val resource = Resource2().apply {
this.resourceId = "资源ID"
this.data = mutableMapOf(
"key" to "value",
"key2" to "value2",
"key3" to "value3"
)
}
val objectMapper = ObjectMapper()
val jsonString = objectMapper
.writerWithDefaultPrettyPrinter()
.writeValueAsString(resource)
.also { println(it) }
objectMapper.readValue(jsonString, Resource2::class.java)
.also { println(it) }
}考虑到注解多又常用,这里有不能每一个都展示,我们穷举场景
-
如果需要自定义POJO某个属性的和序列化结果的对应关系,使用**@JsonProperty、@JsonSetter、@JsonGetter**
-
如果需要指定序列化后字段之间的顺序,使用**@JsonPropertyOrder**
-
如果POJO的某个字段需要直接当做json格式输出,使用@JsonRawValue
-
如果需要忽略某些字段,使用**@JsonIgnore、@JsonIgnoreProperties、@JsonIgnoreType**
-
如果需要修改Jackson针对属性、POJO创建器等的检测逻辑,使用**@JsonAutoDetect**配置
典型地就是设置field、getter、setter、creator方法的可见性,指定哪种可见性能够被检测到
-
如果需要根据属性的值的情况决定是否序列化,可以使用**@JsonInclude**,它甚至可以指定当属性为某个特定的值时才序列化
-
如果某个类需要将某个属性当做该类型最终序列化结果的值,使用**@JsonValue**,一般用于枚举
-
如果需要配置jata.util中的日期相关序列化和反序列化转换逻辑,使用**@JsonFormat**
-
如果同一个POJO,在不同的情况下需要有不同的序列化结果,使用**@JsonView**
-
如果POJO中存在自定义类型,要想将该类型字段在序列化时提取到顶层,使用**@JsonUnwrapped**
-
如果POJO中存在map,想要把map的值提到顶层,使用**@JsonAnyGetter**
反之,如果json拥有多个属性,POJO中仅有少量字段,为了将多余的字段直接放在map中,使用**@JsonAnySetter**
-
如果想要自定义反序列化时调用的POJO构建器,使用**@JsonCreator**
-
针对枚举类型,如果想要在反序列化时匹配不到的情况下设置一个默认值,使用**@JsonEnumDefaultValue**
-
如果在反序列化时需要强制干预一个字段的值,可以使用**@JacksonInject**,但要结合ObjectMapper..setInjectableValues使用
-
如果要使用多态,需要使用**@JsonSubTypes、@JsonTypeId、@JsonTypeInfo、@JsonTypeName**
-
如果你的POJO之间有相互引用,导致序列化时出现递归,你需要使用**@JsonManagedReference、@JsonBackReference或@JsonIdentityInfo**解递归
-
如果希望某个POJO序列化后放在一个字段下,使用**@JsonRootName**
他们的使用,可以参考这篇文章,还挺全的:就是我
树形结构,是Jackson提供的又一强大功能,它允许我们直接构建Json,类似Kotlin的JsonElement,但是更强大。给一个简单的例子
fun main() {
// 两种创建node的方式都一样
// val node = JsonNodeFactory.instance.objectNode()
val objectMapper = ObjectMapper()
val node = objectMapper.createObjectNode()
node.put("resourceId", "这是ID")
.put("resourceType", "这是Type")
.put(
"data", objectMapper.createObjectNode().apply {
put(
"images", objectMapper.createArrayNode().apply {
add("这是第一个链接")
add("这是第二个链接")
}
)
}
)
println(node.toPrettyString())
println(objectMapper.writerWithDefaultPrettyPrinter().writeValueAsString(node))
}输出
{
"resourceId" : "这是ID",
"resourceType" : "这是Type",
"data" : {
"images" : [ "这是第一个链接", "这是第二个链接" ]
}
}
{
"resourceId" : "这是ID",
"resourceType" : "这是Type",
"data" : {
"images" : [ "这是第一个链接", "这是第二个链接" ]
}
}在MapperFeature、SerializationFeature、DeserializationFeature中,定义了很多开关,可根据需要打开或关闭。具体看三个文档
流式API也支持很多功能,翻开JsonGenerator源码,将近三千行的文件长度有点吓人,但总的来说,它大概也只有功能配置和各种写方法。这其中,我们目前只关心之前用到的内容:
- 一个基本的写方法的实现,即writeXXX
- 序列化过程中的状态维护,即JsonWriteContext
- ObjectMapper的基础,即ObjectCodec
最底层的原理
一般来说,通过JsonFactoryBuilder().build().createGenerator(xxx)创建出来的是UTC8JsonGenerator实例,我们来看两个方法的示例
// 写对象开头
public final void writeStartObject() throws IOException {
_verifyValueWrite("start an object");
_writeContext = _writeContext.createChildObjectContext();
if (_outputTail >= _outputEnd) {
_flushBuffer();
}
_outputBuffer[_outputTail++] = BYTE_LCURLY;
}
// 写一个普通字符串
public void writeString(String text) throws IOException {
this._verifyValueWrite("write a string");
if (text == null) {
this._writeNull();
} else {
int len = text.length();
if (len > this._outputMaxContiguous) {
this._writeStringSegments(text, true);
} else {
if (this._outputTail + len >= this._outputEnd) {
this._flushBuffer();
}
this._outputBuffer[this._outputTail++] = this._quoteChar;
this._writeStringSegment((String)text, 0, len);
if (this._outputTail >= this._outputEnd) {
this._flushBuffer();
}
this._outputBuffer[this._outputTail++] = this._quoteChar;
}
}
}
// flush
protected final void _flushBuffer() throws IOException {
int len = this._outputTail;
if (len > 0) {
this._outputTail = 0;
this._outputStream.write(this._outputBuffer, 0, len);
}
}
// 验证写入是否正确
protected final void _verifyValueWrite(String typeMsg) throws IOException {
int status = this._writeContext.writeValue();
if (this._cfgPrettyPrinter != null) {
this._verifyPrettyValueWrite(typeMsg, status);
} else {
byte b;
switch(status) {
case 0:
case 4:
default:
return;
case 1:
b = 44;
break;
case 2:
b = 58;
break;
case 3:
if (this._rootValueSeparator != null) {
byte[] raw = this._rootValueSeparator.asUnquotedUTF8();
if (raw.length > 0) {
this._writeBytes(raw);
}
}
return;
case 5:
this._reportCantWriteValueExpectName(typeMsg);
return;
}
if (this._outputTail >= this._outputEnd) {
this._flushBuffer();
}
this._outputBuffer[this._outputTail++] = b;
}
}我们忽略_cfgPrettyPrinter这个东西,它不是关键。有要点
- 流式API的输出原理:维护一个输出流,维护一个缓存字节数组。每次写入,只是写入缓存数组中,只有主动调用flush()或缓存长度超过设定值(_outputEnd)时,才会将数据批量写入输入流,这样可以提升效率
- 每次写入前,都会调用_verifyValueWrite对当前的状态进行验证,它验证的内容其实是即将写入的内容是否符合Json格式,这是通过JsonStreamContext实现的(对写,对应JsonWriteContext),它维护了序列化过程中,当前的写入状态。比如,刚刚写入了一个key,现在必须写入一个value,否则就会报错。
- 在写对象的起始符时,也创建了jsonContext的子context,可见,Context是有层次结构的,其结构和Json的层次结构保持一致。
看看JsonContext的层次结构,我们大概能猜出其工作原理
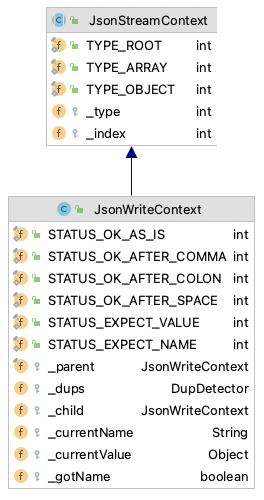
-
三个type(TYPE_ROOT等),是Context的类型,对应了根、数组、对象三种
-
几个status(STATUS_OK_AS_IS等),是Context检查后返回给调用者的结果,其中
- STATUS_OK_AS_IS:表明格式检查正确
- STATUS_OK_AFTER_COMMA:表明格式检查正确,且当前位置后面应该添加逗号
- STATUS_OK_AFTER_COLON:表明格式正确,且当前位置后面应该添加冒号
- STATUS_OK_AFTER_SPACE:表明格式正确,且当前位置后面应该添加空白符
- STATUS_EXPECT_VALUE:表明格式错误,预期是一个值
- STATUS_EXPECT_NAME:表明格式错误,预期是一个字段名
对它们的处理方式,在上面展示的方式_verifyValueWrite中也能看到。
-
其余属性,是为了维持当前状态用,根据状态判定当前调用是否合法,我们忽略"重复属性检查",主要有两个方法,逻辑见注释
// 写字段名 public int writeFieldName(String name) throws JsonProcessingException { // 当前类型是对象或已经写过了字段名,肯定就错了嘛 if ((_type != TYPE_OBJECT) || _gotName) { return STATUS_EXPECT_VALUE; } _gotName = true; _currentName = name; if (_dups != null) { _checkDup(_dups, name); } // 如果这是第一个键值对,则啥都不管,否则,需要在这个键前面加逗号 return (_index < 0) ? STATUS_OK_AS_IS : STATUS_OK_AFTER_COMMA; } // 写值 public int writeValue() { if (_type == TYPE_OBJECT) { // 如果还没有设置键,应该先设置键 if (!_gotName) { return STATUS_EXPECT_NAME; } _gotName = false; ++_index; // 在值前面加冒号 return STATUS_OK_AFTER_COLON; } if (_type == TYPE_ARRAY) { int ix = _index; ++_index; // 如果是数组,如果数组里还一个值都没有,啥也不做,否则,应该在这个之前面加逗号 return (ix < 0) ? STATUS_OK_AS_IS : STATUS_OK_AFTER_COMMA; } ++_index; // 否则就是根对象咯,如果根对象里还没有元素,就啥也不错,否则应该在前面加空格 return (_index == 0) ? STATUS_OK_AS_IS : STATUS_OK_AFTER_SPACE; }
编解码器
如果了解Kotlin的序列化设计策略,就很好理解编解码器了,可以将它类比SerialFormat——为了将流式API的复杂逻辑封装起来,提供一个简单易用的API,我们看它的接口定义。
public abstract class ObjectCodec extends TreeCodec implements Versioned
{
protected ObjectCodec() { }
@Override
public abstract Version version();
public abstract <T> T readValue(JsonParser p, Class<T> valueType);
public abstract <T> T readValue(JsonParser p, TypeReference<T> valueTypeRef);
public abstract <T> T readValue(JsonParser p, ResolvedType valueType);
public abstract <T> Iterator<T> readValues(JsonParser p, Class<T> valueType);
public abstract <T> Iterator<T> readValues(JsonParser p, TypeReference<T> valueTypeRef);
public abstract <T> Iterator<T> readValues(JsonParser p, ResolvedType valueType)
public abstract void writeValue(JsonGenerator gen, Object value) throws IOException;
@Override
public abstract <T extends TreeNode> T readTree(JsonParser p) throws IOException;
@Override
public abstract void writeTree(JsonGenerator gen, TreeNode tree) throws IOException;
@Override
public abstract TreeNode createObjectNode();
@Override
public abstract TreeNode createArrayNode();
@Override
public abstract JsonParser treeAsTokens(TreeNode n);
public abstract <T> T treeToValue(TreeNode n, Class<T> valueType);
@Deprecated
public JsonFactory getJsonFactory() { return getFactory(); }
public JsonFactory getFactory() { return getJsonFactory(); }
}可以看到,它提供的方法非常有限,大致分为两类
- 针对一般类型及其集合类型的读、写方法,接收JsonParser/JsonGenerator、类型参数
- 针对树模型的读写方法
ObjectMapper是data-bind最主要的类,而他,直接继承ObjectCodec,也就是说,可以直接使用ObjectCodec中定义的那些方法。但会发现,最常用的却不是它们,类似SerialFormat,尽管ObjectCodec已经为我们提供了一些方法,但它们只是将流式API的端点和类型联系了起来,还是不够易用,因此data-bind定义了更多易用的方法,将JsonGenerator之类的创建封装在类内部,于是我们就有了writeValueAsString()这样的方法可以直接使用。
来看写方法,其实所有的写方法内部实现都是一样的,writeValueAsString也只是在其内部用一个流缓存序列化输出,再转换为字符串。它们的重点,在于com.fasterxml.jackson.databind.ObjectMapper#_writeValueAndClose
// 所有写方法都会调用的内部方法
protected final void _writeValueAndClose(JsonGenerator g, Object value) throws IOException {
SerializationConfig cfg = getSerializationConfig();
if (cfg.isEnabled(SerializationFeature.CLOSE_CLOSEABLE) && (value instanceof Closeable)) {
_writeCloseable(g, value, cfg);
return;
}
try {
// 重点在serializeValue
_serializerProvider(cfg).serializeValue(g, value);
} catch (Exception e) {
ClassUtil.closeOnFailAndThrowAsIOE(g, e);
return;
}
g.close();
}
// 序列化值
public void serializeValue(JsonGenerator gen, Object value) throws IOException {
_generator = gen;
if (value == null) {
_serializeNull(gen);
return;
}
final Class<?> cls = value.getClass();
// 这是重点
final JsonSerializer<Object> ser = findTypedValueSerializer(cls, true, null);
PropertyName rootName = _config.getFullRootName();
if (rootName == null) {
if (_config.isEnabled(SerializationFeature.WRAP_ROOT_VALUE)) {
_serialize(gen, value, ser, _config.findRootName(cls));
return;
}
} else if (!rootName.isEmpty()) {
_serialize(gen, value, ser, rootName);
return;
}
_serialize(gen, value, ser);
}
// 写入JsonGenerator
private final void _serialize(JsonGenerator gen, Object value, JsonSerializer<Object> ser, PropertyName rootName) throws IOException {
try {
gen.writeStartObject();
gen.writeFieldName(rootName.simpleAsEncoded(_config));
ser.serialize(value, gen, this);
gen.writeEndObject();
} catch (Exception e) {
throw _wrapAsIOE(gen, e);
}
}我们展示了三层调用层次的方法,排除干扰项,要点如下
- 获取待序列化的类型对应的序列化器
- 使用找到的序列化器,执行最后的序列化逻辑
- 向JsonGenerator写入对象起始符
- 向JsonGenerator写入根字段名
- 用得到的序列化器向JsonGenerator写入对象相关信息
- 向JsonGenerator写入对象结束符
这里出现了一个新的概念:序列化器,之前是没有见过的。序列化器和反序列化器的创建,是data-bind的重要内容,我们可以想象一下:序列化器负责对整个对象的序列化,这里的序列化,其实是将对象属性转换为json的token的过程。我们又没有创建序列化器,那要么是编译器创建,要么是运行时创建,很显然前者是不可能的。可以猜测,序列化器的生成,包含了以下逻辑(反序列化类似)
- 包含对Json注解的支持,反射读取注解,然后体现在序列化器上
- 包含对各种功能的支持,目前data-bind的功能主要有MapperFeature、SerializationFeature、DeserializationFeature的支持,生成序列化器时,根据这些条件动态调整转换行为。这其实最终体现在了SerializationConfig中。
- 对新增逻辑的支持,module的扩展性,应该要靠它来支持
有关序列化器的生成逻辑,主要在SerializerProvider,比较深,有兴趣自己跟跟看,解析一下其生成逻辑。对于一个自定义的POJO,创建逻辑最终会来到这里:com.fasterxml.jackson.databind.ser.BeanSerializerFactory#constructBeanOrAddOnSerializer,逻辑过于复杂,所有上面说的那些都交织在其中,有兴趣可以自己研究。下图展示了构建过程中判断MapperFeature.USE_STATIC_TYPING开关的情况。
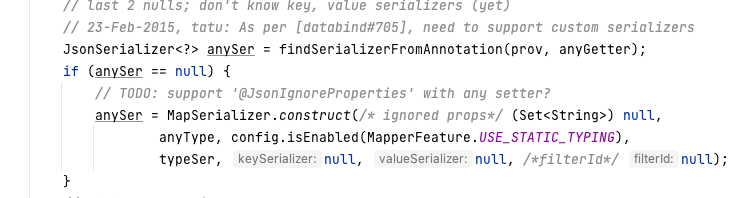
实际上,序列化器会首先在预先设置的序列化器中查找,然后从缓存中查找,实在没有,才会自动生成,且生成后的序列化器会添加到缓存,避免多次生成,从而提升性能。而那些针对Jackson的三方库,基本都是自定义类型的处理方式,是否可以推测,所谓第三方库,其实就是自己提前定义的序列化器和反序列化器,然后注册进来就好。
ObjectMapper是Jackson使用的核心,一般来说,一个ObjectMapper实例对应了一套配置,配置一旦添加不可去除,如果想用多套不同的配置,则需维护多个ObjectMapper,这也是常规使用方法,你看整个Spring中,正常情况下,都只有一个ObejctMapper实例的。
在Jackson主项目下,能看到很多第三方插件(数据类型模块),我们来探究它是如何工作的。

注册一个module的调用方式是
ObjectMapper().registerModule(JavaTimeModule())它干了啥呢?参见com.fasterxml.jackson.databind.ObjectMapper#registerModule(代码太长就不贴了),简单说来
- 将Module依赖的Module进行递归注册
- 将Module中定义的序列化器和反序列化器注册到ObjectMapper
当然,能够自定义的,肯定不止序列化器,看com.fasterxml.jackson.databind.Module.SetupContext

可以看到,它提供了多种配置能力,这些能力怎么用,后面可以单独开一篇文章介绍。
- 可开启各种功能
- 可添加各种序列化器、反序列化器
- 可添加序列化和反序列化描述符
- 添加类型解析器
- 添加注解
- 注册子类型(用于多态)
- 混入
- 命名策略
Jackson提供了SimpleModule,帮助我们在自定义类型module时简化开发,现在我们自定义一个Module。
假设有一系列类型(这里就展示一个),比如
data class Operation2(
val id: Int?
)现在希望Jackson支持它们,于是可以定义一个Module,它需要包含针对这些类型的序列化器,将这些序列化器包装进一个自定义Module,如下
class OperationSerializer : StdSerializer<Operation2>(Operation2::class.java) {
override fun serialize(value: Operation2?, gen: JsonGenerator, provider: SerializerProvider?) {
if (value == null) {
gen.writeNull()
return
}
gen.writeStartObject()
gen.writeNumberField("operationId", value.id!!)
gen.writeEndObject()
}
}
class OperationModule : SimpleModule() {
init {
addSerializer(OperationSerializer())
}
override fun getModuleName(): String {
return this::class.qualifiedName.toString()
}
}然后,在使用时就可以注册并使用了
fun main() {
val objectMapper = ObjectMapper().registerModule(OperationModule())
println(objectMapper.writeValueAsString(Operation2(1)))
}输出如下
{"operationId":1}相对而言,Kotlin序列化功能还非常年轻,有类似也有不同,将二者进行对比,有助于理解。
| Jackson接口 | Kotlin接口 | 用途 |
|---|---|---|
| JsonGenerator/JsonParser | Encoder/Decoder | 底层接口,负责将支持的基本类型编码到流中 |
| JsonSerializer/JsonDeserializer | KSerializer | 序列化器/反序列化器,负责将具有结构的对象,转换为基本类型 |
| ObjectCodec/ObjectMapper | SerialFormat/Json | 编解码器,略有不同,不过都是对用户隐藏了实现,暴露简单接口 |
| TreeNode | JsonElement | 树抽象模型,二者都有,不过Jackson的更加强大 |
| Module | serializerModule | 功能完全不一样,但思想类似,都是维护一堆上下文对象。 区别在于,前者功能更多;后者只有上下文和多态的声明 |
初以为Jackson,区区一Json序列化库,能复杂到哪里去;看了官方手册,不知道是它写的乱,还是我悟性不好,看半天反正不知道在讲啥;后来耐着性子看,并尝试了不少方式,发现用起来还挺简单,模型上又和Kotlin序列化有几分类似,原理上也没那么难懂嘛;多翻一些源码,发现这个历史悠久的库果然不是泛泛之辈,功能太多了,眼花缭乱的,很多功能单拎出来都能写一篇长文,也不怪得网络上那么多Jackson专栏。所以它也不是那种一两天就能搞定的库,更不是一篇文章能说清楚的。
本文我们简要介绍了Jackson的基础能力、基本原理、基本模型等。抓住Jackson主干是主要目的,细枝末节,更加高级偏僻的功能,留待日后探索。通过本文,你应该知道了
- Jackson由core提供核心能力,data-bind提供各种功能,annotations提供注解支持
- Jackson的常用场景使用方法
- Jackson和核心原理,Module的工作原理
有了本文的基础,我们就能更加流畅地去看其他文章了,官网推荐的那些就很好
