We read every piece of feedback, and take your input very seriously.
To see all available qualifiers, see our documentation.
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and privacy statement. We’ll occasionally send you account related emails.
Already on GitHub? Sign in to your account
项目上线前是专门针对 webpack 打包做了优化的,但是在之后做网络优化的时候通过webpack-bundle-analyzer这个插件发现一些公共的js文件重复打包进了业务代码的js中。这些代码体积虽然很小,但是为了将优化做到极致还是想要将其优化一下。这个过程最大的收获就是让自己对 webpack4.x 相关配置项更加的熟悉,能够使用 webpack 游刃有余的实现自己想要的打包方式。
webpack-bundle-analyzer
记得之前的一位前辈同事说过一句前端优化的话:前端优化就是权衡各种利弊后做的一种妥协。
这里先看下优化结果,因为项目是多入口打包的模式(项目脚手架点击这里)每一个页面一个链接且每一个页面都会有自己的一个js文件。
结果如下:
移动端项目能够在原有的基础上减少20kb已经不小了,而且这20kb是属于重复打包产生的。网络优化方面通过我们公司内部监控平台看到的数据也非常明显,项目上线后统计3天内平均数据,页面加载时间节省了接近800ms(上面的500ms是一个保守的写法,因为会存在网络抖动等不可抗因素)。
优化前的数据统计
优化后的数据统计
在 html 的 head 标签中通过 meta 标签指定开启DNS 预解析和添加预解析的域名,实例代码如下:
<!--告诉浏览器开启DNS 预解析--> <meta http-equiv="x-dns-prefetch-control" content="on" /> <!--添加需要预解析的域名--> <link rel="dns-prefetch" href="//tracker.didiglobal.com"> <link rel="dns-prefetch" href="//omgup.didiglobal.com"> <link rel="dns-prefetch" href="//static.didiglobal.com">
先来看下添加上面的代码之前,页面中静态资源的解析时间
添加了DNS 预解析的代码之后与上面的图片比较之后可以明显发现tracker.didiglobal.com 这个域名在需要加载的时候已经提前完成了预解析。如果这个js文件是影响页面渲染的(比如按需加载的页面),可以提高页面的渲染性能。
tracker.didiglobal.com
平时移动端开发过程中我们都会引用一些第三方的js依赖,比如说调用客户端 jsbridge 方法的 client.js和接入打点服务的console.log.js。
client.js
console.log.js
通常的方法也是比较暴力的方法就是将这些依赖的第三方js加入到 head 标签中,在 dom 解析到 head 标签的时候提前下载这些js并且在之后需要的时候能够随时的调用。但是这些放在head 标签中的js下载时间和执行时间无疑会影响页面的渲染时间。
下面的那张图是我们的项目优化前的一个现状,浅绿色的竖线是开始渲染的时间。从下面的图种可以发现我们引用客户端方法的 fusion.js 和打点的 omega.js (这两个js都是放在head标签中的)都影响了页面的渲染的开始时间。
fusion.js
omega.js
其实我们的业务场景在页面渲染出来之前是不需要这些js的执行结果的,那我们为什么不能将这些js做成异步加载呢?
js的异步加载就是选择合适的时机,使用动态创建 script标签的方式,将需要的js加载到页面中来。我们的项目使用的是 vue ,我们选择在 vue 的生命周期 mounted 中将需要打点的js给加载进来,在我们需要调用客户端方法的地方去加载 fusion.js 通过异步加载库回调的方式,当js加载完之后执行用户的操作。
script
mounted
下面是一段简单的示例代码:
export default function executeOmegaFn(fn) { // 动态加载js到当前的页面中来,并且当js加载完之后执行回调,注意需要判断js是否已经在当前环境加载过了 scriptLoader('//xxx.xxxx.com/static/tracker_global/2.2.2/xxx.min.js', function () { fn && fn(); }); } // 异步加载 需要加载的js mounted() { executeOmegaFn(); },
下图是修改之后的效果,可以发现,页面开始渲染的时间提前了,页面渲染完成的时间也比上面图种的渲染完成的时间提前了 2s 左右。可以很明显的看出页面的渲染和下载执行 omega 的时间是互不影响的。
总结:
默认的 webpack4.x 在 production 模式下会对代码做 tree shaking。但是看完这篇文章之后会发现大多数情况下,tree shaking 并没有办法去除重复的代码。 你的Tree-Shaking并没什么卵用
在我的项目中有个lib目录下面放着根据业务需要自己编写的函数库,通过 webpack-bundle-analyzer 发现它重复的打包进了我们的业务代码的js文件中。下面的图是打包后业务代码包含的js文件,可以看到 lib 目录下的内容重复打包了
看到这种情况的时候就来谈谈自己的优化方案:
vendor
先来看下我的 webpack 关于拆包的配置文件,具体看注释:
splitChunks: { chunks: 'all', automaticNameDelimiter: '.', name: undefined, cacheGroups: { default: false, vendors: false, common: { test: function (module, chunks) { // 这里通过配置规则只将 common lib cube-ui 和cube-ui 组件scroll依赖的better-scroll打包进入common中 if (/src\/common\//.test(module.context) || /src\/lib/.test(module.context) || /cube-ui/.test(module.context) || /better-scroll/.test(module.context)) { return true; } }, chunks: 'all', name: 'common', // 这里的minchunks 非常重要,控制cube-ui使用的组件被超过几个chunk引用之后才打包进入该common中否则不打包进该js中 minChunks: 2, priority: 20 }, vendor: { chunks: 'all', test: (module, chunks) => { // 将node_modules 目录下的依赖统一打包进入vendor中 if (/node_modules/.test(module.context)) { return true; } }, name: 'vendor', minChunks: 2, // 配置chunk的打包优先级,这里的数值决定了node_modules下的 cube-ui 不会打包进入 vendor 中 priority: 10, enforce: true } } }
在项目中写了一个 js 将整个项目需要使用的 cube-ui 组件统一引入。具体的代码看这里,调用方法看这里。
这里需要注意下,就是不要将使用频率低的体积大的组件在这个文件中引入,具体的原因可以看下面代码的注释。
/** * @file cube ui 组件引入统一配置文件 建议这里只引入每个页面使用的基础组件,对于复杂的组件比如scroll datepicer组件 * 在页面中单独引入,然后在webpack中同过 minChunk 来指定当这些比较大的组件超过 x 引用数时才打进common中否则单独打包进页面的js中 * @date 2019/04/02 * @author [email protected] */ /* eslint-disable */ import Vue from 'vue'; import { Style, Toast, Loading, // 这里去除 scroll是在页面中单独引入,以使webpack打包时可以根据引用chunk选择是否将该组件打包进入页面的js中还是选择打包进入common中 // Scroll, createAPI } from 'cube-ui'; export default function initCubeComponent() { Vue.use(Loading); // Vue.use(Scroll); createAPI(Vue, Toast, ['timeout'], true); }
项目中目前只有pay_history这个页面使用了 cube-ui 的 scroll 组件,单独打包进业务代码的js中所以该页面的js较大。
当有超过两个页面使用了 scroll 这个组件的时候,根据 webpack 的配置会自动打包进入common中。下图是打包结果,页面的js大小缩小了,commonjs文件的体积变大了。
有时候我在写代码的时候没有注意,通过 import 引用了一个第三方依赖但是最后没有使用它或者是上线的时候并不需要将执行的表达式注释掉,而没有注释掉 import 语句 ,打包结果也会包含这个import的js的。比如以下代码:
import
import VConsole from 'vconsole'; // 测试的时候我们可能打开了下面的注释,但是在上线的时候只是注释了下面的代码,webpack打包的时候仍然会将vconsole打包进目标js中。 // var vConsole = new VConsole();
目前使用 babel + ES6 组合编写前端代码已经很少使用 babel-polyfill 了。 主要是它会污染全局变量,而且是全量引入 polyfill ,打包后的目标js文件会非常的大。
现在大多数情况下都会使用 babel-preset-env 来做 polyfill。更智能或是高级的做法是使用在线的polyfill服务,参考链接
在使用 preset-env 的时候,大多数情况都会忽略去配置兼容的 browsers 列表。或者直接从网络上搜索到配置,不深究其产出结果直接复制、粘贴使用。其实这里的配置会影响我们的js文件的大小。
如果使用 autoprefix 给css自动添加厂商前缀时,也是需要配置一个 browsers 列表。这个配置列表也是会影响css文件大小的。 browserslist官方文档
举个例子,现在 windows phone 手机几乎绝迹,对于现在的移动端项目是不需要考虑兼容 pc 和 wp手机的,那我们在添加 polyfill 或是 css 厂商前缀时是不是可以去掉 -ms- 前缀呢,那么该怎么配置呢?
-ms-
我的配置如下:
"browsers": [ "> 1%", "last 2 versions", "iOS >= 6.0", "not ie > 0", "not ie_mob > 0", "not dead" ]
这里简单提一下,正确使用css新特性的重要性。下面这段代码是我在我们的一个比较旧的项目中看到的。其实咋一看没有什么问题,但是在现代浏览器中浏览却出现了问题?
.example { display: flex; display: -webkit-box; } .test { flex:1 }
这总写法就是对 flex 布局 解析不一致导致的问题。 在chrome 中 .example生效的是 display: -webkit-box 这个弹性盒布局过渡期的写法。 在 .test 中生效的是 flex:1 而这个是新标准的写法。导致布局显示出现问题。
.example
display: -webkit-box
.test
flex:1
autoprefix之后的代码
.example { display: -ms-flexbox; display: flex; display: -webkit-box; } .test { -webkit-box-flex:1; -ms-flex:1; flex:1 }
同样的也会导致上面没有 autoprefix 之前的问题,布局发生错误。
使用webpack编译代码,当代码生成了多个chunk时,webpack是怎么加载这些chunk呢?
webpack 自己实现了一个模块加载器来维护不同模块间的关系(webpack 文章中称它为 runtime 模块)。标识不同模块是通过一串数字来做标识的(具体的可以写个简单的demo来看下编译结果)。
当修改了一个文件的代码,在 runtime 模块中这串数字会发生变化,如果在webpack 打包时对这部分代码不做处理,它会默认的产出到我们的 vendor 代码中。导致只要修改代码,生成的 vendor 文件的hash就会发生变化,没办法充分利用浏览器缓存。
webpack 已经提供了配置可以将这部分代码单独抽离出来生成一个文件。因为这部分代码经常发生变化,而且代码体积很小,为了减少 http 请求可以在打包的时候选择将这部分代码内联进html模板文件中。
在webpack4.x中可以通过以下配置实现 optimization.runtimeChunk: 'single'。如果想要将生产的runtime代码内联进入html,可以使用这个webpack插件inline-manifest-webpack-plugin。
optimization.runtimeChunk: 'single'
inline-manifest-webpack-plugin
async和await语法糖能够很好的解决异步编程问题。在编写前端代码的过程中也可以使用该语法糖。不管是使用 babel 和 typescript 编译代码其实都是将 async和 await 编译成了 generator。
如果对代码体积有极致的需求,我是不太建议在前端代码中使用 async 和await的。因为现在很多第三方依赖处理异步的方式都是使用 Promise ,我们使用的 node_modules依赖一般也都是编译后的 ES5 的源文件,都是对 Promise 做了 Polyfill 的。而且我们自己的 babel 配置也会对 Promise 做 Polyfill, 如果混合使用 async 和 await ,babel又会增加相关 generator run time 代码。
Promise
看一个真实的代码案例:以下代码中出现了一个 async 表达式,但是在任何调用这个方法地方的时候都没有使用await ,通过阅读代码也确定这里不需要使用 async 表达式
添加了一个async表达式后,编译结果如下图。可以发现在产出的目标文件中多了一个generaotr runtime 的代码,而且这部分代码的体积还是比较大的
generaotr runtime
这是编译前的文件大小
去掉这个不必要的 async 表达式后,下图可以看到编译后的文件大小,代码体积缩小了将近 3KB。
在第一小节中已经简单了介绍了优化第三方依赖的打包方法了,这里再做下总结:
后编译,就是在使用的时候编译,可以解决代码重复打包的问题。按需引入是指,假如我使用的cube-ui有20个组件但是我只使用了其中的一个 alert 组件,避免全部引入,增加产出文件的体积;
lodash这个库确实挺好用的,但它有个缺点,全量引入打包后体积较大。那么lodash能不能按需引入呢?
当然是可以的,可以在 npm上搜索 lodash-es这个模块,然后根据文档执行命令可以将 lodash 导出为 es6 modules。 然后就可以通过 import 方式单独导入某个函数的方式使用。
其实lodash到底怎么优化,有没有必要优化,这个也是有一些争议的,具体的可以阅读下百度高T灰大的这篇文章 lodash在webpack中的各项优化的尝试。灰大的这篇文章也论证了文章开头所说的,优化就是根据业务需求做了各种权衡后的一种妥协。
hash 是跟整个项目的构建相关,只要项目里有文件更改,整个项目构建的hash值都会更改,并且全部文件都共用相同的hash值;
hash
chunkhash 采用hash计算的话,每一次构建后生成的哈希值都不一样,即使文件内容压根没有改变。这样子是没办法实现缓存效果,我们需要换另一种哈希值计算方式,即chunkhash。chunkhash和hash不一样,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的哈希值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成哈希值,那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。
chunkhash
contenthash 使用 webpack 编译代码时,我们可以在js文件里面引用css文件的。所以这两个文件应该共用相同的chunkhash值。但是有个问题,如果js更改了代码,css文件就算内容没有任何改变,由于是该模块发生了改变,导致css文件会重复构建。这个时候,我们可以使用 extra-text-webpack-plugin 里的 contenthash 值,保证即使css文件所处的模块里其它文件内容改变,只要css文件内容不变,那么就不会重复构建。
contenthash
extra-text-webpack-plugin
目前网络上能够查询到的 webpack4.x 的文档对于 splitChunks 并没有完整的中文翻译,如果对于英文阅读没有障碍,可以直接去阅读官方文档,如果英文不好可以参考下面的参数和中文释义:
splitChunks
首先 Webpack4.x 会根据下述条件自动进行代码块分割:
// 配置项解释如下 splitChunks: { // 默认作用于异步chunk,值为all //initial模式下会分开优化打包异步和非异步模块。而all会把异步和非异步同时进行优化打包。也就是说moduleA在indexA中异步引入,indexB中同步引入,initial下moduleA会出现在两个打包块中,而all只会出现一个。 // all 所有chunk代码(同步加载和异步加载的模块都可以使用)的公共部分分离出来成为一个单独的文件 // async 将异步加载模块代码公共部分抽离出来一个单独的文件 chunks: 'async', // 默认值是30kb 当文件体积 >= minsize 时将会被拆分为两个文件 某则不生成新的chunk minSize: 30000, // 共享该module的最小chunk数 (当>= minchunks时才会被拆分为新的chunk) minChunks: 1, // 最多有5个异步加载请求该module maxAsyncRequests: 5, // 初始话时最多有3个请求该module maxInitialRequests: 3, // 名字中间的间隔符 automaticNameDelimiter: '~', // 打包后的名称,如果设置为 truw 默认是chunk的名字通过分隔符(默认是~)分隔开,如vendor~ 也可以自己手动指定 name: true, // 设置缓存组用来抽取满足不同规则的chunk, 切割成的每一个新的chunk就是一个cache group cacheGroups: { common: { // 抽取的chunk的名字 name: 'common', // 同外层的参数配置,覆盖外层的chunks,以chunk为维度进行抽取 chunks: 'all', // 可以为字符串,正则表达式,函数,以module为维度进行抽取, // 只要是满足条件的module都会被抽取到该common的chunk中,为函数时第一个参数 // 是遍历到的每一个模块,第二个参数是每一个引用到该模块的chunks数组 test(module, chunks) { // module.context 当前文件模块所属的目录 该目录下包含多个文件 // module.resource 当前模块文件的绝对路径 if (/scroll/.test(module.context)) { let chunkName = ''; // 引用该chunk的模块名字 chunks.forEach(item => { chunkName += item.name + ','; }); console.log(`module-scroll`, module.context, chunkName, chunks.length); } }, // 优先级,一个chunk很可能满足多个缓存组,会被抽取到优先级高的缓存组中, 数值打的优先被选择 priority: 10, // 最少被几个chunk引用 minChunks: 2, // 如果该chunk中引用了已经被抽取的chunk,直接引用该chunk,不会重复打包代码 (当module未发生变化时是否使用之前的Module) reuseExistingChunk: true, // 如果cacheGroup中没有设置minSize,则据此判断是否使用上层的minSize,true:则使用0,false:使用上层minSize enforce: true } } };
The text was updated successfully, but these errors were encountered:
No branches or pull requests
背景:
项目上线前是专门针对 webpack 打包做了优化的,但是在之后做网络优化的时候通过
webpack-bundle-analyzer这个插件发现一些公共的js文件重复打包进了业务代码的js中。这些代码体积虽然很小,但是为了将优化做到极致还是想要将其优化一下。这个过程最大的收获就是让自己对 webpack4.x 相关配置项更加的熟悉,能够使用 webpack 游刃有余的实现自己想要的打包方式。记得之前的一位前辈同事说过一句前端优化的话:前端优化就是权衡各种利弊后做的一种妥协。
优化结果:
这里先看下优化结果,因为项目是多入口打包的模式(项目脚手架点击这里)每一个页面一个链接且每一个页面都会有自己的一个js文件。
结果如下:
移动端项目能够在原有的基础上减少20kb已经不小了,而且这20kb是属于重复打包产生的。网络优化方面通过我们公司内部监控平台看到的数据也非常明显,项目上线后统计3天内平均数据,页面加载时间节省了接近800ms(上面的500ms是一个保守的写法,因为会存在网络抖动等不可抗因素)。
优化前的数据统计
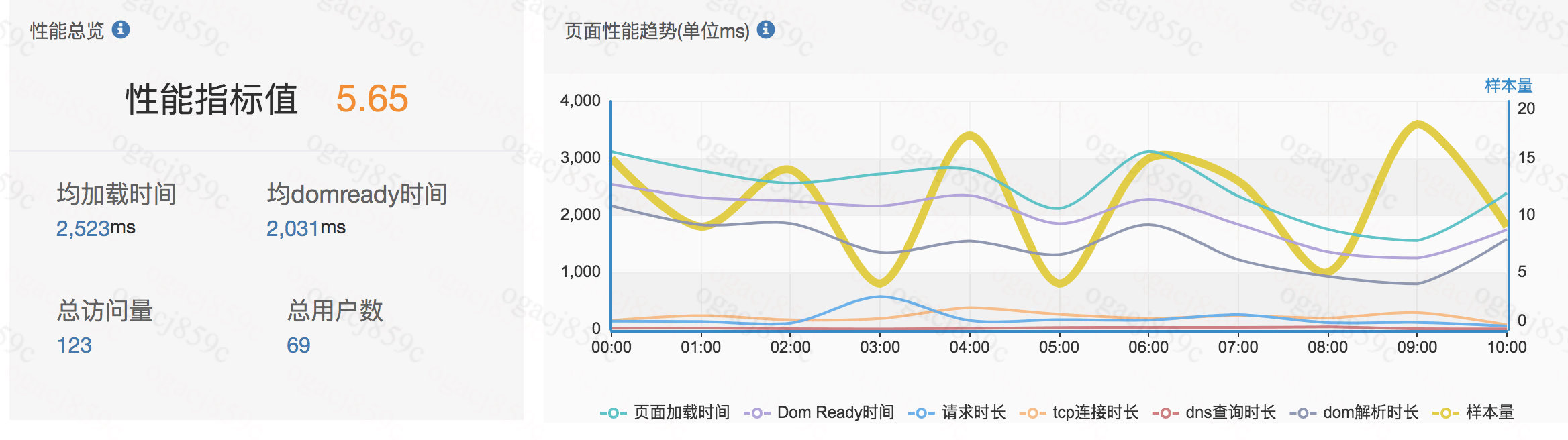
优化后的数据统计

优化网络解析时长和执行时长
1、添加DNS预解析
在 html 的 head 标签中通过 meta 标签指定开启DNS 预解析和添加预解析的域名,实例代码如下:
先来看下添加上面的代码之前,页面中静态资源的解析时间
添加了DNS 预解析的代码之后与上面的图片比较之后可以明显发现
tracker.didiglobal.com这个域名在需要加载的时候已经提前完成了预解析。如果这个js文件是影响页面渲染的(比如按需加载的页面),可以提高页面的渲染性能。2、延时执行影响页面渲染的代码
平时移动端开发过程中我们都会引用一些第三方的js依赖,比如说调用客户端 jsbridge 方法的
client.js和接入打点服务的console.log.js。通常的方法也是比较暴力的方法就是将这些依赖的第三方js加入到 head 标签中,在 dom 解析到 head 标签的时候提前下载这些js并且在之后需要的时候能够随时的调用。但是这些放在head 标签中的js下载时间和执行时间无疑会影响页面的渲染时间。
下面的那张图是我们的项目优化前的一个现状,浅绿色的竖线是开始渲染的时间。从下面的图种可以发现我们引用客户端方法的
fusion.js和打点的omega.js(这两个js都是放在head标签中的)都影响了页面的渲染的开始时间。其实我们的业务场景在页面渲染出来之前是不需要这些js的执行结果的,那我们为什么不能将这些js做成异步加载呢?
js的异步加载就是选择合适的时机,使用动态创建
script标签的方式,将需要的js加载到页面中来。我们的项目使用的是 vue ,我们选择在 vue 的生命周期mounted中将需要打点的js给加载进来,在我们需要调用客户端方法的地方去加载fusion.js通过异步加载库回调的方式,当js加载完之后执行用户的操作。下面是一段简单的示例代码:
下图是修改之后的效果,可以发现,页面开始渲染的时间提前了,页面渲染完成的时间也比上面图种的渲染完成的时间提前了 2s 左右。可以很明显的看出页面的渲染和下载执行 omega 的时间是互不影响的。
总结:
优化webpack产出
1、优化代码重复打包
默认的 webpack4.x 在 production 模式下会对代码做 tree shaking。但是看完这篇文章之后会发现大多数情况下,tree shaking 并没有办法去除重复的代码。 你的Tree-Shaking并没什么卵用
在我的项目中有个lib目录下面放着根据业务需要自己编写的函数库,通过
webpack-bundle-analyzer发现它重复的打包进了我们的业务代码的js文件中。下面的图是打包后业务代码包含的js文件,可以看到 lib 目录下的内容重复打包了看到这种情况的时候就来谈谈自己的优化方案:
vendor依赖;先来看下我的 webpack 关于拆包的配置文件,具体看注释:
在项目中写了一个 js 将整个项目需要使用的 cube-ui 组件统一引入。具体的代码看这里,调用方法看这里。
这里需要注意下,就是不要将使用频率低的体积大的组件在这个文件中引入,具体的原因可以看下面代码的注释。
项目中目前只有pay_history这个页面使用了 cube-ui 的 scroll 组件,单独打包进业务代码的js中所以该页面的js较大。
当有超过两个页面使用了 scroll 这个组件的时候,根据 webpack 的配置会自动打包进入common中。下图是打包结果,页面的js大小缩小了,commonjs文件的体积变大了。
总结:
2、去掉不必要的import
有时候我在写代码的时候没有注意,通过 import 引用了一个第三方依赖但是最后没有使用它或者是上线的时候并不需要将执行的表达式注释掉,而没有注释掉
import语句 ,打包结果也会包含这个import的js的。比如以下代码:总结:
3、babel-preset-env 和 autoprefix 配置优化
目前使用 babel + ES6 组合编写前端代码已经很少使用 babel-polyfill 了。 主要是它会污染全局变量,而且是全量引入 polyfill ,打包后的目标js文件会非常的大。
现在大多数情况下都会使用 babel-preset-env 来做 polyfill。更智能或是高级的做法是使用在线的polyfill服务,参考链接
在使用 preset-env 的时候,大多数情况都会忽略去配置兼容的 browsers 列表。或者直接从网络上搜索到配置,不深究其产出结果直接复制、粘贴使用。其实这里的配置会影响我们的js文件的大小。
如果使用 autoprefix 给css自动添加厂商前缀时,也是需要配置一个 browsers 列表。这个配置列表也是会影响css文件大小的。 browserslist官方文档
举个例子,现在 windows phone 手机几乎绝迹,对于现在的移动端项目是不需要考虑兼容 pc 和 wp手机的,那我们在添加 polyfill 或是 css 厂商前缀时是不是可以去掉
-ms-前缀呢,那么该怎么配置呢?我的配置如下:
这里简单提一下,正确使用css新特性的重要性。下面这段代码是我在我们的一个比较旧的项目中看到的。其实咋一看没有什么问题,但是在现代浏览器中浏览却出现了问题?
这总写法就是对 flex 布局 解析不一致导致的问题。 在chrome 中
.example生效的是display: -webkit-box这个弹性盒布局过渡期的写法。 在.test中生效的是flex:1而这个是新标准的写法。导致布局显示出现问题。autoprefix之后的代码
同样的也会导致上面没有 autoprefix 之前的问题,布局发生错误。
总结:
4、webpack runtime文件inline
使用webpack编译代码,当代码生成了多个chunk时,webpack是怎么加载这些chunk呢?
webpack 自己实现了一个模块加载器来维护不同模块间的关系(webpack 文章中称它为 runtime 模块)。标识不同模块是通过一串数字来做标识的(具体的可以写个简单的demo来看下编译结果)。
当修改了一个文件的代码,在 runtime 模块中这串数字会发生变化,如果在webpack 打包时对这部分代码不做处理,它会默认的产出到我们的
vendor代码中。导致只要修改代码,生成的 vendor 文件的hash就会发生变化,没办法充分利用浏览器缓存。webpack 已经提供了配置可以将这部分代码单独抽离出来生成一个文件。因为这部分代码经常发生变化,而且代码体积很小,为了减少 http 请求可以在打包的时候选择将这部分代码内联进html模板文件中。
在webpack4.x中可以通过以下配置实现
optimization.runtimeChunk: 'single'。如果想要将生产的runtime代码内联进入html,可以使用这个webpack插件inline-manifest-webpack-plugin。5、 去除不必要的async语句
async和await语法糖能够很好的解决异步编程问题。在编写前端代码的过程中也可以使用该语法糖。不管是使用 babel 和 typescript 编译代码其实都是将 async和 await 编译成了 generator。
如果对代码体积有极致的需求,我是不太建议在前端代码中使用 async 和await的。因为现在很多第三方依赖处理异步的方式都是使用
Promise,我们使用的 node_modules依赖一般也都是编译后的 ES5 的源文件,都是对Promise做了 Polyfill 的。而且我们自己的 babel 配置也会对Promise做 Polyfill, 如果混合使用 async 和 await ,babel又会增加相关 generator run time 代码。看一个真实的代码案例:以下代码中出现了一个 async 表达式,但是在任何调用这个方法地方的时候都没有使用await ,通过阅读代码也确定这里不需要使用 async 表达式
添加了一个async表达式后,编译结果如下图。可以发现在产出的目标文件中多了一个
generaotr runtime的代码,而且这部分代码的体积还是比较大的这是编译前的文件大小
去掉这个不必要的 async 表达式后,下图可以看到编译后的文件大小,代码体积缩小了将近 3KB。
6、优化第三方依赖
在第一小节中已经简单了介绍了优化第三方依赖的打包方法了,这里再做下总结:
7、lodash按需引入
lodash这个库确实挺好用的,但它有个缺点,全量引入打包后体积较大。那么lodash能不能按需引入呢?
当然是可以的,可以在 npm上搜索 lodash-es这个模块,然后根据文档执行命令可以将 lodash 导出为 es6 modules。 然后就可以通过 import 方式单独导入某个函数的方式使用。
其实lodash到底怎么优化,有没有必要优化,这个也是有一些争议的,具体的可以阅读下百度高T灰大的这篇文章 lodash在webpack中的各项优化的尝试。灰大的这篇文章也论证了文章开头所说的,优化就是根据业务需求做了各种权衡后的一种妥协。
webpack 重要知识总结
1、hash、contenthash、chunkhash的区别
hash是跟整个项目的构建相关,只要项目里有文件更改,整个项目构建的hash值都会更改,并且全部文件都共用相同的hash值;chunkhash采用hash计算的话,每一次构建后生成的哈希值都不一样,即使文件内容压根没有改变。这样子是没办法实现缓存效果,我们需要换另一种哈希值计算方式,即chunkhash。chunkhash和hash不一样,它根据不同的入口文件(Entry)进行依赖文件解析、构建对应的chunk,生成对应的哈希值。我们在生产环境里把一些公共库和程序入口文件区分开,单独打包构建,接着我们采用chunkhash的方式生成哈希值,那么只要我们不改动公共库的代码,就可以保证其哈希值不会受影响。contenthash使用 webpack 编译代码时,我们可以在js文件里面引用css文件的。所以这两个文件应该共用相同的chunkhash值。但是有个问题,如果js更改了代码,css文件就算内容没有任何改变,由于是该模块发生了改变,导致css文件会重复构建。这个时候,我们可以使用extra-text-webpack-plugin里的 contenthash 值,保证即使css文件所处的模块里其它文件内容改变,只要css文件内容不变,那么就不会重复构建。2、splitChunks详解
目前网络上能够查询到的 webpack4.x 的文档对于
splitChunks并没有完整的中文翻译,如果对于英文阅读没有障碍,可以直接去阅读官方文档,如果英文不好可以参考下面的参数和中文释义:首先 Webpack4.x 会根据下述条件自动进行代码块分割:
参考文章
The text was updated successfully, but these errors were encountered: