| comments | difficulty | edit_url | tags | ||||
|---|---|---|---|---|---|---|---|
true |
中等 |
|
给定一个链接 startUrl 和一个接口 HtmlParser ,请你实现一个网络爬虫,以实现爬取同 startUrl 拥有相同 主机名 的全部链接。
该爬虫得到的全部链接可以 任何顺序 返回结果。
你的网络爬虫应当按照如下模式工作:
- 自链接
startUrl开始爬取 - 调用
HtmlParser.getUrls(url)来获得链接url页面中的全部链接 - 同一个链接最多只爬取一次
- 只输出 域名 与
startUrl相同 的链接集合

如上所示的一个链接,其域名为 example.org。简单起见,你可以假设所有的链接都采用 http协议 并没有指定 端口。例如,链接 http://leetcode.com/problems 和 http://leetcode.com/contest 是同一个域名下的,而链接 http://example.org/test 和 http://example.com/abc 是不在同一域名下的。
HtmlParser 接口定义如下:
interface HtmlParser {
// 返回给定 url 对应的页面中的全部 url 。
public List<String> getUrls(String url);
}
下面是两个实例,用以解释该问题的设计功能,对于自定义测试,你可以使用三个变量 urls, edges 和 startUrl。注意在代码实现中,你只可以访问 startUrl ,而 urls 和 edges 不可以在你的代码中被直接访问。
注意:将尾随斜线“/”的相同 URL 视为不同的 URL。例如,“http://news.yahoo.com” 和 “http://news.yahoo.com/” 是不同的域名。
示例 1:
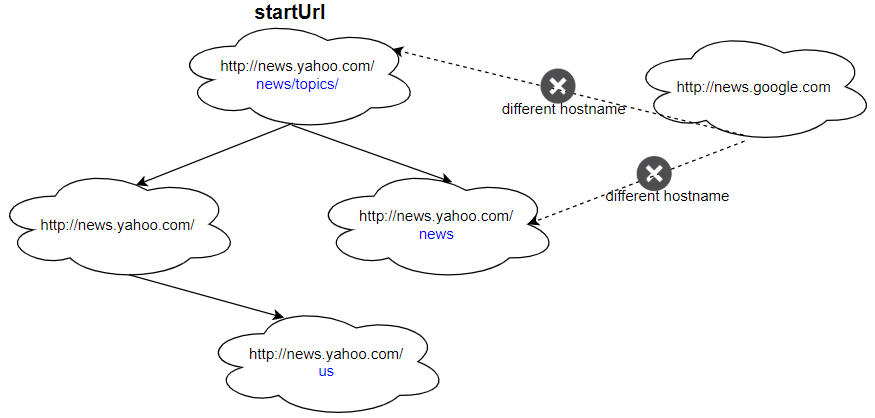
输入: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com", "http://news.yahoo.com/us" ] edges = [[2,0],[2,1],[3,2],[3,1],[0,4]] startUrl = "http://news.yahoo.com/news/topics/" 输出:[ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.yahoo.com/us" ]
示例 2:

输入: urls = [ "http://news.yahoo.com", "http://news.yahoo.com/news", "http://news.yahoo.com/news/topics/", "http://news.google.com" ] edges = [[0,2],[2,1],[3,2],[3,1],[3,0]] startUrl = "http://news.google.com" 输出:["http://news.google.com"] 解释:startUrl 链接到所有其他不共享相同主机名的页面。
提示:
1 <= urls.length <= 10001 <= urls[i].length <= 300startUrl为urls中的一个。- 主机名的长为1到63个字符(包括点),只能包含从‘a’到‘z’的ASCII字母、‘0’到‘9’的数字以及连字符即减号(‘-’)。
- 主机名不会以连字符即减号(‘-’)开头或结尾。
- 关于域名有效性的约束可参考: https://en.wikipedia.org/wiki/Hostname#Restrictions_on_valid_hostnames
- 你可以假定url库中不包含重复项。
# """
# This is HtmlParser's API interface.
# You should not implement it, or speculate about its implementation
# """
# class HtmlParser(object):
# def getUrls(self, url):
# """
# :type url: str
# :rtype List[str]
# """
class Solution:
def crawl(self, startUrl: str, htmlParser: 'HtmlParser') -> List[str]:
def host(url):
url = url[7:]
return url.split('/')[0]
def dfs(url):
if url in ans:
return
ans.add(url)
for next in htmlParser.getUrls(url):
if host(url) == host(next):
dfs(next)
ans = set()
dfs(startUrl)
return list(ans)/**
* // This is the HtmlParser's API interface.
* // You should not implement it, or speculate about its implementation
* interface HtmlParser {
* public List<String> getUrls(String url) {}
* }
*/
class Solution {
private Set<String> ans;
public List<String> crawl(String startUrl, HtmlParser htmlParser) {
ans = new HashSet<>();
dfs(startUrl, htmlParser);
return new ArrayList<>(ans);
}
private void dfs(String url, HtmlParser htmlParser) {
if (ans.contains(url)) {
return;
}
ans.add(url);
for (String next : htmlParser.getUrls(url)) {
if (host(next).equals(host(url))) {
dfs(next, htmlParser);
}
}
}
private String host(String url) {
url = url.substring(7);
return url.split("/")[0];
}
}/**
* // This is the HtmlParser's API interface.
* // You should not implement it, or speculate about its implementation
* class HtmlParser {
* public:
* vector<string> getUrls(string url);
* };
*/
class Solution {
public:
vector<string> ans;
unordered_set<string> vis;
vector<string> crawl(string startUrl, HtmlParser htmlParser) {
dfs(startUrl, htmlParser);
return ans;
}
void dfs(string& url, HtmlParser& htmlParser) {
if (vis.count(url)) return;
vis.insert(url);
ans.push_back(url);
for (string next : htmlParser.getUrls(url))
if (host(url) == host(next))
dfs(next, htmlParser);
}
string host(string url) {
int i = 7;
string res;
for (; i < url.size(); ++i) {
if (url[i] == '/') break;
res += url[i];
}
return res;
}
};/**
* // This is HtmlParser's API interface.
* // You should not implement it, or speculate about its implementation
* type HtmlParser struct {
* func GetUrls(url string) []string {}
* }
*/
func crawl(startUrl string, htmlParser HtmlParser) []string {
var ans []string
vis := make(map[string]bool)
var dfs func(url string)
host := func(url string) string {
return strings.Split(url[7:], "/")[0]
}
dfs = func(url string) {
if vis[url] {
return
}
vis[url] = true
ans = append(ans, url)
for _, next := range htmlParser.GetUrls(url) {
if host(next) == host(url) {
dfs(next)
}
}
}
dfs(startUrl)
return ans
}