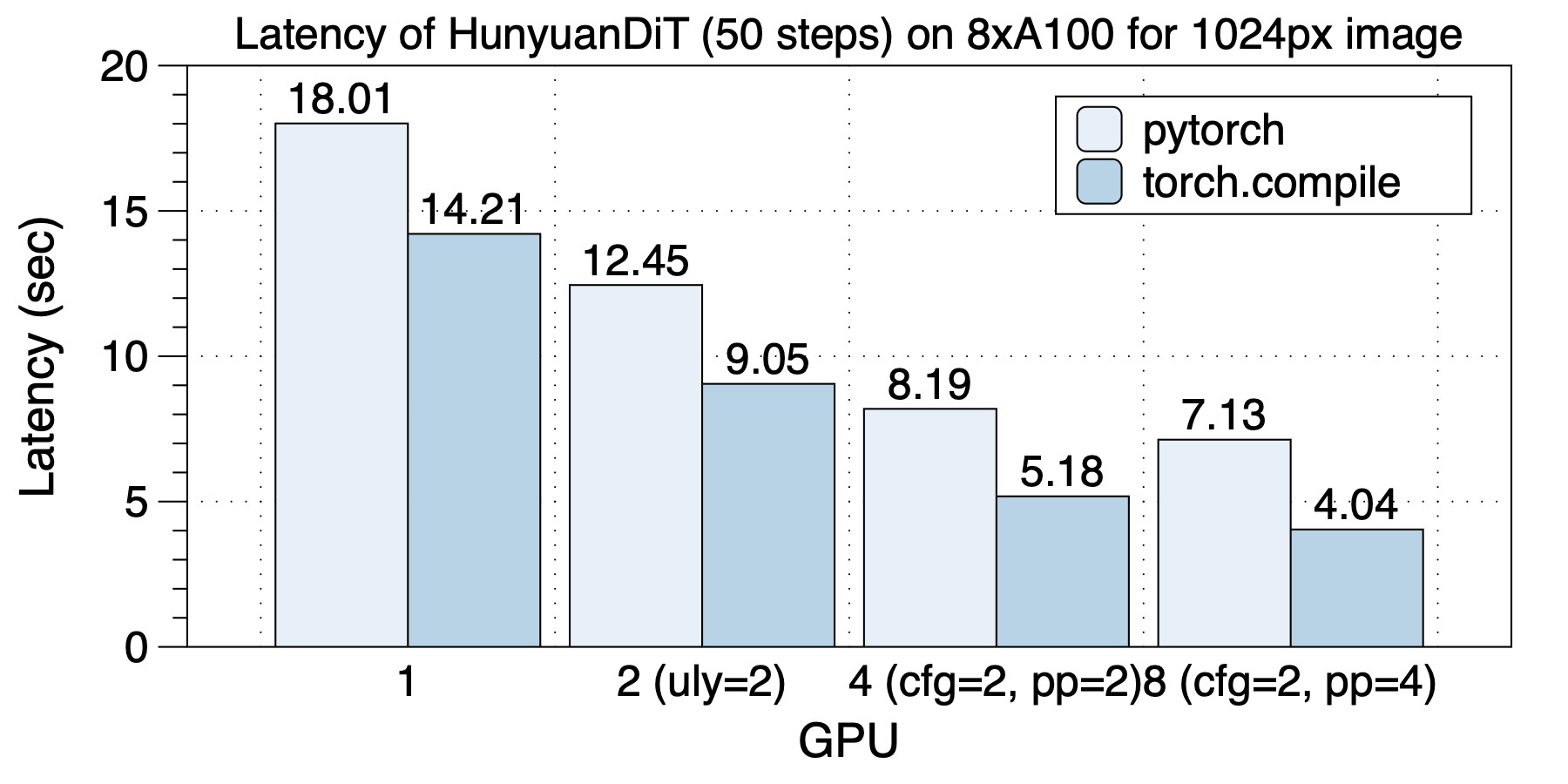
On an 8xA100 (NVLink) machine, the optimal parallel scheme varies with the number of GPUs used, highlighting the importance of hybrid parallelism. The best parallel strategies for different GPU scales are as follows: with 2 GPUs, use ulysses_degree=2; with 4 GPUs, use cfg_parallel=2, ulysses_degree=2; with 8 GPUs, use cfg_parallel=2, pipefusion_parallel=4.
The acceleration effect brought by torch.compile is quite impressive, with parallel schemes achieving a speedup of 1.26x to 1.76x. This enhancement is most pronounced in scenarios of 8 GPUs, where a speedup of 1.76x can be achieved.
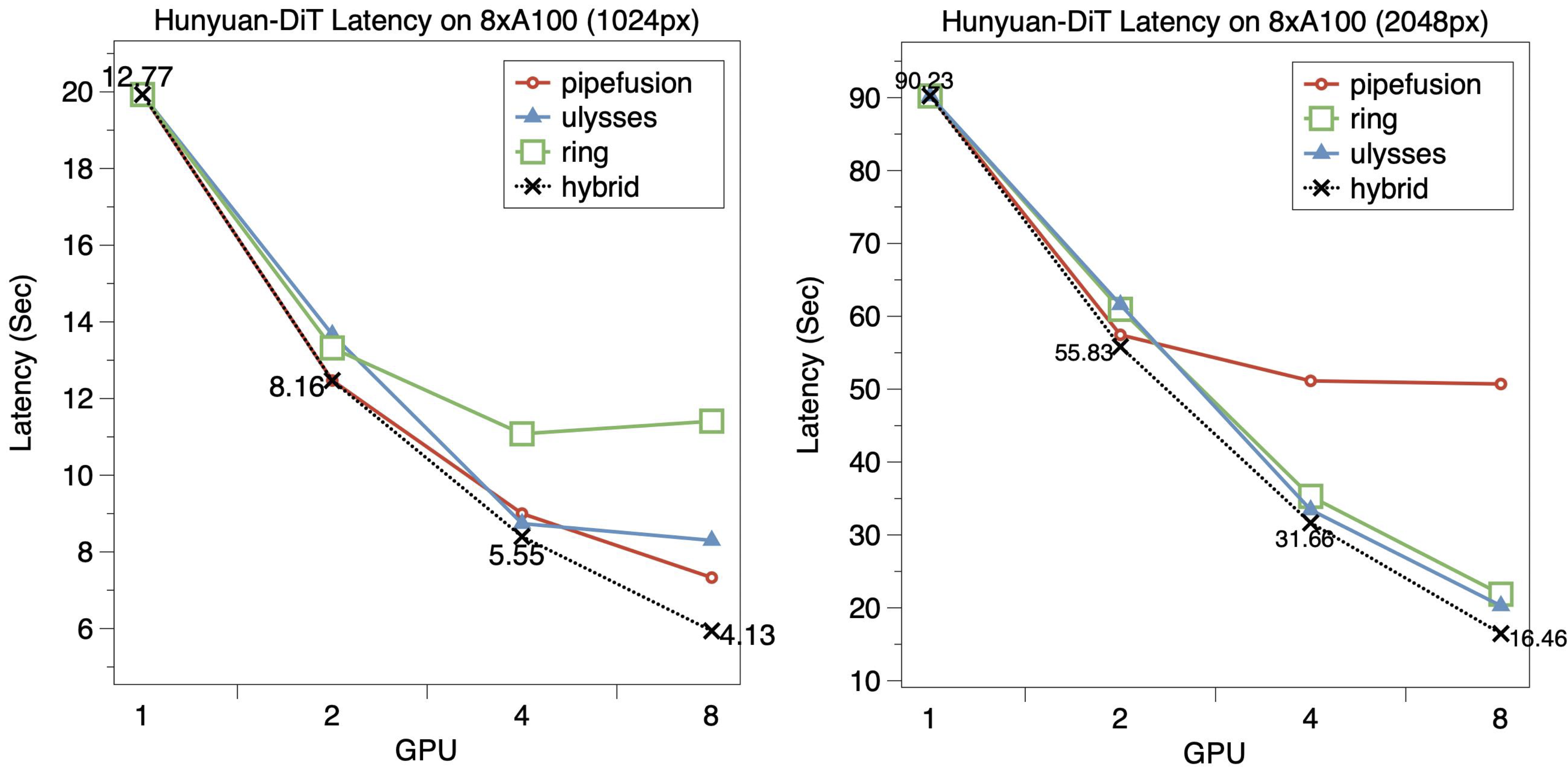
The following figure illustrates the scalability of HunyuanDiT on 8xA100 GPUs. We additionally tested 2048px image generation tasks, although HunyuanDiT is not designed to generate 2048px images.
HunyuanDiT employs DiT Blocks interconnected via Skip Connections, with each DiT Block connected to both an adjacent and a non-adjacent block.
For the 1024px image generation task, the optimal hybrid parallel configurations are as follows: pipefusion=2 for 2 GPUs; cfg=2, pipefusion=2 for 4 GPUs; cfg=2, pipefusion=4 for 8 GPUs. We employ warmup step=1 for PipeFusion. Hybrid parallelism achieves a 1.04x and 1.23x speedup over single parallel methods on 4 and 8 GPUs, respectively. PipeFusion exhibits lower latency than SP-Ulysses on 8 GPUs but similar latency on 4 GPUs. SP-Ring demonstrates the poorest scalability among all parallel methods.
For the 2048px image generation task, the optimal hybrid parallel configuration becomes cfg=2, pipefusion=2, ring=2 for 8 GPUs. Similarly, hybrid parallel achieves a marginal speedup over a single parallel method on 4 and 8 GPUs. However, PipeFusion showcases much higher latency than SP-Ulysses and SP-Ring when using 4 or 8 GPUs, due to the additional P2P communication required by the Skip Connections between GPUs. This issue is mitigated when PipeFusion operates with a parallel degree of 2, highlighting its necessity for optimal performance in hybrid configurations. As the image size increases from 1024px to 2048px, the performance gap between SP-Ring and SP-Ulysses diminishes, because of the reduced computation-to-communication ratio of the model, which allows SP-Ring to hide a larger portion of the communication overhead.
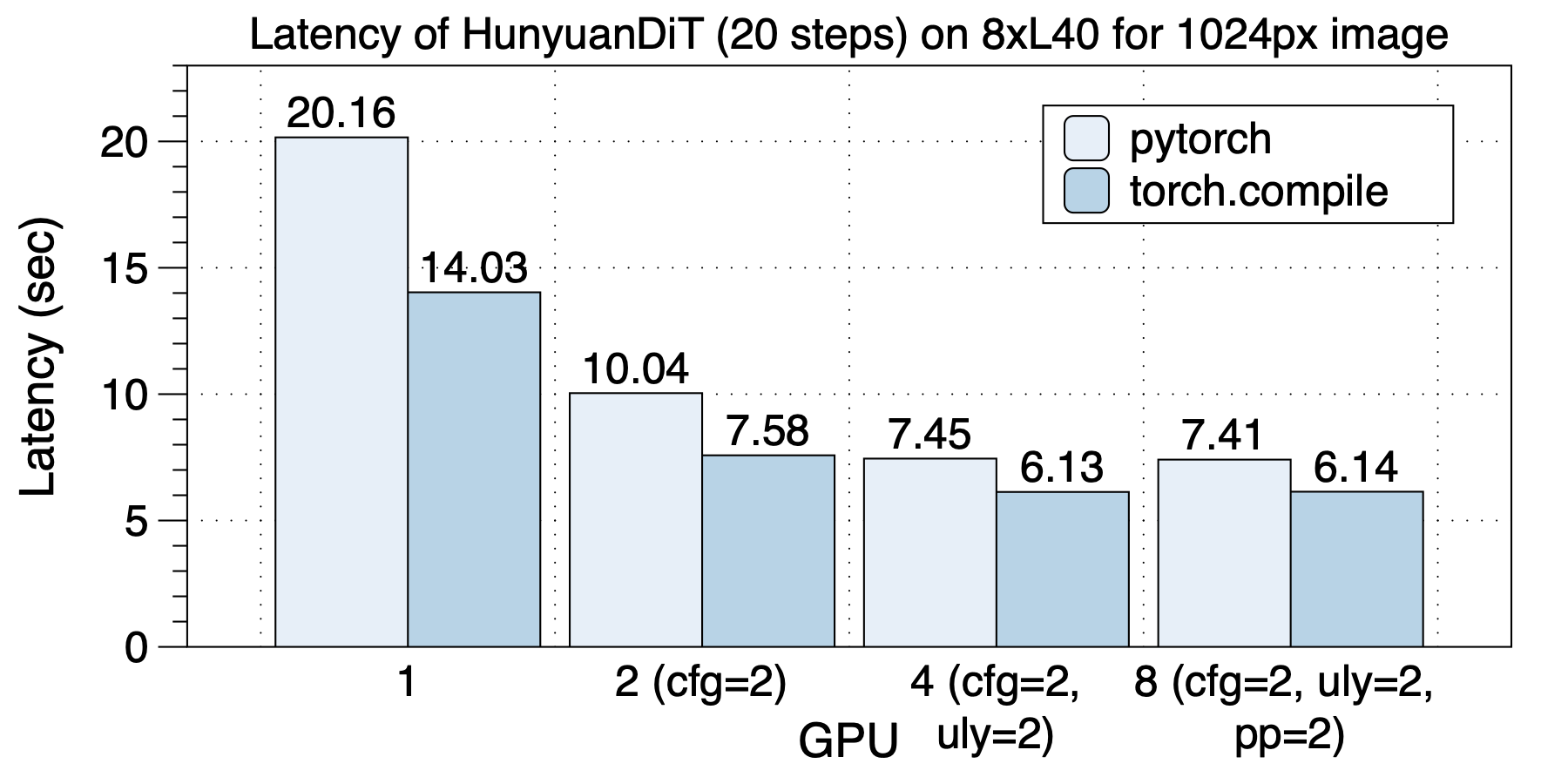
The latency situation on 8xL40 (PCIe) is depicted in the graph below. Similarly, the optimal parallel strategies vary with different GPU scales. Unlike on A100, there is no significant change in latency between 8 GPUs and 4 GPUs on L40. We attribute this to the low communication bandwidth across sockets due to PCIe limitations.
torch.compile provides a speedup ranging from 1.2x to 1.43x.
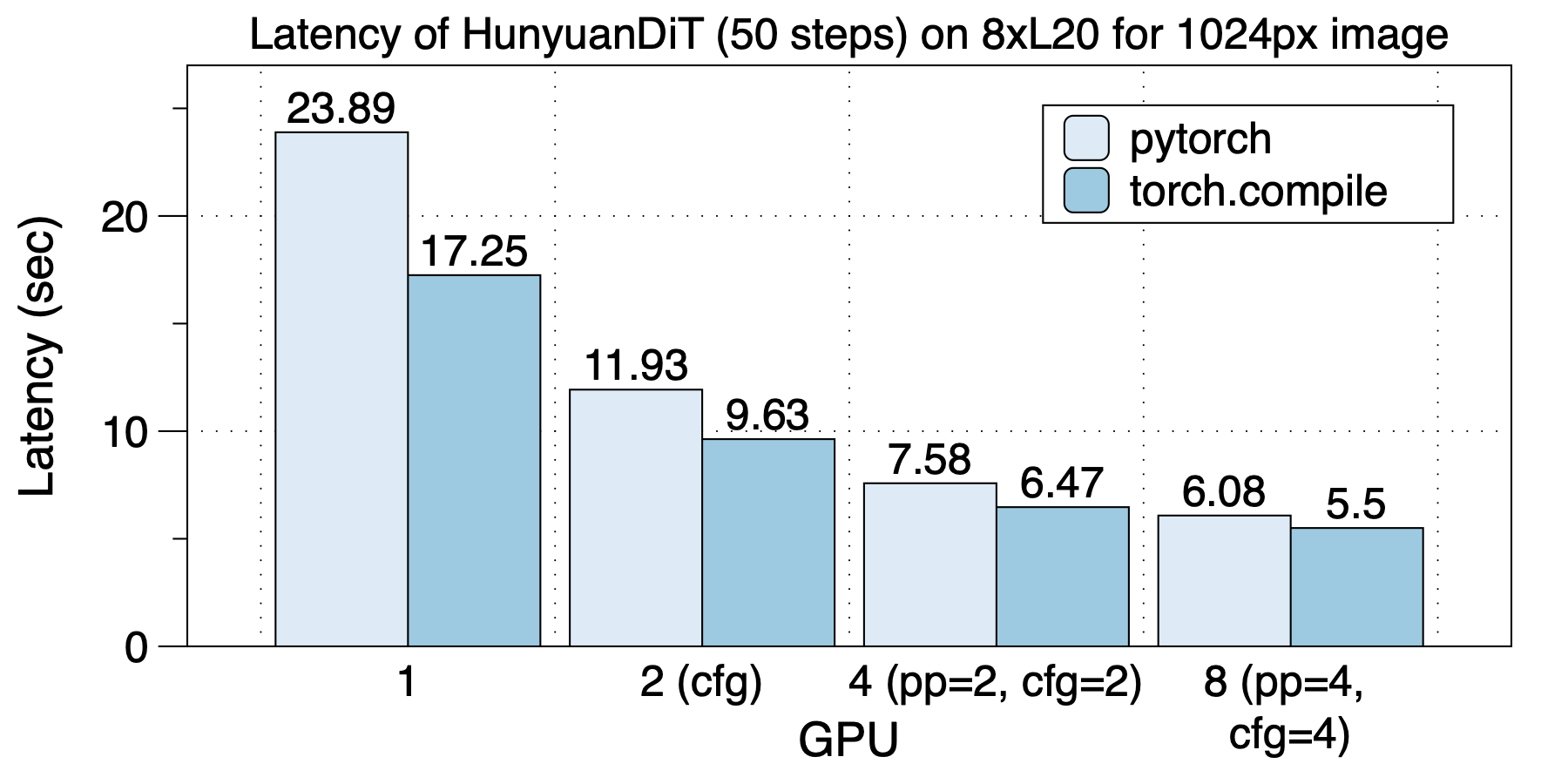
The latency situation on 8xL20 (PCIe) is shown in the figure below. The FP16 FLOPS of L20 is 119.5 TFLOPS, compared to 181.05 TFLOPS for L40. However, on 8 GPUs, L20 actually achieves lower latency compared to L40.
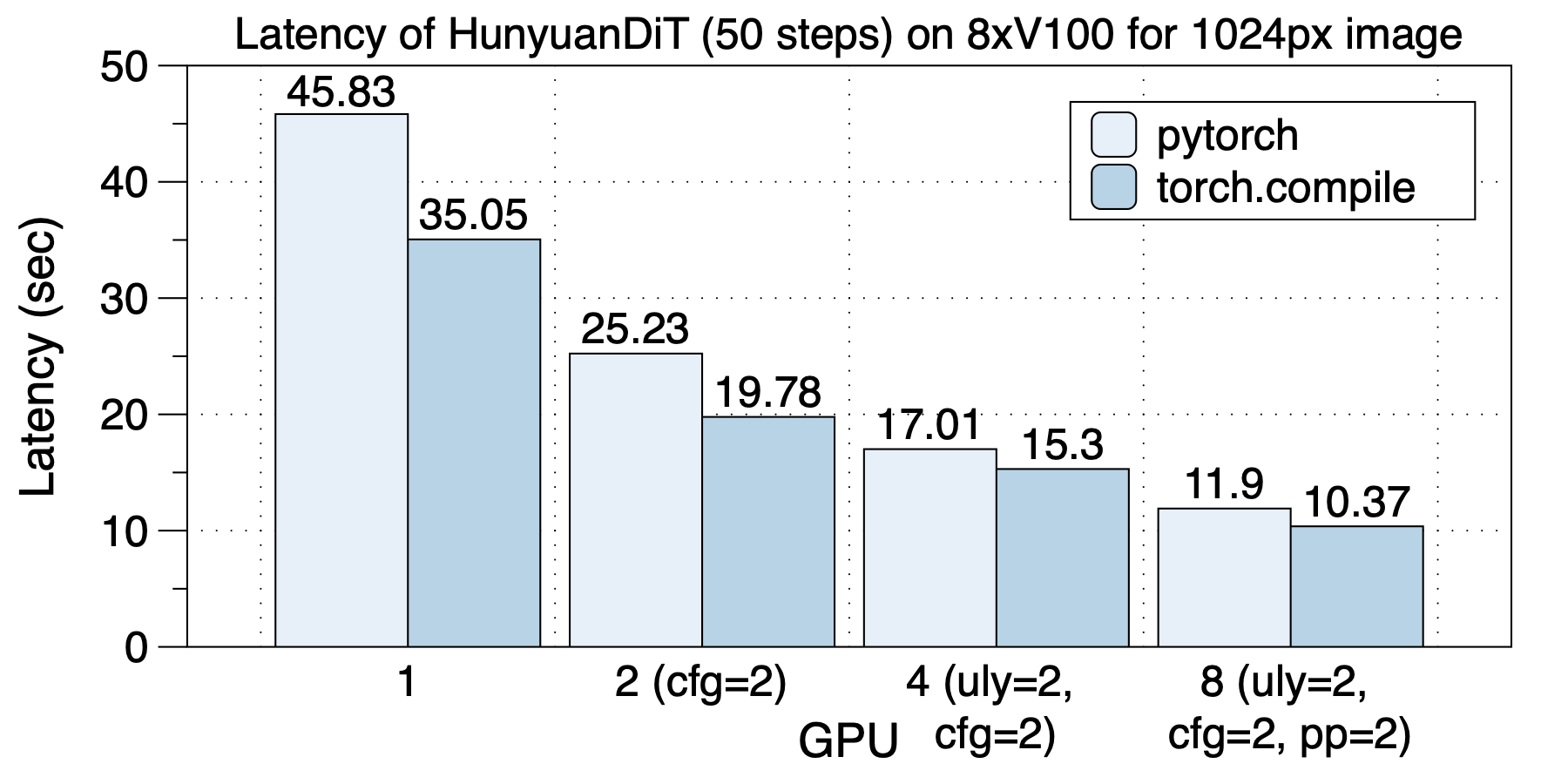
The acceleration on 8xV100 is shown in the figure below.
torch.compile offers a speedup ranging from 1.10x to 1.30x.
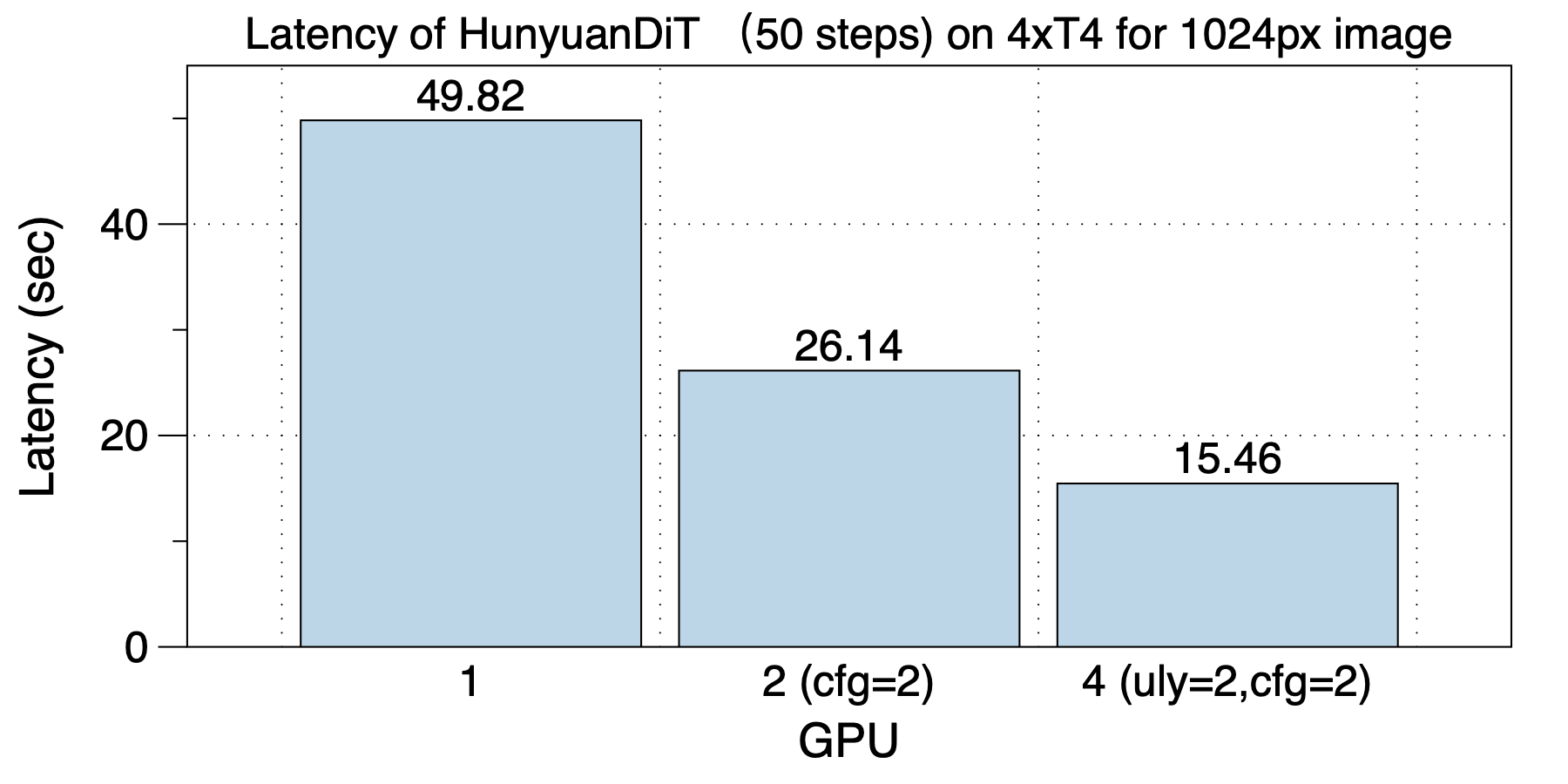
The acceleration on 4xT4 is shown in the figure below.