The is="" attribute is confusing? Maybe we should encourage only ES6 class-based extension. #509
Comments
|
This was previously discussed at length in the other bug tracker, and it's explained in the spec in the sentence above that:
|
|
@domenic That quote that you referred to makes me think exactly the same thing as I just wrote:
You're pointing to something that exists in a spec, but I'm saying it doesn't have to be that way, specs can be modified. There is a solution (I don't know what that solution is specifically yet, but I know that the hardware on any computer that runs a browser nowadays isn't a limitation, and the only limitation is in the software we write, which can be modified). I simply can't understand why an HTML engine must need I wish I had the time and resources to read the Chromium source in order to point to an actual solution (someone else can write the spec, as I'm not even good at reading those), but in the meantime, I'm 100% sure a backwards-compatible programmatic solution exists. |
|
Yes, everything is Turing machines and everything can be implemented. However, there are real-world constraints---both in implementation complexity and in ecosystem impact---that make it not desirable. |
|
Some things are complex to implement, but this particular change doesn't seem to be. :] Would you mind kindly pointing to the complexity and impact that make it non-desirable? Is it because if the element isn't registered (i.e. with JS turned off) that the browser won't know to at least render a fallback What other reason might there be? |
|
When someone who comes from React tries to learn Custom Elements for the first time (which is more likely to happen than someone learning Custom Elements first due to the mere fact that specs are hard to read compared to things like React docs, unfortunately, because specs are meant for implementers, and the actual usage docs if any are sometimes limited or hard to find), they'll face these weird things like the redundant This is what classes are for, and in the case of the HTML engine where multiple types of elements may share the same interface (which is probably a partial cause to any current problems) the third argument to I'd take this further and propose that every single built in element should have a single unique associated class, and therefore ES2015 class extension would be the only required form of extension definition. Just in case, let me point out we must currently specify an extension three whole times. For example, to extend a button: class MyButton extends HTMLButtonElement {} // 1
customElements.define('my-button', MyButton, { extends: 'button' }) // 2<button is="my-button"></button> <!-- 3 -->That's three times we've needed to specify that we're extending something, just to extend one thing. Doesn't this strike you as a bad idea from an end-user perspective? It should ideally just be this, assuming that there is a one-to-one relationship between built-in elements and JS classes: class MyButton extends HTMLButtonElement {} // 1
customElements.define('my-button', MyButton)<my-button></my-button>I get what you're saying about complexities and real-world world constraints, but I think "breaking the web" might actually fix the web in the long run. There can be an API cleansing, and websites may have to specify that the new breaking-API is to be used by supplying an HTTP header. Previous behavior can be supported for a matter of years and finally dropped, the new API becoming default at that time. Sites that don't update within a matter of years probably aren't cared for anyways. I'm just arguing for a better web overall, and breaking changes are sometimes necessary. It seems I may be arguing for this forever though. Unless I am an employee at a browser vendor, I'm not sure my end-user viewpoints matter much. The least I can do is share them. |
|
The problem here is that UA internally checks local name e.g. Now I'm going to re-iterate that Apple objects to extending subclasses of |
I think that relying on element tag names might be a bad idea, especially if we give users ability to scope elements on a per-shadow-root basis (now that's a good idea!). If we can allow end users of a custom element to assign any name they wish to that custom element used within the user's component (within the user's component's inner shadow tree), then we can avoid the global mess that In React (by contrast) the creator of a component never decides what the name of that component will be in the end user's inner tree. The end user has full control over the name of an imported component thanks to ES6 Modules. We can encourage a similar concept by introducing a per-shadow-root custom element registration feature. If we can map names to classes without collision and without two names assigned to the same class (i.e. without elements like This API is still v0 in practice, so I think there's room for modification even if v1 is on the verge of coming out.
I think Webkit not implementing If we continue with globally registered elements, it will be inevitable that some two components in an app will have a name collision, and that the developer of that app will attempt to fix the problem by modifying the source of one custom element (possibly requiring forking of an NPM module, pushing to a new git repo, publishing a new module, etc, time consuming things) just to change the name of that element; it'd be a pain and can introduce unexpected errors if parts of the modified code are relying on the old tag names. TLDR, if we put more care into the JavaScript aspects of an element (f.e. choosing which class represents an element, which is already happening in v1) then we'll have a more solid Web Component design, and we can drop |
|
@domenic Can you describe the "ecosystem impact" that you might know of? |
|
I am referring to the various tools which key on local name, including JavaScript frameworks, HTML preprocessors and postprocessors, HTML conformance checkers, and so on. |
|
I think I know what you mean. For example, search engines read the tag names from the markup in order to detect what type of content and how to render it in the search results. This point may be moot because today it completely possible to use a root <html>
<head>
<title>foo</title>
</head>
<body>
<app></app>
</body>
</html>That's functionally equivalent to an app with no shadow roots and made entirely of randomly named elements: <html>
<head>
<title>foo</title>
</head>
<body>
<asf>
<oiur>
...
</oiur>
<urvcc>
...
</urvcc>
</asf>
</body>
</html>Based on that, I don't think it's necessary to keep element names. I imagine a couple remedies:
|
|
Remedy 1 is what we have consensus on. |
|
I'll note that we've vocally and repeatedly objected to having |
|
It’s important to note that a lot of elements are implemented partially (or completely) with CSS. So, in order to support this and allow user agents to continue to implement elements like they do today, a new CSS pseudo-class would be needed: |
Not really. The point of the |
|
@chaals right. You would need the pseudo-class if using a custom element that extends a native button could be done like |
|
Also, like @trusktr said, if this and whatwg/html#896 become a thing, I think it’ll be possible to remove altogether the Offering this as an alternative to the current way of defining extending native elements — allowing user agent developers and authors to choose which they want to use — is the best solution in my opinion. As @trusktr said, “I think ‘breaking the web’ might actually fix the web in the long run”. |
|
(@Zambonifofex it's generally not clear to me what you mean when you say "this", which makes it hard to engage)
I've tried breaking the Web, at the turn of the century when it was smaller, to do something that would have been really useful. It failed. For pretty much the reasons given by people who say "you can't break the web". Although user agent developers are less reluctant to break things than they were a decade ago, they're still very reluctant, and I believe with very good reason. I think a strategy reliant on breaking the Web to fix it is generally a non-starter, even if the alternatives are far more painful. |
|
For what it's worth, I agree with @rniwa's characterisation - we have an agreement that we won't write |
When I say “this” I mean “this issue”; the suggestion made by @trusktr in the first comment of this thread. But, honestly, — not that I’d be able to know, as I’ve never touched any browser’s code — I think that this would be a much easier change to make for user agent developers than you guys are making it out to be. |
|
I mean, sure, it could be slightly annoying to go and change all of the checks for the tag name to something else, but would it be actually hard? |
|
The <my-el></my-el>class MyEl extends HTMLElement { /*... */ }
MyEl.extends = 'div'
document.registerElement('my-el', MyEl)
// ...
document.querySelector('my-el') instanceof MyEl // true or false? |
|
That API does not reflect the current custom elements API. |
|
We should make the result of <my-el></my-el>class MyEl extends HTMLDivElement { /*... */ }
customElements.define('my-el', MyEl)
// ...
document.querySelector('my-el') instanceof MyEl // true! |
|
I forgot this line too, in the previous comment: document.querySelector('my-el') instanceof HTMLDivElement // also true! |
|
(@domenic I'm still using v0 in Chrome) |
I think you meant "instance" instead of "intense"? This seems to be the reason why I am against both of those methods of defining extension, as I believe encouraging ES6 Classes as the the tool for defining extension will reduce room for confusion. |
|
Perhaps existing native elements should be re-worked so that any differences they have should rather be described (explained) by using class extension, and not using those other two methods ( |
|
@trusktr the idea is not terrible but it raised a few concerns:
My last points regard the fact that However, this last point is more about a polyfill limitation, not exactly how behaviors should be defined by specs. P.S. this is exactly what wickedElements has been for years, except the definition is via CSS selector, not specific attribute P.S.2 ... imho, |
|
@trusktr more concerns while quickly implementing an alternative/proposal to experiment with:
Thanks for clarifications. edit This is how I see this API proposal more useful, all optional except the target: class CustomBehavior {
get target() {
// the element associated with this behavior: read-only
// returns `null` after `detachedCallback` happens
}
// same as CE ... all optional
static get observedAttributes() { return []; }
attachedCallback() {
// as opposite of constructor, unless there's a destructor
// invoked once like a constructor would be
// `this.target` is already available (even if it was a constructor)
}
attributeChangedCallback(name, oldValue, newValue) {
// invoked surely after attachedCallback/constructor
// if the attribute is one of the observed one
}
connectedCallback() {
// invoked surely after attributeChangedCallback the very first time if live
// invoked every time the element goes live again
}
disconnectedCallback() {
// invoked only if the element goes offline
// NOT INVOKED if the behavior is removed
}
detachedCallback() {
// or either we have destructor, in case we have a constructor
// invoked once and `this.target` will returns `null` right after
// the behavior is "dead" at the end of this callback, and if
// its name will be added back, a new instance will be used
}
}With such base class all behaviors can extend it and inherits This allows behaviors to initialize their listeners when attached, and cleanup once detached, but these operations are not necessarily bound with the element live state, simplifying setup/teardown per each behavior, less unexpected when All names are subject to changes, but I think this proposal would be much cleaner than your one, and simply because, differently from Custom Elements, behaviors can be added and removed at runtime, while custom elements are forever, and strictly bound with the element these represent. I hope this sounds better to you too. P.S. alternatively, class CustomBehavior {
get target() {}
}
customBehaviors.define('foo', class extends CustomBehavior {
static get observedAttributes() { return ['any']; }
constructor() {
setup(this.target);
}
attributeChangedCallback(name, oldValue, newValue) {}
connectedCallback() {}
disconnectedCallback(detached = false) {
if (detached)
teardown(this.target);
}
}); |
Now sure what you mean by that. Are you talking about There's only one issue with the
True. I see the ambiguity there. A developer should be responsible about knowing what their class does though...
True. If it were to become a spec'd feature, that could be changed to be sync during parse like with CEs.
That can't happen. If an element is disconnected already, connectedCallback will not be called. The sequence can only ever be
That's also an interesting approach. In some ways it is like jQuery (instantiating plugins via selectors).
I thought about that, but there's no already-existing built-in behaviors, so they aren't really "custom".
I thought about this too. Basically it's more like a "when do I clean up?". Rather than having, for example, two separate methods, I just think of it this way: if an element is removed from the live DOM, or if the behavior is removed from an element, then effectively the behavior is disconnected from live DOM. The behaviors (currently) can not be moved from one element to another. So even after being disconnected from DOM, Also, not sure we'd want the behavior to still be "connected", because if it isn't in the DOM, it really shouldn't do anything (it should be cleaned up, just like the element was.
Same thought here: is the behavior connected into the DOM? If so, then it is guaranteed to have been connected to an element, and it should initialize things at that time. The main thoughts are "when to initialize" and "when to cleanup". Could there be a different name for those two methods?
The "destructor" is basically what I was going for. The "cleanup" is not necessarily tied to the element's life cycle exactly. F.e. remove behavior -> behavior cleanup, or remove element -> behavior cleanup. Suppose instead Would this be better? Maybe people would be likely to do things wrong compared to just "initialize" and "cleanup". My inclination is that I will most likely just have both of the disconnect call a third custom What about
Currently if the element is disconnected, the behavior was cleaned up (disconnectedCallback) and so nothing should run (ideally). Not sure if
What do you mean? Does trashing layout mean getting rid of a subtree? If so, then all behaviors would have
Do you mean with Or do you mean behaviors on elements that are inside a EDIT: I just did a test, and it appears if elements are in a
It just creates a new one currently. Actually exposing But perhaps that should be read-only, and perhaps the only way to add/remove them imperatively would be something like Otherwise, if a user instantiates them manually, we couldn't guarantee that they pass in the element instance to the constructor (relating to the I'll circle back to modifying element-behaviors to fix that part regarding Another idea regarding
I'm not sure. There's something nice about the simple initialize vs cleanup. The user need not worry about if the element still is in the DOM or not. The behavior just does what it does when it needs to, otherwise it is cleaned up and gone. Also is "attached" vs "connected" naming clear? Both terms have been used to describe when elements are connected to the DOM. I do agree the new suggestion would allow more flexibility of some sorts (partial clean up rather than full cleanups). Is it worth the extra methods? What may we want to do with the extra methods (that would be worth it) that we can't do with only two methods regardless of name? With four methods, I would imagine some people just doing this: class MyBehavior {
connectedCallback() {
this.initialize()
}
attachedCallback() {
this.initialize()
}
initialized = false
initialize() {
if (this.initialized) return
this.initialized = true
// initialize stuff.
}
disconnectedCallback() {
this.cleanup()
}
detachedCallback() {
this.cleanup()
}
cleanup() {
if (!this.initialized) return
this.initialized = false
// cleanup stuff.
}
}I think most of the time I would just want to initialize things, it will run for a while, then finally cleanup. I think that I like the two-methods better still. But I'm not clear on if I'd actually want to do something different with the four method that merely forwarding to initialize/cleanup. I think I like the idea of "the behavior is connected or disconnected from the DOM", regardless of whether it happened with the element or not. In this form, the user does have a guarantee:
That might be more confusing. I think four methods would be cleaner if it went that direction.
Wondering what are some compelling use cases for it. |
My concern is about trapping the argument/leaking it, while a read-only property that returns
I think a base class to extend is more elegant and future proof (in case we want to add behavior features, all extenders will benefit).
The MO schedules records, so the sequence of events will be guaranteed, but being asynchronous, if you quick append and remove an element before the MO callback triggers, you have a Nothing we can do though, let's not focus much on this, but it'll be a caveat of the polyfill.
Yeah, I've realized I can simulate most of this via
Fair enough.
Not in my implementation.
It's veeeeeeery verbose ... let's think about it.
My implementation drops the MO once detached, nothing works anymore, behavior dead.
Cool, I like that.
Yeah, I think leaking behaviors around is not great indeed.
My implementation sets it as getter and uses a WeakMap pre-populated per behavior <-> node. It works out of the box in constructor too.
For behaviors: yes, which is why connected/disconnected are not a good place to do so.
DOM diffing. You have a list of things and you filter things as you type, as example, and nodes get off/on all the time, without changing state, except their presence on the document. Doing listeners dance, or any other, due diffing, looks like extremely undesired overhead. Behaviors are per element, not per element lifecycle, so coupling these strictly with element lifecycle might easily backfire, imho. |
|
@trusktr after thinking about this for a little while, I think the API would be much simpler if it had only ElementObserverThis API proposal consist in being able to use const eo = new ElementObserver((records, eo) => {
for (const {target, type} of records) {
if (type === 'connected') {
// target has been connected
doConnectedThings(target);
}
else {
// target has been disconnected
doDisconnectedThings(target);
}
}
});
const target = document.querySelector('any-dom-element');
eo.observe(target);
if (target.isConnected)
doConnectedThings(target);If the asynchronous nature (easier to polyfill and aligned with MO) is not cool or ideal, the API could instead be like: const eo = new ElementObserver({
connectedCallback(element) {
// do things with element
},
disconnectedCallback(element) {
// do things with element
}
});
eo.observe(anyDOMElement);
// maybe the sync version could trigger
// connectedCallback if the element is already live?With this new mechanism a lot of the arguments around builtin-extends might vanish, because at that point we'll have MutationObserver to mimic This API makes it possible, out of the box, to define behaviors however developers like, but it'll also make it possible to have a simplified API for behaviors, in case we'd like to abuse the // base class
class Behavior {
get target() { /* return the element/target */ }
// a constructor like place to setup once
attachedCallback() {
this.eo = new ElementObserver(callback || literalObserver);
this.eo.observe(this.target);
}
// a destructor like place to teardown once
detachedCallback() {
this.eo.disconnect();
// this.target is null after this call
}
}Doing this way the Behavior doesn't mislead with elements associated callbacks through its prototype, the separation of concerns/responsibilities is clear, there's no confusion, and observing elements lifecycle becomes optional, so that behaviors can be much simpler in intent, scope, and also code. What do you, or anyone else, think about these two possible APIs? Is it worth opening a new issue and discuss any of these in there? Thank you. |
|
P.S. I really like the literal API proposal, because it allows the Behavior class to eventually have those methods and be the argument passed along to const eo = new ElementObserver({
attributeChangedCallback(element, name, oldValue, newValue) {
},
connectedCallback(element) {
// do things with element
},
disconnectedCallback(element) {
// do things with element
}
});
eo.observe(element, {
attributes: true,
attributesFilter: ['only', 'these', 'attributes']
});I think I'll play around a bit with this, also making |
|
@trusktr if interested, ElementObserver is live and working well. |
|
Hey, @trusktr, did you had a chance to look at @WebReflection , the possibility of augmenting standard elements with custom behaviors without a globally shared registry sounds really great, but I still don't see how to bind it to |
|
@andregs customBehaviors.define(
'my-thing',
{
observedAttributes: ['some', 'attribute'],
attributeChangedCallback(element, name, oldValue, newValue) {},
connectedCallback(element) {},
disconnectedCallback(element) {}
}
);The const registry = new Map;
customBehaviors.define = (name, behavior) => {
if (registry.has(name))
throw new Error(`duplicated ${name}`);
const instance = new ElementObserver(behavior);
const options = {
attributes: true,
attributeFilter: behavior.observedAttributes || [],
attributeOldValue: true
};
registry.set(name, {instance, options});
for (const target of document.querySelectorAll(`[has="${name}"]`))
instance.observe(target, options);
};
// a simulation of what should happen at the global level
const mo = new MutationObserver(records => {
for (const {target, attributeName, oldValue} of records) {
if (attributeName === 'has') {
const newBehaviors = (target.getAttribute('has') || '').split(/\s+/);
const oldBhaviors = (oldValue || '').split(/\s+/);
for (const behavior of oldBhaviors) {
if (registry.has(behavior) && !newBehaviors.includes(behavior))
registry.get(behavior).instance.disconnect(target);
}
for (const behavior of newBehaviors) {
if (registry.has(behavior) && !oldBhaviors.includes(behavior)) {
const {instance, options} = registry.get(behavior);
instance.observe(target, options);
}
}
}
}
});
mo.observe(document, {
attributeFilter: ['has'],
subtree: true
});The only possible improvement I can see needed is an |
|
I did some experiments with ElementObserver (https://stackblitz.com/edit/element-observer?devtoolsheight=44&file=index.js) in the spirit of this component and these are my findings:
function messAround() {
console.info('messing with the new one');
const el = document.getElementById('another-counter');
console.info('removing it from dom', el);
el.remove();
console.info('changing its value', el);
counter.inc(el);
counter.dec(el);
counter.dec(el);
console.info('adding it back to dom', el);
document.getElementById('app').append(el);
}
|
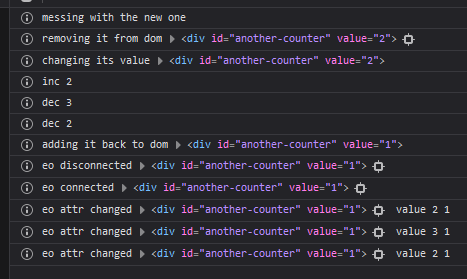
|
I am not sure this thread is the right venue for these kind of conversations ... but here my answers:
it's based on Custom Elements behavior, where
If we use
exactly like MutationObserver works ... you stop observing the element, nothing triggers anymore.
exactly how Custom Elements work. The attributeChangedCallback is always triggered before connectedCallback if an element is upgraded and one of its attributes is observed. Moving away from the current standard lifecycle doesn't look like a good idea, imho.
this is abusing the meaning of connected/disconnected which is, in Custom Elements world, about these elements being upgraded and live on the DOM, or removed. The right place to setup listeners once is the constructors, but here we don't have one, so that
This is how Custom Elements work. The only difference here is that Mutation Observer callbacks are asynchronous and nobody can know upfront if other callbacks were queued/scheduled, without further delaying the reaction. The order is guaranteed to be the correct one though, the sequence is always exactly the one that happened live. However, This is how MutationObserver works, nothing I can do, and a well know tiny caveat of all Custom Elements polyfills to date that are based on the asynchronous nature of the Mutation Observer. Synchroonus DOM mutation events are deprecated for good, and I don't want to over-complicate in my library this dance, as there is no effective way to avoid multiple calls, all I can guarantee is that the sequence is correct (i.e. by triggering removedNodes before addedNodes*). I hope this answered all your findings/questions. |
|
Yes, that clarifies a lot. And I'm sorry if I went off topic, I'm just trying to collaborate since you asked what we think of the APIs. After your explanations I can see I was misusing connected/disconnected callbacks as observed/unobserved callbacks. And, honestly, setup/teardown could be done alongside The beauty of this ElementObserver (or element-behaviors) is that they make it easy to define reusable behaviors that you can apply to standard or custom elements. It's also good that the relationship between elements and behaviors is many-to-many, unlike in That said, I'd only rename Thank you for your attention and hard-work. I'm looking forward to see @trusktr 's opinions too. |
|
@andregs @trusktr after feedback and a post, I've experimented a new approach where mixins/behaviors are handled directly through the |
|
Adding to the pile of reasons to support extending built-in elements, whether it's The Hotwired framework depends on the Except in Safari of course where it doesn't work at all. You can read the PR at hotwired/turbo#131. |
|
I'm realizing how hard it is to write Web Components with ARIA without being able to extend the native elements. For example, I would like to use HTMLButtonElement or HTMLDialogElement, but am forced to use the basic HTMLElement. The alternative is to wrap the intended element inside the WebComponent. But, now that element is now hidden from the regular DOM (HTML writer) meaning it's impossible to set ARIA attributes. For example, if a user wants to add https://github.com/ionic-team/ionic-framework/pull/25156/files Is there really no clean solution to using native elements as fallback, as suggested by WAI-ARIA, and using Web Components? Does Apple have another solution to this problem? For the sake of accessibility, we should A) watch for all ARIA attributes, B) don't use Web Components, or C) ignore the recommendation of using native elements? |
|
ARIA attributes have been added to |
|
@rniwa Thanks for the quick reply. I saw your comment earlier (long thread) about HTMLInputElement and ARIA tags. HTMLInputElement should be self-closing anyway, meaning it's an "impossibility" inherent in custom elements. Replicating attrs is probably the way to go with a feature detection for ElementInternals. And after it is fully implemented, the ARIA attribute list would be ignored anyway (no falling out of spec). |
|
Thank you @rniwa. While we have you, is it still the stance of WebKit to not support this feature? While I too am not a huge fan of the |
Nothing has changed as far as I'm aware. |
|
@rniwa aria attributes are not the only feature difficult to work with due to lack of customized built-ins ( Although I don't like customized built-ins as currently spec'd, I believe that because Safari (you as far as I can tell, because it seemed to have been your choice in particular) led the charge to not implementing customized built-ins, it would be great for Safari (probably you, not because I'm demanding, but because it was seemingly your sole responsibility to choose this path, although I would be happy to hear if I am incorrect) to lead the charge in providing a better and wholesome alternative that allows solving all the the same problems in whole and in a simple (if different) ways ( |
|
So this isn't being implemented for ideological reasons, is that right? After 8 years seems safe to say that
Sorry, but seems to me that anyone seriously suggesting there are "better" methods than simple inheritance hasn't tried implementing any of this stuff in real-world apps of any real complexity. IMHO of course. Regards, |
|
At TPAC 2023, the attendees (browser vendors including WebKit, CG/WG members, community, etc.) agreed to begin working on an alternative that was capable of handling the original use cases plus additional use cases that have been discovered since. There were several proposals discussed during the meeting for which there were already WIP specs and even polyfills. Coming out of that meeting, a new proposal attempted to capture some of the ideas and discussion. Please give it a read and help determine if it will enable your use cases: |
The
is=""API can be confusing, and awkward. For example (in current v1 API):inheritance currently has to be specified three times:
But, I believe it could be better:
inheritance specified once, easier non-awkward API:
But, there's problems that the
is=""attribute solves, like making it easy to specify that a<tr>elementisactually amy-rowelement, without tripping up legacy parser behavior (among other problems). So, after discussing in this issue, I've implemented an idea in #727:See #727 for more details.
Original Post:
The spec says:
But, in my mind, that's just what the spec says, but not that it has to be that way. Why has it been decided for it to be that way?
I believe that we can specify this type of information in the
customElement.define()call rather than in the markup. For example, that very same document shows this example:Obviously,
plastic-buttonextendsbuttonas defined right there in that call todefine(), so why do we need a redundantis=""attribute to be applied ontobutton? I think the following HTML and JavaScript is much nicer:The necessary info for the HTML engine to upgrade that element properly is right there, in
{ extends: "button" }. I do believe there's some way to make this work (as there always is with software, because we make it, it is ours, we make software do what we want, and this is absolutely true without me having to read a single line of browser source code to know it), and thatis=""is not required and can be completely removed from the spec because it seems like a hack to some limitation that can be solved somehow else (I don't know what that "somehow" is specifically, but I do know that the "somehow" exists because there's always some way to modify software to make it behave how we want within the limitations of current hardware where current hardware is not imposing any limitation on this feature).The text was updated successfully, but these errors were encountered: