diff --git a/docs-2.0/nebula-dashboard-ent/4.cluster-operator/operator/version-upgrade.md b/docs-2.0/nebula-dashboard-ent/4.cluster-operator/operator/version-upgrade.md
index 921c4c98578..0339abc6e91 100644
--- a/docs-2.0/nebula-dashboard-ent/4.cluster-operator/operator/version-upgrade.md
+++ b/docs-2.0/nebula-dashboard-ent/4.cluster-operator/operator/version-upgrade.md
@@ -10,7 +10,7 @@ NebulaGraph Dashboard Enterprise Edition supports upgrading the version of the e
!!! note
- - Only supports upgrading the NebulaGraph cluster that version greater than **3.0.0** to the version equal to or lower than **3.2.1**. To upgrade to **3.3.0**, see [manual upgrade](../../..//4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md).
+ - Only supports upgrading the NebulaGraph cluster that version greater than **3.0.0** to the version equal to or lower than **3.2.1**. To upgrade to **3.3.0**, see [manual upgrade](../../../4.deployment-and-installation/3.upgrade-nebula-graph/upgrade-nebula-from-300-to-latest.md).
- Do not support upgrading clusters across the major version.
- The community edition can be upgraded to the enterprise edition by uploading and verifying licenses, and the enterprise edition can be upgraded to the community edition.
- The cluster can be upgraded to a minor version in the current major version, including a smaller version than the current minor version.
diff --git a/docs-2.0/nebula-explorer/workflow/1.prepare-resources.md b/docs-2.0/nebula-explorer/workflow/1.prepare-resources.md
index 275d772d1cc..ad4acddf8d5 100644
--- a/docs-2.0/nebula-explorer/workflow/1.prepare-resources.md
+++ b/docs-2.0/nebula-explorer/workflow/1.prepare-resources.md
@@ -1,6 +1,6 @@
# Prepare resources
-You must prepare your environment for running a workflow, including NebulaGraph configurations, HDFS configurations, and NebulaGraph Analytics configurations.
+You must prepare your environment for running a workflow, including NebulaGraph configurations, DAG configurations, NebulaGraph Analytics configurations and HDFS configurations.
## Prerequisites
@@ -12,16 +12,43 @@ You must prepare your environment for running a workflow, including NebulaGraph
1. At the top of the Explorer page, click **Workflow**.
-2. In the **Workflows** tab, click **Configuration**.
+2. Click **Workflow Configuration** in the upper right corner of the page.
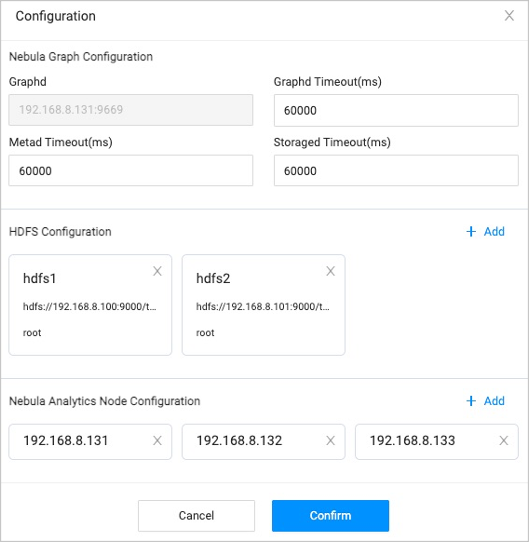
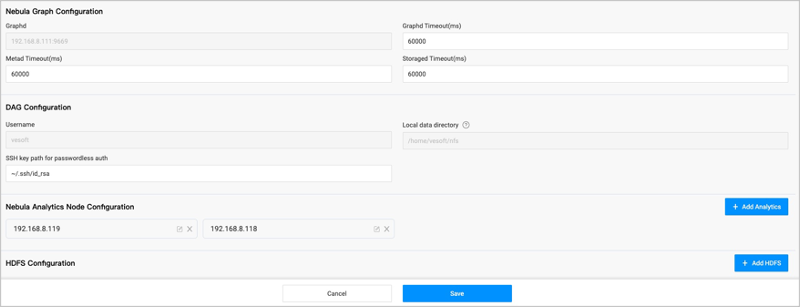
-3. Configure the following resources:
+3. Configure the following resources.
- 
+ 
- |Type|Description|
- |:--|:--|
- |NebulaGraph Configuration| The access address of the graph service that executes a graph query or to which the graph computing result is written. The default address is the address that you use to log into Explorer and can not be changed. You can set timeout periods for three services. |
- |HDFS Configuration| The HDFS address that stores the result of the graph query or graph computing. Click **Add** to add a new address, you can set the HDFS name, HDFS path (`fs.defaultFS`), and HDFS username. You can configure the save path, such as `hdfs://192.168.8.100:9000/test`. The configuration takes effect only after the HDFS client is installed on the machine where the Analytics is installed. |
- |NebulaGraph Analytics Configuration| The NebulaGraph Analytics address that performs the graph computing. Click **Add** to add a new address.|
+ - NebulaGraph configuration
-4. Click **Confirm**.
+ The access address of the graph service that executes a graph query or to which the graph computing result is written. The default address is the address that you use to log into Explorer and can not be changed. You can set timeout periods for three services.
+
+ - DAG configuration
+
+ The configuration of the Dag Controller for the graph computing.
+
+ - Username: Fixed to `vesoft` and does not need to be changed.
+ - Local data directory: The Analytics data directory, the shared directory of NFS service. By default, the workflow uses NFS to store the graph computing results, but the user needs to install NFS and mount the directory manually.
+ - SSH key path for passwordless auth: The path to the private key file of the machine where Dag Controller is located. It is used for SSH-free login between machines.
+
+ - NebulaGraph Analytics configuration
+
+ Add the address of the NebulaGraph Analytics where the graph computing will be performed.
+
+ - Nebula Analytics Node IP address: fill in the new Analytics node IP address.
+ - Username: Default is `vesoft` and does not need to be changed.
+ - SSH port number: Default is `22`.
+ - SSH key path for passwordless auth: Used for SSH-free login between machines. Default is `~/.ssh/id_rsa`.
+ - Local data directory: Default is `~/analytics-data`.
+ - ALGORITHM script path: Default is `~/nebula-analytics/scripts/run_algo.sh`.
+
+ - HDFS configuration (Optional)
+
+ By default, NFS is used to save the graph computing results. If you need to use HDFS, please install the HDFS client on the machine where Analytics is located first.
+
+ - HDFS name: Fill in the name of HDFS configuration, it is convenient to distinguish different HDFS configurations.
+ - HDFS path: The `fs.defaultFS` configuration in HDFS. Support configure the save path, such as `hdfs://192.168.8.100:9000/test`.
+ - HDFS username: The name of the user using HDFS.
+
+4. Click **Save**.
+
+5. Click **Configuration Check** in the upper right corner and click **Start Check** to check if the configuration is working.
diff --git a/docs-2.0/nebula-explorer/workflow/2.create-workflow.md b/docs-2.0/nebula-explorer/workflow/2.create-workflow.md
index d4bc7d759fd..218e28343d8 100644
--- a/docs-2.0/nebula-explorer/workflow/2.create-workflow.md
+++ b/docs-2.0/nebula-explorer/workflow/2.create-workflow.md
@@ -4,7 +4,7 @@ This topic describes how to create a simple workflow.
## Prerequisites
-- The data source is ready. The data source can be data in NebulaGraph or CSV files on HDFS.
+- The data source is ready. The data source can be data in NebulaGraph or CSV files on NFS/HDFS.
- The [resource](1.prepare-resources.md) has been configured.
@@ -26,7 +26,7 @@ With the result of the MATCH statement `MATCH (v1:player)--(v2) RETURN id(v1),
|Input| Set custom parameters that can be used for parameterized query. Click **Add parameter** to add more custom parameters. |
|Query language| Select the graph space to execute the nGQL statement and fill in the nGQL statement. Click **Parse Parameter** to display the returned column name in the **Output**.|
|Output| The column name returned by parsing the query language. You can change the name, which is equivalent to aliasing the column with `AS`.|
- |Results| Set the saving project of the result. To call the results expediently for other algorithms, the results of the graph query component can only be saved in the HDFS.|
+ |Results| Set the saving project of the result. To call the results expediently for other algorithms, the results of the graph query component can be saved in the NFS or HDFS.|
!!! note
@@ -42,16 +42,16 @@ With the result of the MATCH statement `MATCH (v1:player)--(v2) RETURN id(v1),
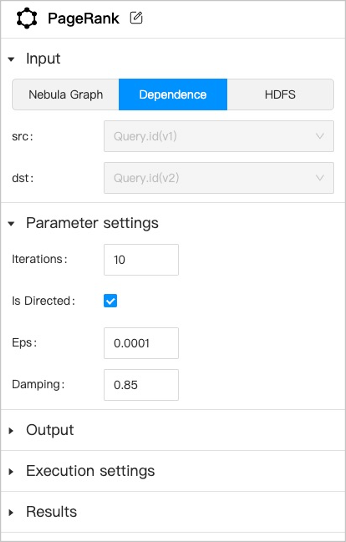
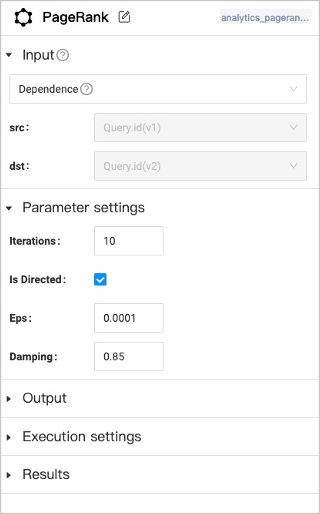
5. Click the graph computing component and set the following parameters in the configuration panel on the right side.
- 
+ 
|Parameters|Description|
|:---|:---|
|PageRank|Click  to modify the component name to identify the component.|
- |Input| Three data sources are supported as input.
**NebulaGraph**: Users must select one graph space and corresponding edge types.
**Dependence**: The system will automatically recognize the data source according to the connection of the anchor.
**HDFS**: Users must select HDFS and fill in the relative path of the data source file.|
+ |Input| Multiple data sources are supported as input.
**NebulaGraph**: Users must select one graph space and corresponding edge types.
**Dependence**: The system will automatically recognize the data source according to the connection of the anchor.
**HDFS**: Users must select HDFS and fill in the relative path of the data source file.
**Local**: Users must fill in the relative path of the data source file.|
|Parameter settings| Set the parameters of the graph algorithm. The parameters of different algorithms are different. Some parameters can be obtained from any upstream component where the anchor are shown in yellow.|
|Output| Display the column name of the graph computing results. The name can not be modified.|
|Execution settings| **Machine num**: The number of machines executing the algorithm.
**Processes**: The total number of processes executing the algorithm. Allocate these processes equally to each machine based on the number of machines.
**Threads**: How many threads are started per process.|
- |Results| Set the restoration path of the results in HDFS or NebulaGraph.
**HDFS**: The save path is automatically generated based on the job and task ID.
**NebulaGraph**: Tags need to be created beforehand in the corresponding graph space to store the results. For more information about the properties of the tag, see [Algorithm overview](../../graph-computing/algorithm-description.md).
Some algorithms can only be saved in the HDFS.|
+ |Results| Set the restoration path of the results in NFS, HDFS or NebulaGraph.
**Local**: The save path is automatically generated based on the job and task ID.
**HDFS**: The save path is automatically generated based on the job and task ID.
**NebulaGraph**: Tags need to be created beforehand in the corresponding graph space to store the results. For more information about the properties of the tag, see [Algorithm overview](../../graph-computing/algorithm-description.md).
Some algorithms can only be saved in the HDFS.|
6. Click  next to the automatically generated workflow name at the upper left corner of the canvas page to modify the workflow name, and click **Run** at the upper right corner of the canvas page. The job page is automatically displayed to show the job progress. You can view the result after the job is completed. For details, see [Job management](4.jobs-management.md).
diff --git a/docs-2.0/nebula-explorer/workflow/workflows.md b/docs-2.0/nebula-explorer/workflow/workflows.md
index 8d7db35131f..b01be223f1e 100644
--- a/docs-2.0/nebula-explorer/workflow/workflows.md
+++ b/docs-2.0/nebula-explorer/workflow/workflows.md
@@ -25,14 +25,14 @@ Instantiate the workflow when performing graph computing. The instantiated compo
- The input to the graph query component can only be the nGQL.
-- The results of a graph query component can only be stored in the HDFS, which is convenient to be called by multiple algorithms.
+- The results of a graph query component can be stored in the NFS by default and also in HDFS, which is convenient to be called by multiple algorithms.
-- The input to the graph computing component can be the specified data in the NebulaGraph or HDFS, or can depend on the results of the graph query component.
+- The input to the graph computing component can be the specified data in the NebulaGraph, NFS or HDFS, or can depend on the results of the graph query component.
If an input depends on the results of the previous graph query component, the graph computing component must be fully connected to the graph query component, that is, the white output anchors of the previous graph query component are all connected to the white input anchors of the graph compute component.
- The parameters of some algorithms can also depend on the upstream components.
-- The result of the graph computing components can be stored in the NebulaGraph or HDFS, but not all algorithm results are suitable to be stored in NebulaGraph. Some algorithms can only be saved in HDFS when configuring the save results page.
+- The result of the graph computing components can be stored in the NebulaGraph, NFS or HDFS, but not all algorithm results are suitable to be stored in NebulaGraph. Some algorithms can only be saved in NFS or HDFS when configuring the save results page.
## Algorithm description