diff --git a/.github/workflows/deploy.yaml b/.github/workflows/deploy.yaml
index b964cce2730..cc5c4b1df70 100644
--- a/.github/workflows/deploy.yaml
+++ b/.github/workflows/deploy.yaml
@@ -10,7 +10,7 @@ jobs:
steps:
- uses: actions/checkout@v2
with:
- fetch-depth: 0 # fetch all commits/branches
+ fetch-depth: 1 # fetch all commits/branches
- name: Setup Python
uses: actions/setup-python@v1
diff --git a/README.md b/README.md
index 73300bbcdb7..82b3f366a4f 100644
--- a/README.md
+++ b/README.md
@@ -1,10 +1,17 @@
[](https://github.com/vesoft-inc/nebula-docs-cn/actions/workflows/deploy.yaml)
-# NebulaGraph 文档
+# {{nebula.name}} 文档
+{{ ent.ent_begin }}
- [中文](https://docs.nebula-graph.com.cn/)
- [English](https://docs.nebula-graph.io)
+{{ ent.ent_end }}
+
+{{ comm.comm_begin }}
+- [中文](https://docs.nebula-graph.com.cn/)
+- [English](https://docs.nebula-graph.io)
+{{ comm.comm_end }}
## 贡献文档
-如果发现文档问题,请随时创建一个 [Issue](https://github.com/vesoft-inc/nebula-docs-cn/issues) 告知我们或直接创建一个 [PR](https://github.com/vesoft-inc/nebula-docs-cn/pulls) 修复或更新。请参阅 NebulaGraph [中文文档贡献指南](CONTRIBUTING.md)开始贡献。
+如果发现文档问题,请随时创建一个 [Issue](https://github.com/vesoft-inc/nebula-docs-cn/issues) 告知我们或直接创建一个 [PR](https://github.com/vesoft-inc/nebula-docs-cn/pulls) 修复或更新。请参阅{{nebula.name}} [中文文档贡献指南](CONTRIBUTING.md)开始贡献。
diff --git a/docs-2.0/1.introduction/0-0-graph.md b/docs-2.0/1.introduction/0-0-graph.md
index 56ccfdf45b9..49fc2c8b9dc 100644
--- a/docs-2.0/1.introduction/0-0-graph.md
+++ b/docs-2.0/1.introduction/0-0-graph.md
@@ -14,7 +14,7 @@
## 图、图片与图论
-图无处不在。当听到图这个词时,很多人都会想到条形图或折线图,因为有时候我们确实会把它们称作图。从传统意义上来说,图是用来展示两个或多个数据系统之间的联系的。最简单的例子如下图,下图展示了 NebulaGraph GitHub 仓库星星数量随时间推移的变化。
+图无处不在。当听到图这个词时,很多人都会想到条形图或折线图,因为有时候我们确实会把它们称作图。从传统意义上来说,图是用来展示两个或多个数据系统之间的联系的。最简单的例子如下图,下图展示了{{nebula.name}} GitHub 仓库星星数量随时间推移的变化。

diff --git a/docs-2.0/1.introduction/0-1-graph-database.md b/docs-2.0/1.introduction/0-1-graph-database.md
index 3cff5aaa2c1..589f7bbb60c 100644
--- a/docs-2.0/1.introduction/0-1-graph-database.md
+++ b/docs-2.0/1.introduction/0-1-graph-database.md
@@ -153,7 +153,7 @@ Cypher 启发了一系列后续的图查询语言,包括
[^GSQL]: https://docs.tigergraph.com/dev/gsql-ref
-2019 年,NebulaGraph 以 openCypher 为基础发布其扩展的图语言 NebulaGraph Query Language, nGQL。
+2019 年,{{nebula.name}}以 openCypher 为基础发布其扩展的图语言 NebulaGraph Query Language, nGQL。

@@ -240,6 +240,6 @@ Oracle graph[^Oracle] 是关系型数据库巨头 Oracle 在图技术与图数
[^Oracle]: https://www.oracle.com/database/graph/
-#### 新一代开源分布式图数据库 NebulaGraph
+#### 新一代开源分布式图数据库{{nebula.name}}
-在下一章,我们将正式介绍新一代开源分布式图数据库 NebulaGraph。
+在下一章,我们将正式介绍新一代开源分布式图数据库{{nebula.name}}。
diff --git a/docs-2.0/1.introduction/0-2.relates.md b/docs-2.0/1.introduction/0-2.relates.md
index d00a0c60e51..5e32d96434a 100644
--- a/docs-2.0/1.introduction/0-2.relates.md
+++ b/docs-2.0/1.introduction/0-2.relates.md
@@ -55,7 +55,7 @@ NoSQL 数据库的列式存储与 NoSQL 数据库的键值存储有许多相似
#### 图存储
-最后一类 NoSQL 数据库是图数据库。本书重点讨论的 NebulaGraph 也是一种图数据库。虽然同为 NoSQL 型数据库,但是图数据库与上述 NoSQL 数据库有本质上的差异。图数据库以点、边、属性的形式存储数据。其优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。我们将在随后的章节中详细讨论图数据库。不过在本章中,你只要知道图数据库是一种 NoSQL 类型的数据库就可以了。常见的图数据库有:NebulaGraph、Neo4j、OrientDB 等。
+最后一类 NoSQL 数据库是图数据库。本书重点讨论的{{nebula.name}}也是一种图数据库。虽然同为 NoSQL 型数据库,但是图数据库与上述 NoSQL 数据库有本质上的差异。图数据库以点、边、属性的形式存储数据。其优点在于灵活性高,支持复杂的图形算法,可用于构建复杂的关系图谱。我们将在随后的章节中详细讨论图数据库。不过在本章中,你只要知道图数据库是一种 NoSQL 类型的数据库就可以了。常见的图数据库有:{{nebula.name}}、Neo4j、OrientDB 等。
## 图技术方面
diff --git a/docs-2.0/1.introduction/1.what-is-nebula-graph.md b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
index f8848dcb1e4..f544d1d932b 100644
--- a/docs-2.0/1.introduction/1.what-is-nebula-graph.md
+++ b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
@@ -1,8 +1,8 @@
-# 什么是 NebulaGraph
+# 什么是{{nebula.name}}
-NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
+{{nebula.name}}是一款开源的、分布式的、易扩展的原生图数据库,能够承载包含数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。
-
+
## 什么是图数据库
@@ -12,78 +12,79 @@ NebulaGraph 是一款开源的、分布式的、易扩展的原生图数据库
图数据库适合存储大多数从现实抽象出的数据类型。世界上几乎所有领域的事物都有内在联系,像关系型数据库这样的建模系统会提取实体之间的关系,并将关系单独存储到表和列中,而实体的类型和属性存储在其他列甚至其他表中,这使得数据管理费时费力。
-NebulaGraph 作为一个典型的图数据库,可以将丰富的关系通过边及其类型和属性自然地呈现。
+{{nebula.name}}作为一个典型的图数据库,可以将丰富的关系通过边及其类型和属性自然地呈现。
-## NebulaGraph 的优势
+## {{nebula.name}}的优势
+{{ comm.comm_begin }}
### 开源
-NebulaGraph 是在 Apache 2.0 条款下开发的。越来越多的人,如数据库开发人员、数据科学家、安全专家、算法工程师,都参与到 NebulaGraph 的设计和开发中来,欢迎访问 [NebulaGraph GitHub 主页](https://github.com/vesoft-inc/nebula)参与开源项目。
+{{nebula.name}}是在 Apache 2.0 条款下开发的。越来越多的人,如数据库开发人员、数据科学家、安全专家、算法工程师,都参与到{{nebula.name}}的设计和开发中来,欢迎访问 [{{nebula.name}} GitHub 主页](https://github.com/vesoft-inc/nebula)参与开源项目。
+{{ comm.comm_end }}
### 高性能
-基于图数据库的特性使用 C++ 编写的 NebulaGraph,可以提供毫秒级查询。众多数据库中,NebulaGraph 在图数据服务领域展现了卓越的性能,数据规模越大,NebulaGraph 优势就越大。详情请参见 [NebulaGraph benchmarking 页面](https://discuss.nebula-graph.com.cn/t/topic/11727)。
+基于图数据库的特性使用 C++ 编写的{{nebula.name}},可以提供毫秒级查询。众多数据库中,{{nebula.name}}在图数据服务领域展现了卓越的性能,数据规模越大,{{nebula.name}}优势就越大。详情请参见 [{{nebula.name}} benchmarking 页面](https://discuss.nebula-graph.com.cn/t/topic/11727)。
### 易扩展
-NebulaGraph 采用 shared-nothing 架构,支持在不停止数据库服务的情况下扩缩容。
+{{nebula.name}}采用 shared-nothing 架构,支持在不停止数据库服务的情况下扩缩容。
### 易开发
-NebulaGraph 提供 Java、Python、C++ 和 Go 等流行编程语言的客户端,更多客户端仍在开发中。详情请参见 [NebulaGraph clients](../14.client/1.nebula-client.md)。
+{{nebula.name}}提供 Java、Python、C++ 和 Go 等流行编程语言的客户端,更多客户端仍在开发中。详情请参见 [{{nebula.name}} clients](../14.client/1.nebula-client.md)。
### 高可靠访问控制
-NebulaGraph 支持严格的角色访问控制和 LDAP(Lightweight Directory Access Protocol)等外部认证服务,能够有效提高数据安全性。详情请参见[验证和授权](../7.data-security/1.authentication/1.authentication.md)。
+{{nebula.name}}支持严格的角色访问控制和 LDAP(Lightweight Directory Access Protocol)等外部认证服务,能够有效提高数据安全性。详情请参见[验证和授权](../7.data-security/1.authentication/1.authentication.md)。
### 生态多样化
-NebulaGraph 开放了越来越多的原生工具,例如 [NebulaGraph Studio](https://github.com/vesoft-inc/nebula-studio)、[NebulaGraph Console](https://github.com/vesoft-inc/nebula-console)、[NebulaGraph Exchange](https://github.com/vesoft-inc/nebula-exchange) 等,更多工具可以查看[生态工具概览](../20.appendix/6.eco-tool-version.md)。
+{{nebula.name}}开放了越来越多的原生工具,例如 [NebulaGraph Studio](https://github.com/vesoft-inc/nebula-studio)、[NebulaGraph Console](https://github.com/vesoft-inc/nebula-console)、[NebulaGraph Exchange](https://github.com/vesoft-inc/nebula-exchange) 等,更多工具可以查看[生态工具概览](../20.appendix/6.eco-tool-version.md)。
-此外,NebulaGraph 还具备与 Spark、Flink、HBase 等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
+此外,{{nebula.name}}还具备与 Spark、Flink、HBase 等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
### 兼容 openCypher 查询语言
-NebulaGraph 查询语言,简称为 nGQL,是一种声明性的、部分兼容 openCypher 的文本查询语言,易于理解和使用。详细语法请参见 [nGQL 指南](../3.ngql-guide/1.nGQL-overview/1.overview.md)。
+{{nebula.name}}查询语言,简称为 nGQL,是一种声明性的、部分兼容 openCypher 的文本查询语言,易于理解和使用。详细语法请参见 [nGQL 指南](../3.ngql-guide/1.nGQL-overview/1.overview.md)。
### 面向未来硬件,读写平衡
-闪存型设备有着极高的性能,并且[价格快速下降](https://blocksandfiles.com/wp-content/uploads/2021/01/Wikibon-SSD-less-than-HDD-in-2026.jpg),
- NebulaGraph 是一个面向 SSD 设计的产品,相比于基于 HDD + 大内存的产品,更适合面向未来的硬件趋势,也更容易做到读写平衡。
+闪存型设备有着极高的性能,并且[价格快速下降](https://blocksandfiles.com/wp-content/uploads/2021/01/Wikibon-SSD-less-than-HDD-in-2026.jpg),{{nebula.name}}是一个面向 SSD 设计的产品,相比于基于 HDD + 大内存的产品,更适合面向未来的硬件趋势,也更容易做到读写平衡。
### 灵活数据建模
-用户可以轻松地在 NebulaGraph 中建立数据模型,不必将数据强制转换为关系表。而且可以自由增加、更新和删除属性。详情请参见[数据模型](2.data-model.md)。
+用户可以轻松地在{{nebula.name}}中建立数据模型,不必将数据强制转换为关系表。而且可以自由增加、更新和删除属性。详情请参见[数据模型](2.data-model.md)。
### 广受欢迎
-腾讯、美团、京东、快手、360 等科技巨头都在使用 NebulaGraph。详情请参见 [NebulaGraph 官网](https://nebula-graph.com.cn/)。
+腾讯、美团、京东、快手、360 等科技巨头都在使用{{nebula.name}}。详情请参见 [{{nebula.name}}官网](https://nebula-graph.com.cn/)。
## 适用场景
-NebulaGraph 可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议使用 NebulaGraph。
+{{nebula.name}}可用于各种基于图的业务场景。为节约转换各类数据到关系型数据库的时间,以及避免复杂查询,建议使用{{nebula.name}}。
### 欺诈检测
-金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图来建模,然后借助 NebulaGraph,可以很容易地检测出诈骗团伙或其他复杂诈骗行为。
+金融机构必须仔细研究大量的交易信息,才能检测出潜在的金融欺诈行为,并了解某个欺诈行为和设备的内在关联。这种场景可以通过图来建模,然后借助{{nebula.name}},可以很容易地检测出诈骗团伙或其他复杂诈骗行为。
### 实时推荐
-NebulaGraph 能够及时处理访问者产生的实时信息,并且精准推送文章、视频、产品和服务。
+{{nebula.name}}能够及时处理访问者产生的实时信息,并且精准推送文章、视频、产品和服务。
### 知识图谱
-自然语言可以转化为知识图谱,存储在 NebulaGraph 中。用自然语言组织的问题可以通过智能问答系统中的语义解析器进行解析并重新组织,然后从知识图谱中检索出问题的可能答案,提供给提问人。
+自然语言可以转化为知识图谱,存储在{{nebula.name}}中。用自然语言组织的问题可以通过智能问答系统中的语义解析器进行解析并重新组织,然后从知识图谱中检索出问题的可能答案,提供给提问人。
### 社交网络
-人际关系信息是典型的图数据,NebulaGraph 可以轻松处理数十亿人和数万亿人际关系的社交网络信息,并在海量并发的情况下,提供快速的好友推荐和工作岗位查询。
+人际关系信息是典型的图数据,{{nebula.name}}可以轻松处理数十亿人和数万亿人际关系的社交网络信息,并在海量并发的情况下,提供快速的好友推荐和工作岗位查询。
## 视频
用户也可以通过视频了解什么是图数据。
-- [图数据库 NebulaGraph 介绍视频](https://www.bilibili.com/video/BV1kf4y1v7LM)(01 分 39 秒)
+- [{{nebula.name}}介绍视频](https://www.bilibili.com/video/BV1kf4y1v7LM)(01 分 39 秒)
diff --git a/docs-2.0/1.introduction/2.data-model.md b/docs-2.0/1.introduction/2.data-model.md
index 85bffbb14db..64709a41aa4 100644
--- a/docs-2.0/1.introduction/2.data-model.md
+++ b/docs-2.0/1.introduction/2.data-model.md
@@ -1,10 +1,10 @@
# 数据模型
-本文介绍 NebulaGraph 的数据模型。数据模型是一种组织数据并说明它们如何相互关联的模型。
+本文介绍{{nebula.name}}的数据模型。数据模型是一种组织数据并说明它们如何相互关联的模型。
## 数据模型
-NebulaGraph 数据模型使用 6 种基本的数据模型:
+{{nebula.name}}数据模型使用 6 种基本的数据模型:
- 图空间(Space)
@@ -19,7 +19,7 @@ NebulaGraph 数据模型使用 6 种基本的数据模型:
!!! Compatibility
- NebulaGraph 2.x 及以下版本中的点必须包含至少一个 Tag。
+ {{nebula.name}} 2.x 及以下版本中的点必须包含至少一个 Tag。
- 边(Edge)
@@ -55,7 +55,7 @@ NebulaGraph 数据模型使用 6 种基本的数据模型:
## 有向属性图
-NebulaGraph 使用有向属性图模型,指点和边构成的图,这些边是有方向的,点和边都可以有属性。
+{{nebula.name}}使用有向属性图模型,指点和边构成的图,这些边是有方向的,点和边都可以有属性。
下表为篮球运动员数据集的结构示例,包括两种类型的点(**player**、**team**)和两种类型的边(**serve**、**follow**)。
@@ -68,10 +68,10 @@ NebulaGraph 使用有向属性图模型,指点和边构成的图,这些边
!!! Note
- NebulaGraph 中没有无向边,只支持有向边。
+ {{nebula.name}}中没有无向边,只支持有向边。
!!! compatibility
- 由于 NebulaGraph {{ nebula.release }} 的数据模型中,允许存在"悬挂边",因此在增删时,用户需自行保证“一条边所对应的起点和终点”的存在性。详见 [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md)、[DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md)、[INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md)、[DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md)。
+ 由于{{nebula.name}} {{ nebula.release }} 的数据模型中,允许存在"悬挂边",因此在增删时,用户需自行保证“一条边所对应的起点和终点”的存在性。详见 [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md)、[DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md)、[INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md)、[DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md)。
不支持 openCypher 中的 MERGE 语句。
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
index 08715e7d343..8d6a456020e 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/1.architecture-overview.md
@@ -1,22 +1,22 @@
-# NebulaGraph 架构总览
+# {{nebula.name}}架构总览
-NebulaGraph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
+{{nebula.name}}由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。
-每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署 NebulaGraph 集群。
+每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署{{nebula.name}}集群。
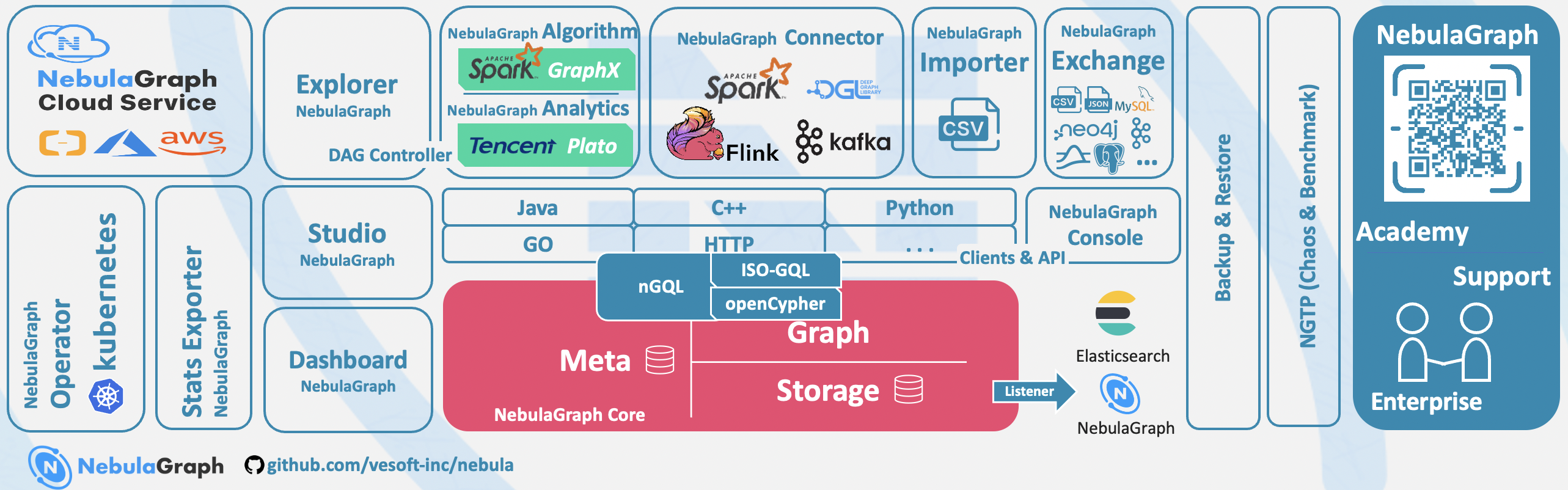
-下图展示了 NebulaGraph 集群的经典架构。
+下图展示了{{nebula.name}}集群的经典架构。
-
+
## Meta 服务
-在 NebulaGraph 架构中,Meta 服务是由 nebula-metad 进程提供的,负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
+在{{nebula.name}}架构中,Meta 服务是由 nebula-metad 进程提供的,负责数据管理,例如 Schema 操作、集群管理和用户权限管理等。
Meta 服务的详细说明,请参见 [Meta 服务](2.meta-service.md)。
## Graph 服务和 Storage 服务
-NebulaGraph 采用计算存储分离架构。Graph 服务负责处理计算请求,Storage 服务负责存储数据。它们由不同的进程提供,Graph 服务是由 nebula-graphd 进程提供,Storage 服务是由 nebula-storaged 进程提供。计算存储分离架构的优势如下:
+{{nebula.name}}采用计算存储分离架构。Graph 服务负责处理计算请求,Storage 服务负责存储数据。它们由不同的进程提供,Graph 服务是由 nebula-graphd 进程提供,Storage 服务是由 nebula-storaged 进程提供。计算存储分离架构的优势如下:
- 易扩展
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
index 654fda6ad45..43537cfde32 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/2.meta-service.md
@@ -8,8 +8,8 @@
Meta 服务是由 nebula-metad 进程提供的,用户可以根据场景配置 nebula-metad 进程数量:
-- 测试环境中,用户可以在 NebulaGraph 集群中部署 1 个或 3 个 nebula-metad 进程。如果要部署 3 个,用户可以将它们部署在 1 台机器上,或者分别部署在不同的机器上。
-- 生产环境中,建议在 NebulaGraph 集群中部署 3 个 nebula-metad 进程。请将这些进程部署在不同的机器上以保证高可用。
+- 测试环境中,用户可以在{{nebula.name}}集群中部署 1 个或 3 个 nebula-metad 进程。如果要部署 3 个,用户可以将它们部署在 1 台机器上,或者分别部署在不同的机器上。
+- 生产环境中,建议在{{nebula.name}}集群中部署 3 个 nebula-metad 进程。请将这些进程部署在不同的机器上以保证高可用。
所有 nebula-metad 进程构成了基于 Raft 协议的集群,其中一个进程是 leader,其他进程都是 follower。
@@ -25,7 +25,7 @@ leader 是由多数派选举出来,只有 leader 能够对客户端或其他
Meta 服务中存储了用户的账号和权限信息,当客户端通过账号发送请求给 Meta 服务,Meta 服务会检查账号信息,以及该账号是否有对应的请求权限。
-更多 NebulaGraph 的访问控制说明,请参见[身份验证](../../7.data-security/1.authentication/1.authentication.md)。
+更多{{nebula.name}}的访问控制说明,请参见[身份验证](../../7.data-security/1.authentication/1.authentication.md)。
### 管理分片
@@ -33,15 +33,15 @@ Meta 服务负责存储和管理分片的位置信息,并且保证分片的负
### 管理图空间
-NebulaGraph 支持多个图空间,不同图空间内的数据是安全隔离的。Meta 服务存储所有图空间的元数据(非完整数据),并跟踪数据的变更,例如增加或删除图空间。
+{{nebula.name}}支持多个图空间,不同图空间内的数据是安全隔离的。Meta 服务存储所有图空间的元数据(非完整数据),并跟踪数据的变更,例如增加或删除图空间。
### 管理 Schema 信息
-NebulaGraph 是强类型图数据库,它的 Schema 包括 Tag、Edge type、Tag 属性和 Edge type 属性。
+{{nebula.name}}是强类型图数据库,它的 Schema 包括 Tag、Edge type、Tag 属性和 Edge type 属性。
Meta 服务中存储了 Schema 信息,同时还负责 Schema 的添加、修改和删除,并记录它们的版本。
-更多 NebulaGraph 的 Schema 信息,请参见[数据模型](../2.data-model.md)。
+更多{{nebula.name}}的 Schema 信息,请参见[数据模型](../2.data-model.md)。
### 管理 TTL 信息
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
index 99faa4ddde5..9ed312c24c8 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
@@ -94,7 +94,7 @@ Executor 模块包含调度器(Scheduler)和执行器(Executor),通过
## 代码结构
-NebulaGraph 的代码层次结构如下:
+{{nebula.name}}的代码层次结构如下:
```bash
|--src
@@ -115,7 +115,7 @@ NebulaGraph 的代码层次结构如下:
## 视频
-用户也可以通过视频全方位了解 NebulaGraph 的查询引擎。
+用户也可以通过视频全方位了解{{nebula.name}}的查询引擎。
- [nMeetup·上海 |全面解析 Query Engine](https://www.bilibili.com/video/BV1xV411n7DD)(33 分 30 秒)
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
index a0ae138f629..a9d13eb60b3 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
@@ -1,6 +1,6 @@
# Storage 服务
-NebulaGraph 的存储包含两个部分,一个是 Meta 相关的存储,称为 Meta 服务,在前文已有介绍。
+{{nebula.name}}的存储包含两个部分,一个是 Meta 相关的存储,称为 Meta 服务,在前文已有介绍。
另一个是具体数据相关的存储,称为 Storage 服务。其运行在 nebula-storaged 进程中。本文仅介绍 Storage 服务的架构设计。
@@ -52,17 +52,17 @@ Storage 服务是由 nebula-storaged 进程提供的,用户可以根据场景
## KVStore
-NebulaGraph 使用自行开发的 KVStore,而不是其他开源 KVStore,原因如下:
+{{nebula.name}}使用自行开发的 KVStore,而不是其他开源 KVStore,原因如下:
- 需要高性能 KVStore。
-- 需要以库的形式提供,实现高效计算下推。对于强 Schema 的 NebulaGraph 来说,计算下推时如何提供 Schema 信息,是高效的关键。
+- 需要以库的形式提供,实现高效计算下推。对于强 Schema 的{{nebula.name}}来说,计算下推时如何提供 Schema 信息,是高效的关键。
- 需要数据强一致性。
-基于上述原因,NebulaGraph 使用 RocksDB 作为本地存储引擎,实现了自己的 KVStore,有如下优势:
+基于上述原因,{{nebula.name}}使用 RocksDB 作为本地存储引擎,实现了自己的 KVStore,有如下优势:
-- 对于多硬盘机器,NebulaGraph 只需配置多个不同的数据目录即可充分利用多硬盘的并发能力。
+- 对于多硬盘机器,{{nebula.name}}只需配置多个不同的数据目录即可充分利用多硬盘的并发能力。
- 由 Meta 服务统一管理所有 Storage 服务,可以根据所有分片的分布情况和状态,手动进行负载均衡。
@@ -76,11 +76,11 @@ NebulaGraph 使用自行开发的 KVStore,而不是其他开源 KVStore,原
## 数据存储格式
-图存储的主要数据是点和边,NebulaGraph 将点和边的信息存储为 key,同时将点和边的属性信息存储在 value 中,以便更高效地使用属性过滤。
+图存储的主要数据是点和边,{{nebula.name}}将点和边的信息存储为 key,同时将点和边的属性信息存储在 value 中,以便更高效地使用属性过滤。
- 点数据存储格式
- 相比 NebulaGraph 2.x 版本,3.x 版本在开启**无 Tag** 的点配置后,每个点多了一个不含 TagID 字段并且无 value 的 key。
+ 相比{{nebula.name}} 2.x 版本,3.x 版本在开启**无 Tag** 的点配置后,每个点多了一个不含 TagID 字段并且无 value 的 key。
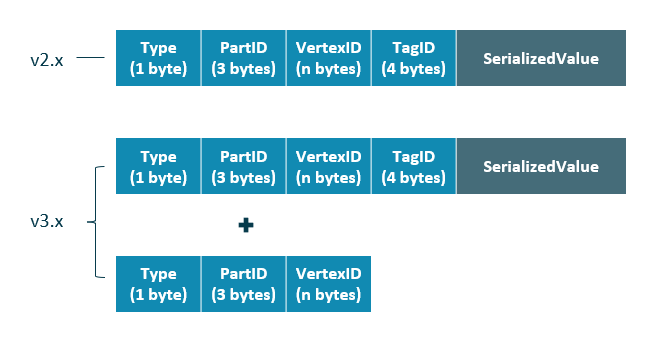
@@ -108,19 +108,19 @@ NebulaGraph 使用自行开发的 KVStore,而不是其他开源 KVStore,原
### 属性说明
-NebulaGraph 使用强类型 Schema。
+{{nebula.name}}使用强类型 Schema。
-对于点或边的属性信息,NebulaGraph 会将属性信息编码后按顺序存储。由于属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)。同时为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息。
+对于点或边的属性信息,{{nebula.name}}会将属性信息编码后按顺序存储。由于属性的长度是固定的,查询时可以根据偏移量快速查询。在解码之前,需要先从 Meta 服务中查询具体的 Schema 信息(并缓存)。同时为了支持在线变更 Schema,在编码属性时,会加入对应的 Schema 版本信息。
## 数据分片
-由于超大规模关系网络的节点数量高达百亿到千亿,而边的数量更会高达万亿,即使仅存储点和边两者也远大于一般服务器的容量。因此需要有方法将图元素切割,并存储在不同逻辑分片(Partition)上。NebulaGraph 采用边分割的方式。
+由于超大规模关系网络的节点数量高达百亿到千亿,而边的数量更会高达万亿,即使仅存储点和边两者也远大于一般服务器的容量。因此需要有方法将图元素切割,并存储在不同逻辑分片(Partition)上。{{nebula.name}}采用边分割的方式。
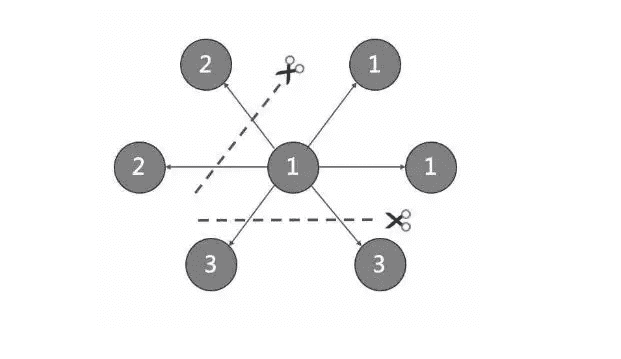
### 切边与存储放大
-NebulaGraph 中逻辑上的一条边对应着硬盘上的两个键值对(key-value pair),在边的数量和属性较多时,存储放大现象较明显。边的存储方式如下图所示。
+{{nebula.name}}中逻辑上的一条边对应着硬盘上的两个键值对(key-value pair),在边的数量和属性较多时,存储放大现象较明显。边的存储方式如下图所示。
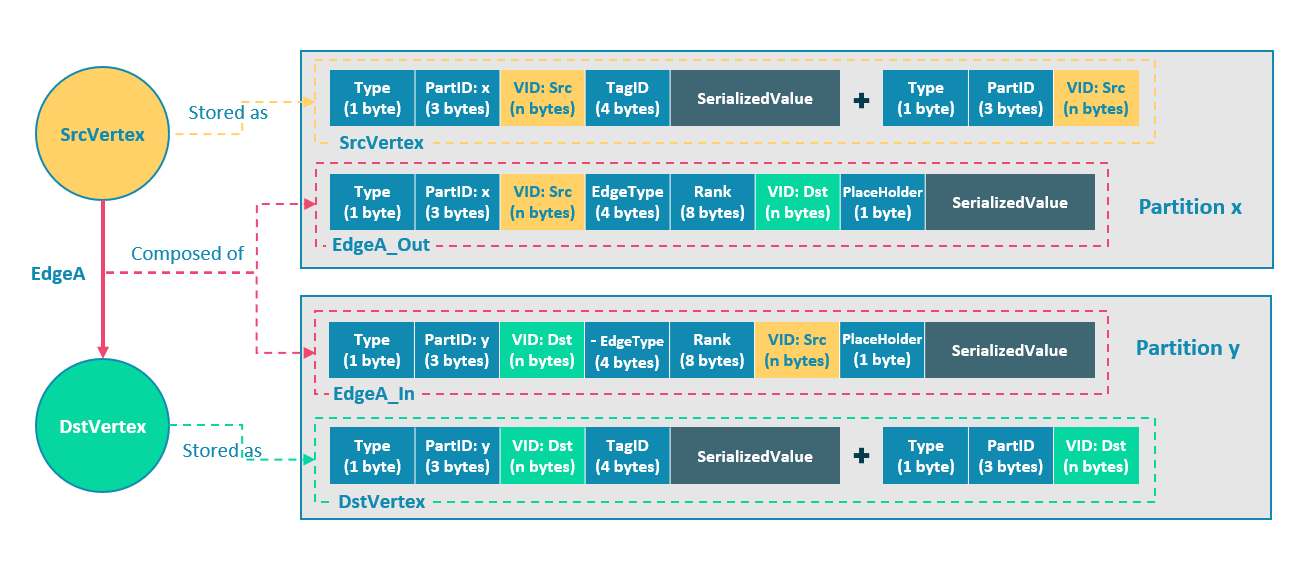
@@ -136,7 +136,7 @@ NebulaGraph 中逻辑上的一条边对应着硬盘上的两个键值对(key-v
EdgeA_Out 和 EdgeA_In 以方向相反的两条边的形式存在于存储层,二者组合成了逻辑上的一条边 EdgeA。EdgeA_Out 用于从起点开始的遍历请求,例如`(a)-[]->()`;EdgeA_In 用于指向目的点的遍历请求,或者说从目的点开始,沿着边的方向逆序进行的遍历请求,例如例如`()-[]->(a)`。
-如 EdgeA_Out 和 EdgeA_In 一样,NebulaGraph 冗余了存储每条边的信息,导致存储边所需的实际空间翻倍。因为边对应的 key 占用的硬盘空间较小,但 value 占用的空间与属性值的长度和数量成正比,所以,当边的属性值较大或数量较多时候,硬盘空间占用量会比较大。
+如 EdgeA_Out 和 EdgeA_In 一样,{{nebula.name}}冗余了存储每条边的信息,导致存储边所需的实际空间翻倍。因为边对应的 key 占用的硬盘空间较小,但 value 占用的空间与属性值的长度和数量成正比,所以,当边的属性值较大或数量较多时候,硬盘空间占用量会比较大。
### 分片算法
@@ -202,14 +202,14 @@ pId = vid % numParts + 1;
Raft 多副本的方式与 HDFS 多副本的方式是不同的,Raft 基于“多数派”投票,因此副本数量不能是偶数。
### Multi Group Raft
由于 Storage 服务需要支持集群分布式架构,所以基于 Raft 协议实现了 Multi Group Raft,即每个分片的所有副本共同组成一个 Raft group,其中一个副本是 leader,其他副本是 follower,从而实现强一致性和高可用性。Raft 的部分实现如下。
-由于 Raft 日志不允许空洞,NebulaGraph 使用 Multi Group Raft 缓解此问题,分片数量较多时,可以有效提高 NebulaGraph 的性能。但是分片数量太多会增加开销,例如 Raft group 内部存储的状态信息、WAL 文件,或者负载过低时的批量操作。
+由于 Raft 日志不允许空洞,{{nebula.name}}使用 Multi Group Raft 缓解此问题,分片数量较多时,可以有效提高{{nebula.name}}的性能。但是分片数量太多会增加开销,例如 Raft group 内部存储的状态信息、WAL 文件,或者负载过低时的批量操作。
实现 Multi Group Raft 有 2 个关键点:
@@ -223,7 +223,7 @@ Listener:这是一种特殊的 Raft 角色,并不参与投票,也不能用
### 批量(Batch)操作
-NebulaGraph 中,每个分片都是串行写日志,为了提高吞吐,写日志时需要做批量操作,但是由于 NebulaGraph 利用 WAL 实现一些特殊功能,需要对批量操作进行分组,这是 NebulaGraph 的特色。
+{{nebula.name}}中,每个分片都是串行写日志,为了提高吞吐,写日志时需要做批量操作,但是由于{{nebula.name}}利用 WAL 实现一些特殊功能,需要对批量操作进行分组,这是{{nebula.name}}的特色。
例如无锁 CAS 操作需要之前的 WAL 全部提交后才能执行,如果一个批量写入的 WAL 里包含了 CAS 类型的 WAL,就需要拆分成粒度更小的几个组,还要保证这几组 WAL 串行提交。
@@ -245,14 +245,14 @@ leader 切换对于负载均衡至关重要,当把某个分片从一台机器
### 成员变更
-为了避免脑裂,当一个 Raft group 的成员发生变化时,需要有一个中间状态,该状态下新旧 group 的多数派需要有重叠的部分,这样就防止了新的 group 或旧的 group 单方面做出决定。为了更加简化,Diego Ongaro 在自己的博士论文中提出每次只增减一个 peer 的方式,以保证新旧 group 的多数派总是有重叠。NebulaGraph 也采用了这个方式,只不过增加成员和移除成员的实现有所区别。具体实现方式请参见 Raft Part class 里 addPeer/removePeer 的实现。
+为了避免脑裂,当一个 Raft group 的成员发生变化时,需要有一个中间状态,该状态下新旧 group 的多数派需要有重叠的部分,这样就防止了新的 group 或旧的 group 单方面做出决定。为了更加简化,Diego Ongaro 在自己的博士论文中提出每次只增减一个 peer 的方式,以保证新旧 group 的多数派总是有重叠。{{nebula.name}}也采用了这个方式,只不过增加成员和移除成员的实现有所区别。具体实现方式请参见 Raft Part class 里 addPeer/removePeer 的实现。
diff --git a/docs-2.0/1.introduction/3.vid.md b/docs-2.0/1.introduction/3.vid.md
index 958ba8a8d7a..0003838dd33 100644
--- a/docs-2.0/1.introduction/3.vid.md
+++ b/docs-2.0/1.introduction/3.vid.md
@@ -22,7 +22,7 @@
## VID 使用建议
-- NebulaGraph 1.x 只支持 VID 类型为`INT64`,从 2.x 开始支持`INT64`和`FIXED_STRING()`。在`CREATE SPACE`中通过参数`vid_type`可以指定 VID 类型。
+- {{nebula.name}} 1.x 只支持 VID 类型为`INT64`,从 2.x 开始支持`INT64`和`FIXED_STRING()`。在`CREATE SPACE`中通过参数`vid_type`可以指定 VID 类型。
- 可以使用`id()`函数,指定或引用该点的 VID。
@@ -52,7 +52,7 @@ VID 必须在[插入点](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md
## "查询起始点"(`start vid`) 与全局扫描
-绝大多数情况下,NebulaGraph 的查询语句(`MATCH`、`GO`、`LOOKUP`)的执行计划,必须要通过一定方式找到查询起始点的 VID(`start vid`)。
+绝大多数情况下,{{nebula.name}}的查询语句(`MATCH`、`GO`、`LOOKUP`)的执行计划,必须要通过一定方式找到查询起始点的 VID(`start vid`)。
定位 `start vid` 只有两种方式:
diff --git a/docs-2.0/14.client/1.nebula-client.md b/docs-2.0/14.client/1.nebula-client.md
index 95eccf02993..20e59f10cad 100644
--- a/docs-2.0/14.client/1.nebula-client.md
+++ b/docs-2.0/14.client/1.nebula-client.md
@@ -1,6 +1,6 @@
# 客户端介绍
-NebulaGraph 提供多种类型客户端,便于用户连接、管理 NebulaGraph 图数据库。
+{{nebula.name}}提供多种类型客户端,便于用户连接、管理{{nebula.name}}图数据库。
- [NebulaGraph Console](../nebula-console.md):原生 CLI 客户端
@@ -18,7 +18,7 @@ NebulaGraph 提供多种类型客户端,便于用户连接、管理 NebulaGrap
!!! caution
- 以下客户端工具也可用于连接和管理 NebulaGraph。他们由非常酷的社区用户提供和维护,欢迎大家参与测试和贡献。
+ 以下客户端工具也可用于连接和管理{{nebula.name}}。他们由非常酷的社区用户提供和维护,欢迎大家参与测试和贡献。
- [NebulaGraph PHP](https://github.com/nebula-contrib/nebula-php)
- [NebulaGraph Node](https://github.com/nebula-contrib/nebula-node)
diff --git a/docs-2.0/14.client/3.nebula-cpp-client.md b/docs-2.0/14.client/3.nebula-cpp-client.md
index d9d5b8414de..a36a6769733 100644
--- a/docs-2.0/14.client/3.nebula-cpp-client.md
+++ b/docs-2.0/14.client/3.nebula-cpp-client.md
@@ -1,6 +1,6 @@
# NebulaGraph CPP
-[NebulaGraph CPP](https://github.com/vesoft-inc/nebula-cpp/tree/{{cpp.branch}}) 是一款 C++ 语言的客户端,可以连接、管理 NebulaGraph 图数据库。
+[NebulaGraph CPP](https://github.com/vesoft-inc/nebula-cpp/tree/{{cpp.branch}}) 是一款 C++ 语言的客户端,可以连接、管理{{nebula.name}}图数据库。
## 使用限制
@@ -8,7 +8,7 @@
## 版本对照表
-|NebulaGraph 版本|NebulaGraph CPP 版本|
+|{{nebula.name}}版本|NebulaGraph CPP 版本|
|:---|:---|
|3.3.0|3.3.0|
|3.1.0 ~ 3.2.x|3.0.2|
@@ -100,9 +100,9 @@
$ LIBRARY_PATH=:$LIBRARY_PATH g++ -std=c++11 SessionExample.cpp -I -lnebula_graph_client -o session_example
```
- - `library_folder_path`:NebulaGraph 动态库文件存储路径,默认为`/usr/local/nebula/lib64`。
+ - `library_folder_path`:{{nebula.name}}动态库文件存储路径,默认为`/usr/local/nebula/lib64`。
- - `include_folder_path`:NebulaGraph 头文件存储路径,默认为`/usr/local/nebula/include`。
+ - `include_folder_path`:{{nebula.name}}头文件存储路径,默认为`/usr/local/nebula/include`。
示例:
@@ -112,7 +112,7 @@
## 核心代码
-NebulaGraph CPP 客户端提供 Session Pool 和 Connection Pool 两种方式连接 NebulaGraph。使用 Connection Pool 需要用户自行管理 Session 实例。
+NebulaGraph CPP 客户端提供 Session Pool 和 Connection Pool 两种方式连接{{nebula.name}}。使用 Connection Pool 需要用户自行管理 Session 实例。
- Session Pool
diff --git a/docs-2.0/14.client/4.nebula-java-client.md b/docs-2.0/14.client/4.nebula-java-client.md
index 4349c775e77..e7152ae8bd0 100644
--- a/docs-2.0/14.client/4.nebula-java-client.md
+++ b/docs-2.0/14.client/4.nebula-java-client.md
@@ -1,6 +1,6 @@
# NebulaGraph Java
-[NebulaGraph Java](https://github.com/vesoft-inc/nebula-java/tree/{{ java.branch }}) 是一款 Java 语言的客户端,可以连接、管理 NebulaGraph 图数据库。
+[NebulaGraph Java](https://github.com/vesoft-inc/nebula-java/tree/{{ java.branch }}) 是一款 Java 语言的客户端,可以连接、管理{{nebula.name}}图数据库。
## 前提条件
@@ -8,7 +8,7 @@
## 版本对照表
-|NebulaGraph 版本|NebulaGraph Java 版本|
+|{{nebula.name}}版本|NebulaGraph Java 版本|
|:---|:---|
|3.3.0|3.3.0|
|3.0.0 ~ 3.2.0|3.0.0|
diff --git a/docs-2.0/14.client/5.nebula-python-client.md b/docs-2.0/14.client/5.nebula-python-client.md
index ae3dd4e6bac..918d2dcfa87 100644
--- a/docs-2.0/14.client/5.nebula-python-client.md
+++ b/docs-2.0/14.client/5.nebula-python-client.md
@@ -1,6 +1,6 @@
# NebulaGraph Python
-[NebulaGraph Python](https://github.com/vesoft-inc/nebula-python) 是一款 Python 语言的客户端,可以连接、管理 NebulaGraph 图数据库。
+[NebulaGraph Python](https://github.com/vesoft-inc/nebula-python) 是一款 Python 语言的客户端,可以连接、管理{{nebula.name}}图数据库。
## 前提条件
@@ -8,7 +8,7 @@
## 版本对照表
-|NebulaGraph 版本|NebulaGraph Python 版本|
+|{{nebula.name}}版本|NebulaGraph Python 版本|
|:---|:---|
|3.3.0|3.3.0|
|3.1.0 ~ 3.2.x|3.1.0|
diff --git a/docs-2.0/14.client/6.nebula-go-client.md b/docs-2.0/14.client/6.nebula-go-client.md
index 5f3553f3915..26dfac69e36 100644
--- a/docs-2.0/14.client/6.nebula-go-client.md
+++ b/docs-2.0/14.client/6.nebula-go-client.md
@@ -1,6 +1,6 @@
# NebulaGraph Go
-[NebulaGraph Go](https://github.com/vesoft-inc/nebula-go/tree/{{go.branch}}) 是一款 Go 语言的客户端,可以连接、管理 NebulaGraph 图数据库。
+[NebulaGraph Go](https://github.com/vesoft-inc/nebula-go/tree/{{go.branch}}) 是一款 Go 语言的客户端,可以连接、管理{{nebula.name}}图数据库。
## 前提条件
@@ -8,7 +8,7 @@
## 版本对照表
-|NebulaGraph 版本|NebulaGraph Go 版本|
+|{{nebula.name}}版本|NebulaGraph Go 版本|
|:---|:---|
|3.3.0|3.3.0|
|3.2.x|3.2.0|
diff --git a/docs-2.0/15.contribution/how-to-contribute.md b/docs-2.0/15.contribution/how-to-contribute.md
index 419eb448ffc..caaae179ddd 100644
--- a/docs-2.0/15.contribution/how-to-contribute.md
+++ b/docs-2.0/15.contribution/how-to-contribute.md
@@ -18,7 +18,7 @@
## 修改单篇文档
-NebulaGraph 文档以 Markdown 语言编写。单击文档标题右侧的铅笔图标即可提交修改建议。
+{{nebula.name}}文档以 Markdown 语言编写。单击文档标题右侧的铅笔图标即可提交修改建议。
该方法仅适用于修改单篇文档。
@@ -28,11 +28,11 @@ NebulaGraph 文档以 Markdown 语言编写。单击文档标题右侧的铅笔
### Step 1:通过 GitHub fork 仓库
-NebulaGraph 项目有很多[仓库](https://github.com/vesoft-inc),以 [NebulaGraph 仓库](https://github.com/vesoft-inc/nebula)为例:
+{{nebula.name}}项目有很多[仓库](https://github.com/vesoft-inc),以 [{{nebula.name}}仓库](https://github.com/vesoft-inc/nebula)为例:
1. 访问 [github.com/vesoft-inc/nebula](https://github.com/vesoft-inc/nebula)。
-2. 在右上角单击按钮`Fork`,然后单击用户名,即可 fork 出 NebulaGraph 仓库。
+2. 在右上角单击按钮`Fork`,然后单击用户名,即可 fork 出{{nebula.name}}仓库。
### Step 2:将分支克隆到本地
@@ -75,7 +75,7 @@ NebulaGraph 项目有很多[仓库](https://github.com/vesoft-inc),以 [Nebula
4. (可选)定义 pre-commit hook。
- 请将 NebulaGraph 的 pre-commit hook 连接到`.git`目录。
+ 请将{{nebula.name}}的 pre-commit hook 连接到`.git`目录。
hook 将检查 commit,包括格式、构建、文档生成等。
@@ -124,7 +124,7 @@ NebulaGraph 项目有很多[仓库](https://github.com/vesoft-inc),以 [Nebula
- 代码风格
- **NebulaGraph** 采用`cpplint`来确保代码符合 Google 的代码风格指南。检查器将在提交代码之前执行。
+ {{nebula.name}}采用`cpplint`来确保代码符合 Google 的代码风格指南。检查器将在提交代码之前执行。
- 单元测试要求
@@ -132,7 +132,7 @@ NebulaGraph 项目有很多[仓库](https://github.com/vesoft-inc),以 [Nebula
- 构建代码时开启单元测试
- 详情请参见[使用源码安装 NebulaGraph](../4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md)。
+ 详情请参见[使用源码安装{{nebula.name}}](../4.deployment-and-installation/2.compile-and-install-nebula-graph/1.install-nebula-graph-by-compiling-the-source-code.md)。
!!! Note
@@ -193,7 +193,7 @@ pull request 创建后,至少需要两人审查。审查人员将进行彻底
### Step 1:确认项目捐赠
-通过邮件、微信、Slack 等方式联络 NebulaGraph 官方人员,确认捐赠项目一事。项目将被捐赠至 [NebulaGraph Contrib](https://github.com/nebula-contrib) 组织下。
+通过邮件、微信、Slack 等方式联络{{nebula.name}}官方人员,确认捐赠项目一事。项目将被捐赠至 [{{nebula.name}} Contrib](https://github.com/nebula-contrib) 组织下。
* 邮件地址:info@vesoft.com
@@ -203,10 +203,10 @@ pull request 创建后,至少需要两人审查。审查人员将进行彻底
### Step 2:获取项目接收人信息
-由 NebulaGraph 官方人员给出 NebulaGraph Contrib 的项目接收者 ID。
+由{{nebula.name}}官方人员给出{{nebula.name}} Contrib 的项目接收者 ID。
### Step 3:捐赠项目
-由您将项目转移至本次捐赠的项目接受人,并由项目接收者将该项目转移至 [NebulaGraph Contrib](https://github.com/nebula-contrib) 组织下。捐赠后,您将以 Maintain 角色继续主导社区项目的发展。
+由您将项目转移至本次捐赠的项目接受人,并由项目接收者将该项目转移至 [{{nebula.name}} Contrib](https://github.com/nebula-contrib) 组织下。捐赠后,您将以 Maintain 角色继续主导社区项目的发展。
GitHub 上转移仓库的操作,请参见 [Transferring a repository owned by your user account](https://docs.github.com/en/enterprise-server@3.0/github/administering-a-repository/managing-repository-settings/transferring-a-repository#transferring-a-repository-owned-by-your-user-account)。
diff --git a/docs-2.0/2.quick-start/1.quick-start-overview.md b/docs-2.0/2.quick-start/1.quick-start-overview.md
index 0df2ae90f49..47fbd101e6b 100644
--- a/docs-2.0/2.quick-start/1.quick-start-overview.md
+++ b/docs-2.0/2.quick-start/1.quick-start-overview.md
@@ -1,24 +1,24 @@
# 快速入门概览
-用户可通过 Docker Desktop、云、本地三种部署方式快速入门 NebulaGraph。快速入门将介绍如何通过 Docker Desktop、云、本地三种部署方式简单地使用 NebulaGraph,包括部署、连接 NebulaGraph,以及基础的增删改查操作。
+用户可通过 Docker Desktop、云、本地三种部署方式快速入门{{nebula.name}}。快速入门将介绍如何通过 Docker Desktop、云、本地三种部署方式简单地使用{{nebula.name}},包括部署、连接{{nebula.name}},以及基础的增删改查操作。
## 使用 Docker Desktop 一键部署
-按照以下步骤可以快速在 Docker Desktop 中部署 NebulaGraph。
+按照以下步骤可以快速在 Docker Desktop 中部署{{nebula.name}}。
1. 安装 [Docker Desktop](https://www.docker.com/products/docker-desktop/)。
!!! caution
如果在 Windows 端安装 Docker Desktop 需[安装 WSL 2](https://docs.docker.com/desktop/install/windows-install/)。
-
-2. 在仪表盘中单击`Extensions`或`Add Extensions`打开Extensions Marketplace 搜索 NebulaGraph ,也可以点击 [NebulaGraph](https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext) 在 Docker Desktop 打开。
-3. 导航到 NebulaGraph 的扩展市场。
-4. 点击`Install`下载 NebulaGraph。
+
+2. 在仪表盘中单击`Extensions`或`Add Extensions`打开Extensions Marketplace 搜索{{nebula.name}} ,也可以点击 [{{nebula.name}}](https://hub.docker.com/extensions/weygu/nebulagraph-dd-ext) 在 Docker Desktop 打开。
+3. 导航到{{nebula.name}}的扩展市场。
+4. 点击`Install`下载{{nebula.name}}。
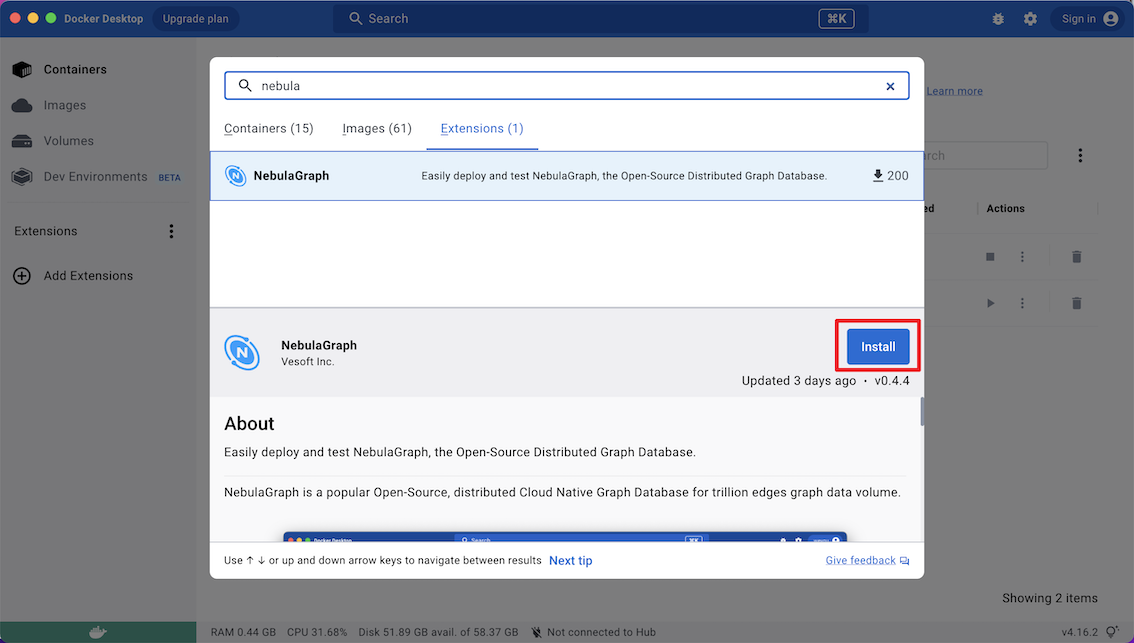
-5. 在有 NebulaGraph 更新的时候,可以点击`Update`更新到最新版本。
+5. 在有更新的时候,可以点击`Update`更新到最新版本。
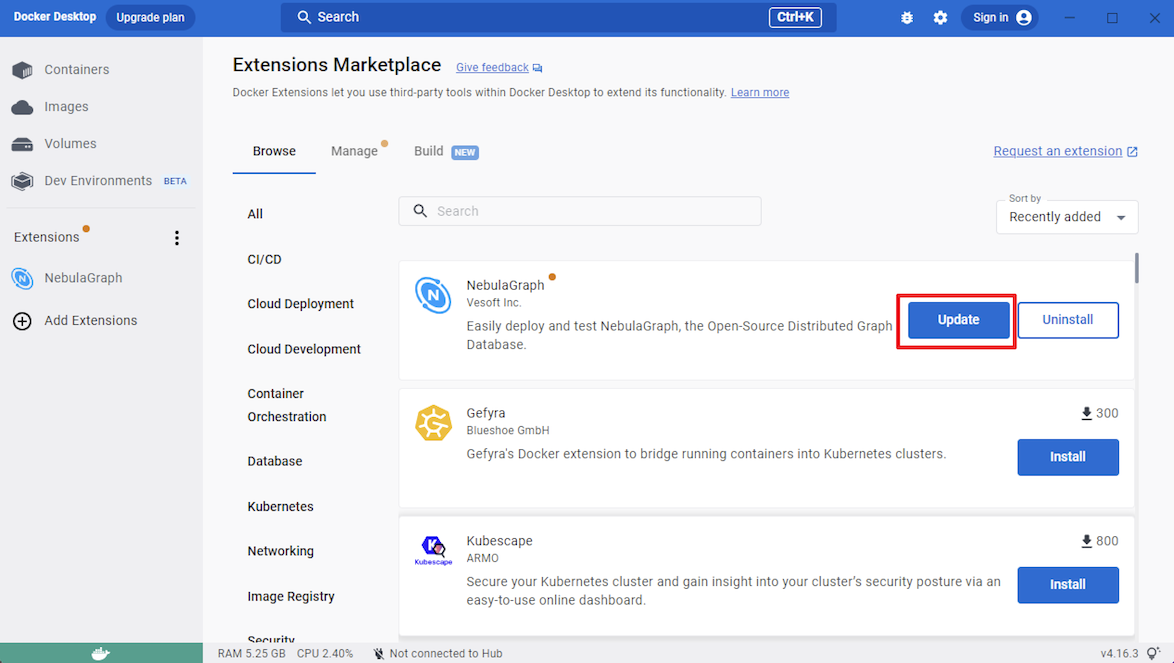
@@ -35,13 +35,13 @@
### 操作步骤
-按照以下步骤可以快速在云上部署并且使用 NebulaGraph。
+按照以下步骤可以快速在云上部署并且使用{{nebula.name}}。
1. [创建云服务实例](https://docs.nebula-graph.com.cn/{{cloud.aliyunLatestRelease}}/nebula-cloud/nebula-cloud-on-alibabacloud/1.create-service-instance/)
-2. [连接 NebulaGraph](2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md)
+2. [连接{{nebula.name}}](2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md)
-3. [管理 NebulaGraph 数据](2.quick-start-on-cloud/3.how-to-query-on-cloud.md)
+3. [管理{{nebula.name}}数据](2.quick-start-on-cloud/3.how-to-query-on-cloud.md)
### 更多方式
@@ -55,15 +55,15 @@
### 操作步骤
-按照以下步骤可以快速在本地部署并且使用 NebulaGraph。
+按照以下步骤可以快速在本地部署并且使用{{nebula.name}}。
-1. [安装 NebulaGraph](../4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md)
+1. [安装{{nebula.name}}](../4.deployment-and-installation/2.compile-and-install-nebula-graph/2.install-nebula-graph-by-rpm-or-deb.md)
-2. [启动 NebulaGraph](3.quick-start-on-premise/5.start-stop-service.md)
+2. [启动{{nebula.name}}](3.quick-start-on-premise/5.start-stop-service.md)
-3. [连接 NebulaGraph](3.quick-start-on-premise/3.connect-to-nebula-graph.md)
+3. [连接{{nebula.name}}](3.quick-start-on-premise/3.connect-to-nebula-graph.md)
4. [注册 Storage 服务](3.quick-start-on-premise/3.1add-storage-hosts.md)
@@ -73,13 +73,13 @@
### 更多方式
-快速入门使用 RPM 或 DEB 文件安装 NebulaGraph,您还可以使用其他本地部署方式安装 NebulaGraph。关于其它部署方式及相应的准备工作,参见文档目录**安装部署**。
+快速入门使用 RPM 或 DEB 文件安装{{nebula.name}},您还可以使用其他本地部署方式安装{{nebula.name}}。关于其它部署方式及相应的准备工作,参见文档目录**安装部署**。
## 视频
-用户也可以观看视频快速了解 NebulaGraph 的相关概念和操作。
+用户也可以观看视频快速了解{{nebula.name}}的相关概念和操作。
-### NebulaGraph Academy 系列课程
+### {{nebula.name}} Academy 系列课程
* [第一课:图的概念](https://www.bilibili.com/video/BV1CK411f7Fw)(03 分 45 秒)
@@ -100,7 +100,7 @@
-->
-* [Foesa 小学姐课堂——NebulaGraph 那些磨人的概念](https://www.bilibili.com/video/BV1Q5411K7Gg)(04 分 20 秒)
+* [Foesa 小学姐课堂——{{nebula.name}}那些磨人的概念](https://www.bilibili.com/video/BV1Q5411K7Gg)(04 分 20 秒)
diff --git a/docs-2.0/2.quick-start/2.quick-start-on-cloud/1.create-instance-on-cloud.md b/docs-2.0/2.quick-start/2.quick-start-on-cloud/1.create-instance-on-cloud.md
index 4b328c385f6..2fd34f52431 100644
--- a/docs-2.0/2.quick-start/2.quick-start-on-cloud/1.create-instance-on-cloud.md
+++ b/docs-2.0/2.quick-start/2.quick-start-on-cloud/1.create-instance-on-cloud.md
@@ -1,14 +1,14 @@
# 创建云服务实例
-用户可以在云服务上创建 NebulaGraph 实例,本文介绍如何在阿里云上快速创建 NebulaGraph 实例。
+用户可以在云服务上创建{{nebula.name}}实例,本文介绍如何在阿里云上快速创建{{nebula.name}}实例。
## 背景信息
-NebulaGraph 支持在多个云平台上部署 NebulaGraph,本文只介绍如何在 NebulaGraph Cloud 阿里云版创建 NebulaGraph 实例。更多云服务平台的支持情况,参见 [NebulaGraph Cloud](https://docs.nebula-graph.com.cn/{{cloud.aliyunLatestRelease}}/nebula-cloud/1.what-is-cloud/)。
+{{nebula.name}}支持在多个云平台上部署{{nebula.name}},本文只介绍如何在 NebulaGraph Cloud 阿里云版创建{{nebula.name}}实例。更多云服务平台的支持情况,参见 [NebulaGraph Cloud](https://docs.nebula-graph.com.cn/{{cloud.aliyunLatestRelease}}/nebula-cloud/1.what-is-cloud/)。
!!! caution
- 使用 NebulaGraph Cloud 阿里云版创建的实例对应`{{cloud.aliyunLatestRelease}}`版本的 NebulaGraph。
+ 使用 NebulaGraph Cloud 阿里云版创建的实例对应`{{cloud.aliyunLatestRelease}}`版本的{{nebula.name}}。
{% include "/source_create_instance_aliyun.md" %}
diff --git a/docs-2.0/2.quick-start/2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md b/docs-2.0/2.quick-start/2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md
index 5f1803f323c..f9e34fbeced 100644
--- a/docs-2.0/2.quick-start/2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md
+++ b/docs-2.0/2.quick-start/2.quick-start-on-cloud/2.connect-to-nebulagraph-on-cloud.md
@@ -1,6 +1,6 @@
-# 连接 NebulaGraph
+# 连接{{nebula.name}}
-创建好云服务实例后,可以连接 NebulaGraph。本文介绍如何使用 NebulaGraph Explorer 快速连接 NebulaGraph。
+创建好云服务实例后,可以连接{{nebula.name}}。本文介绍如何使用{{explorer.name}}快速连接{{nebula.name}}。
## 前提条件
@@ -8,7 +8,7 @@
## 操作步骤
-本文使用 [NebulaGraph Explorer](../../nebula-explorer/about-explorer/ex-ug-what-is-explorer.md) 快速连接 NebulaGraph。操作步骤如下:
+本文使用 [{{explorer.name}}](../../nebula-explorer/about-explorer/ex-ug-what-is-explorer.md) 快速连接{{nebula.name}}。操作步骤如下:
1. 登录[服务实例管理](https://computenest.console.aliyun.com/user/cn-hangzhou/serviceInstance/private)页面。
@@ -21,7 +21,7 @@
4. 在**概览**页签的**基本信息**区域,查看**nebula_private_ip**及**explorer_portal**信息。
-5. 单击**explorer_portal**对应链接,进入 NebulaGraph Explorer 登录页面。
+5. 单击**explorer_portal**对应链接,进入{{explorer.name}}登录页面。
6. 填写登录信息,单击**登录**。
- **Host**:`nebula_private_ip地址:9669`,例如`192.168.98.160:9669`。
@@ -35,9 +35,9 @@
## 更多连接方式
-用户可根据自己的需求选择其他连接方式。关于更多连接方式,参见[连接 NebulaGraph](https://docs.nebula-graph.com.cn/{{cloud.aliyunLatestRelease}}/nebula-cloud/nebula-cloud-on-alibabacloud/2.use-cloud-services/#_4)。
+用户可根据自己的需求选择其他连接方式。关于更多连接方式,参见[连接{{nebula.name}}](https://docs.nebula-graph.com.cn/{{cloud.aliyunLatestRelease}}/nebula-cloud/nebula-cloud-on-alibabacloud/2.use-cloud-services/#_4)。
## 下一步
-[管理 NebulaGraph 数据](3.how-to-query-on-cloud.md)
\ No newline at end of file
+[管理{{nebula.name}}数据](3.how-to-query-on-cloud.md)
\ No newline at end of file
diff --git a/docs-2.0/2.quick-start/2.quick-start-on-cloud/3.how-to-query-on-cloud.md b/docs-2.0/2.quick-start/2.quick-start-on-cloud/3.how-to-query-on-cloud.md
index 546594feb1f..d46aefbad5e 100644
--- a/docs-2.0/2.quick-start/2.quick-start-on-cloud/3.how-to-query-on-cloud.md
+++ b/docs-2.0/2.quick-start/2.quick-start-on-cloud/3.how-to-query-on-cloud.md
@@ -1,16 +1,16 @@
-# 管理 NebulaGraph 数据
+# 管理{{nebula.name}}数据
-nGQL 是 NebulaGraph 创建的声明式图查询语言。用户可以使用 nGQL 语句对 NebulaGraph 数据库进行增删改查。本文介绍如何通过 NebulaGraph Cloud 中 Explorer 的控制台功能快速使用 Nebula Graph 基本语句。
+nGQL 是{{nebula.name}}创建的声明式图查询语言。用户可以使用 nGQL 语句对{{nebula.name}}数据库进行增删改查。本文介绍如何通过 NebulaGraph Cloud 中{{explorer.name}}的控制台功能快速使用 Nebula Graph 基本语句。
!!! note
- 用户可以在 Explorer 中通过可视化查询 NebulaGraph 数据。本文介绍通过控制台功能使用 nGQL 语句增删改查 NebulaGraph 数据。关于如何可视化使用 Explorer 查询数据,参见[开始探索](../../nebula-explorer/graph-explorer/ex-ug-query-exploration.md)和[探索拓展](../../nebula-explorer/graph-explorer/ex-ug-graph-exploration.md),或者观看视频。
+ 用户可以在{{explorer.name}}中通过可视化查询{{nebula.name}}数据。本文介绍通过控制台功能使用 nGQL 语句增删改查{{nebula.name}}数据。关于如何可视化使用{{explorer.name}}查询数据,参见[开始探索](../../nebula-explorer/graph-explorer/ex-ug-query-exploration.md)和[探索拓展](../../nebula-explorer/graph-explorer/ex-ug-graph-exploration.md),或者观看视频。
## 前提条件
-[连接 NebulaGraph](2.connect-to-nebulagraph-on-cloud.md)
+[连接{{nebula.name}}](2.connect-to-nebulagraph-on-cloud.md)
## 基本流程
@@ -18,7 +18,7 @@ nGQL 是 NebulaGraph 创建的声明式图查询语言。用户可以使用 nGQL
## 操作入口
-在 Explorer 页面的右上方,单击进入控制台页面。在控制台命令行中执行 nGQL 语句。
+在{{explorer.name}}页面的右上方,单击进入控制台页面。在控制台命令行中执行 nGQL 语句。
{% include "/source_ngql_for_quick_start.md" %}
diff --git a/docs-2.0/2.quick-start/3.quick-start-on-premise/2.install-nebula-graph.md b/docs-2.0/2.quick-start/3.quick-start-on-premise/2.install-nebula-graph.md
index 076caba1d63..4f87fcbbc46 100644
--- a/docs-2.0/2.quick-start/3.quick-start-on-premise/2.install-nebula-graph.md
+++ b/docs-2.0/2.quick-start/3.quick-start-on-premise/2.install-nebula-graph.md
@@ -1,4 +1,4 @@
-# 步骤 1:安装 NebulaGraph
+# 步骤 1:安装{{nebula.name}}
{% include "/source_install-nebula-graph-by-rpm-or-deb.md" %}
diff --git a/docs-2.0/2.quick-start/3.quick-start-on-premise/3.1add-storage-hosts.md b/docs-2.0/2.quick-start/3.quick-start-on-premise/3.1add-storage-hosts.md
index d211c7fdf94..f4029d65439 100644
--- a/docs-2.0/2.quick-start/3.quick-start-on-premise/3.1add-storage-hosts.md
+++ b/docs-2.0/2.quick-start/3.quick-start-on-premise/3.1add-storage-hosts.md
@@ -1,21 +1,21 @@
# 注册 Storage 服务
-首次连接到 NebulaGraph 后,需要先添加 Storage 主机,并确认主机都处于在线状态。
+首次连接到{{nebula.name}}后,需要先添加 Storage 主机,并确认主机都处于在线状态。
!!! compatibility "历史版本兼容性"
- 从 NebulaGraph 3.0.0 版本开始,必须先使用`ADD HOSTS`添加主机,才能正常通过 Storage 服务读写数据。
+ 从{{nebula.name}} 3.0.0 版本开始,必须先使用`ADD HOSTS`添加主机,才能正常通过 Storage 服务读写数据。
## 前提条件
-已[连接 NebulaGraph 服务](3.connect-to-nebula-graph.md)。
+已[连接{{nebula.name}}服务](3.connect-to-nebula-graph.md)。
## 操作步骤
diff --git a/docs-2.0/2.quick-start/3.quick-start-on-premise/3.connect-to-nebula-graph.md b/docs-2.0/2.quick-start/3.quick-start-on-premise/3.connect-to-nebula-graph.md
index ddc4a173963..f53edeb6ef7 100644
--- a/docs-2.0/2.quick-start/3.quick-start-on-premise/3.connect-to-nebula-graph.md
+++ b/docs-2.0/2.quick-start/3.quick-start-on-premise/3.connect-to-nebula-graph.md
@@ -1,4 +1,4 @@
-# 步骤 3:连接 NebulaGraph
+# 步骤 3:连接{{nebula.name}}
{% include "/source_connect-to-nebula-graph.md" %}
diff --git a/docs-2.0/2.quick-start/3.quick-start-on-premise/4.nebula-graph-crud.md b/docs-2.0/2.quick-start/3.quick-start-on-premise/4.nebula-graph-crud.md
index 518f37f70fd..e431514762b 100644
--- a/docs-2.0/2.quick-start/3.quick-start-on-premise/4.nebula-graph-crud.md
+++ b/docs-2.0/2.quick-start/3.quick-start-on-premise/4.nebula-graph-crud.md
@@ -1,6 +1,6 @@
# 步骤 4:使用常用 nGQL(CRUD 命令)
-本文介绍 NebulaGraph 查询语言的基础语法,包括用于 Schema 创建和常用增删改查操作的语句。
+本文介绍{{nebula.name}}查询语言的基础语法,包括用于 Schema 创建和常用增删改查操作的语句。
如需了解更多语句的用法,参见 [nGQL 指南](../../3.ngql-guide/1.nGQL-overview/1.overview.md)。
diff --git a/docs-2.0/2.quick-start/3.quick-start-on-premise/5.start-stop-service.md b/docs-2.0/2.quick-start/3.quick-start-on-premise/5.start-stop-service.md
index c245195926f..374c024ef1c 100644
--- a/docs-2.0/2.quick-start/3.quick-start-on-premise/5.start-stop-service.md
+++ b/docs-2.0/2.quick-start/3.quick-start-on-premise/5.start-stop-service.md
@@ -1,4 +1,4 @@
-# 步骤 2:启动 NebulaGraph 服务
+# 步骤 2:启动{{nebula.name}}服务
{% include "/source_manage-service.md" %}
diff --git a/docs-2.0/2.quick-start/6.cheatsheet-for-ngql-command.md b/docs-2.0/2.quick-start/6.cheatsheet-for-ngql-command.md
index 3905c90654a..c8749a0cfdf 100644
--- a/docs-2.0/2.quick-start/6.cheatsheet-for-ngql-command.md
+++ b/docs-2.0/2.quick-start/6.cheatsheet-for-ngql-command.md
@@ -341,7 +341,7 @@
| [CREATE SPACE](../3.ngql-guide/9.space-statements/1.create-space.md) | `CREATE SPACE [IF NOT EXISTS] ( [partition_num = ,] [replica_factor = ,] vid_type = {FIXED_STRING() | INT[64]} ) [COMMENT = '']` | `CREATE SPACE my_space_1 (vid_type=FIXED_STRING(30))` | 创建一个新的图空间。 |
| [CREATE SPACE](../3.ngql-guide/9.space-statements/1.create-space.md) | `CREATE SPACE AS ` | `CREATE SPACE my_space_4 as my_space_3` | 克隆现有图空间的 Schema。 |
| [USE](../3.ngql-guide/9.space-statements/2.use-space.md) | `USE ` | `USE space1` | 指定一个图空间,或切换到另一个图空间,将其作为后续查询的工作空间。 |
-| [SHOW SPACES](../3.ngql-guide/9.space-statements/3.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | 列出 NebulaGraph 示例中的所有图空间。 |
+| [SHOW SPACES](../3.ngql-guide/9.space-statements/3.show-spaces.md) | `SHOW SPACES` | `SHOW SPACES` | 列出{{nebula.name}}示例中的所有图空间。 |
| [DESCRIBE SPACE](../3.ngql-guide/9.space-statements/4.describe-space.md) | `DESC[RIBE] SPACE ` | `DESCRIBE SPACE basketballplayer` | 显示指定图空间的信息。 |
| [CLEAR SPACE](../3.ngql-guide/9.space-statements/6.clear-space.md) | `CLEAR SPACE [IF EXISTS] ` | 清空图空间中的点和边,但不会删除图空间本身以及其中的 Schema 信息。 |
| [DROP SPACE](../3.ngql-guide/9.space-statements/5.drop-space.md) | `DROP SPACE [IF EXISTS] ` | `DROP SPACE basketballplayer` | 删除指定图空间的所有内容。 |
@@ -371,7 +371,7 @@
| 语句 | 语法 | 示例 | 说明 |
| ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ |
-| [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md) | `INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...] VALUES : ([prop_value_list])` | `INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8)` | 在 NebulaGraph 实例的指定图空间中插入一个或多个点。 |
+| [INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md) | `INSERT VERTEX [IF NOT EXISTS] [tag_props, [tag_props] ...] VALUES : ([prop_value_list])` | `INSERT VERTEX t2 (name, age) VALUES "13":("n3", 12), "14":("n4", 8)` | 在{{nebula.name}}实例的指定图空间中插入一个或多个点。 |
| [DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md) | `DELETE VERTEX [, ...]` | `DELETE VERTEX "team1"` | 删除点,以及点关联的出边和入边。 |
| [UPDATE VERTEX](../3.ngql-guide/12.vertex-statements/2.update-vertex.md) | `UPDATE VERTEX ON SET [WHEN ] [YIELD