diff --git a/CONTRIBUTING.md b/CONTRIBUTING.md
index 487e2b5f9b..e67a307a20 100644
--- a/CONTRIBUTING.md
+++ b/CONTRIBUTING.md
@@ -6,11 +6,11 @@
可以从以下方面进行贡献:
-- 修正拼写错误或格式(标点,空格,缩进,代码块等)
-- 修正或更新不适当或过时的描述
-- 提交新文档
-- 提交或解决文档[issues](https://github.com/vesoft-inc/nebula-docs-cn/issues)
-- 审阅他人提交的 PR
+- 修正拼写错误或格式(标点,空格,缩进,代码块等)。
+- 修正或更新不适当或过时的描述。
+- 提交新文档。
+- 提交或解决文档 [issue][_issues]。
+- 审阅他人提交的 PR。
## 必须遵循的 Markdown 规范
@@ -22,5 +22,8 @@
可以选择以下方式进行贡献:
-- 在 [GitHub](https://github.com/vesoft-inc/nebula-docs-cn/issues) 提交 issue。
-- Fork 文档,在本地分支上更改或添加新内容,然后向主分支提交 PR。
+- 在 GitHub 提交 [issue][_issues]。
+- [Fork](https://github.com/vesoft-inc/nebula-docs-cn/fork) 文档,在本地分支上更改或添加新内容,然后向主分支提交 PR。
+
+
+[_issues]: https://github.com/vesoft-inc/nebula-docs-cn/issues
diff --git a/docs-2.0/1.introduction/1.what-is-nebula-graph.md b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
index ff79971438..6b8773df67 100644
--- a/docs-2.0/1.introduction/1.what-is-nebula-graph.md
+++ b/docs-2.0/1.introduction/1.what-is-nebula-graph.md
@@ -38,7 +38,7 @@ Nebula Graph支持严格的角色访问控制和LDAP(Lightweight Directory Acc
### 生态多样化
-Nebula Graph开放了越来越多的原生工具,例如[Nebula Graph Studio](https://github.com/vesoft-inc/nebula-studio)、[Nebula Console](https://github.com/vesoft-inc/nebula-console)、[Nebula Exchange](https://github.com/vesoft-inc/nebula-spark-utils/tree/v2.0.0/nebula-exchange)等,更多工具可以查看 [生态工具概览](../20.appendix/6.eco-tool-version.md)。
+Nebula Graph开放了越来越多的原生工具,例如[Nebula Graph Studio](https://github.com/vesoft-inc/nebula-studio)、[Nebula Console](https://github.com/vesoft-inc/nebula-console)、[Nebula Exchange](https://github.com/vesoft-inc/nebula-exchange)等,更多工具可以查看 [生态工具概览](../20.appendix/6.eco-tool-version.md)。
此外,Nebula Graph还具备与Spark、Flink、HBase等产品整合的能力,在这个充满挑战与机遇的时代,大大增强了自身的竞争力。
diff --git a/docs-2.0/1.introduction/2.data-model.md b/docs-2.0/1.introduction/2.data-model.md
index a84bc96131..c78e42b655 100644
--- a/docs-2.0/1.introduction/2.data-model.md
+++ b/docs-2.0/1.introduction/2.data-model.md
@@ -1,12 +1,12 @@
# 数据模型
-本文介绍Nebula Graph的数据模型。数据模型是一种组织数据并说明它们如何相互关联的模型(schema)。
+本文介绍Nebula Graph的数据模型。数据模型是一种组织数据并说明它们如何相互关联的模型(schema)。
## 数据模型
Nebula Graph数据模型使用6种基本的数据模型:
-- 图空间(Space)
+- 图空间(Space)
图空间用于隔离不同团队或者项目的数据。不同图空间的数据是相互隔离的,可以指定不同的存储副本数、权限、分片等。
@@ -14,7 +14,7 @@ Nebula Graph数据模型使用6种基本的数据模型:
点用来保存实体对象,特点如下:
- - 点是用点标识符(`VID`)标识的。`VID`在同一图空间中唯一。VID 是一个 int64, 或者 fixed_string(N)。
+ - 点是用点标识符(`VID`)标识的。`VID`在同一图空间中唯一。VID 是一个 int64,或者 fixed_string(N)。
- 点必须有至少一个Tag,也可以有多个Tag。但不能没有Tag。
- 边(Edge)
@@ -25,7 +25,7 @@ Nebula Graph数据模型使用6种基本的数据模型:
- 边是有方向的,不存在无向边。
- 四元组 `<起点VID、Edge type、边排序值(Rank)、终点VID>` 用于唯一标识一条边。边没有EID。
- 一条边有且仅有一个Edge type。
- - 一条边有且仅有一个rank。其为int64, 默认为0。
+ - 一条边有且仅有一个rank。其为int64,默认为0。
- 标签(Tag)
@@ -51,10 +51,10 @@ Nebula Graph使用有向属性图模型,指点和边构成的图,这些边
| 类型 | 名称 | 属性名(数据类型) | 说明 |
| :--- | :--- | :---| :--- |
-|Tag| **player** | name (string)
age (int) | 表示球员。 |
-|Tag| **team** | name (string) | 表示球队。 |
-|Edge type| **serve** | start_year (int)
end_year (int) | 表示球员的行为。
该行为将球员和球队联系起来,方向是从球员到球队。 |
-|Edge type| **follow** | degree(int) | 表示球员的行为。
该行为将两个球员联系起来,方向是从一个球员到另一个球员。 |
+|Tag| **player** | name (string)
age(int) | 表示球员。 |
+|Tag| **team** | name (string) | 表示球队。 |
+|Edge type| **serve** | start_year (int)
end_year (int) | 表示球员的行为。
该行为将球员和球队联系起来,方向是从球员到球队。 |
+|Edge type| **follow** | degree (int) | 表示球员的行为。
该行为将两个球员联系起来,方向是从一个球员到另一个球员。 |
!!! Note
@@ -62,6 +62,6 @@ Nebula Graph使用有向属性图模型,指点和边构成的图,这些边
!!! compatibility
- 由于 Nebula Graph {{ nebula.release }} 的数据模型中,允许存在"悬挂边",因此在增删时,用户需自行保证“一条边所对应的起点和终点”的存在性。详见[INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md), [DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md), [INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md), [DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md)。
+ 由于 Nebula Graph {{ nebula.release }} 的数据模型中,允许存在"悬挂边",因此在增删时,用户需自行保证“一条边所对应的起点和终点”的存在性。详见[INSERT VERTEX](../3.ngql-guide/12.vertex-statements/1.insert-vertex.md)、[DELETE VERTEX](../3.ngql-guide/12.vertex-statements/4.delete-vertex.md)、[INSERT EDGE](../3.ngql-guide/13.edge-statements/1.insert-edge.md)、[DELETE EDGE](../3.ngql-guide/13.edge-statements/4.delete-edge.md)。
不支持 openCypher 中的 MERGE 语句。
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
index eeb4187915..fc901892b1 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/3.graph-service.md
@@ -20,7 +20,7 @@ Graph 服务主要负责处理查询请求,包括解析查询语句、校验
Parser 模块收到请求后,通过 Flex(词法分析工具)和 Bison(语法分析工具)生成的词法语法解析器,将语句转换为抽象语法树(AST),在语法解析阶段会拦截不符合语法规则的语句。
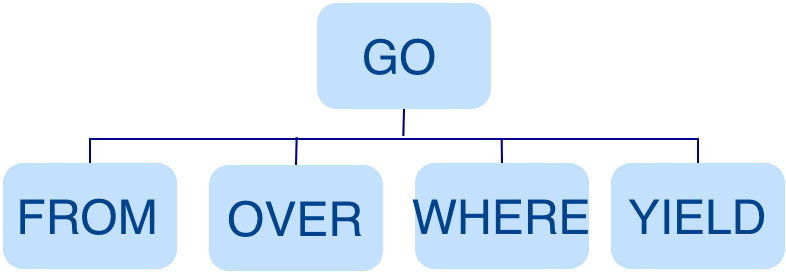
-例如`GO FROM "Tim" OVER like WHERE like.likeness > 8.0 YIELD like._dst`语句转换的 AST 如下。
+例如`GO FROM "Tim" OVER like WHERE properties(edge).likeness > 8.0 YIELD dst(edge)`语句转换的 AST 如下。
@@ -38,7 +38,7 @@ Validator 模块对生成的 AST 进行语义校验,主要包括:
校验引用的变量是否存在或者引用的属性是否属于变量。
- 例如语句`$var = GO FROM "Tim" OVER like YIELD like._dst AS ID; GO FROM $var.ID OVER serve YIELD serve._dst`,Validator 模块首先会检查变量 `var` 是否定义,其次再检查属性 `ID` 是否属于变量 `var`。
+ 例如语句`$var = GO FROM "Tim" OVER like YIELD dst(edge) AS ID; GO FROM $var.ID OVER serve YIELD dst(edge)`,Validator 模块首先会检查变量 `var` 是否定义,其次再检查属性 `ID` 是否属于变量 `var`。
- 校验类型推断
@@ -50,13 +50,13 @@ Validator 模块对生成的 AST 进行语义校验,主要包括:
查询语句中包含 `*` 时,校验子句时需要将 `*` 涉及的Schema都进行校验。
- 例如语句`GO FROM "Tim" OVER * YIELD like._dst, like.likeness, serve._dst`,校验`OVER`子句时需要校验所有的 Edge type,如果 Edge type 包含 `like`和`serve`,该语句会展开为`GO FROM "Tim" OVER like,serve YIELD like._dst, like.likeness, serve._dst`。
+ 例如语句`GO FROM "Tim" OVER * YIELD dst(edge), properties(edge).likeness, dst(edge)`,校验`OVER`子句时需要校验所有的 Edge type,如果 Edge type 包含 `like`和`serve`,该语句会展开为`GO FROM "Tim" OVER like,serve YIELD dst(edge), properties(edge).likeness, dst(edge)`。
- 校验输入输出
校验管道符(|)前后的一致性。
- 例如语句`GO FROM "Tim" OVER like YIELD like._dst AS ID | GO FROM $-.ID OVER serve YIELD serve._dst`,Validator 模块会校验 `$-.ID` 在管道符左侧是否已经定义。
+ 例如语句`GO FROM "Tim" OVER like YIELD dst(edge) AS ID | GO FROM $-.ID OVER serve YIELD dst(edge)`,Validator 模块会校验 `$-.ID` 在管道符左侧是否已经定义。
校验完成后,Validator 模块还会生成一个默认可执行,但是未进行优化的执行计划,存储在目录 `src/planner` 内。
diff --git a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
index c977a5cc27..b747dad8be 100644
--- a/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
+++ b/docs-2.0/1.introduction/3.nebula-graph-architecture/4.storage-service.md
@@ -142,6 +142,8 @@ EdgeA_Out和EdgeA_In以方向相反的两条边的形式存在于存储层,二
如EdgeA_Out和EdgeA_In一样,Nebula Graph冗余了存储每条边的信息,导致存储边所需的实际空间翻倍。因为边对应的Key占用的硬盘空间较小,但Value占用的空间与属性值的长度和数量成正比,所以,当边的属性值较大或数量较多时候,硬盘空间占用量会比较大。
+如果对边进行操作,为了保证两个键值对的最终一致性,可以开启[TOSS功能](../../5.configurations-and-logs/1.configurations/3.graph-config.md),开启后,会先在正向边所在的分片进行操作,然后在反向边所在分片进行操作,最后返回结果。
+
### 分片算法
分片策略采用**静态 Hash**的方式,即对点VID进行取模操作,同一个点的所有Tag、出边和入边信息都会存储到同一个分片,这种方式极大地提升了查询效率。
diff --git a/docs-2.0/1.introduction/3.vid.md b/docs-2.0/1.introduction/3.vid.md
index d3a6c399d5..f53a71e1d0 100644
--- a/docs-2.0/1.introduction/3.vid.md
+++ b/docs-2.0/1.introduction/3.vid.md
@@ -28,7 +28,7 @@
- 可以使用`LOOKUP`或者`MATCH`语句,来通过属性索引查找对应的VID;
-- 性能上,直接通过VID找到点的语句性能最高,例如`DELETE xxx WHERE id(xxx) == "player100"`, 或者`GO FROM "player100"`等语句。通过属性先查找VID,再进行图操作的性能会变差,例如`LOOKUP | GO FROM $-.ids`等语句,相比前者多了一次内存或硬盘的随机读(`LOOKUP`)以及一次序列化(`|`)。
+- 性能上,直接通过VID找到点的语句性能最高,例如`DELETE xxx WHERE id(xxx) == "player100"`,或者`GO FROM "player100"`等语句。通过属性先查找VID,再进行图操作的性能会变差,例如`LOOKUP | GO FROM $-.ids`等语句,相比前者多了一次内存或硬盘的随机读(`LOOKUP`)以及一次序列化(`|`)。
## VID生成建议
@@ -50,13 +50,13 @@ VID的数据类型必须在[创建图空间](../3.ngql-guide/9.space-statements/
## "查询起始点"(`start vid`)与全局扫描
-绝大多数情况下,Nebula Graph 的查询语句(`MATCH`, `GO`, `LOOKUP`)的执行计划,必须要通过一定方式找到查询起始点的 VID (`start vid`)。
+绝大多数情况下,Nebula Graph 的查询语句(`MATCH`、`GO`、`LOOKUP`)的执行计划,必须要通过一定方式找到查询起始点的 VID(`start vid`)。
定位 `start vid` 只有两种方式:
1. 例如 `GO FROM "player100" OVER` 是在语句中显式的指明 `start vid` 是 "player100";
-2. 例如, `LOOKUP ON player WHERE player.name == "Tony Parker"` 或者 `MATCH (v:player {name:"Tony Parker"}) `,是通过属性 `player.name` 的索引来定位到 `start vid`;
+2. 例如 `LOOKUP ON player WHERE player.name == "Tony Parker"` 或者 `MATCH (v:player {name:"Tony Parker"}) `,是通过属性 `player.name` 的索引来定位到 `start vid`;
!!! caution 不能在没有 `start vid` 情况下进行全局扫描;
diff --git a/docs-2.0/14.client/4.nebula-java-client.md b/docs-2.0/14.client/4.nebula-java-client.md
index 7ae1dcc909..a68f665e8e 100644
--- a/docs-2.0/14.client/4.nebula-java-client.md
+++ b/docs-2.0/14.client/4.nebula-java-client.md
@@ -101,7 +101,7 @@ try {
ResultSet resp = session.execute(insertEdges);
// query
- String query = "GO FROM \"Bob\" OVER like " + "YIELD $$.person.name, $$.person.age, like.likeness";
+ String query = "GO FROM \"Bob\" OVER like " + "YIELD properties($$).name, properties($$).age, properties(edge).likeness";
ResultSet resp = session.execute(query);
printResult(resp);
}finally {
diff --git a/docs-2.0/2.quick-start/4.nebula-graph-crud.md b/docs-2.0/2.quick-start/4.nebula-graph-crud.md
index ea78aab7b1..68346173c4 100644
--- a/docs-2.0/2.quick-start/4.nebula-graph-crud.md
+++ b/docs-2.0/2.quick-start/4.nebula-graph-crud.md
@@ -23,7 +23,7 @@
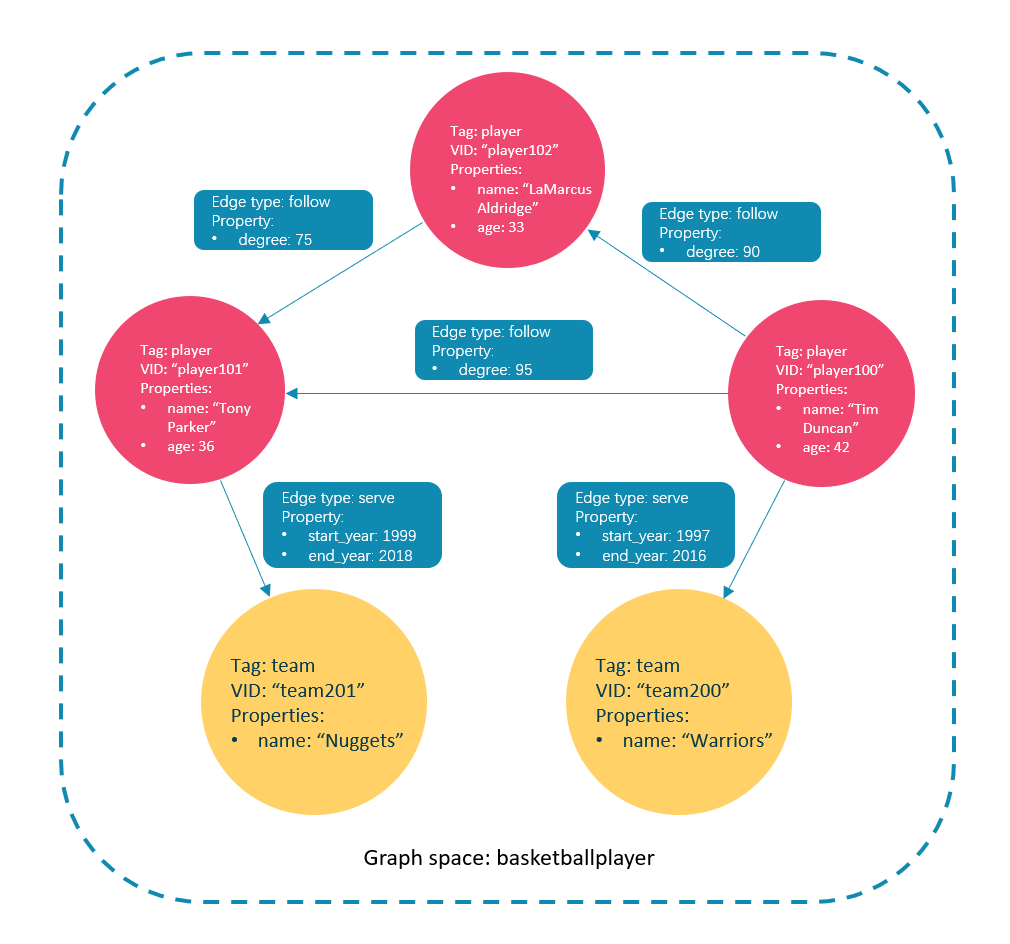
本文将使用下图的数据集演示基础操作的语法。
-
+
## 检查Nebula Graph集群的机器状态
@@ -37,21 +37,17 @@ nebula> SHOW HOSTS;
| Host | Port | Status | Leader count | Leader distribution | Partition distribution |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged0" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
-+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged1" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
-+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "storaged2" | 9779 | "ONLINE" | 0 | "No valid partition" | "No valid partition" |
-+-------------+-----------+-----------+--------------+----------------------+------------------------+
| "Total" | __EMPTY__ | __EMPTY__ | 0 | __EMPTY__ | __EMPTY__ |
+-------------+-----------+-----------+--------------+----------------------+------------------------+
-Got 4 rows (time spent 1061/2251 us)
```
在返回结果中,查看**Status**列,可以看到所有Storage服务都在线。
### 异步实现创建和修改
-!!! caution
+!!! caution
Nebula Graph中执行如下创建和修改操作,是异步实现的。要在**下一个**心跳周期之后才能生效;否则访问会报错。
@@ -81,7 +77,7 @@ Got 4 rows (time spent 1061/2251 us)
```ngql
CREATE SPACE [IF NOT EXISTS] (
- [partition_num = ,]
+ [partition_num = ,]
[replica_factor = ,]
vid_type = {FIXED_STRING() | INT64}
)
@@ -113,7 +109,6 @@ Got 4 rows (time spent 1061/2251 us)
```ngql
nebula> CREATE SPACE basketballplayer(partition_num=15, replica_factor=1, vid_type=fixed_string(30));
- Execution succeeded (time spent 2817/3280 us)
```
2. 执行命令`SHOW HOSTS`检查分片的分布情况,确保平衡分布。
@@ -124,14 +119,10 @@ Got 4 rows (time spent 1061/2251 us)
| Host | Port | Status | Leader count | Leader distribution | Partition distribution |
+-------------+-----------+-----------+--------------+----------------------------------+------------------------+
| "storaged0" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" |
- +-------------+-----------+-----------+--------------+----------------------------------+------------------------+
| "storaged1" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" |
- +-------------+-----------+-----------+--------------+----------------------------------+------------------------+
| "storaged2" | 9779 | "ONLINE" | 5 | "basketballplayer:5" | "basketballplayer:5" |
- +-------------+-----------+-----------+--------------+----------------------------------+------------------------+
| "Total" | | | 15 | "basketballplayer:15" | "basketballplayer:15" |
+-------------+-----------+-----------+--------------+----------------------------------+------------------------+
- Got 4 rows (time spent 1633/2867 us)
```
如果**Leader distribution**分布不均匀,请执行命令`BALANCE LEADER`重新分配。更多信息,请参见[Storage负载均衡](../8.service-tuning/load-balance.md)。
@@ -140,7 +131,6 @@ Got 4 rows (time spent 1061/2251 us)
```ngql
nebula[(none)]> USE basketballplayer;
- Execution succeeded (time spent 1229/2318 us)
```
用户可以执行命令`SHOW SPACES`查看创建的图空间。
@@ -152,7 +142,6 @@ Got 4 rows (time spent 1061/2251 us)
+--------------------+
| "basketballplayer" |
+--------------------+
- Got 1 rows (time spent 977/2000 us)
```
## 创建Tag和Edge type
@@ -180,16 +169,12 @@ CREATE {TAG | EDGE} { | }(
```ngql
nebula> CREATE TAG player(name string, age int);
-Execution succeeded (time spent 20708/22071 us)
nebula> CREATE TAG team(name string);
-Execution succeeded (time spent 5643/6810 us)
nebula> CREATE EDGE follow(degree int);
-Execution succeeded (time spent 12665/13934 us)
nebula> CREATE EDGE serve(start_year int, end_year int);
-Execution succeeded (time spent 5858/6870 us)
```
## 插入点和边
@@ -225,32 +210,24 @@ Execution succeeded (time spent 5858/6870 us)
```ngql
nebula> INSERT VERTEX player(name, age) VALUES "player100":("Tim Duncan", 42);
- Execution succeeded (time spent 28196/30896 us)
nebula> INSERT VERTEX player(name, age) VALUES "player101":("Tony Parker", 36);
- Execution succeeded (time spent 2708/3834 us)
nebula> INSERT VERTEX player(name, age) VALUES "player102":("LaMarcus Aldridge", 33);
- Execution succeeded (time spent 1945/3294 us)
- nebula> INSERT VERTEX team(name) VALUES "team200":("Warriors"), "team201":("Nuggets");
- Execution succeeded (time spent 2269/3310 us)
+ nebula> INSERT VERTEX team(name) VALUES "team203":("Trail Blazers"), "team204":("Spurs");
```
- 插入代表球员和球队之间关系的边。
```ngql
- nebula> INSERT EDGE follow(degree) VALUES "player100" -> "player101":(95);
- Execution succeeded (time spent 3362/4542 us)
+ nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player100":(95);
- nebula> INSERT EDGE follow(degree) VALUES "player100" -> "player102":(90);
- Execution succeeded (time spent 2974/4274 us)
+ nebula> INSERT EDGE follow(degree) VALUES "player101" -> "player102":(90);
- nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player101":(75);
- Execution succeeded (time spent 1891/3096 us)
+ nebula> INSERT EDGE follow(degree) VALUES "player102" -> "player100":(75);
- nebula> INSERT EDGE serve(start_year, end_year) VALUES "player100" -> "team200":(1997, 2016), "player101" -> "team201":(1999, 2018);
- Execution succeeded (time spent 6064/7104 us)
+ nebula> INSERT EDGE serve(start_year, end_year) VALUES "player101" -> "team204":(1999, 2018),"player102" -> "team203":(2006, 2015);
```
## 查询数据
@@ -269,9 +246,13 @@ Execution succeeded (time spent 5858/6870 us)
```ngql
GO [[ TO] STEPS ] FROM
- OVER [REVERSELY] [BIDIRECT]
- [WHERE [AND | OR expression ...])]
- YIELD [DISTINCT] ;
+ OVER [{REVERSELY | BIDIRECT}]
+ [ WHERE ]
+ [YIELD [DISTINCT] ]
+ [{SAMPLE | LIMIT }]
+ [| GROUP BY {col_name | expr | position} YIELD ]
+ [| ORDER BY [{ASC | DESC}]]
+ [| LIMIT [,] ];
```
- `FETCH`
@@ -279,24 +260,24 @@ Execution succeeded (time spent 5858/6870 us)
- 查询Tag属性
```ngql
- FETCH PROP ON { | | *}
- [YIELD [DISTINCT] ];
+ FETCH PROP ON {[, tag_name ...] | *}
+ [, vid ...]
+ [YIELD [AS ]];
```
- 查询边属性
```ngql
- FETCH PROP ON -> [@]
- [, -> ...]
- [YIELD [DISTINCT] ];
+ FETCH PROP ON -> [@] [, -> ...]
+ [YIELD