[Tuning] Results are GPU-number and batch-size dependent #444
Comments
|
My experience is exactly the same. Lower batch size (either nominally lower with the same number of GPUs or effectively lower because of smaller number of GPUs) results in worse results, even if I train long enough to compensate for the lower batch. |
|
@vince62s you mentioned that the gap is never closed even if you wait to compensate the batch size difference. Have you been able to compensate by decreasing learning rate when decreasing batch size ? As suggested here, maybe it would make sense to define the learning rate by multiplying it by |
|
not sure, because adam / noam is supposed to be adaptive. all the tests I did (changing the lr) were not better. tensor2tensor/tensor2tensor/utils/optimize.py Line 106 in e3cd447 here the lr is divided by the sqrt of nb of gpu https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/utils/model_builder.py#L219 |
|
I have nice TensorBoard BLEU curves illustrating that training with more GPUs converges faster to higher BLEU (which is what everyone expects). When answering the question whether N GPUs are N times faster (or less or more, which is what this issue is about), it depends whether we plot steps or hours on the x axis:
I am still waiting whether 1GPU can achieve as good results as 8GPU, after long enough time (several weeks). So the main question of this issue still remains unanswered. All GPUs are of the exactly same type (1080 Ti). Of course, these results should be still taken with a grain of salt - it is just one testset (newstest2013), different testsets may give (slightly) different results. |


|
And more post (this time with base models instead of big) showing that you should always use the highest possible batch_size (comparing batch size 1500, 3000 and 4500, all three trained just on one GPU): |

|
Some results with T2T 1.3.2:
I'm running this on 4 P100 GPUs - As far as I understand the code On news-test2014 (with averaging): This is not very close to the 28.2 BLEU reported here. After reading vince62s post, maybe the t2t authors used worker replicas rather than |
|
I think you might be correct. I realize my above comment was misleading since I confused replicas and gpu. EDIT: actually not exactly, because if the "default" values are tuned for 8 GPU / 1 replica, then we would need to make a prorata for learning_rate and warmup_steps. |
|
Second thought (actually maybe 1000th one). |
|
Well, I think if it was calibrated for 1 replica we would be fine since dividing the learning rate or multiplying warmup_steps by worker_replicas would have no effect. My current thesis is that the default parameters are tuned for 8 replica, each with 1 GPU. In this case we need to decrease the learning rate and increase warmup steps in order to simulate the setting on a single machine with multiple GPUs. I am trying that right now... |
|
Paper says one machine, 8 GPUs. |
|
You are right.. that means I'm still deeply confused. @lukaszkaiser the exact training command for replicating the 28.2 BLEU would be very helpful. |
|
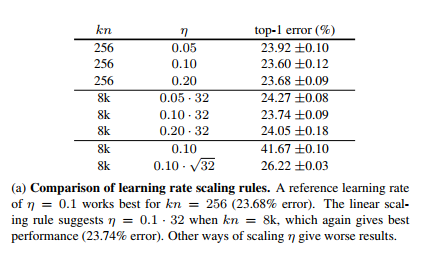
If the gpu memory is not sufficient for the ideal batch size of 4096, @martinpopel suggested in #446 to use
I adjusted
|


|
As I have commented elsewhere, I think that in the Attention is all you need paper they use batch_size=3072 (which multiplied by 8 gives the approx. 25000 tokens per batch reported in the paper). However, the number 3072 never appeared in the source code of transformer.py. |
|
For the best base model so far (28.2) I used 8 gpus with the default transformer_base. Some recent papers suggested scaling learning rate linearly or square-root-like with batch size, so according to them if we go down from 8 to 2 gpus we should scale learning rate down by 2x or 4x. Martin: could you try these? I'll try to reproduce the above results to make sure we understand it better. If it's indeed the case, then we should probably add automatic LR scaling... |
|
I would have said the contrary, ie the more GPUs the smaller LR since the batch size isx times bigger. |
|
First a note: The graphs I posted above are all on the Now I did some experiments with learning rate (and 1 GPU and a fixed batch size):
|
|
My results from the very first post were with 1.2.9 if I recall well. |
|
@martinpopel Have you had success with high learning rates? Increased learning rates seem to make up for lower batch size. I'm currently training a transformer_big model with a LR of 0,8 (warmup=32k) on 4 GPUs each with a batch size of 2000. So far this provides me with the greatest loss on 4x1080TIs. |
|
@mehmedes: No success with higher learning rates. I've tried lr=0.5 (and warmup 32k) and it is still about the same as other learning rates (except for lr=0.01 which is clearly worse). Then I tried lr=1 and it diverged (BLEU=0). |
|
@mehmedes did you through the end fo your training, how did it go ? |
|
My training with LR=0.8 is still running. My loss curve hasn't flattened out yet, compared to previous models (see above) where I divided the LR by the ideal / available batch size ratio instead of multiplying it.
|

|
@martinpopel did you test LR=0.5 on a single GPU or on multiple? |
|
@mehmedes: All my experiments with learning rate so far are on a single GPU. As I think about it I am afraid there is no easy way (one magical formula) how to exactly compensate for a lower batch size (caused e.g. by less GPUs) with a learning rate scaling: |
|
@martinpopel yes, that's true. What I find curious about T2T is that the LR impact behaves inverserly proportional. So far, I've made the experice in T2T that if I decrease the batch size by Any ideas, why? |
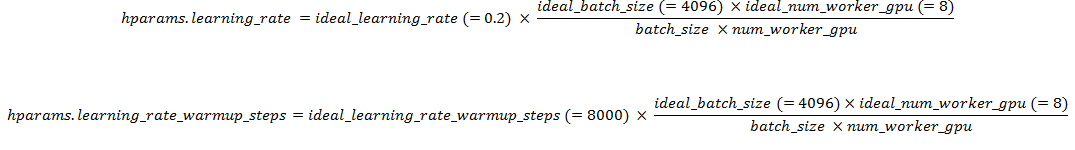
|
@fstahlberg I did a quick experiment. |
|
@vince62s you may also need to increase The params I use for batch_size=6000 are: And during data generation you also need to use _packed problems with max_length=100: |
|
Ok here are my last results on WMT ENDE32k Big, Adafactor, batchsize 5000, 4 GPU These results are still under the paper Base 100k steps 27.3, Big 300k steps 28.4 I would really love to know if you guys at GG Brain @lukaszkaiser @rsepassi still replicate |
|
Hi all, can i double check the scores you guys produced in your experiments? Are they with t2t-bleu or sacreBLEU (with or without --tok intl)? Thanks! |
|
Talking for myself, I always report BLEU from mteval13a.pl without intl tok, and this is the same as multi-bleu-detok.perl |
|
I report BLEU with |
|
Thanks @vince62s and @martinpopel for your replies. |
|
Just use sacreBleu without -tok intl and without -lc and you will be comparable I think. |
|
@martinpopel : I saw you draw this picture (BLEU_uncased) in tensorboard: https://user-images.githubusercontent.com/724617/33940325-d217ba74-e00e-11e7-9996-5132b62d51dc.png |
|
@DC-Swind: approx_bleu is computed on the dev set, but using the internal subword tokenization, so it is not replicable (and it is not reliable because of using gold reference last word). I use |
|
@martinpopel : There is no event file was generated by |
|
@DC-Swind: t2t-bleu creates the event file if called with proper parameters, see https://github.com/tensorflow/tensor2tensor/blob/master/tensor2tensor/bin/t2t_bleu.py#L27-L53 |
|
Is there anyone who tried greater batch sizes than recommended to see whether it is possible to gain better performance than in the paper? With accumulation of gradients, one can arbitrarily increase the batch size. Was my question already answered before? |
|
The effect of batch size is discussed in this paper. The maximum batch size depends on the GPU memory (and optimizer - with Adafactor we can afford bigger batches, see Table 2 of the paper). The conclusions are: "for the BASE model, a higher batch size gives better results, although with diminishing returns. With the BIG model, we see quite different results."
Yes, I had this idea as well: accumulate gradients from N batches and do just one update of weights afterwards, simulating N times bigger batch (or N times more GPUs). I think it is worth trying, but someone would need to implement it first. There will be a question of how to compute the number of steps (which influences the learning rate schedule). However, I am not sure super-big batches will improve the convergence speed. Still, it may be useful for simulating multi-GPU experiments on a single GPU (so that after buying more GPUs, I will already know what are the optimal hyperparams). |
|
Thanks for your response. As you said, I'm simulating such a situation (for language modeling with Transformer) with a single GPU at the expense of time per iteration (for this reason, achieving convergence isn't realistic). I hope someone will figure out how much performance gain it is possible with a huge batch size with multiple GPUs. |
|
We have an upcoming ACL paper where we use this idea for neural machine translation with target side syntax. It turns out that using large batch sizes is even more important when generating long output sequences. I'll post a link to arXiv when ready. There is also a t2t implementation: https://github.com/fstahlberg/tensor2tensor/blob/master/tensor2tensor/utils/largebatch_optimizer.py However, this is still t2t 1.3.1. I haven't had time to polish the code and update t2t to see if it still works. But I can do that and make a PR. Regarding the original question: From my experience it is a good idea to try to match the number_of_gpus*batch_size setup, and n can compensate for reducing either of these values. I haven't seen gains from even larger batches. |
|
@fstahlberg I really appreciate your feedback, and I'm looking forward to reading your paper. Generating a long sequence (though not for translation) is something I'm currently working on, so that's very beneficial to learn about. Maybe increasing the batch size enhances the generalizability of text transduction model, which alleviates the issue of exposure bias in generating long sequences? I'm eager to hear from you about any of these as well as bit more relevant details about your paper. |
|
does someone have a recent comparison between 4 and 8 GPU for the same set of hparam |
|
This recent paper achieved 5x speedup on translation using Transformer with various techniques, including batch size of 400k and mixed precision: Scaling Neural Machine Translation. Furthermore, it achieved BLEU of 29.3 and 43.2 on En-De and En-Fr, respectively. For those of us who don't have many GPUs, the use of diet variables of utils/diet.py would be helpful to increase the batch size if that thing works. Has anybody tried diet variables? Does it really work as expected? |
|
@AranKomat: Please note that in the aforementioned paper one crucial factor in the speed up is switching from single to half precision and that the hardware is V100, which achieves 14TFLOPs in single precision and 112TFLOPs!! in half precision. The P100, which was used in the T2T paper, would "only" increase from 9TFLOPs to 18TFLOPs when switching to half precision. The hardware should also be considered when evaluating the speed up. |
|
@mehmedes I didn't notice that there was such as huge difference between V100 and P100 in terms of half precision TFLOPS! But I believe Table 1 accounts for the difference by citing the BLEU and speed with V100. Maybe using diet variables wouldn't benefit much in this case if half precision is already used. |
|
Hi @fstahlberg Has your paper been published?
|
|
Hi @xerothermic yes, we have used it in https://www.aclweb.org/anthology/P18-2051 for syntax and in https://www.aclweb.org/anthology/W18-6427 for a WMT18 submission. |
@lukaszkaiser
This is to illustrate what I have discussed on gitter.
Working with WMT EN-FR, I have observed the following.

You can replicate the paper results with "transformer -base" with 4 GPU.
The BLEUapprox looks like this: (batch-size 4096, warmup step 6000)
If I do the same on 3 GPU (batch size 4096 warmup step 8000), taking into account that I need to compare step 120K of 4GPU run vs 160K of the 3GPU run, I get this with a clear offset of 1 BLEU point.
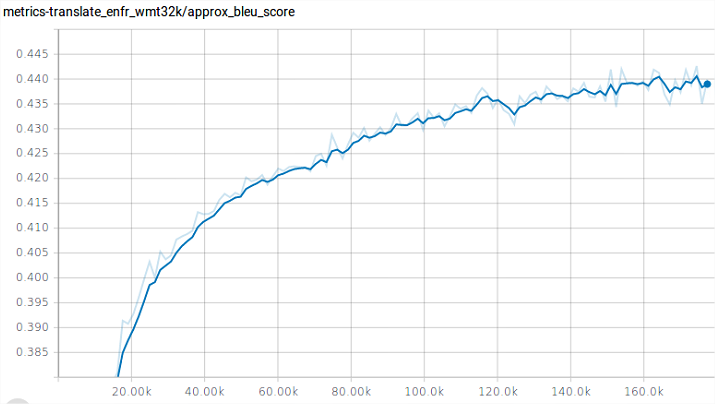
The gap is never closed if we wait.
If I do the same on 2GPU, it's even lower, 1GPU same.
Also, I observed that it is very dependent on the batch size.
For instance if you lower to 3072 you don't get the same as with 4096
With 2048 even lower.
This makes impossible to replicate the Transformer BIG results since you can only fit a batch size of 2048 even on a GTX1080ti.
Hope this helps for better tuning.
The text was updated successfully, but these errors were encountered: