-
Notifications
You must be signed in to change notification settings - Fork 20
/
main.py
271 lines (217 loc) · 8.29 KB
/
main.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
# -*- coding: utf-8 -*-
import argparse
import os
import re
import markdown
from feedgen.feed import FeedGenerator
from github import Github
from lxml.etree import CDATA
from marko.ext.gfm import gfm as marko
MD_HEAD = """**<p align="center">[Leeyom's Blog](https://blog.leeyom.top)</p>**
====
**<p align="center">用于记录一些幼稚的想法和脑残的瞬间</p>**
[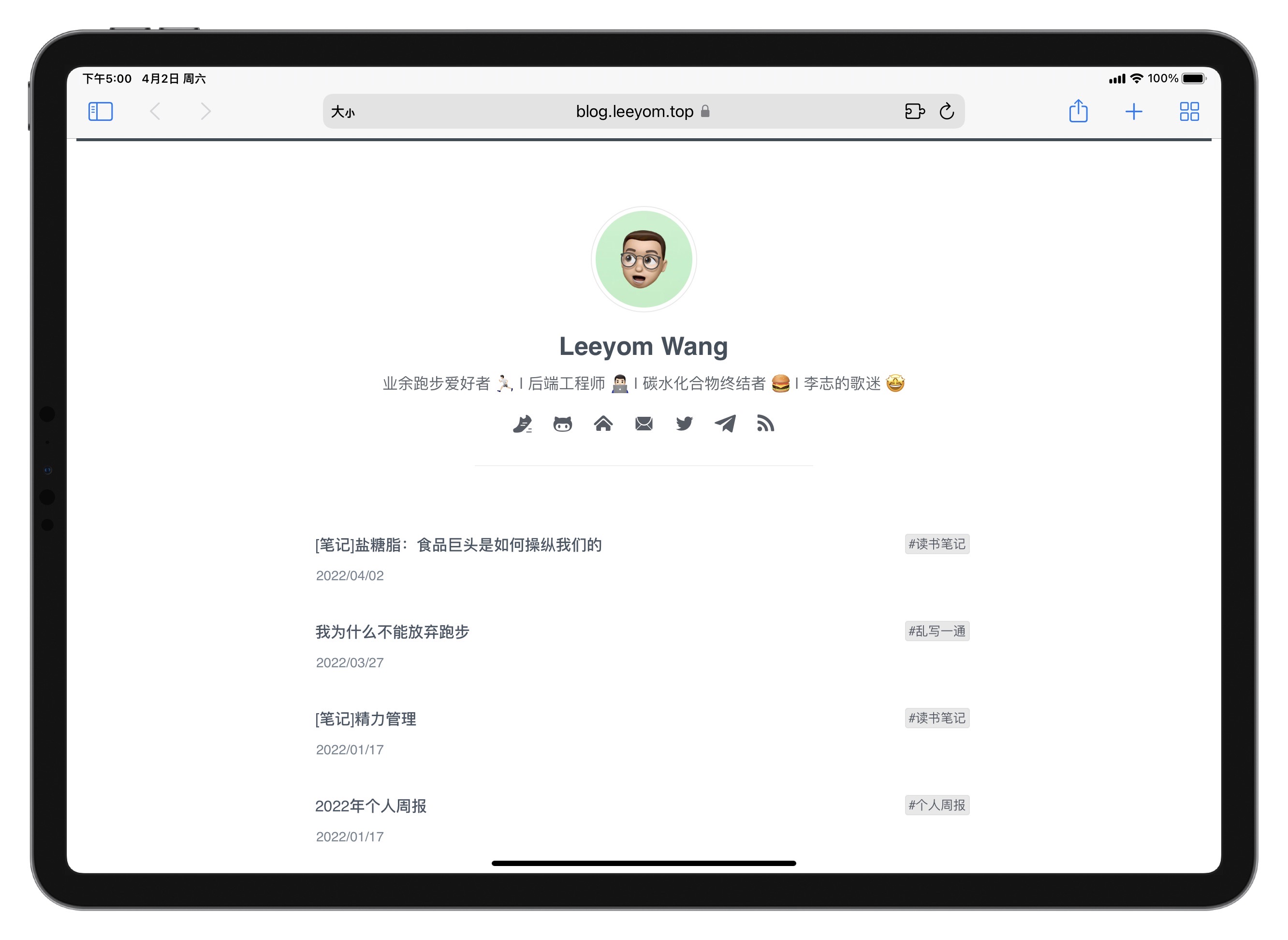](https://blog.leeyom.top)
## 联系方式
- Twitter:[@super_leeyom](https://twitter.com/super_leeyom)
- Telegram:[@super_leeyom](https://t.me/super_leeyom)
- Email:[[email protected]](mailto:[email protected])
- Blog:[https://blog.leeyom.top](https://blog.leeyom.top)
- RSS:[RSS Feed](https://raw.githubusercontent.com/{repo_name}/master/feed.xml)
"""
BACKUP_DIR = "backup"
ANCHOR_NUMBER = 5
TOP_ISSUES_LABELS = ["Top"]
TODO_ISSUES_LABELS = ["TODO"]
IGNORE_LABELS = TOP_ISSUES_LABELS + TODO_ISSUES_LABELS
def get_me(user):
return user.get_user().login
def is_me(issue, me):
return issue.user.login == me
# help to covert xml vaild string
def _valid_xml_char_ordinal(c):
codepoint = ord(c)
# conditions ordered by presumed frequency
return (
0x20 <= codepoint <= 0xD7FF
or codepoint in (0x9, 0xA, 0xD)
or 0xE000 <= codepoint <= 0xFFFD
or 0x10000 <= codepoint <= 0x10FFFF
)
def format_time(time):
return str(time)[:10]
def login(token):
return Github(token)
def get_repo(user: Github, repo: str):
return user.get_repo(repo)
def parse_TODO(issue):
body = issue.body.splitlines()
todo_undone = [l for l in body if l.startswith("- [ ] ")]
todo_done = [l for l in body if l.startswith("- [x] ")]
# just add info all done
if not todo_undone:
return f"[{issue.title}]({issue.html_url}) all done", []
return (
f"[{issue.title}]({issue.html_url})--{len(todo_undone)} jobs to do--{len(todo_done)} jobs done",
todo_done + todo_undone,
)
def get_top_issues(repo):
return repo.get_issues(labels=TOP_ISSUES_LABELS)
def get_todo_issues(repo):
return repo.get_issues(labels=TODO_ISSUES_LABELS)
def get_repo_labels(repo):
return [l for l in repo.get_labels()]
def get_issues_from_label(repo, label):
return repo.get_issues(labels=(label,))
def add_issue_info(issue, md):
time = format_time(issue.created_at)
md.write(f"- [{issue.title}]({issue.html_url})--{time}\n")
def add_md_todo(repo, md, me):
todo_issues = list(get_todo_issues(repo))
if not TODO_ISSUES_LABELS or not todo_issues:
return
with open(md, "a+", encoding="utf-8") as md:
md.write("## TODO\n")
for issue in todo_issues:
if is_me(issue, me):
todo_title, todo_list = parse_TODO(issue)
md.write("TODO list from " + todo_title + "\n")
for t in todo_list:
md.write(t + "\n")
# new line
md.write("\n")
def add_md_top(repo, md, me):
top_issues = list(get_top_issues(repo))
if not TOP_ISSUES_LABELS or not top_issues:
return
with open(md, "a+", encoding="utf-8") as md:
md.write("## 置顶文章\n")
for issue in top_issues:
if is_me(issue, me):
add_issue_info(issue, md)
def add_md_recent(repo, md, me, limit=5):
count = 0
with open(md, "a+", encoding="utf-8") as md:
# one the issue that only one issue and delete (pyGitHub raise an exception)
try:
md.write("## 最近更新\n")
for issue in repo.get_issues():
if is_me(issue, me):
add_issue_info(issue, md)
count += 1
if count >= limit:
break
except Exception as e:
print(str(e))
def add_md_header(md, repo_name):
with open(md, "w", encoding="utf-8") as md:
md.write(MD_HEAD.format(repo_name=repo_name))
md.write("\n")
def add_md_label(repo, md, me):
labels = get_repo_labels(repo)
# sort lables by description info if it exists, otherwise sort by name,
# for example, we can let the description start with a number (1#Java, 2#Docker, 3#K8s, etc.)
labels = sorted(
labels,
key=lambda x: (
x.description is None,
x.description == "",
x.description,
x.name,
),
)
with open(md, "a+", encoding="utf-8") as md:
for label in labels:
# we don't need add top label again
if label.name in IGNORE_LABELS:
continue
issues = get_issues_from_label(repo, label)
if issues.totalCount:
md.write("## " + label.name + "\n")
issues = sorted(issues, key=lambda x: x.created_at, reverse=True)
i = 0
for issue in issues:
if not issue:
continue
if is_me(issue, me):
if i == ANCHOR_NUMBER:
md.write("<details><summary>显示更多</summary>\n")
md.write("\n")
add_issue_info(issue, md)
i += 1
if i > ANCHOR_NUMBER:
md.write("</details>\n")
md.write("\n")
def get_to_generate_issues(repo, dir_name, issue_number=None):
md_files = os.listdir(dir_name)
generated_issues_numbers = [
int(i.split("_")[0]) for i in md_files if i.split("_")[0].isdigit()
]
to_generate_issues = [
i
for i in list(repo.get_issues())
if int(i.number) not in generated_issues_numbers
]
if issue_number:
to_generate_issues.append(repo.get_issue(int(issue_number)))
return to_generate_issues
def generate_rss_feed(repo, filename, me):
generator = FeedGenerator()
generator.id(repo.html_url)
generator.title(f"RSS feed of {repo.owner.login}'s {repo.name}")
generator.author(
{"name": os.getenv("GITHUB_NAME"), "email": os.getenv("GITHUB_EMAIL")}
)
generator.link(href=repo.html_url)
generator.link(
href=f"https://raw.githubusercontent.com/{repo.full_name}/master/{filename}",
rel="self",
)
for issue in repo.get_issues():
if not issue.body or not is_me(issue, me) or issue.pull_request:
continue
item = generator.add_entry(order="append")
item.id(issue.html_url)
item.link(href=issue.html_url)
item.title(issue.title)
item.published(issue.created_at.strftime("%Y-%m-%dT%H:%M:%SZ"))
for label in issue.labels:
item.category({"term": label.name})
body = "".join(c for c in issue.body if _valid_xml_char_ordinal(c))
item.content(CDATA(marko.convert(body)), type="html")
generator.atom_file(filename)
def main(token, repo_name, issue_number=None, dir_name=BACKUP_DIR):
user = login(token)
me = get_me(user)
repo = get_repo(user, repo_name)
# add to readme one by one, change order here
add_md_header("README.md", repo_name)
for func in [add_md_top, add_md_recent, add_md_label, add_md_todo]:
func(repo, "README.md", me)
generate_rss_feed(repo, "feed.xml", me)
to_generate_issues = get_to_generate_issues(repo, dir_name, issue_number)
# save md files to backup folder
for issue in to_generate_issues:
save_issue(issue, me, dir_name)
def save_issue(issue, me, dir_name=BACKUP_DIR):
md_name = os.path.join(
dir_name, f"{issue.number}_{issue.title.replace('/', '-').replace(' ', '.')}.md"
)
with open(md_name, "w") as f:
f.write(f"# [{issue.title}]({issue.html_url})\n\n")
f.write(issue.body or "")
if issue.comments:
for c in issue.get_comments():
if is_me(c, me):
f.write("\n\n---\n\n")
f.write(c.body or "")
if __name__ == "__main__":
if not os.path.exists(BACKUP_DIR):
os.mkdir(BACKUP_DIR)
parser = argparse.ArgumentParser()
parser.add_argument("github_token", help="github_token")
parser.add_argument("repo_name", help="repo_name")
parser.add_argument(
"--issue_number", help="issue_number", default=None, required=False
)
options = parser.parse_args()
main(options.github_token, options.repo_name, options.issue_number)