1 Introduction
2 Linked Open Data
2.1 The Semantic Web
2.2 Open Data and Linked Data
2.3 Graph Database vs. Relational Database
2.4 Triple Storage and Resource Description Framework
2.5 RDF Vocabulary
2.6 RDF Serialization
2.7 RDF Data Cube model
2.8 SPARQL and how to query Linked Data
2.9 SPARQL vs. SQL
3 Data Models
3.1 The SDMX Standard
3.2 Concepts of the Historic Data
3.3 Concepts of the RDF Data Cube
3.4 Other important Concepts
4 SPARQL
4.1 SPARQL in this notebook
4.2 Example Query: all DataSets
4.2.1 Explanation
4.3 Example Query: the first 100 Triples
4.3.1 Explanation
4.4 Example Query: total number of Triples
4.4.1 Explanation
4.5 Example Query: number of Observations per DataSet
4.5.1 Explanation
4.6 Example Query: filter with regular expressions
4.6.1 Explanation
4.7 Example Query: Kennzahlen and measures
4.7.1 Explanation
4.8 Example Query: Groups and dimensions
4.8.1 Explanation
4.9 Example Query: DataSets of specific dimensions or topics
4.9.1 Explanation
4.9.2 Specific topics
4.9.3 Explanation
4.10 Example Query: Metadata and attributes
4.10.1 Explanation
4.11 Example Query: Groupcodes
4.11.1 Explanation
4.12 Example Query: Hierarchy of Groupcodes
4.12.1 Explanation
4.12.2 Hierarchy of topics
4.12.3 Explanation
4.13 Example Query: spatial Hierarchies
4.13.1 Explanation
4.14 Example Query: links to other Databases
4.14.1 Explanation
4.15 Example Query: Slices of DataSets
4.15.1 Explanation
4.16 Example Query: Shapes
4.16.1 Explanation
4.17 Example Query: Metadata of Observations
4.17.1 Explanation
4.18 Example Query: more Metadata of Observations
4.18.1 Explanation
4.19 Example Query: relations of a DataSet
4.19.1 Explanation
4.20 Example Query: relations of an Observation
4.20.1 Explanation
4.21 Example Query: evolution of the plot area without forest
4.21.1 Explanation
4.22 Example Query: females of swiss origin in 2016
4.22.1 Explanation
4.23 Example Query: evolution of the number of unemployed over time
4.23.1 Explanation
4.24 Example Query: conjunction of Kennzahlen
4.24.1 Explanation
4.25 Example Query: differences in population numbers
4.25.1 Explanation
4.26 Example Query: GeoSPARQL
4.26.1 Explanation
6 SPARQL in R
6.1 Plotting in R
7 SPARQL in Python
7.1 Plotting in Python
8 SSZVIS
9 OpenSource and Repositories
Statistik Stadt Zürich (SSZ) is replacing its statistical yearbook with a web-based solution. The content can be accessed directly or programmatically:
- through a REST-interface
- through a SPARQL-interface
The purpose of this notebook is to give an overview of the available data and describe how interested parties are able to query it with SPARQL.
The project page is the home base and provides links to Github and all other resources.
The data is provided in the form of Linked Open Statistical Data (LOSD), or more precisely, in the form of a graph database - also called triplestore - with the underlying structure being a RDF Data Cube. The data is queried by means of the SPARQL Query Language (or SPARQL in short). If you want to get a first impression of querying RDF Data Cubes via SPARQL, check out this screencast.
- This Linked Data course offers an introduction for users new to graph databases and triplestores (in contrast to relational databases)
- The RDF Data Cube model in particular, is introduced in section 3.3
Linked data is a topic far too big to be completely covered here. Likewise, a complete SPARQL tutorial would go far beyond the scope of this document (and was already done plenty of times). However, the most important concepts shall be mentioned and linked with their specifications or other useful sources.
The Web started as a collection of documents published online, accessible at Web locations identified by a URL. These documents often contain data about real world resources which are mainly human readable and cannot be understood by machines.
The so called Semantic Web is about enabling the access to this data, by making it available in machine readable formats (JSON, Turtle, XML, etc.) and connecting it by using Uniform Resource Identifiers (URIs), thus enabling people and machines to collect the data, and put it together to do all kinds of things with it (so far as the license permits it).
- The European Commission provides a nice presentation on the topic
"Open means anyone can freely access, use, modify, and share for any purpose (subject, at most, to requirements that preserve provenance and openness)." OpenDefinition.org
"Linked data is a set of design principles for sharing machine-readable data on the Web for use by public administrations, business and citizens." EC ISA
Tim Berners Lee proposed the following four design principles for Linked Data:
- Use Uniform Resource Identifiers (URIs) as names for things.
- Use HTTP URIs so that people can look up those names.
- When someone looks up an URI, provide useful information, using the standards (RDF, SPARQL etc.).
- Include links to other URIs so that they can discover more things.
The quality of Linked Open Data can be assessed with the help of the 5-star scheme, also proposed by Tim Berners Lee:
- Make your stuff available on the Web (whatever format) under an open license.
- Make it available as structured data (e.g., Excel instead of image scan of a table)
- Use non-proprietary formats (e.g., CSV instead of Excel)
- Use URIs to denote things, so that people can point at your stuff
- Link your data to other data to provide context
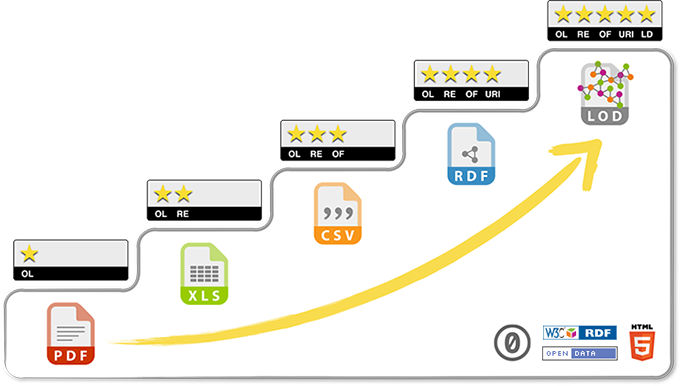
The Open Data projects of SSZ reached a solid three stars until now...
Linked Open Statistics Data (LOSD) will reach the top and earn its five stars!
An example of the 5-star qualities is the link between LOSD and Wikipedia:

Certain LOSData has a property <sameAs> - with a Wikidata entity as Resource URI - that establishes a link to the Wikidata store (more on <sameAs> shortly).
- See this section of the Linked Data crash course
- or this RDF/OWL lecture for a more detailed introduction to the subject
- This site provides an interactive graph of worldwide LOData with a plethora of datasets and SPARQL endpoints
Data contained in the Semantic Web is stored in directed labelled graphs to show not only the data itself, but also properties of the data and its relation to other relevant data. The following figure (click "view image" for higher resolution) shows a graph constructed from a single statistical measurement (a so called Observation) of our LOSData:

For our purposes a graph has nodes - with either a resource URI or a literal value - and directed relationships. A resource URI represents a link or "address" to another node whereas a literal value is just a String value, for example. Even the relations are defined through URIs! If you are familiar with the concept of Namespaces, you will certainly understand why this is so important. Section 2.5 about Vocabularies and Ontologies will make it even clearer.
In a graph there is no concept of roots or hierarchies. A graph consists of resources related to other resources, with no single resource having any particular intrinsic importance over another. So how do we express such a construct in de facto hierarchical form, let's say XML? Before we get to the answer (the Resource Description Framework or RDF), let's examine an enlarged section of the example above:

This subgraph is fairly intuitive and can be summarized by the following statements:
dataset "AST-RAUM-ZEIT-BTA" has the label "Arbeitsstätten nach Betriebsart, Raum, Zeit" (translates to "number of Businesses depending on the Business sector, Area, Date)
dataset "AST-RAUM-ZEIT-BTA" is of type "DataSet"
data of the dataset "AST-RAUM-ZEIT-BTA" is measured in units of "arbeitsstaette" (translates to "Business"; literally "working place")
These statements reveal the essence of graph description and RDF:
- Graphs are expressed in a set of triple statements
- Every statement has a subject, predicate and object
- subjects and objects represent nodes whereas the predicates represent relationships
Hence the name "triplestore" for graph/RDF databases.
- RDF Specification
- See the aforementioned RDF/OWL lecture for one of the best introductions to the subject
- URIs for the designation, RDF for the description and SPARQL for the querying of data
A Uniform Resource Identifier (URI) is a compact sequence of characters that identifies an abstract or physical resource! Recall Namespaces..
RDF is graphical formalism for expressing data models about "something" (resources) using statements expressed as triples
You can already see plenty of URIs in the graph example above.. URI references may be either absolute or relative. URIs often have fragmentIDs and are of the form <http://www.somedomain.com/some/path/to/file#fragmentID>. A corresponding relative URI is for example sd:fragmentID (more on that later).
RDF breaks every piece of information down in triples:
- Subject: a resource, which may be identified with an URI
- Predicate: an URI-identified reused specification of the relationship
- Object: a resource or literal to which the subject is related
An RDF model is an unordered collection of statements, each with a subject, predicate and object! The following code extracts RDF triples from the LOSD graph. Don't mind the code itself, we are only interested in the ouput in form of unordered RDF triples (in N-Triples syntax) for now:
>SPARQL
%endpoint https://lindas-data.ch:8443/lindas/query
%auth basic public public
%format any
%display raw
PREFIX : <arbitrary:relation>
CONSTRUCT{?sub ?pred ?obj}
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{<https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BTA> ((:|!:)|^(:|!:))? ?sub. ?sub ?pred ?obj}
LIMIT 10
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <http://purl.org/linked-data/cube#dataSet> <https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BTA> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/property/RAUM> <https://ld.stadt-zuerich.ch/statistics/code/R30000> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/attribute/QUELLE> <https://ld.stadt-zuerich.ch/statistics/quelle/SSD002> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/attribute/KORREKTUR> "false"^^<http://www.w3.org/2001/XMLSchema#boolean> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <http://www.w3.org/2004/02/skos/core#notation> "Z30061966R30000ASTBTA7100XXX0000XXX0000XXX0000XXX0000"^^<http://www.w3.org/2001/XMLSchema#string> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/attribute/DATENSTAND> "2018-08-08"^^<http://www.w3.org/2001/XMLSchema#date> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/attribute/GLOSSAR> <https://ld.stadt-zuerich.ch/statistics/glossary/GBTA7100> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://purl.org/linked-data/cube#Observation> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/attribute/ERWARTETE_AKTUALISIERUNG> "2019-08-22"^^<http://www.w3.org/2001/XMLSchema#date> .
<https://ld.stadt-zuerich.ch/statistics/observation/AST/R30000/Z30061966/BTA7100> <https://ld.stadt-zuerich.ch/statistics/property/ZEIT> "1966-06-30"^^<http://www.w3.org/2001/XMLSchema#date> .
Example triples:
<https://ld.stadt-zuerich.ch/statistics/attribute/ERWARTETE_AKTUALISIERUNG> <http://www.w3.org/1999/02/22-rdf-syntax-ns#type> <http://purl.org/linked-data/cube#AttributeProperty> .
- Meaning: the resource ERWARTETE_AKTUALISIERUNG is a type of AttributeProperty (a resource from another namespace)
<https://ld.stadt-zuerich.ch/schema/TopicEntity> <http://www.w3.org/2000/01/rdf-schema#label> "A topic entity"@en .
- Meaning: the resource TopicEntity has the label "A topic entity" (a literal value with a language tag)
- RDFS (RDF Scheme), OWL (Web Ontology Language) - and many more - extend the base vocabulary of RDF
- See this introduction to semantic modelling and why we need vocabularies
Vocabulary: A collection of terms given a well-defined meaning that is consistent across contexts.
Ontology: Allows you to define contextual relationships behind a defined vocabulary. It is the cornerstone of defining a knowledge domain. A formal syntax for defining ontologies is OWL (Web Ontology Language) which is an extension to RDFS (RDF Schema).
Example: Do LOSD resources like "Heimatland" or "Raum" have a representation, for instance, in Wikidata? Is "Motherland" the Wikidata representation of "Heimatland"? How do we ensure that LOSD can properly "communicate" with Wikidata, or Wikidata is able to query the proper data on our side?
Properly linking data is about adopting the same base ontology or a common vocabulary!
This notebook as well as the LOSData uses primarily the following vocabularies:
The vocabulary names are linked with the respective documentations.
See section 4.25 for a nice example query that incorporates Wikidata!
RDF graphs can be expressed in a variety of formats!
- JSON is a common format for data serialization and messaging
- TURTLE is especially useful because it conforms with the SPARQL syntax
- N-Triples: simple notation, easy-to-parse, line-based format that is not as compact as Turtle
- RDF/XML: One of the first formats available. Due to its complexity we do not recommend to work with RDF/XML, unless you have a good reason to do so.
to name the most common ones. Note that you can always translate any RDF serialization to another one without loosing any information.
- See section 3.3 of this notebook and the Specification
- See the Specification,
- the cheat-sheet for a summary of the syntax
- explore the wikibook for more examples
- and most importantly, watch Zazuko's video on querying our RDF DataCube with SPARQL and the YASGUI interface
Learning by doing is our motto!
Explore a variety of examples in the SPARQL section.
- Interested paties are invited to explore this nice comparison
The data provided SSZ conforms with the Statistical Data and Metadata (SDMX) standard. Check out this video for a nice introduction of SDMX. The part starting at 5:42 is especially descriptive because it illustrates SDMX with the aid of a statistical table. Illustrations of the statistical tables in the yearbooks of SSZ shall be presented in the next section.
The standard describes and universalizes the way to exchange statistical data, and provides standard formats for data and metadata, content guidelines as well as IT architecture for exchange of data and metadata. The specification with the definition of these terms is provided here. The following figure shows a high level schematic of the major artefacts in the SDMX Information Model. However, terms like Concept Scheme or Code List, which are of particular use to us, are explained in later sections in the context of our data model.

Observation:
As the basis of the historic data, observations are the individual measurements of the statistics with a code structure of the form:
ZddmmyyyyRrrrrrKENGR10000GR20000GR30000GR40000GR50000
where the format(length) is equal to Char(53).
Kennzahl or Measure:
The Kennzahl represents the dimension that is measured by an observation in dependance of other dimensions. If we look at an observation as a function, then the Kennzahl serves as its output (all other dimensions as input). Examples of Kennzahlen are:
- "BEW" for population
- "STF" for plot area (in m2)
- "ZUZ" for in-migration
- "WSS" for water pollutant (in mg/l)
- etc.
The format(length) is Char(3). "KEN" serves as the placeholder in the observation code. For an observation reading "residential population in dependance of homeland, sex and urban district in the year 2016", the Kennzahl would correspond to "BEW" for residential population:
Z31122016R00012BEWHEL1000SEX0001XXX0000XXX0000XXX0000, with a value of BEW = 206 persons
Z31122016R00011BEWHEL2000SEX0002XXX0000XXX0000XXX0000, with a value of BEW = 414 persons
are two examples with their respective measurements.
Group or Dimension:
Groups are equivalent to dimensions and describe how a Kennzahl is divided into subsets. In other words, groups correspond to the input parameters in the function analogy. They also determine the hierarchy of an observation or measurement. Group examples are:
- "BEW" for residence permit (not to be confused with the Kennzahl!)
- "HEL" for homeland
- "SEX" for sex
- "ALT" for age
- "TIG" for animal species
- etc.
The format(length) is also Char(3) and "GR1",...,"GR5" serve as the placeholders in the observation code. An observation may comprise a maximum of 5 groups where missing groups are denoted with "XXX" (see the examples above). It is important to note that, despite being dimensions as well, "Zeit" and "Raum" are regarded separately. Both are fixed parts of each and every observation with their own format(length).
Zeit:
Represents date and time. Zeit is a special type of dimension with identifier "Z" and groupcode of format(length) Char(9). Missing or unknown groupvalues are denoted with "X". Examples are "ZXXXX2016" for the year 2016 or "Z24121950" for the 24th Dec. in 1950.
Raum:
Represents space or area. Raum is a special type of dimension with identifier "R" and groupcode of format(length) Char(6). Examples are "R30000" for Zurich or "R00011" for the urban district "Rathaus" in Zurich.
Groupcodes:
A groupcode is a group identifier paired with its respective value or measurement. A groupvalue has format(length) Char(4) which adds up to a total of Char(7) for the groupcode. In the observation code "0000" corresponds to missing or unknown groupvalues.
Metadata:
Having located an observation, we need certain metadata in order to be able to interpret it. What is the unit of measurement, when was it measured or where was it acquired? Other Metadata includes footnotes, glossary entries or even a date when the data will be updated. Metadata is provided as attributes and can be attached to individual observations or to higher levels. We distinguish two types of Metadata:
Literal values bound to a specific measurement (or higher level):
- DATENSTAND: a xsd:date value ("YYYY-MM-DD") that states the last date the data was updated or the last time the data was acquired, respectively
- BEZUGSZEIT: a string value that states in what intervals the data is acquired, e.g. "Tag;Monat", "Periode;Jahr", "Tag;Tag;Monat;Quartal;Trimester;Semester;Jahr" etc.
- license: a string value that states under what license the data is published, e.g. "CC0" or "CCBY" (Creative Commons 0 and Creative Commons BY)
- KORREKTUR: a xsd:boolean value that states if the data was updated or not
- ERWARTETE_AKTUALISIERUNG: a xsd:date value ("YYYY-MM-DD") that states the next date the data is updated or the next time the data is acquired, respectively
URI resources that are possibly referenced by multiple measurements (or higher level):
- Unit: the unit of measurement, e.g. years, square meters, persons etc. Each unit is a resource with type, label, notation and rounding
- QUELLE: the source of the data with a creator, rights, license, label and notation
- FUSSNOTE: a footnote with a type, label and scheme
- GLOSSAR: a string value that further describes a resource, concept, Groupcode etc. A glossary resource has a description, comment, label and notation
The following figures show excerpts of the statistical yearbooks from the year 1941 and 2016 (taken from the Statistik Stadt Zurich page). Such data is first of all mapped to the aforementioned observations, then equipped with metadata (version, source, glossary etc.) and subsequently collected in DataSets of the RDF Data Cube model.


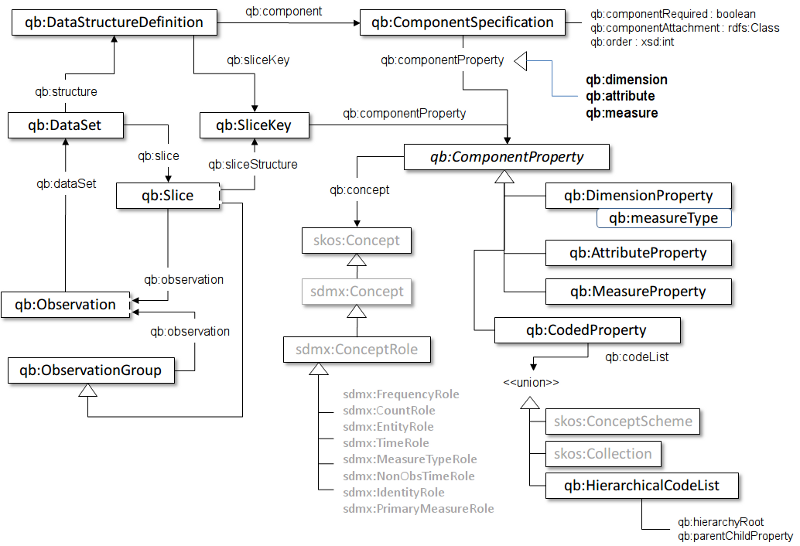
The Data Cube model further specifies the SDMX definitions and forms an actual data model which is described in terms of the Resource Description Framework. The basis of every Data Cube is its ensemble of observations. They represent the actual statistical measurements and every other concept serves to relate and structure these measurements in a meaningful way. The primary concepts shall be briefly explained here and in the following section:
qb:DataSet:
A statistical data set comprises a collection of observations made at some points across some logical space. The collection can be characterized by a set of dimensions that define what the observation applies to (e.g. time, area, gender) along with metadata describing what has been measured (e.g. economic activity, population), how it was measured and how the observations are expressed (e.g. units, multipliers, status). We can think of the statistical data set as a multi-dimensional space, or hyper-cube, indexed by those dimensions.
- Observations of the historic data are collected in DataSets according to the following rule:
ZddmmyyyyRrrrrrKENGR10000GR20000GR30000GR40000GR50000
corresponds to the DataSet
KEN-RAUM-ZEIT-GR1-GR2-GR3-GR4-GR5
where missing groups/dimensions ("XXX") are omitted in qb:DataSet notation.
- DataSets are accessed through the node https://ld.stadt-zuerich.ch/statistics/dataset/ followed by their respective notation
qb:Observation:
This is the actual data, the measured values. In a statistical table (as in the statistical yearbooks), the observations would be the values in the table cells.
- Observations of the historic data are mapped according to the following rule:
ZddmmyyyyRrrrrrKENGR10000GR20000GR30000GR40000GR50000
corresponds to the observation
KEN/Rrrrrr/Zddmmyyyy/GR10000/GR20000/GR30000/GR40000/GR50000
in our DataCube notation
where missing groups/dimensions ("XXX") are omitted in qb:Observation notation.
- Observations are accessed through the node https://ld.stadt-zuerich.ch/statistics/observation/ followed by their respective notation
qb:MeasureProperty:
The measure components represent the observed phenomena.
- Kennzahlen or measures of the historic data are mapped to MeasureProperty.
- Measures are accessed through the node https://ld.stadt-zuerich.ch/statistics/measure/ followed by their respective notation
qb:DimensionProperty:
The dimension components serve to identify the observations. A set of values for all the dimension components is sufficient to identify a single observation. Examples of dimensions include the time to which the observation applies, or a geographic region which the observation covers etc.
- Dimensions of the historic data are mapped to DimensionProperty.
- Dimensions are accessed through the node https://ld.stadt-zuerich.ch/statistics/property/ followed by their respective notation
qb:AttributeProperty:
The attribute components allow us to qualify and interpret the observed value(s). They enable specification of the units of measure, any scaling factors and metadata such as the status of the observation (e.g. estimated, provisional).
- Only meta and system attributes of the historic data are mapped to AttributeProperty!
- Attributes are accessed through the node https://ld.stadt-zuerich.ch/statistics/attribute/ followed by their respective notation
- Units of the MeasureProperties, for instance, are mapped to an independent concept (see next section)
qb:Slice:
A subset of observations within a DataSet. Produced by fixing one or more dimensions and refer to all observations with those dimension values as a single entity, a slice. In statistical applications it is common to work with slices in which a single dimension is left unspecified. In particular, to refer to such slices, in which the single free dimension is time, as "Time Series". Within the Data Cube vocabulary however, arbitrary dimensionality slices are allowed and particular types of slice are not denoted differently.
- Slices of a specific <DataSet> and <SliceKey> are accessed through the nodes https://ld.stadt-zuerich.ch/statistics/dataset/<DataSet>/<SliceKey>/slice
A diagram of the RDF Data Cube model is provided in the following figure. In addition to the official Data Cube Documentation a very informative presentation can be downloaded here.
Shapes:
Shape expressions (written in RDF) are used to declare various constraints for the components of a RDF graph (or Data Cube). Informally, a shape is a set of conditions that determine how to validate a node (of a graph), based on the values of properties and other characteristics of the node, with the Shapes Constraint Language (SHACL). Shapes and SHACL represent a validation mechanism. Examples of such constraints are:
- Observations must be linked to a Raum and Zeit
- Observations must be linked to a measure
- Observations measure a double value
- Observations comprise 5 groups at most
- DataSets contain several slices and slices contain several observations
- and many more..
More information on shapes can be found in the official SHACL Documentation.
- Shapes of a specific <DataSet> are accessed through the nodes https://ld.stadt-zuerich.ch/statistics/dataset/<DataSet>/shape
sdmx:unitMeasure and qudt:unit:
The units of measurement of observations are mapped to these two concepts and accessed through the node https://ld.stadt-zuerich.ch/statistics/unit/. qudt:unit acts as the type and sdmx:unitMeasure as the relation of triples:
?sub sdmx:unitMeasure ?unit?unit a qudt:unit
skos:Concept:
Groupcodes of the historic data are mapped to skos:Concept and accessed through the node https://ld.stadt-zuerich.ch/statistics/code/. A skos:Concept can be viewed as an idea or notion. It is useful when describing the conceptual or intellectual structure of a knowledge organization system, and when referring to specific ideas or meanings established within a KOS. An Example:
- <https://ld.stadt-zuerich.ch/statistics/code/R00012> is a skos:Concept representing institutions of higher education (label "Hochschulen") or, more precisely, the occupied area
- <https://ld.stadt-zuerich.ch/statistics/code/ABT6000> is a skos:Concept representing all apprentices (label "Lehrlinge")
skos:Notation: Is a string of characters, such as "R00012" or "ABT6000", used to uniquely identify a skos:Concept within the scope of a given concept scheme. A notation is different from a lexical label in that a notation is not normally recognizable as a word or sequence of words in any natural language. An Example:
- <https://ld.stadt-zuerich.ch/statistics/code/R00012> is a concept with skos:Notation "R00012"
skos:inScheme:
Tells us to which scheme a concept belongs. A skos:ConceptScheme can be viewed as an aggregation of one or more skos:Concepts. Semantic relationships (links) between those concepts may also be viewed as part of a concept scheme. The notion of a concept scheme is useful when dealing with data that describes two or more different knowledge organization systems. An Example:
- the concept <https://ld.stadt-zuerich.ch/statistics/code/R00012> is in skos:inScheme <https://ld.stadt-zuerich.ch/statistics/scheme/Raum>
- note that "Raum" is not only used as a dimension but also as a concept!
skos:broader and skos:narrower:
Are used to assert a direct hierarchical link between two skos:Concepts:
- A triple <A> skos:broader <B> asserts that <B>, the object of the triple, is a broader concept than <A>, the subject of the triple.
- Similarly, a triple <C> skos:narrower <D> asserts that <D>, the object of the triple, is a narrower concept than <C>, the subject of the triple.
- <https://ld.stadt-zuerich.ch/statistics/code/R00012> for instance has skos:broader
owl:sameAs:
The sameAs statement indicates that two URI resources actually refer to the same thing or represent the same concept. owl:sameAs statements are often used for mappings between ontologies. It is unrealistic to assume everyone will use the same name to refer to some resource or concept. Two concepts generally have different features and relations to other resources, despite being linked by sameAs! In this way, making a union between such ontologies or databases provides more complete data. The graph example in section 2.3 had the following statement regarding the city district Alt-Wiedikon:
- <https://ld.stadt-zuerich.ch/statistics/code/R00031> owl:sameAs <http://www.wikidata.org/entity/Q433012>
This means, Wikidata's database entry - with its own location-/population information, images and references - is linked with LOSD. As a result, Wikidata is able to use R00031 as a gateway to query and effectively incorporate the LOSData into its own database (and vice versa of course).
The challenge with owl:sameAs is that when there are many mappings of nodes between graphs, and especially when big chains of sameAs appear, it becomes inefficient. owl:sameAs is defined as symmetric and transitive, so given that <A> sameAs <B> sameAs <C>, also the statements <A> sameAs <A>, <A> sameAs <C>, <B> sameAs <A> etc. will be produced.
- See section 4.25 for a nice example
Topics:
The node https://ld.stadt-zuerich.ch/schema/Category contains the main categories of a topic tree. The following figure shows a simplified diagram:

skos:narrower reveals a new topic level for each category and subtopic - and so on - until a DataSet is reached. Each topic relates to a number of DataSets.
- The SPARQL interface is accessed through https://ld.stadt-zuerich.ch/sparql/
- The actual queries are done via https://ld.stadt-zuerich.ch/query which is the SPARQL endpoint as well
- The complete graph can be found at the opendata.swiss node https://linked.opendata.swiss/graph/zh/statistics
- The integration environment is accessed through https://ld.integ.stadt-zuerich.ch/sparql/, but it is to be noted that the URIs tend to point back to the production environment. While testing, the ".integ" has to be inserted by hand or programmatically
Don't forget to watch our developer guide on how to query our data with SPARQL!
Before we get down to business, we have to prepare a few things for the queries to reach outside of this notebook:
>SPARQL
%endpoint https://lindas-data.ch:8443/lindas/query
%auth basic public public
%format JSON
%display table
These so called line magics control the behaviour of the SPARQL kernel, i.e., the queries in this notebook. The most important ones shall be briefly explained:
- >Kernelname: defines the code format of the cell. This notebook includes SPARQL and R examples, so a cell is either declared >SPARQL or >R
- %endpoint: defines the mandatory SPARQL endpoint for all subsequent queries. It remains active until superseded by another endpoint magic.
- %auth: defines the HTTP authentification to send to the backend. For the lindas endpoint we can simply use "public" for the <username> and <password>
- %format: sets the data format requested to the SPARQL endpoint. We request the endpoint to provide results in JSON format if nothing else is mentioned
- %display: sets the output rendering shape. "raw" would display our results as specified by %format whereas "table" generates a table out of them. We will also see results displayed as diagrams later
- %lsmagics: displays all available magics
If at any point a query doesn't work as expected or throws an error, we advise the reader to rerun the cell with the magics or insert the line magics at the beginning of the query before trying again.
Be careful to remove all magics if you copy paste our examples!
In our first SPARQL queries we want to get a feel for the data and how it is structured. It makes sense to start by exploring the DataSets, although the observations serve as the true foundation of the statistical data. The various DataSets and their labels help us in getting a good overview of the provided data and its partitioning.
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?dataset ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?dataset a qb:DataSet;
rdfs:label ?label.
}
Note that ?dataset a qb:DataSet is short for
?dataset http://www.w3.org/1999/02/22-rdf-syntax-ns#type qb:DataSet
- rdf:type is generally shortened to just "a" as in "is a type of..".
The following query SELECTS randomly 100 RDF triples:
>SPARQL
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?sub ?pred ?obj.
}
LIMIT 100
Example has no practical use but gives an overview of the stored data.
SELECT *simply selects all variables declared in the query in order of appearanceLIMIT 100limits the output to 100 matches
The COUNT command allows us to count the number of matches of a variable or multiple variables:
>SPARQL
SELECT (COUNT(*) AS ?count)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?sub ?pred ?obj.
}
| count |
|---|
| 3924445 |
Example has no practical use but shows the sheer size of the graph.
COUNT(*)simply counts all declared variables. Since all of them are part of the same statement, they are counted only once. In other casesCOUNT(DISTINCT *)might be better suited to account for identical matches
The following query lists all DataSets, labels them and counts the Observations:
>SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
SELECT ?dataset ?label (COUNT(DISTINCT ?observation) AS ?observations)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?observation a qb:Observation;
qb:dataSet ?dataset.
?dataset rdfs:label ?label.
}
GROUP BY ?dataset ?label
ORDER BY DESC(?observations)
| dataset | label | observations |
|---|---|---|
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT | Wirtschaftliche Wohnbevölkerung nach Alter, Raum, Zeit | 35919 |
| https://ld.stadt-zuerich.ch/statistics/dataset/STF-RAUM-ZEIT-BBA | Grundstückfläche nach Bodenbedeckungsart, Raum, Zeit | 33118 |
| https://ld.stadt-zuerich.ch/statistics/dataset/STF-RAUM-ZEIT-EIG | Grundstückfläche nach Eigentümerart, Raum, Zeit | 32049 |
| https://ld.stadt-zuerich.ch/statistics/dataset/STF-RAUM-ZEIT-ZON | Grundstückfläche nach Raum, Zeit, Zonenart | 29104 |
| https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BTA | Arbeitsstätten nach Betriebsart, Raum, Zeit | 23566 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-HEL-SEX | Wirtschaftliche Wohnbevölkerung nach Heimatland, Raum, Geschlecht, Zeit | 11276 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-HEL-SEX | Wirtschaftliche Wohnbevölkerung nach Alter, Heimatland, Raum, Geschlecht, Zeit | 7928 |
| https://ld.stadt-zuerich.ch/statistics/dataset/STF-RAUM-ZEIT-BBA-ZON | Grundstückfläche nach Bodenbedeckungsart, Raum, Zeit, Zonenart | 7237 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-AUA-HEL | Wirtschaftliche Wohnbevölkerung nach Aufenthaltsart, Heimatland, Raum, Zeit | 6849 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-HEL | Wirtschaftliche Wohnbevölkerung nach Alter, Heimatland, Raum, Zeit | 6682 |
| https://ld.stadt-zuerich.ch/statistics/dataset/ZUS-RAUM-ZEIT-BTA | Zuschauer/innen, Besucher/innen nach Betriebsart, Raum, Zeit | 6143 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-HEL | Wirtschaftliche Wohnbevölkerung nach Heimatland, Raum, Zeit | 5640 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-SEX | Wirtschaftliche Wohnbevölkerung nach Raum, Geschlecht, Zeit | 5162 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-SEX | Wirtschaftliche Wohnbevölkerung nach Alter, Raum, Geschlecht, Zeit | 3964 |
| https://ld.stadt-zuerich.ch/statistics/dataset/ABL-RAUM-ZEIT-ALT-HEL | Arbeitslose nach Alter, Heimatland, Raum, Zeit | 3744 |
| https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT | Wirtschaftliche Wohnbevölkerung nach Raum, Zeit | 2669 |
| https://ld.stadt-zuerich.ch/statistics/dataset/SCH-RAUM-ZEIT-BTA-SST | Schüler/innen und Student/innen nach Betriebsart, Raum, Schulstufen und Fächer, Zeit | 2520 |
| https://ld.stadt-zuerich.ch/statistics/dataset/STF-RAUM-ZEIT | Grundstückfläche nach Raum, Zeit | 2466 |
| https://ld.stadt-zuerich.ch/statistics/dataset/ANT-RAUM-ZEIT-GGH-HEL | Anteil nach Grundgesamtheit, Heimatland, Raum, Zeit | 2379 |
| https://ld.stadt-zuerich.ch/statistics/dataset/VER-RAUM-ZEIT-BTA-VSA | Veranstaltungen, Aufführungen nach Betriebsart, Raum, Veranstaltungsart, Zeit | 1531 |
The example shows that you are ill advised to directly load the DataSet "AST-RAUM-ZEIT-BTA"..
To search for specific names, terms or patterns in labels or code values etc., SPARQL offers the FILTER command and regular expressions. The following query searches for the term "Tier" in all available labels of the DataCube:
>SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?sub rdfs:label ?label.
FILTER REGEX(?label, "Tiere*")
}
ORDER BY ?sub
LIMIT 100
Various types of matches are included in the (complete) results:
- Topic, e.g. https://stat.stadt-zuerich.ch/topic/WIR009 (Tierhaltung der Landwirtschaftsbetriebe)
- DataSet, e.g. https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BTA-TIG/ASTBTA9200TIG9000/slice (Anzahl Ladwirtschaftsbetriebe mit übrigen Tierarten)
- Measure, e.g. https://ld.stadt-zuerich.ch/statistics/measure/TII (Tierindividuen)
- Code, e.g. https://ld.stadt-zuerich.ch/statistics/code/PAT1200 (Tierpartei Schweiz "TPS")
- Property, e.g. https://ld.stadt-zuerich.ch/statistics/property/TIG (Tiergattung)
- external applications and glossary are not yet supported (coming later)
Regular expressions in FILTER are used as follows:
FILTER REGEX( string, pattern )
where pattern is the actual regular expression. The asterisk denotes that the string may contain "Tier" more than once. More on regular expressions here. See also section 4.19.1.
As explained in section 3.3, the measures or Kennzahlen of the statistical data are mapped to qb:MeasureProperty. With this very intuitive query all those properties are extracted with their label, unit and additional comments or notes:
>SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qudt: <http://qudt.org/schema/qudt#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
SELECT ?measure ?label ?unit ?comment ?note
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?measure a qb:MeasureProperty;
rdfs:label ?label;
qudt:unit ?unit;
rdfs:comment ?comment.
OPTIONAL{?measure skos:scopeNote ?note}
}
ORDER BY ?measure
| measure | label | unit | comment | note |
|---|---|---|---|---|
| https://ld.stadt-zuerich.ch/statistics/measure/ABF | Abfall | https://ld.stadt-zuerich.ch/statistics/unit/tonnen | Abfall in Tonnen | Abfälle sind alle Stoffe oder Gegenstände, deren sich der Besitzer entledigt. |
| https://ld.stadt-zuerich.ch/statistics/measure/ABG | Stimmen | https://ld.stadt-zuerich.ch/statistics/unit/stimmen | Anzahl Stimmen | Die Parteistimmen ergeben sich aus der Summe der Kandidaten- und der Zusatzstimmen jeder Wahlliste. |
| https://ld.stadt-zuerich.ch/statistics/measure/ABL | Arbeitslose | https://ld.stadt-zuerich.ch/statistics/unit/personen | Anzahl Arbeitslose | Beim Regionalen Arbeitsvermittlungszentrum (RAV) registrierte Personen aus der Wohnbevölkerung, die am Stichtag
keine Erwerbstätigkeit ausüben, sodass sie zu einem sofortigen Stellenantritt bereit sind. Nicht dazu zählen Personen, die zeitlich befristet arbeiten (Zwischenverdienst) oder ein Beschäftigungsprogramm durchlaufen. Ausgesteuerte Arbeitslose sind in den Zahlen enthalten, sofern sie sich beim RAV um eine Arbeit bemühen. |
| https://ld.stadt-zuerich.ch/statistics/measure/ABP | Abfall pro Einwohner/ -in | https://ld.stadt-zuerich.ch/statistics/unit/kgproeinwohner | Abfall pro Einwohner/ -in in Kilogramm | Die durchschnittliche Menge des Abfalls, die pro Einwohner/-in anfällt. Die Menge wird in Kilogramm angegeben. |
| https://ld.stadt-zuerich.ch/statistics/measure/ABS | Abschlüsse | https://ld.stadt-zuerich.ch/statistics/unit/abschluss | Abschlüsse (Lehrdiplome) | Die Berufslehre wird mit einem eidgenössisch anerkanntem Diplom (Fähigkeitszeugnis) abgeschlossen. Die Lernenden müssen dazu eine Lehrabschlussprüfung bestehen. Die Prüfungs- und Erfahrungsnoten werden gleich gewichtet. Der Abschluss (Lehrdiplom) ist meist eine Voraussetzung für eine Arbeitsstelle. |
| https://ld.stadt-zuerich.ch/statistics/measure/ABW | Abwassermenge | https://ld.stadt-zuerich.ch/statistics/unit/miom3 | Abwassermenge in Mio. m³ | |
| https://ld.stadt-zuerich.ch/statistics/measure/ADA | Ausstellungsdauer | https://ld.stadt-zuerich.ch/statistics/unit/tage | Dauer der Ausstellung/Messe in Tagen | |
| https://ld.stadt-zuerich.ch/statistics/measure/AEH | Ehelösungen durch Tod eines Partners | https://ld.stadt-zuerich.ch/statistics/unit/anzahl | Ehelösungen durch Tod eines Partners | |
| https://ld.stadt-zuerich.ch/statistics/measure/AGT | Agglomerationstyp | https://ld.stadt-zuerich.ch/statistics/unit/klasse | Unterscheidung von Kernstadt, Hauptkern, Nebenkern, Agglomerationsgürtelgemeinde | Die Agglomeration Zürich besteht aus 150 Gemeinden und sie wird unterteilt in eine Kernstadt (Stadt Zürich), einen Hauptkern (31 Gemeinden), einen Nebenkern (32 Gemeinden) sowie in einen Agglomerationsgürtel (86 Gemeinden). Die Kernstadt gilt als Teil des Hauptkerns. Agglomerationen müssen sowohl über einen dichten Kern verfügen als auch eine bestimmte Grösse erreichen. |
| https://ld.stadt-zuerich.ch/statistics/measure/ALQ | Arbeitslosenquote | https://ld.stadt-zuerich.ch/statistics/unit/prozent | Arbeitslosenquote | Die Arbeitslosenquote berechnet sich aufgrund der aktuellen Arbeitslosenzahlen dividiert durch die Erwerbspersonen gemäss der Volkszählung 2010. Zu den Erwerbspersonen zählen Erwerbstätige und Erwerbslose. |
| https://ld.stadt-zuerich.ch/statistics/measure/ANK | Ankünfte von Personen | https://ld.stadt-zuerich.ch/statistics/unit/personen | Anzahl Ankünfte von Personen | |
| https://ld.stadt-zuerich.ch/statistics/measure/ANR | Anrufe | https://ld.stadt-zuerich.ch/statistics/unit/anrufe | Anrufe (Notrufe) | |
| https://ld.stadt-zuerich.ch/statistics/measure/ANT | Anteil | https://ld.stadt-zuerich.ch/statistics/unit/prozent | Anteil in Bezug auf (benötigt immer eine Dimension Grundgesamtheit) | Anteil in Bezug auf (benötigt immer eine Dimension Grundgesamtheit) |
| https://ld.stadt-zuerich.ch/statistics/measure/APA | Anteil nach Partei | https://ld.stadt-zuerich.ch/statistics/unit/prozent | Anteil nach Partei in Prozent | |
| https://ld.stadt-zuerich.ch/statistics/measure/APL | Arbeitsplätze | https://ld.stadt-zuerich.ch/statistics/unit/anzahl | Anzahl Arbeitsplätze (Anzahl Beschäftigte mit vertraglich vereinbarter Arbeitstätigkeit > 6h/Woche) | |
| https://ld.stadt-zuerich.ch/statistics/measure/ASL | Anschlussleitungen | https://ld.stadt-zuerich.ch/statistics/unit/leitung | Anzahl Anschlussleitungen | |
| https://ld.stadt-zuerich.ch/statistics/measure/AST | Arbeitsstätten | https://ld.stadt-zuerich.ch/statistics/unit/arbeitsstaette | Anzahl Arbeitsstätten | Eine Arbeitsstätte ist eine örtlich abgegrenzte Einheit, in welcher mindestens 20 Stunden pro Woche gearbeitet wird. Die Begriffe «Arbeitsstätten» und «Betriebe» werden synonym verwendet. |
| https://ld.stadt-zuerich.ch/statistics/measure/AUD | Aufenthaltsdauer in Tagen | https://ld.stadt-zuerich.ch/statistics/unit/tage | Aufenthaltsdauer in Tagen | Die durchschnittliche Aufenthaltsdauer in einem Betrieb errechnet sich aus der Anzahl Logiernächte dividiert durch die Anzahl Ankünfte. |
| https://ld.stadt-zuerich.ch/statistics/measure/AUF | Auflage | https://ld.stadt-zuerich.ch/statistics/unit/exemplare | Auflagegrösse (Anzahl Exemplare) von Zeitungen oder Publikationen | |
| https://ld.stadt-zuerich.ch/statistics/measure/AUG | Aufgelöste Partnerschaften | https://ld.stadt-zuerich.ch/statistics/unit/aufloesungen | Anzahl aufgelöste Partnerschaften |
Important to consider in this query is that not every measure defines a skos:scopeNote! As a result we have to use OPTIONAL or else only measures will be matched that have such a scopeNote (measures without one would be omitted in the results). OPTIONAL tells SELECT that if such a note exists, please match it or else proceed normally.
Note that the DataCube model also offers the relation qb:measure to access the MeasureProperties, but only with qb:SliceKey and qb:ComponentSpecification as the subject (see the diagram in section 3.3). To select specific Kennzahlen, one could do the following:
- use the absolute URI as relation:
?sub <https://ld.stadt-zuerich.ch/statistics/measure/<measure>> ?measure - use the relative URI as relation (with the respective PREFIX defined):
?sub measure:<measure> ?measure
As explained in section 3.3, the groups or dimensions of the statistical data are mapped to qb:DimensionProperty. With this very intuitive query all those properties are extracted with their label:
>SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
SELECT ?dimension ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?dimension a qb:DimensionProperty;
rdfs:label ?label;
}
ORDER BY ?dimension
Note that the DataCube model also offers the relation qb:dimension to access the DimensionProperties, but only with qb:SliceKey and qb:ComponentSpecification as the subject (see the diagram in section 3.3). To select specific dimensions, one could do the following (see also the next example):
- use the absolute URI as relation:
?sub <https://ld.stadt-zuerich.ch/statistics/property/<dimension>> ?dimension - use the relative URI as relation (with the respective PREFIX defined):
?sub property:<dimension> ?dimension
As explained in section 3.3, groups or dimensions of the statistical data are accessed through the node https://ld.stadt-zuerich.ch/statistics/property/. If we want to query all DataSets of particular dimensions, we can do this by asking for the property relation as follows. An example is given with property:SEX where all observations of the resulting DataSets are counted:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
SELECT ?dataset (COUNT(DISTINCT ?sub) AS ?observations)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?sub a qb:Observation;
qb:dataSet ?dataset;
property:SEX ?code.
}
GROUP BY ?dataset
ORDER BY DESC(?observations)
COUNT counts all the subjects that fulfill these statements where the last statement requires the subject to have a particular dimension SEX. GROUP BY is always necessary for COUNT.
See section 3.4 for an explanation on the topics. The following query selects for each topic all the related DataSets. To limit the number of matches, only topics up to topic level two are selected. See also example 4.12.2 for the hierarchies.
>SPARQL
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX xsd: <http://www.w3.org/2001/XMLSchema#>
PREFIX schema: <https://ld.stadt-zuerich.ch/schema/>
SELECT DISTINCT ?topicLevel ?topicLabel ?dataset ?datasetLabel
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
SELECT *
WHERE{
?category a schema:Category.
{?category skos:narrower ?topic. BIND("1" AS ?topicLevel)}
UNION
{?category skos:narrower/skos:narrower ?topic. BIND("2" AS ?topicLevel)}
UNION
{?topic a schema:Category. BIND("0" AS ?topicLevel)}
}
ORDER BY ?topic
}
?dataset a qb:DataSet;
rdfs:label ?datasetLabel.
?topic rdfs:label ?topicLabel;
skos:narrower+ ?dataset.
}
ORDER BY ?topicLabel ?dataset
| topicLevel | topicLabel | dataset | datasetLabel |
|---|---|---|---|
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/ANT-RAUM-ZEIT-GGH-HEL | Anteil nach Grundgesamtheit, Heimatland, Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT | Wirtschaftliche Wohnbevölkerung nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT | Wirtschaftliche Wohnbevölkerung nach Alter, Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-HEL | Wirtschaftliche Wohnbevölkerung nach Alter, Heimatland, Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-HEL-SEX | Wirtschaftliche Wohnbevölkerung nach Alter, Heimatland, Raum, Geschlecht, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-ALT-SEX | Wirtschaftliche Wohnbevölkerung nach Alter, Raum, Geschlecht, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-AUA-HEL | Wirtschaftliche Wohnbevölkerung nach Aufenthaltsart, Heimatland, Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-HEL | Wirtschaftliche Wohnbevölkerung nach Heimatland, Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-HEL-SEX | Wirtschaftliche Wohnbevölkerung nach Heimatland, Raum, Geschlecht, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT-SEX | Wirtschaftliche Wohnbevölkerung nach Raum, Geschlecht, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/GEB-RAUM-ZEIT | Geborene (wirtschaftlich) nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/GES-RAUM-ZEIT | Sterbefälle (wirtschaftlich) nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/SAB-RAUM-ZEIT | Saldo aller Bevölkerungsbewegungen (wirtschaftlich) nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/SNB-RAUM-ZEIT | Saldo der natürlichen Bevölkerungsbewegungen (wirtschaftlich) nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/SUB-RAUM-ZEIT | Saldo von Umzügen (Personen, wirtschaftlich) nach Raum, Zeit |
| 2 | Aktueller Bestand | https://ld.stadt-zuerich.ch/statistics/dataset/SWB-RAUM-ZEIT | Saldo der Wanderungsbewegungen (Personen, wirtschaftlich) nach Raum, Zeit |
| 2 | Alter | https://ld.stadt-zuerich.ch/statistics/dataset/AVA-RAUM-ZEIT | Altersdurchschnitt nach Raum, Zeit |
| 2 | Alter | https://ld.stadt-zuerich.ch/statistics/dataset/AVA-RAUM-ZEIT-GGH-HEL | Altersdurchschnitt nach Grundgesamtheit, Heimatland, Raum, Zeit |
| 2 | Alter | https://ld.stadt-zuerich.ch/statistics/dataset/AVA-RAUM-ZEIT-GGH-HEL-SEX | Altersdurchschnitt nach Grundgesamtheit, Heimatland, Raum, Geschlecht, Zeit |
| 2 | Alter | https://ld.stadt-zuerich.ch/statistics/dataset/AVA-RAUM-ZEIT-GGH-SEX | Altersdurchschnitt nach Grundgesamtheit, Raum, Geschlecht, Zeit |
The sub SELECT matches all topics up to topic level two by narrowing of the main categories "Bevölkerung" and "Bildung, Kultur & Sport". After the subquery, we make use of the fact that all topics lead to a DataSet sooner or later. The property path skos:narrower+ is traversed as many times as it takes to reach a DataSet (but at least once, because zero times would mean that the topic already is a DataSet).
As explained in section 3.3, the primary metadata of the statistical data is mapped to qb:AttributeProperty. With this very intuitive query all those properties are extracted with their label:
>SPARQL
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?attribute a qb:AttributeProperty;
rdfs:label ?label;
}
ORDER BY ?attribute
| attribute | label |
|---|---|
| https://ld.stadt-zuerich.ch/schema/korrektur | Wert ist korrigiert |
| https://ld.stadt-zuerich.ch/schema/lastUpdate | Letzte Aktuallisierung |
| https://ld.stadt-zuerich.ch/schema/nextUpdate | Nächste Aktuallisierung |
| https://ld.stadt-zuerich.ch/statistics/attribute/DATENSTAND | Datenstand |
| https://ld.stadt-zuerich.ch/statistics/attribute/ERWARTETE_AKTUALISIERUNG | Erwartete Aktualisierung |
| https://ld.stadt-zuerich.ch/statistics/attribute/FUSSNOTE | Fussnote |
| https://ld.stadt-zuerich.ch/statistics/attribute/GLOSSAR | Glossar |
| https://ld.stadt-zuerich.ch/statistics/attribute/KORREKTUR | Korrektur |
| https://ld.stadt-zuerich.ch/statistics/attribute/QUELLE | Quelle |
| https://ld.stadt-zuerich.ch/statistics/attribute/UPDATE | Update |
Note that the DataCube model also offers the relation qb:attribute to access the AttributeProperties, but only with qb:SliceKey and qb:ComponentSpecification as the subject (see the diagram in section 3.3). To select specific attributes, one could do the following:
- use the absolute URI as relation:
?sub <https://ld.stadt-zuerich.ch/statistics/attribute/<attribute>> ?attribute - use the relative URI as relation (with the respective PREFIX defined):
?sub attribute:<attribute> ?attribute
See section 4.17 and 4.18 for more examples on metadata.
As explained in section 3.3 and 3.4, the Groupcodes of the statistical data are mapped to skos:Concept. With this very intuitive query all those codes are extracted with their label:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?code ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?code a skos:Concept;
rdfs:label ?label.
}
ORDER BY ?code
skos:Concept is explained in section 3.4!
Most codes have hierarchies as explained in section 3.4. We have to consider that there are two types of hierarchies: skos:broader and skos:narrower. To extract all of them, our query requires a UNION of subqueries - one for each type of hierarchy - to match both to the same variable ?hierarchy:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?code ?codelabel ?pred ?hierarchy ?hierarchylabel
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
?code a skos:Concept;
rdfs:label ?codelabel.
}
{?code skos:broader ?hierarchy. ?code ?pred ?hierarchy. ?hierarchy rdfs:label ?hierarchylabel.}
UNION
{?code skos:narrower ?hierarchy. ?code ?pred ?hierarchy. ?hierarchy rdfs:label ?hierarchylabel.}
}
ORDER BY ?code
The first part of the query simply SELECTS all the codes and labels them. The two subqueries then match each type of the hierarchy to the same variable:
?code skos:broader(narrower) ?hierarchy.matches the hierarchies to the variable ?hierarchy?code ?pred ?hierarchy.matches the respective relation to ?pred (without it ?pred would be empty)
The hierarchies are also labeled for the sake of clarity.
If we want to reveal the absolute hierarchies of the topic tree, we can use the following query. Starting with the main categories "Bevölkerung" and "Bildung, Kultur & Sport", we traverse the graph by using skos:narrower up to topic level three (where already many of the topics reach a DataSet). UNION is used to merge the matches of the different topic levels, and MINUS to account for the cases where skos:narrower already reached a DataSet (and we do no longer have a topic):
>SPARQL
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX schema: <https://ld.stadt-zuerich.ch/schema/>
SELECT DISTINCT ?categoryLabel ?topic ?topicLabel ?topicLevel
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?category a schema:Category; rdfs:label ?categoryLabel.
{?category skos:narrower ?topic. BIND("1" AS ?topicLevel)}
UNION
{?category skos:narrower/skos:narrower ?topic. BIND("2" AS ?topicLevel)}
UNION
{?category skos:narrower/skos:narrower/skos:narrower ?topic. BIND("3" AS ?topicLevel)}
MINUS{?topic a qb:DataSet}.
?topic rdfs:label ?topicLabel.
}
ORDER BY ?topicLabel
| categoryLabel | topic | topicLabel | topicLevel |
|---|---|---|---|
| Bevölkerung | https://stat.stadt-zuerich.ch/code/aktuellerbestand | Aktueller Bestand | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/alter | Alter | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/altergeschlecht | Alter & Geschlecht | 1 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV028 | Altersklasse der Mutter bei der Geburt | 3 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/anteilauslaendischewohnbevoelkerung | Anteil ausländische Wohnbevölkerung | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/aufenthaltsart | Aufenthaltsart | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/aufenthaltsdauer | Aufenthaltsdauer | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV011 | Ausländische Wohnbevölkerung nach Geschlecht, Altersklasse und Heimat | 3 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV012 | Ausländische Wohnbevölkerung nach Geschlecht, Aufenthaltsart und Heimat | 3 |
| Bildung, Kultur & Sport | https://stat.stadt-zuerich.ch/topic/KUL020 | Bade- und Schulschwimmanlagen | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/bestand | Bestand | 1 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/bestandnachdefinition | Bestand nach Definition | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV057 | Bevölkerungsbilanz nach Stadtquartier | 3 |
| Bildung, Kultur & Sport | https://stat.stadt-zuerich.ch/topic/KUL022 | Bibliotheken | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/buergerrechtderstadtzuerich | Bürgerrecht der Stadt Zürich | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/dauerderehe | Dauer der Ehe | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV022 | Durchschnittsalter der Eheschliessenden | 3 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV027 | Durchschnittsalter der Mutter bei der Geburt | 3 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV009 | Durchschnittsalter der Wohnbevölkerung | 3 |
| Bevölkerung | https://stat.stadt-zuerich.ch/topic/BEV025 | Ehescheidungen nach Altersklassen Anteile | 3 |
If we change the query slightly, we can reveal the relative parent topics:
>SPARQL
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX schema: <https://ld.stadt-zuerich.ch/schema/>
SELECT DISTINCT ?parentTopic ?topic ?topicLabel ?topicLevel
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?category0 a schema:Category.
{?category0 rdfs:label ?parentTopic; skos:narrower ?topic. BIND("1" AS ?topicLevel)}
UNION
{?category0 skos:narrower [rdfs:label ?parentTopic; skos:narrower ?topic]. BIND("2" AS ?topicLevel)}
UNION
{?category0 skos:narrower/skos:narrower [rdfs:label ?parentTopic; skos:narrower ?topic]. BIND("3" AS ?topicLevel)}
MINUS{?topic a qb:DataSet}.
?topic rdfs:label ?topicLabel.
}
ORDER BY ?topicLabel
| parentTopic | topic | topicLabel | topicLevel |
|---|---|---|---|
| Bestand | https://stat.stadt-zuerich.ch/code/aktuellerbestand | Aktueller Bestand | 2 |
| Alter & Geschlecht | https://stat.stadt-zuerich.ch/code/alter | Alter | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/altergeschlecht | Alter & Geschlecht | 1 |
| Geburten | https://stat.stadt-zuerich.ch/topic/BEV028 | Altersklasse der Mutter bei der Geburt | 3 |
| Alter | https://stat.stadt-zuerich.ch/topic/BEV028 | Altersklasse der Mutter bei der Geburt | 3 |
| Geschlecht | https://stat.stadt-zuerich.ch/topic/BEV028 | Altersklasse der Mutter bei der Geburt | 3 |
| Nationalität, Einbürgerung, Sprache | https://stat.stadt-zuerich.ch/code/anteilauslaendischewohnbevoelkerung | Anteil ausländische Wohnbevölkerung | 2 |
| Nationalität, Einbürgerung, Sprache | https://stat.stadt-zuerich.ch/code/aufenthaltsart | Aufenthaltsart | 2 |
| Zuzug, Wegzug, Umzug | https://stat.stadt-zuerich.ch/code/aufenthaltsdauer | Aufenthaltsdauer | 2 |
| Herkunft | https://stat.stadt-zuerich.ch/topic/BEV011 | Ausländische Wohnbevölkerung nach Geschlecht, Altersklasse und Heimat | 3 |
| Nationalität, Heimat | https://stat.stadt-zuerich.ch/topic/BEV011 | Ausländische Wohnbevölkerung nach Geschlecht, Altersklasse und Heimat | 3 |
| Geschlecht | https://stat.stadt-zuerich.ch/topic/BEV011 | Ausländische Wohnbevölkerung nach Geschlecht, Altersklasse und Heimat | 3 |
| Alter | https://stat.stadt-zuerich.ch/topic/BEV011 | Ausländische Wohnbevölkerung nach Geschlecht, Altersklasse und Heimat | 3 |
| Herkunft | https://stat.stadt-zuerich.ch/topic/BEV012 | Ausländische Wohnbevölkerung nach Geschlecht, Aufenthaltsart und Heimat | 3 |
| Aufenthaltsart | https://stat.stadt-zuerich.ch/topic/BEV012 | Ausländische Wohnbevölkerung nach Geschlecht, Aufenthaltsart und Heimat | 3 |
| Geschlecht | https://stat.stadt-zuerich.ch/topic/BEV012 | Ausländische Wohnbevölkerung nach Geschlecht, Aufenthaltsart und Heimat | 3 |
| Nationalität, Heimat | https://stat.stadt-zuerich.ch/topic/BEV012 | Ausländische Wohnbevölkerung nach Geschlecht, Aufenthaltsart und Heimat | 3 |
| Sport | https://stat.stadt-zuerich.ch/topic/KUL020 | Bade- und Schulschwimmanlagen | 2 |
| Bevölkerung | https://stat.stadt-zuerich.ch/code/bestand | Bestand | 1 |
| Bestand | https://stat.stadt-zuerich.ch/code/bestandnachdefinition | Bestand nach Definition | 2 |
?category0 skos:narrower [rdfs:label ?parentTopic; skos:narrower ?topic]
is the short form for the following two statements:
?category0 skos:narrower/rdfs:label ?parentTopic;
?category0 skos:narrower/skos:narrower ?topic.
We also match the parent topic in each UNION, and omit cases for which the path skos:narrower/skos:narrower/skos:narrower already matches a DataSet (and we no longer have topics). This is achieved by MINUS{?topic a qb:DataSet} which simply excludes everything matching the statement in brackets.
The codes are categorized according to their Scheme. To get an overview of all the spatial hierarchies, we have to SELECT those codes with skos:inScheme https://ld.stadt-zuerich.ch/statistics/scheme/Raum. We also have to consider that there are two types of hierarchies: skos:broader and skos:narrower. To extract all of them, our query requires a UNION of subqueries - one for each type of hierarchy - to match both to the same variable ?hierarchy:
>SPARQL
BASE <https://ld.stadt-zuerich.ch/statistics/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?code ?labelcode ?pred ?hierarchy ?labelhierarchy
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
?code a skos:Concept;
skos:inScheme <scheme/Raum>;
rdfs:label ?labelcode.
}
{?code skos:broader ?hierarchy. ?code ?pred ?hierarchy. ?hierarchy rdfs:label ?labelhierarchy.}
UNION
{?code skos:narrower ?hierarchy. ?code ?pred ?hierarchy. ?hierarchy rdfs:label ?labelhierarchy.}
}
ORDER BY ?code
The spatial hierarchy of Raum (area) is complex. A Raum code typically has multiple skos:broader and skos:narrower relations to other Raum codes:
- R10000: Kreis 1 has skos:broader https://ld.stadt-zuerich.ch/statistics/code/Kreis
- R20000: City after 1. incorporation in 1893 has skos:broader https://ld.stadt-zuerich.ch/statistics/code/R00081 (Seefeld)
- R30000: Zurich City since 1934 has skos:broader https://ld.stadt-zuerich.ch/statistics/code/Gemeinde
to name a few examples. See also the graph visualization in section 2.3.
The first part of the query simply SELECTS all the Raum codes and labels them. The two subqueries then match each type of the hierarchy to the same variable:
?code skos:broader(narrower) ?hierarchy.matches the hierarchies to the variable ?hierarchy?code ?pred ?hierarchy.matches the respective relation to ?pred (without it ?pred would be empty)
The hierarchies are also labeled for the sake of clarity.
In addition to the example in section 3.4, other sameAs relations shall be given here:
>SPARQL
PREFIX owl: <http://www.w3.org/2002/07/owl#>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?sub owl:sameAs ?obj.
}
ORDER BY ?sub
The query simply lists all sameAs relations. Note that not only Wikidata links are present! sameAs is also used to link DataSets or Slices etc. to the corresponding plots of the SSZVIS-Interface.
Select all Slices of the DataCube:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT DISTINCT ?slice ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{?dataset a qb:slice. ?sub ?pred ?obj. ?obj rdfs:label ?label.}
UNION
{?dataset qb:slice ?slice. ?slice rdfs:label ?label.}
}
The URI of a Slice already reveals which dimension is fixed. The Slice "BEWSEX0002" for example, fixes the sex and reduces the DataSet "population as a function of area, sex, date" to "female population as a function of area, date". See 3.3 for more details on Slices.
Select all Shapes of the DataCube:
>SPARQL
PREFIX shacl: <http://www.w3.org/ns/shacl#>
SELECT DISTINCT ?shape
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{?shape a shacl:NodeShape.}
UNION
{?dataset shacl:shapesGraph ?shape.}
}
See section 3.4 for details on shapes.
Metadata is extracted from five randomly selected observations of a random DataSet:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX schema: <https://ld.stadt-zuerich.ch/schema/>
PREFIX attribute: <https://ld.stadt-zuerich.ch/statistics/attribute/>
SELECT DISTINCT ?observation ?predicate ?attribute
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
SELECT ?dataset WHERE{
?dataset a qb:DataSet
}
ORDER BY RAND()
LIMIT 1
}
{
SELECT ?observation WHERE{
?observation qb:dataSet ?dataset
}
ORDER BY RAND()
LIMIT 5
}
{?observation schema:korrektur ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation schema:lastUpdate ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation schema:nextUpdate ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:DATENSTAND ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:RWARTETE_AKTUALISIERUNG ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:FUSSNOTE ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:GLOSSAR ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:KORREKTUR ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:QUELLE ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:UPDATE ?attribute. ?observation ?predicate ?attribute}
UNION
{?observation attribute:BEZUGSZEIT ?attribute. ?observation ?predicate ?attribute}
}
ORDER BY DESC(?attribute)
The first two subqueries select randomly a DataSet and Observations of it. Then the Metadata is extracted individually and merged by UNION. DESC orders the list in a way that the literal values come first.
Every DataSet and all of the Observations with the respective metadata are queried. Per DataSet, a particular metadata value is only selected once (thanks to DISTINCT):
>SPARQL
PREFIX attribute: <https://ld.stadt-zuerich.ch/statistics/attribute/>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
SELECT ?dataset ?pred ?obj
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?dataset a qb:DataSet.
{
#Unit
?dataset <http://purl.org/linked-data/sdmx/2009/attribute#unitMeasure> ?obj.
?dataset ?pred ?obj.
}
UNION
{
#Lizenz
?dataset <http://purl.org/dc/terms/license> ?obj.
?dataset ?pred ?obj.
}
UNION
{
#Fussnoten
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:FUSSNOTE ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Glossar
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:GLOSSAR ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Quelle
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:QUELLE ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Erwartetes Aktualisierungsdatum
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:ERWARTETE_AKTUALISIERUNG ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Letztes Aktualisierungsdatum
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:DATENSTAND ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Korrektur
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:KORREKTUR ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
UNION
{
#Bezugszeit
SELECT DISTINCT ?dataset ?pred ?obj WHERE{
?obs a qb:Observation;
attribute:BEZUGSZEIT ?obj;
?pred ?obj;
qb:dataSet ?dataset.
}
}
}
ORDER BY ?pred
The first two subqueries simply extract the license and unitMeasure for every DataSet. The other subqueries SELECT all DISTINCT metadata of the Observations of an individual DataSet.
For a randomly selected DataSet, this query extracts all nodes with a path length equal to one, originating from the central node:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX : <arbitrary:relation>
SELECT DISTINCT ?dataset ?pred ?property
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
SELECT ?dataset WHERE{
?dataset skos:notation "AST-RAUM-ZEIT-BTA".
#?dataset a qb:DataSet.
#FILTER REGEX(STR(?dataset), "stadt-zuerich").
}
ORDER BY RAND()
LIMIT 1
}
{?dataset (:|!:) ?property. ?dataset ?pred ?property}
}
ORDER BY DESC(?property)
First a DataSet is selected, either randomly (switch the comments in the subselect) or a specific one, then the query tests the relationships originating from the cetral node https://ld.stadt-zuerich.ch/statistics/dataset/<DataSet>. The property path (:|!:) checks wheter there is a relation connecting two resources and ?dataset ?pred ?property matches these relation. The following list gives an overview of the required regular expressions:
- (a|b) means either path a OR b
- !a means negation, i.e. NOT a
- ^a means the inverse path of a (graph is traversed in reverse direction)
- a/b means a sequence of path a followed by b
- a? is a path that connects the subject and object by zero OR one match of a
- a* is a path that connects the subject and object by zero or more matches of a
- a+ is a path that connects the subject and object by one or more matches of a
- : is an empty and arbitrary relation, e.g. PREFIX : arbitrary:relation
Every relation is certainly either : OR !: which implies that the property path simply matches all paths of lenght or depth equal to one.
Let's say we want to CONSTRUCT the whole LOSD graph or subgraphs for visualisation purposes. Would the expression above be enough to completely traverse a graph? NO, because if we want to traverse a directed graph in both directions, we have to consider inverse paths of the form ^(:|!:) as well. To match every single path one would need the following subquery:
{<origin> ((:|!:)|^(:|!:))* ?sub. ?sub ?pred ?obj}
which can then be used in a CONSTRUCT query (after replacing
>SPARQL
PREFIX : <arbitrary:relation>
CONSTRUCT{?sub ?pred ?obj}
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{<origin> ((:|!:)|^(:|!:))* ?sub. ?sub ?pred ?obj}
LIMIT 100
Note that you can change the output format of such CONSTRUCT queries through the SPARQL-Interface (RDF-XML, JSON, Turtle etc.). Other options are available such as URL arguments or HTTP headers:

For a randomly selected Observation, this query extracts all nodes with a path length equal to one, originating from the central node:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX : <arbitrary:relation>
SELECT DISTINCT ?observation ?pred ?property
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
{
SELECT ?observation WHERE{
?observation skos:notation "Z31121978R00031ASTBTA5005XXX0000XXX0000XXX0000XXX0000".
#?observation a qb:Observation.
#FILTER REGEX(STR(?observation), "stadt-zuerich").
}
ORDER BY RAND()
LIMIT 1
}
{?observation (:|!:) ?property. ?observation ?pred ?property}
}
ORDER BY ?property
First an Observation is selected, either randomly (switch the comments in the subselect) or a specific one, then the query tests the relationships originating from the cetral node https://ld.stadt-zuerich.ch/statistics/dataset/<Observation>. The property path (:|!:) checks wheter there is a relation connecting two resources and ?dataset ?pred ?property matches these relations. For more detail see the previous section.
This query shall display the evolution of plot area, without forest, in Zurich over the years. We can extract the respective DataSet and code with the help of a FILTER REGEX(), for instance. The data is then plotted with the Google Chart feature of the SPARQL-Interface (a plot via notebook is not possible):
>SPARQL
BASE <https://ld.stadt-zuerich.ch/statistics/>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?year ?area
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?observation qb:dataSet <dataset/STF-RAUM-ZEIT-BBA>;
<measure/STF> ?area;
<property/ZEIT> ?date;
<property/BBA>/skos:notation ?Bodenbedeckungsart;
<property/RAUM>/skos:notation ?Raum.
#required for Google Chart
BIND(SUBSTR(STR(?date),1,4) AS ?year).
#set Raum=Zurich and Bodenbedeckungsart=Land area without forest
FILTER(?Raum IN ("R30000")).
FILTER(?Bodenbedeckungsart IN ("BBA1000")).
}
ORDER BY ?year
| year | area |
|---|---|
| 1934 | 6473.1 |
| 1935 | 6473.1 |
| 1936 | 6473.1 |
| 1937 | 6473.1 |
| 1938 | 6504.4 |
| 1939 | 6504.4 |
| 1940 | 6504.4 |
| 1941 | 6382.2 |
| 1942 | 6403.6 |
| 1943 | 6403.6 |
| 1944 | 6406.3 |
| 1945 | 6530.6 |
| 1946 | 6493.4 |
| 1947 | 6493.3 |
| 1948 | 6493.6 |
| 1949 | 6494.4 |
| 1950 | 6494.4 |
| 1951 | 6495.4 |
| 1952 | 6494.0 |
| 1953 | 6494.0 |

- R30000: Zurich City
- BBA: Bodenbedeckungsart https://ld.stadt-zuerich.ch/statistics/property/BBA
- BBA1000: Plot area without forest https://ld.stadt-zuerich.ch/statistics/code/BBA1000
- unitMeasure of plot area: Hectare https://ld.stadt-zuerich.ch/statistics/measure/STF
- the year has to be extracted from the date and bound to a String value for Google Chart to plot it properly
This query uses the Google Chart feature of the SPARQL interface and is not displayable by the notebook. Google Chart offers various chart types along with font, color, axis and other customization options:

This query corresponds to the year book excerpt in section 3.2. A single measurement of the residential population in dependance of homeland, sex and urban district in the year 2016 shall be given for the district "Rathaus":
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?Observation a qb:Observation;
qb:dataSet dataset:BEW-RAUM-ZEIT-HEL-SEX;
measure:BEW ?Bevoelkerung;
property:RAUM ?Raum;
property:ZEIT ?Zeit;
property:HEL ?Herkunft;
property:SEX ?Geschlecht.
FILTER (YEAR(?Zeit)=2016 && ?Raum=code:R00011 && ?Herkunft=code:HEL1000 && ?Geschlecht=code:SEX0002)
}
ORDER BY ?Zeit
| Observation | Bevoelkerung | Raum | Zeit | Herkunft | Geschlecht |
|---|---|---|---|---|---|
| https://ld.stadt-zuerich.ch/statistics/observation/BEW/R00011/Z31122016/HEL1000/SEX0002 | 1090.0 | https://ld.stadt-zuerich.ch/statistics/code/R00011 | 2016-12-31 | https://ld.stadt-zuerich.ch/statistics/code/HEL1000 | https://ld.stadt-zuerich.ch/statistics/code/SEX0002 |
With HEL1000 corresponding to swiss origin and SEX0002 representing female, the query result indeed agrees with the statistical table of the yearbook:

The number of unemployed citizens in the district "Rathaus" as a function of time shall be given:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT ?unemployed ?year
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE {
?observation a qb:Observation;
qb:dataSet dataset:ABL-RAUM-ZEIT;
measure:ABL ?unemployed;
property:RAUM ?Raum;
property:ZEIT ?Zeit.
BIND(SUBSTR(STR(?Zeit), 1, 4) as ?year)
FILTER (?Raum=code:R00011)
}
ORDER BY ?Zeit
| unemployed | year |
|---|---|
| 88.0 | 2004 |
| 60.0 | 2005 |
| 35.0 | 2006 |
| 35.0 | 2007 |
| 37.0 | 2008 |
| 55.0 | 2009 |
| 63.0 | 2010 |
| 45.0 | 2011 |
| 47.0 | 2012 |
| 59.0 | 2013 |
| 60.0 | 2014 |
| 66.0 | 2015 |
| 62.0 | 2016 |
All observations of the respective DataSet are extracted along with their values for the measure and dimensions (only Raum and Zeit in this case). The year is bound to a separate variable and the query then finalized by filtering out all measurements in the Rathaus district. Feel free to test this query in the interface and plot it in a Google Chart!
The conjunction and combination of data is considerably simplified thanks to the data harmonization. As an example, the difference between births and deaths in Zurich as a function of the year shall be calculated:
>SPARQL
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT ?year (SUM(?births) AS ?births) (SUM(?deaths) AS ?deaths) (SUM(?difference) AS ?difference)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?observation a qb:Observation;
property:RAUM ?Raum;
property:ZEIT ?Zeit.
#extract births
{
?observation qb:dataSet dataset:GEB-RAUM-ZEIT;
measure:GEB ?births.
BIND(?births AS ?difference)
}
UNION
#extract deaths
{
?observation qb:dataSet dataset:GES-RAUM-ZEIT;
measure:GES ?deaths.
BIND(?deaths*-1 AS ?difference)
}
#Raum = Zurich
FILTER(?Raum = code:R30000)
#date2year as string for Google Chart
BIND(SUBSTR(STR(?Zeit),1,4) AS ?year)
}
GROUP BY ?year
ORDER BY ?year
| year | births | deaths | difference |
|---|---|---|---|
| 1980 | 2953.0 | 4482.0 | -1529.0 |
| 1981 | 2989.0 | 4480.0 | -1491.0 |
| 1982 | 3076.0 | 4453.0 | -1377.0 |
| 1983 | 2994.0 | 4540.0 | -1546.0 |
| 1984 | 2984.0 | 4328.0 | -1344.0 |
| 1985 | 2953.0 | 4448.0 | -1495.0 |
| 1986 | 2986.0 | 4489.0 | -1503.0 |
| 1987 | 2942.0 | 4281.0 | -1339.0 |
| 1988 | 3036.0 | 4241.0 | -1205.0 |
| 1989 | 3044.0 | 4228.0 | -1184.0 |
| 1990 | 3046.0 | 4330.0 | -1284.0 |
| 1991 | 3342.0 | 4248.0 | -906.0 |
| 1992 | 3406.0 | 4148.0 | -742.0 |
| 1993 | 3400.0 | 4048.0 | -648.0 |
| 1994 | 3483.0 | 4187.0 | -704.0 |
| 1995 | 3419.0 | 4168.0 | -749.0 |
| 1996 | 3430.0 | 4105.0 | -675.0 |
| 1997 | 3459.0 | 4046.0 | -587.0 |
| 1998 | 3455.0 | 3972.0 | -517.0 |
| 1999 | 3489.0 | 3948.0 | -459.0 |

This query uses the Google Chart feature of the SPARQL interface and is not displayable by the notebook. Google Chart offers various chart types along with font, color, axis and other customization options. The BIND command merges the births AND the -deaths value (of every year) into ?difference thanks to the UNION of both subqueries (without UNION, BIND would overwrite ?difference). COUNT then adds or subtracts them respectively.
The following query is a bit more difficult because it relies on Wikidata vocabulary. Its objective is to show the differences in population numbers between SSZ and Wikidata. Only those entries are matched, for which the SSZ and Wikidata population numbers are different and the measurement happened in the same year. This example is a particular nice illustration of the benefits and significance of Linked Data. Without it and SPARQL, this comparison would have been possible only with multiple tools and a tremendous amount of work!
>SPARQL
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX wdt: <http://www.wikidata.org/prop/direct/>
PREFIX wd: <http://www.wikidata.org/entity/>
PREFIX pq: <http://www.wikidata.org/prop/qualifier/>
PREFIX ps: <http://www.wikidata.org/prop/statement/>
PREFIX p: <http://www.wikidata.org/prop/>
PREFIX wikibase: <http://wikiba.se/ontology#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX dimension: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX attribute: <https://ld.stadt-zuerich.ch/statistics/attribute/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT DISTINCT ?Raum ?RaumLabel ?ZeitSSZ ?WikiDate ?WikidataUID ?BevSSZ ?BevWiki ?Rank
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?sub a qb:Observation;
qb:dataSet dataset:BEW-RAUM-ZEIT;
measure:BEW ?Bevoelkerung;
dimension:RAUM ?Raum;
dimension:ZEIT ?ZeitSSZ.
?Raum owl:sameAs ?WikidataUID;
skos:broader code:Quartier;
rdfs:label ?RaumLabel.
BIND(xsd:decimal(?Bevoelkerung) AS ?BevSSZ)
BIND(xsd:dateTime(CONCAT(SUBSTR(STR(?ZeitSSZ),1,4),"-01-01T00:00:00Z")) AS ?WikiDate)
SERVICE <https://query.wikidata.org/bigdata/namespace/wdq/sparql>{
SELECT ?BevWiki ?WikiDate ?WikidataUID ?Rank
WHERE{
?WikidataUID wdt:P31 wd:Q19644586;
p:P1082 ?EinwohnerProperty.
?EinwohnerProperty ps:P1082 ?BevWiki;
pq:P585 ?WikiDate;
wikibase:rank ?Rank.
}
}
}
HAVING (?BevSSZ != ?BevWiki)
ORDER BY DESC(?ZeitSSZ)
LIMIT 100
- Here is the list of the PREFIXes and explanations of them
- Here is the Wikidata introduction to SPARQL queries
Except for the Wikidata vocabulary, the query is not that difficult:
- BIND to display the SSZ population (double) in the same format as Wikidata (decimal) as well as extending the SSZ Zeit (xsd:date) to the WikidataDate (xsd:dateTime) with matching years
- SERVICE to give the Wikidata SELECT access to the Wikidata SPARQL endpoint
- HAVING to select only those matches for which the population numbers are different
The GeoSPARQL ontology in conjunction with the SPARQL interface enable us to query and visualize area maps. The following query extracts the "Kreis" districts of Zurich in the form of coordinate shapes (magic is deliberately false for proper display in markdown):
SPARQLx
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?raum rdfs:label ?raumLabel;
skos:broader code:Kreis;
geo:hasGeometry/geo:asWKT ?shape.
}
?raum skos:broader code:Kreismatchtes all the "Kreis" districts of Zurichgeo:hasGeometryconnects ?raum to its geometriesgeo:asWKTlinks the geometry entities to the geometry literal representations. Values for these properties use the geo-sf:WKTLiteral data type.
See the GeoSPARQL documentation for further explanations.
The result can then be visualized as a map with the Geo function of the SPARQL interface:

If we now incorporate the dataset "BEW-RAUM-ZEIT", for example, we are able to display the population measurements depending on the "Kreis" district for a given date (magic is deliberately false for proper display in markdown):
SPARQLx
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX skos: <http://www.w3.org/2004/02/skos/core#>
PREFIX geo: <http://www.opengis.net/ont/geosparql#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT *
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?obs a qb:Observation;
qb:dataSet dataset:BEW-RAUM-ZEIT;
measure:BEW ?bew;
property:RAUM ?raum;
property:ZEIT "2000-12-31"^^xsd:date.
?raum rdfs:label ?raumLabel;
skos:broader code:Kreis;
geo:hasGeometry/geo:asWKT ?shape.
BIND(CONCAT(STR(?raumLabel), ": ", STR(?bew)) AS ?shapeLabel)
}
The result is again visualized as a map with the Geo function:

The querying of LOSData in RStudio is made possible through the SPARQL package (has dependencies on the RCurl package). Its short documentation can be found here. As a first example, we shall execute the query all DataSets. The main function is SPARQL() which, after receiving the endpoint, query and http auth credentials as input, fetches the results as a list. The do.call() method then converts this impractical list into a data.frame:
>R
install.packages("RCurl")
install.packages("SPARQL")
library(RCurl)
library(SPARQL)
endpoint <- 'https://lindas-data.ch:8443/lindas/query'
query <- 'PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?dataset ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?dataset a qb:DataSet;
rdfs:label ?label.
}
LIMIT 10'
rawResults <- SPARQL(endpoint,query,curl_args=c('userpwd'=paste('public',':','public',sep='')))
results <- do.call(rbind.data.frame, results)
View(results)
View(results):

The package ggplot2 allows us to plot data like we did with Google Chart in query conjunction of Kennzahlen, for example. For proper plotting we first we have to convert string values back to numeric values with the function as.numeric(). And for queries which select multiple y values for some x values (as it is the case in this particular example), we have to tell ggplot which column of the data.frame corresponds to the x values. This is done by the melt() function. Note that documentation of a method is displayed by ??<function name>. The following query executes and plots conjunction of Kennzahlen in RStudio:
>R
install.packages("reshape")
install.packages("ggplot2")
library(RCurl)
library(SPARQL)
library(reshape)
library(ggplot2)
endpoint <- 'https://lindas-data.ch:8443/lindas/query'
query <- 'PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT ?year (SUM(?births) AS ?births) (SUM(?deaths) AS ?deaths) (SUM(?difference) AS ?difference)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?observation a qb:Observation;
property:RAUM ?Raum;
property:ZEIT ?Zeit.
#extract births
{
?observation qb:dataSet dataset:GEB-RAUM-ZEIT;
measure:GEB ?births.
BIND(?births AS ?difference)
}
UNION
#extract deaths
{
?observation qb:dataSet dataset:GES-RAUM-ZEIT;
measure:GES ?deaths.
BIND(?deaths*-1 AS ?difference)
}
#Raum = Zurich
FILTER(?Raum = code:R30000)
#date2string for Google Chart
BIND(SUBSTR(STR(?Zeit),1,4) AS ?year)
}
GROUP BY ?year
ORDER BY ?year'
rawResults <- SPARQL(endpoint,query,curl_args=c('userpwd'=paste('public',':','public',sep='')))
results <- do.call(rbind.data.frame, rawResults)
View(results)
results$year = as.numeric(as.character(results$year))
results.melted <- melt(results, id = "year")
p <- ggplot(data = results.melted, aes(x = year, y = value, color = variable, group = variable)) + geom_point() +
geom_line() + scale_x_continuous(breaks = scales::pretty_breaks(n = 10)) +
scale_y_continuous(breaks = scales::pretty_breaks(n = 10)) + labs(y = "count")
plot(p)
View(results):

plot(p):

To query the LOSData in Python, we need the library SPARQLWrapper. For visualization we use Matplotlib, which allows for simple MATLAB-like plotting. Other useful libraries for working with RDF and graph databases in general, include RDFLib and RDFLib-jsonld. The libraries can be installed with pip:
pip install sparqlwrapper
pip install matplotlib
pip install rdflib
pip install rdflib-jsonld
As a first example, we shall execute the query all DataSets. SPARQLWrapper first creates the sparql instance from the endpoint, then various methods are called to set the http auth credentials, potential http headers, the query and return format. The allowed parameters are best examined in the configuration tab of the SPARQL interface whereas the format of these parameters can be found on the YASGUI github page. The main function is queryAndconvert() which, after receiving the endpoint, query and http auth credentials as input, fetches the results as a Python dictionary in json format:
>Python3
from SPARQLWrapper import SPARQLWrapper, JSON #XML, CSV etc.
sparql = SPARQLWrapper("https://lindas-data.ch:8443/lindas/query")
sparql.setHTTPAuth("BASIC")
sparql.setCredentials("public","public")
#sparql.addCustomHttpHeader("acceptHeaderSelect","application/sparql-results+xml")
sparql.setQuery("""
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?dataset ?label
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?dataset a qb:DataSet;
rdfs:label ?label.
}
LIMIT 10
""")
sparql.setReturnFormat(JSON)
results = sparql.queryAndConvert()
for result in results["results"]["bindings"]:
print('%s \t %s' % (result["dataset"]["value"], result["label"]["value"]))
https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BTA Arbeitsstätten nach Betriebsart, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/BES-RAUM-ZEIT-BTA-SEX Beschäftigte nach Betriebsart, Raum, Geschlecht, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/BES-RAUM-ZEIT-BTA Beschäftigte nach Betriebsart, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/ZUS-RAUM-ZEIT-BTA-HEL Zuschauer/innen, Besucher/innen nach Betriebsart, Heimatland, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/ZUS-RAUM-ZEIT-BTA-SEX Zuschauer/innen, Besucher/innen nach Betriebsart, Raum, Geschlecht, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/ZUS-RAUM-ZEIT-BTA Zuschauer/innen, Besucher/innen nach Betriebsart, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/SCH-RAUM-ZEIT-BTA-SST Schüler/innen und Student/innen nach Betriebsart, Raum, Schulstufen und Fächer, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/SCH-RAUM-ZEIT-BTA Schüler/innen und Student/innen nach Betriebsart, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/AST-RAUM-ZEIT-BEW-BTA Arbeitsstätten nach Bewilligung, Betriebsart, Raum, Zeit
https://ld.stadt-zuerich.ch/statistics/dataset/BEW-RAUM-ZEIT Wirtschaftliche Wohnbevölkerung nach Raum, Zeit
The execution and plotting of example query conjunction of Kennzahlen in Python is even simpler than R (with the exception of the legend). We have to convert the dictionary values to float() (remember that ?year was selected as string) and consider that label='births' would add a label in every loop iteration. We can avoid this by checking with get_legend_handles_labels() if the legend already includes a particular label.
>Python3
import matplotlib.pyplot as plt
from SPARQLWrapper import SPARQLWrapper, JSON #XML, CSV etc.
sparql = SPARQLWrapper("https://lindas-data.ch:8443/lindas/query")
sparql.setHTTPAuth("BASIC")
sparql.setCredentials("public","public")
sparql.addCustomHttpHeader("acceptHeaderSelect","application/sparql-results+json")
sparql.setQuery("""
PREFIX qb: <http://purl.org/linked-data/cube#>
PREFIX dataset: <https://ld.stadt-zuerich.ch/statistics/dataset/>
PREFIX measure: <https://ld.stadt-zuerich.ch/statistics/measure/>
PREFIX property: <https://ld.stadt-zuerich.ch/statistics/property/>
PREFIX code: <https://ld.stadt-zuerich.ch/statistics/code/>
SELECT ?year (SUM(?births) AS ?births) (SUM(?deaths) AS ?deaths) (SUM(?difference) AS ?difference)
FROM <https://linked.opendata.swiss/graph/zh/statistics>
WHERE{
?observation a qb:Observation;
property:RAUM ?Raum;
property:ZEIT ?Zeit.
#extract births
{
?observation qb:dataSet dataset:GEB-RAUM-ZEIT;
measure:GEB ?births.
BIND(?births AS ?difference)
}
UNION
#extract deaths
{
?observation qb:dataSet dataset:GES-RAUM-ZEIT;
measure:GES ?deaths.
BIND(?deaths*-1 AS ?difference)
}
#Raum = Zurich
FILTER(?Raum = code:R30000)
#date2year as string for plotting
BIND(SUBSTR(STR(?Zeit),1,4) AS ?year)
}
GROUP BY ?year
ORDER BY ?year
""")
sparql.setReturnFormat(JSON)
results = sparql.queryAndConvert()
for result in results["results"]["bindings"]:
print('%s \t %s \t %s \t %s' %(result["year"]["value"], result["births"]["value"], result["deaths"]["value"], result["difference"]["value"]))
plt.xlabel('year')
plt.ylabel('count')
plt.grid(True)
for result in results["results"]["bindings"]:
plt.plot(float(result["year"]["value"]), float(result["births"]["value"]),'bo', label='births' if 'births' not in plt.gca().get_legend_handles_labels()[1] else '')
plt.plot(float(result["year"]["value"]), float(result["deaths"]["value"]),'ro', label='deaths' if 'deaths' not in plt.gca().get_legend_handles_labels()[1] else '')
plt.plot(float(result["year"]["value"]), float(result["difference"]["value"]),'go', label='difference' if 'difference' not in plt.gca().get_legend_handles_labels()[1] else '')
plt.legend()
plt.show()
1980 2953.0 4482.0 -1529.0
1981 2989.0 4480.0 -1491.0
1982 3076.0 4453.0 -1377.0
1983 2994.0 4540.0 -1546.0
1984 2984.0 4328.0 -1344.0
1985 2953.0 4448.0 -1495.0
1986 2986.0 4489.0 -1503.0
1987 2942.0 4281.0 -1339.0
1988 3036.0 4241.0 -1205.0
1989 3044.0 4228.0 -1184.0
1990 3046.0 4330.0 -1284.0
1991 3342.0 4248.0 -906.0
1992 3406.0 4148.0 -742.0
1993 3400.0 4048.0 -648.0
1994 3483.0 4187.0 -704.0
1995 3419.0 4168.0 -749.0
1996 3430.0 4105.0 -675.0
1997 3459.0 4046.0 -587.0
1998 3455.0 3972.0 -517.0
1999 3489.0 3948.0 -459.0
2000 3577.0 3996.0 -419.0
2001 3472.0 3943.0 -471.0
2002 3553.0 3726.0 -173.0
2003 3629.0 3809.0 -180.0
2004 3791.0 3568.0 223.0
2005 3895.0 3604.0 291.0
2006 4029.0 3438.0 591.0
2007 4119.0 3480.0 639.0
2008 4349.0 3448.0 901.0
2009 4639.0 3417.0 1222.0
2010 4588.0 3395.0 1193.0
2011 4760.0 3290.0 1470.0
2012 4678.0 3330.0 1348.0
2013 4920.0 3465.0 1455.0
2014 5145.0 3334.0 1811.0
2015 5191.0 3400.0 1791.0
2016 5176.0 3178.0 1998.0
2017 5240.0 3279.0 1961.0

SSZVIS is a visualization library of Statistik Stadt Zürich. The data model and the chart system is defined here.
The resources can be found here:
- https://www.npmjs.com/package/sszvis
- https://github.com/statistikstadtzuerich/sszvis-components
- https://github.com/statistikstadtzuerich/stip-frontend
- http://stip-frontend-docs.interactivethings.io/
- http://www.catalog.style/
An example:

Statistik Stadt Zürich provides the code for LOSD under the BSD-3-Clause license. The code can freely be used but no support will be provided by Statistik Stadt Zürich.
Relevant repositories: