You signed in with another tab or window. Reload to refresh your session.You signed out in another tab or window. Reload to refresh your session.You switched accounts on another tab or window. Reload to refresh your session.Dismiss alert
因为浏览器无法直接使用HTML/SVG/XHTML,因此当浏览器客户端从服务器那接受到HTML文档后,就会遍历文档节点,然后对这些文档节点通过HTML解析器进行解析,最后生成DOM树,所生成的 DOM 树结构和HTML标签一一对应。在这其中HTML解析器会进行诸如:标记化算法,树构建算法等操作,其中的规范即遵循了W3C的相应规范,也都有浏览器引擎自己的一些特定的操作,详情可以翻阅这篇非常著名的文章:
一、浏览器如何渲染网页
要了解浏览器渲染页面的过程,首先得知道一个名词——关键路径渲染。关键渲染路径(Critical Rendering Path)是指与当前用户操作有关的内容。例如用户在浏览器中打开一个页面,其中页面所显示的东西就是当前用户操作相关的内容,也就是浏览器从服务器那收到的HTML,CSS,JavaScript等相关资源,然后经过一系列处理后渲染出来web页面。实际抽象出来理解可以将这些步骤看作一个函数,就输入HTML,经过一层层的处理,最后输出像素。
而浏览器渲染的过程主要包括以下几步:
具体如下图过程如下图所示:
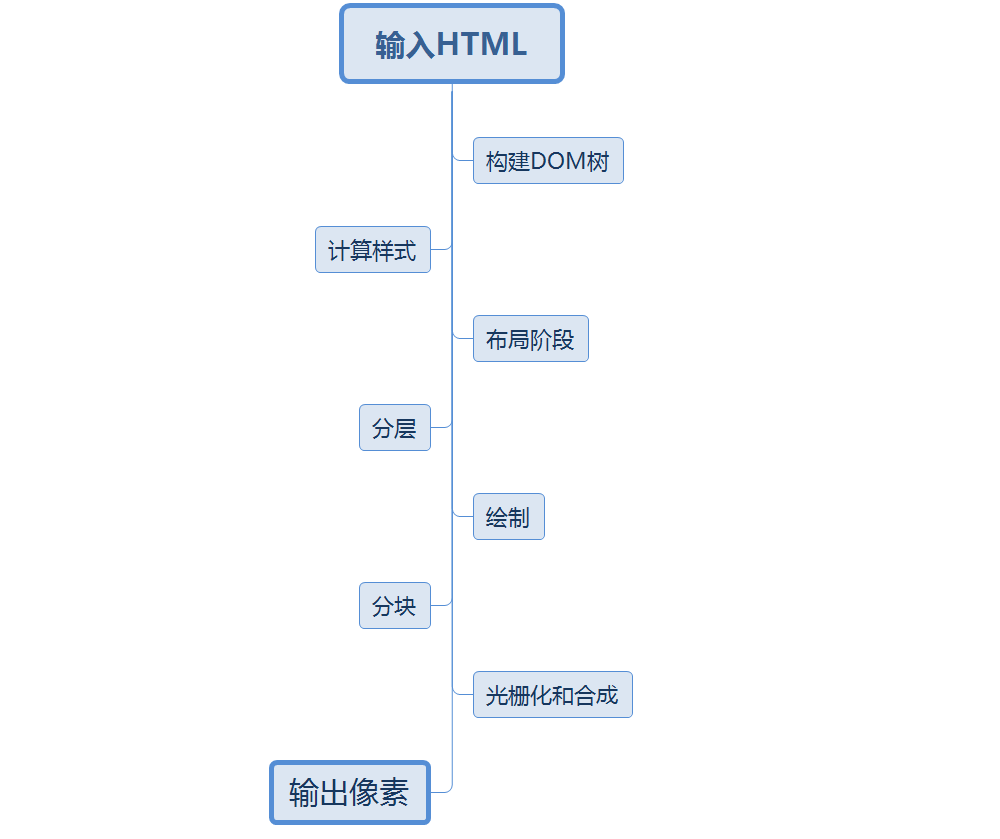
需要注意的是,以上几个步骤并不一定是一次性顺序完成,比如 DOM 被修改时,亦或是哪个过程会重复执行,这样才能计算出哪些像素需要在屏幕上进行重新渲染。而在实际情况中,JavaScript和CSS的某些操作往往会多次修改DOM或者CSSOM。
值得注意的的是,在每个阶段,都会有对应的输入,处理,以及输出。下面我们就来详细的了解一下这几个过程及需要注意的事项。
二、浏览器渲染网页的具体流程
2.1 构建DOM树
因为浏览器无法直接使用HTML/SVG/XHTML,因此当浏览器客户端从服务器那接受到HTML文档后,就会遍历文档节点,然后对这些文档节点通过HTML解析器进行解析,最后生成DOM树,所生成的 DOM 树结构和HTML标签一一对应。在这其中HTML解析器会进行诸如:标记化算法,树构建算法等操作,其中的规范即遵循了W3C的相应规范,也都有浏览器引擎自己的一些特定的操作,详情可以翻阅这篇非常著名的文章:
值得注意的是,HTML解析器并不是等整个文档全部加载完之后才开始解析的,而是网络进程加载了多少数据,HTML解析器就会解析多少数据。相当于在网络进程与渲染进程会在这期间建立一个数据共享的管道,网络进程每次收到数据都会通过这个管道将数据转发到渲染进程,从而保证渲染进程中的HTML解析器可以源源不断的获取到用于渲染的数据。这个过程可以理解为下方这个流程:

每个页面的DOM树,我们也可以直接通过在控制台输入document 来进行访问:

对于DOM树,我们需要注意以下几点:
此外DOM 树在构建的过程中可能会被 CSS 和 JS 给阻塞住,也就是我们常说的阻塞渲染。这是因为HTML文件是通过HTML解析器转化成 DOM 树的,而在HTML解析器中如果遇到了 JavaScript 脚本,HTML 解析器会先执行 JavaScript 脚本,待这个脚本执行完成之后,再继续往下解析。因此我们常说,将script标签放在body下面,通常就是基于这种考虑的。但为什么CSS也有可能会阻塞DOM树的构建呢,可以看下面一个栗子:
由于任何script代码都能改变HTML的结构,因此HTML每次遇到script都会停止解析,等待JavaScript引擎将这个JavaScript脚本执行完毕,然后再进行接下来的解析,这就是我们常说的JavaScript会阻塞渲染的原因。那为什么CSS也可能会阻塞DOM树的构建呢?这个是由于当我们通过 JavaScript 去进行样式操作的时候,这个 JavaScript 脚本执行完成的前提条件就成了需要现将样式信息加载以及确定下来,因此在这种情况下,HTML解析器在这里所需要等待的时间,也一定程度上取决于这个css文件的大小。这也是我们常说的,别在 JavaScript 中操作样式的原因。(这块的具体情况感兴趣的也可以去看《JavaScript忍者秘籍 第二版》)
为了优化这种情况,现代浏览器也做了一些优化,比如预解析操作。当渲染引擎接收到字节流后,会开启一个预解析线程,用来分析 HTML文件的代码中的JS,CSS文件,解析到相关文件的时候,预解析进行会提前下载这些资源。
对于处理这种事情,避免阻塞的产生,我们也有以下几点可以注意的:
2.2 计算样式
在构建渲染树时,需要计算每一个呈现对象的可视化的属性值。而这个过程就被称为样式计算或者计算样式。这个过程主要是为了 DOM 树中每个节点的具体样式,大致可分为三大步骤:
2.2.1 解析CSS
和html一个道理,浏览器也无法直接去理解我们所写的那些CSS样式,因此浏览器在接收到CSS文件后,会将CSS文件转换为浏览器所能理解的 StyleSheet。转化了的 StyleSheet 我们同样也可以通过控制台来访问:

在这个过程中需要注意的是:
2.2.2 标准化属性值
在将CSS文转化为浏览器能够理解的 styleSheet 后,就需要对期进行进行属性值的标准化操作了。这里的标准化的意思就是,我们在写css文件的时候,会写一些语义化的属性比如:red/bold等等。但其实这些词对于渲染引擎来说,却不是那么好理解的。因此在进行计算样式之前,浏览器还会这对这些不怎么好计算的值进行标准化,将其转化为渲染引擎容易理解的词,比如将red转化成为 rgb(255, 0, 0)等等。
2.2.3 计算具体样式
计算出 DOM 树中每个节点的具体样式主要涉及的就是CSS继承规则和层叠规则了,对于继承规则其实比较好理解,就是,每个DOM节点都包含的父节点的样式。
而层叠规则也就是样式层叠就有点麻烦了,MDN是这么描述层叠的:
层叠的具体细节在这里也不展开讲了(我自己现在还没搞清楚。。。),大家可以去CSS层叠看看其内部的一些规则。
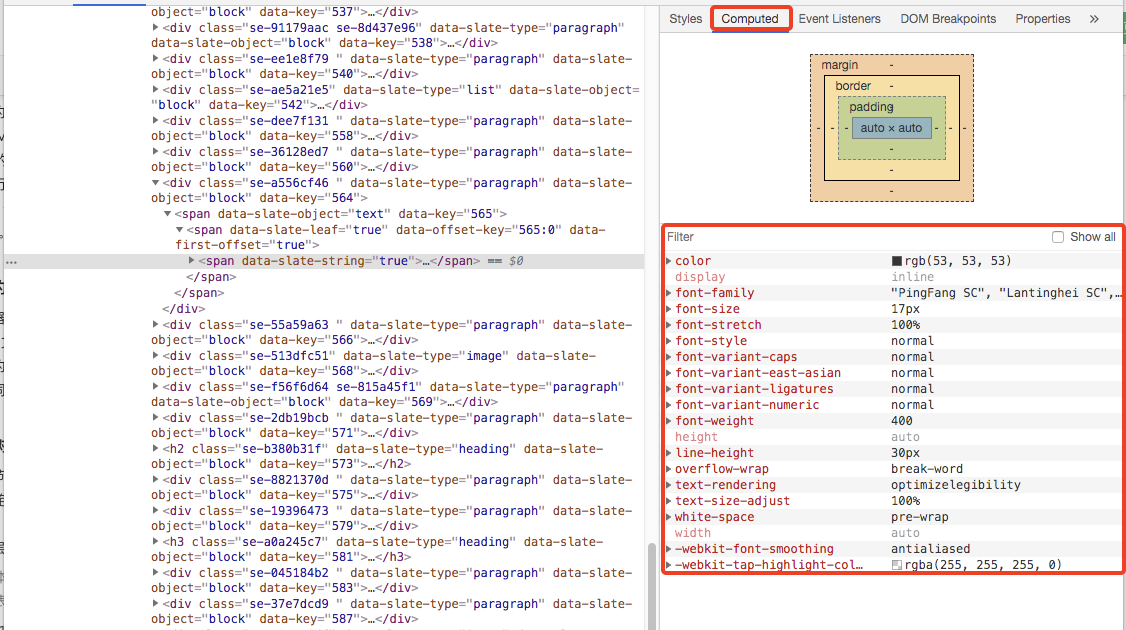
在有了css继承规则和层叠规则后,样式计算的这个阶段就会在这两个规则的基础上对 DOM 节点中的每个元素计算处具体的样式,这个阶段中最终输出的结果会保存在 ComputedStyle 中,这个同样可以通过控制台进行查看:
**
2.3 布局阶段
通过前面两个阶段,我们已经得到了DOM树以及DOM树中具体每个元素的样式了,但对于每个元素所处的几何位置我们现在还是不知道的,因此接下来要做的就是计算出DOM树中可见元素的几何位置。这个过程可以分为两个阶段:
2.3.1 创建布局树
由于DOM树还包含很多不可见的元素,比如head标签,script标签,以及设置为display:none的属性,因为浏览器势必不能将所有的dom树的元素都全部拿来进行布局计算,因此在这个阶段,浏览器会额外构建一颗只包含可见元素的布局树。在构建布局树期间,浏览器大体会进行以下一些工作:
下面两个需要注意:
2.3.2 布局计算
在已经获取了所有可见元素的树之后,就可以计算布局树节点的几何位置了。HTML是基于流的布局方式,因此大多数情况下,只需要进行一次遍历即刻计算出页面的几何信息。通常来说,处于流靠后的元素不会影响到靠前位置元素的几何特征,因此在进行布局计算的时候,通常是按从左至右,从上至下的顺序遍历文档(只是通常而言,比如表格啥的就不是这样)。
布局计算是一个递归的过程,它从根节点出发,然后递归遍历部分或所有的节点,为每一个需要计算的呈现器计算几何信息。这个计算量无疑是庞大的,因此为了避免一些较小的更改也会触发页面的整体布局计算,浏览器将布局方式分为了全局布局和增量布局。
在执行完布局计算后,会将布局计算的结果写入布局树中,因此这个过程可以理解为一种装饰者模式,输入输出都是一个布局树,只是在这个过程中会将布局计算的结果给加进去。
2.4 分层
在有了布局树之后,浏览器的还是不能直接根据布局树来将页面给画出来,因为页面中还存在中一些特殊的效果,比如页面滚动,z-index等。为了能够方便的实现这些花里胡哨的功能,渲染引擎还需要进行一个分层处理,将特定节点生成转筒的图层,并生成一个图层树(LayerTree),这个我们也能通过浏览器的面板看到:
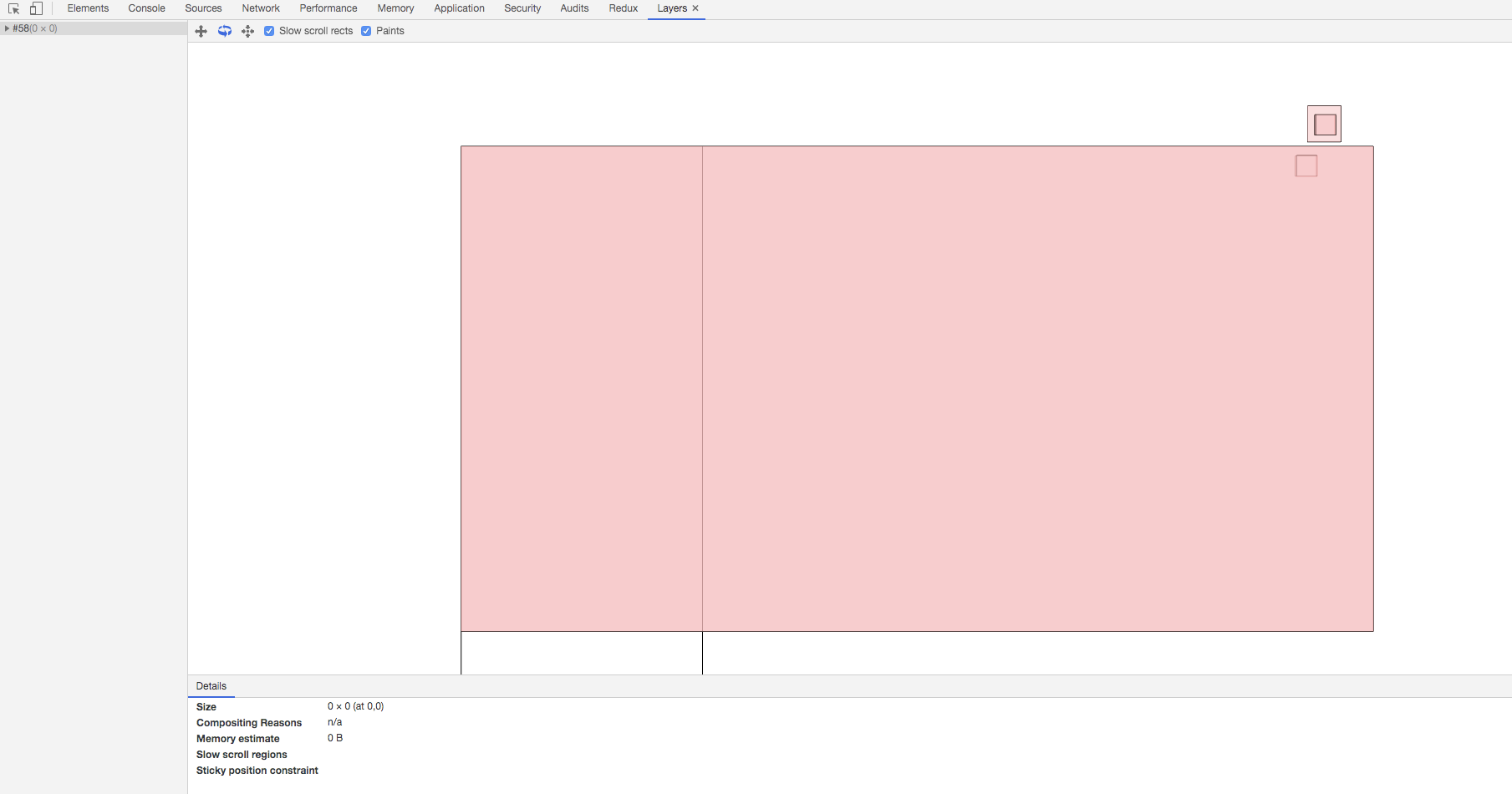
如上图所示,浏览器的页面实际上被分成了多个图层,这些图层叠加在一起就形成了我们最终所看到的页面。需要注意的是,并不是布局树中的每一个节点都会包含一个图层,因此如果一个节点没有所对应的图层,那么它就会从属于父节点的图层。如果一个节点需要有自己的图层,通常需要满足以下联合条件
2.5 图层绘制
在确定好图层之后,浏览器的渲染引擎会对图层树中的每个图层进行绘制,渲染引擎会将一个图层的绘制拆封成很多个小的绘制指令,然后会将这些绘制指令按照一定顺序组成一个待绘制列表。和布局相同,绘制也分为全局和增量两种,也是为了避免部分图层的改变而需要对整个图层树进行绘制。此外,CSS也对绘制顺序做了规定:
2.6 栅格化(raster)操作
这里的栅格化是指将图转化为位图。绘制列表只是用来记录绘制顺序和绘制指令的列表,而实际绘制操作是由渲染引擎中的合成线程来完成的。实际过程是当图层对应的绘制列表准备好之后,主线程会将绘制列表提交给合成线程。 合成线程会根据用户所能见的窗口范围对一些划分,将一些大的图层化分为图块。然后合成线程会根据用户所见范围附近的图块来优先生成位图,实际生成位图的操作是由栅格化来执行的。图块是栅格化执行的最小单元,渲染进程维护了一个栅格化的线程池,所有的图块栅格化操作都会在这个线程池里进行。
通常,栅格化会使用GPU进程中的GPU来进行加速,使用GPU进程生成位图的过程叫快速栅格化,通过这个方式生成的位图会被保存在GPU内存中。这样做的好处就在于,当渲染进程的主线程发生阻塞的时候,合成线程以及GPU进程不会受其影响,可以正常运行。这也是为啥有时候主线程卡住了,但CSS动画依然可以风骚依旧的原因。
2.7 合成和显示
在所有的图块都被进行栅格化后,合成线程就会生成绘制图块的命令——“DrawQuad”,然后将该命令提交给浏览器进程。浏览器进程里面有一个叫 viz 的组件,用来接收合成线程发过来的 DrawQuad 命令,然后根据 DrawQuad 命令,将其页面内容绘制到内存中,最后再将内存显示在屏幕上。
三、浏览器渲染网页的那些事儿
3.1 回流和重绘(reflow和repaint)
我们都知道HTML默认是流式布局的,但CSS和JS会打破这种布局,改变DOM的外观样式以及大小和位置。因此我们就需要知道两个概念:
需要注意的是,display:none 会触发 reflow,而visibility: hidden属性则并不算是不可见属性,它的语义是隐藏元素,但元素仍然占据着布局空间,它会被渲染成一个空框,这在我们上面有提到过。所以visibility:hidden 只会触发 repaint,因为没有发生位置变化。
我们不能避免reflow,但还是能通过一些操作来减少回流:
另外有些情况下,比如修改了元素的样式,浏览器并不会立刻reflow 或 repaint 一次,而是会把这样的操作积攒一批,然后做一次 reflow,这又叫异步 reflow 或增量异步 reflow。但是在有些情况下,比如resize 窗口,改变了页面默认的字体等。对于这些操作,浏览器会马上进行 reflow。
3.2 几条关于优化渲染效率的建议
结合上文和我看到的一些文章,有以下几点可以优化渲染效率
参考资料:
The text was updated successfully, but these errors were encountered: