From a9451e6d07ae90428e879db8951edde4cb7d42f2 Mon Sep 17 00:00:00 2001
From: Luke Kim <80174+lukekim@users.noreply.github.com>
Date: Wed, 27 Nov 2024 18:23:04 -0800
Subject: [PATCH] Documentation improvements for RC.1
---
.github/copilot-instructions.md | 5 ++
.../docs/components/embeddings/huggingface.md | 10 ++--
.../docs/components/embeddings/index.md | 11 +++--
.../docs/components/embeddings/local.md | 13 ++++--
.../docs/components/embeddings/openai.md | 22 ++++-----
.../docs/components/models/filesystem.md | 13 ++++--
spiceaidocs/docs/components/models/openai.md | 9 ++--
spiceaidocs/docs/components/models/spiceai.md | 2 +-
spiceaidocs/docs/components/views/index.md | 8 ++--
spiceaidocs/docs/features/cdc/index.md | 14 +++---
.../features/data-acceleration/constraints.md | 36 +++++++--------
.../docs/features/data-acceleration/index.md | 12 ++---
.../features/data-acceleration/indexes.md | 2 +-
.../docs/features/data-ingestion/index.md | 18 ++++----
.../docs/features/federated-queries/index.md | 8 ++--
.../features/large-language-models/index.md | 4 +-
.../features/large-language-models/memory.md | 11 +++--
.../parameter_overrides.md | 11 +++--
.../large-language-models/runtime_tools.md | 30 +++++++-----
.../ml-model-serving/index.md | 2 +-
spiceaidocs/docs/features/search/index.md | 2 +-
.../docs/features/semantic-model/index.md | 8 ++--
spiceaidocs/docs/index.md | 12 ++---
.../docs/intelligent-applications/index.md | 46 +++++++++++++++++--
.../docs/reference/spicepod/catalogs.md | 4 +-
.../docs/reference/spicepod/embeddings.md | 10 ++--
spiceaidocs/docs/reference/spicepod/index.md | 6 +--
spiceaidocs/docs/reference/spicepod/models.md | 22 +++++----
spiceaidocs/docs/use-cases/data-mesh/index.md | 8 ++--
.../docs/use-cases/database-cdn/index.md | 10 ++--
.../docs/use-cases/enterprise-search/index.md | 6 +--
spiceaidocs/docs/use-cases/rag/index.md | 4 +-
32 files changed, 218 insertions(+), 161 deletions(-)
diff --git a/.github/copilot-instructions.md b/.github/copilot-instructions.md
index cf5fdae3..7319ef74 100644
--- a/.github/copilot-instructions.md
+++ b/.github/copilot-instructions.md
@@ -6,13 +6,18 @@ Remember to be concise, but do not omit useful information. Pay attention to det
Use plain, clear, simple, easy-to-understand language. Do not use hyperbole or hype.
+Avoid "allows" to describe functionality.
+
Always provide references and citations with links.
Adhere to the instructions in CONTRIBUTING.md.
Never use the words:
+- delve
- seamlessly
- empower / empowering
- supercharge
- countless
+- enhance / enhancing
+- allow / allowing
diff --git a/spiceaidocs/docs/components/embeddings/huggingface.md b/spiceaidocs/docs/components/embeddings/huggingface.md
index 086c772d..0955fdb1 100644
--- a/spiceaidocs/docs/components/embeddings/huggingface.md
+++ b/spiceaidocs/docs/components/embeddings/huggingface.md
@@ -4,7 +4,10 @@ sidebar_label: 'HuggingFace'
sidebar_position: 2
---
-To run an embedding model from HuggingFace, specify the `huggingface` path in `from`. This will handle downloading and running the embedding model locally.
+To use an embedding model from HuggingFace with Spice, specify the `huggingface` path in the `from` field of your configuration. The model and its related files will be automatically downloaded, loaded, and served locally by Spice.
+
+Here is an example configuration in `spicepod.yaml`:
+
```yaml
embeddings:
- from: huggingface:huggingface.co/sentence-transformers/all-MiniLM-L6-v2
@@ -12,11 +15,12 @@ embeddings:
```
Supported models include:
- - All models tagged as [text-embeddings-inference](https://huggingface.co/models?other=text-embeddings-inference) on Huggingface
- - Any Huggingface repository with the correct files to be loaded as a [local embedding model](/components/embeddings/local.md).
+- All models tagged as [text-embeddings-inference](https://huggingface.co/models?other=text-embeddings-inference) on Huggingface
+- Any Huggingface repository with the correct files to be loaded as a [local embedding model](/components/embeddings/local.md).
With the same semantics as [language models](/components/models/huggingface#access-tokens), `spice` can run private HuggingFace embedding models:
+
```yaml
embeddings:
- from: huggingface:huggingface.co/secret-company/awesome-embedding-model
diff --git a/spiceaidocs/docs/components/embeddings/index.md b/spiceaidocs/docs/components/embeddings/index.md
index 092c7712..c2dc21b3 100644
--- a/spiceaidocs/docs/components/embeddings/index.md
+++ b/spiceaidocs/docs/components/embeddings/index.md
@@ -7,12 +7,12 @@ pagination_prev: null
pagination_next: null
---
-Embedding models are used to convert raw text into a numerical representation that can be used by machine learning models.
-
-Spice supports running embedding models locally, or use remote services such as OpenAI, or [la Plateforme](https://console.mistral.ai/).
+Embedding models convert raw text into numerical representations that can be used by machine learning models. Spice supports running embedding models locally or using remote services such as OpenAI or [la Plateforme](https://console.mistral.ai/).
Embedding models are defined in the `spicepod.yaml` file as top-level components.
+Example configuration in `spicepod.yaml`:
+
```yaml
embeddings:
- from: huggingface:huggingface.co/sentence-transformers/all-MiniLM-L6-v2
@@ -31,5 +31,6 @@ embeddings:
```
Embedding models can be used either by:
- - An OpenAI-compatible [endpoint](/api/http/embeddings.md)
- - By augmenting a dataset with column-level [embeddings](/reference/spicepod/datasets.md#embeddings), to provide vector-based [search functionality](/features/search/index.md#vector-search).
+
+- An OpenAI-compatible [endpoint](/api/http/embeddings.md)
+- By augmenting a dataset with column-level [embeddings](/reference/spicepod/datasets.md#embeddings), to provide vector-based [search functionality](/features/search/index.md#vector-search).
diff --git a/spiceaidocs/docs/components/embeddings/local.md b/spiceaidocs/docs/components/embeddings/local.md
index 910e9277..56518275 100644
--- a/spiceaidocs/docs/components/embeddings/local.md
+++ b/spiceaidocs/docs/components/embeddings/local.md
@@ -4,7 +4,11 @@ sidebar_label: 'Local'
sidebar_position: 3
---
-Embedding models can be run with files stored locally.
+Embedding models can be run with files stored locally. This method is useful for using models that are not hosted on remote services.
+
+### Example Configuration
+
+To configure an embedding model using local files, you can specify the details in the `spicepod.yaml` file as shown below:
```yaml
embeddings:
@@ -16,6 +20,7 @@ embeddings:
```
## Required Files
- - Model file, one of: `model.safetensors`, `pytorch_model.bin`.
- - A tokenizer file with the filename `tokenizer.json`.
- - A config file with the filename `config.json`.
+
+- Model file, one of: `model.safetensors`, `pytorch_model.bin`.
+- A tokenizer file with the filename `tokenizer.json`.
+- A config file with the filename `config.json`.
diff --git a/spiceaidocs/docs/components/embeddings/openai.md b/spiceaidocs/docs/components/embeddings/openai.md
index 6d25d530..6a4fd5d6 100644
--- a/spiceaidocs/docs/components/embeddings/openai.md
+++ b/spiceaidocs/docs/components/embeddings/openai.md
@@ -4,20 +4,18 @@ sidebar_label: 'OpenAI'
sidebar_position: 1
---
-To use a hosted OpenAI (or compatible) embedding model, specify the `openai` path in `from`.
+To use a hosted OpenAI (or compatible) embedding model, specify the `openai` path in the `from` field of your configuration. If you want to use a specific model, include its model ID in the `from` field. If no model ID is specified, it defaults to `"text-embedding-3-small"`.
-For a specific model, include it as the model ID in `from` (see example below). Defaults to `"text-embedding-3-small"`.
-These parameters are specific to OpenAI models:
+The following parameters are specific to OpenAI models:
-| Parameter | Description | Default |
-| ----- | ----------- | ------- |
-| `openai_api_key` | The OpenAI API key. | - |
-| `openai_org_id` | The OpenAI organization id. | - |
-| `openai_project_id` | The OpenAI project id. | - |
-| `endpoint` | The OpenAI API base endpoint. | `https://api.openai.com/v1` |
+| Parameter | Description | Default |
+| ------------------- | ------------------------------------- | --------------------------- |
+| `openai_api_key` | The API key for accessing OpenAI. | - |
+| `openai_org_id` | The organization ID for OpenAI. | - |
+| `openai_project_id` | The project ID for OpenAI. | - |
+| `endpoint` | The base endpoint for the OpenAI API. | `https://api.openai.com/v1` |
-
-Example:
+Below is an example configuration in `spicepod.yaml`:
```yaml
models:
@@ -31,4 +29,4 @@ models:
params:
endpoint: https://api.mistral.ai/v1
api_key: ${ secrets:SPICE_MISTRAL_API_KEY }
-```
\ No newline at end of file
+```
diff --git a/spiceaidocs/docs/components/models/filesystem.md b/spiceaidocs/docs/components/models/filesystem.md
index c0915893..11d155aa 100644
--- a/spiceaidocs/docs/components/models/filesystem.md
+++ b/spiceaidocs/docs/components/models/filesystem.md
@@ -5,7 +5,7 @@ sidebar_label: 'Filesystem'
sidebar_position: 3
---
-To use a model hosted on a filesystem, specify the path to the model file in `from`.
+To use a model hosted on a filesystem, specify the path to the model file in the `from` field.
Supported formats include ONNX for traditional machine learning models and GGUF, GGML, and SafeTensor for large language models (LLMs).
@@ -50,15 +50,17 @@ models:
```
### Example: Loading from a directory
+
```yaml
models:
- name: hello
from: file:models/llms/llama3.2-1b-instruct/
```
-Note: The folder provided should contain all the expected files (see examples above) to load a model in the base level.
+Note: The folder provided should contain all the expected files (see examples above) to load a model in the base level.
### Example: Overriding the Chat Template
+
Chat templates convert the OpenAI compatible chat messages (see [format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-messages)) and other components of a request
into a stream of characters for the language model. It follows Jinja3 templating [syntax](https://jinja.palletsprojects.com/en/3.1.x/templates/).
@@ -81,6 +83,7 @@ models:
```
#### Templating Variables
- - `messages`: List of chat messages, in the OpenAI [format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-messages).
- - `add_generation_prompt`: Boolean flag whether to add a [generation prompt](https://huggingface.co/docs/transformers/main/chat_templating#what-are-generation-prompts).
- - `tools`: List of callable tools, in the OpenAI [format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-tools).
+
+- `messages`: List of chat messages, in the OpenAI [format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-messages).
+- `add_generation_prompt`: Boolean flag whether to add a [generation prompt](https://huggingface.co/docs/transformers/main/chat_templating#what-are-generation-prompts).
+- `tools`: List of callable tools, in the OpenAI [format](https://platform.openai.com/docs/api-reference/chat/create#chat-create-tools).
diff --git a/spiceaidocs/docs/components/models/openai.md b/spiceaidocs/docs/components/models/openai.md
index 0ec53d19..e71769dc 100644
--- a/spiceaidocs/docs/components/models/openai.md
+++ b/spiceaidocs/docs/components/models/openai.md
@@ -5,16 +5,17 @@ sidebar_label: 'OpenAI'
sidebar_position: 4
---
-To use a language model hosted on OpenAI (or compatible), specify the `openai` path in `from`.
+To use a language model hosted on OpenAI (or compatible), specify the `openai` path in the `from` field.
+
+For a specific model, include it as the model ID in the `from` field (see example below). The default model is `"gpt-3.5-turbo"`.
-For a specific model, include it as the model ID in `from` (see example below). Defaults to `"gpt-3.5-turbo"`.
These parameters are specific to OpenAI models:
| Param | Description | Default |
| ------------------- | ----------------------------- | --------------------------- |
| `openai_api_key` | The OpenAI API key. | - |
-| `openai_org_id` | The OpenAI organization id. | - |
-| `openai_project_id` | The OpenAI project id. | - |
+| `openai_org_id` | The OpenAI organization ID. | - |
+| `openai_project_id` | The OpenAI project ID. | - |
| `endpoint` | The OpenAI API base endpoint. | `https://api.openai.com/v1` |
Example:
diff --git a/spiceaidocs/docs/components/models/spiceai.md b/spiceaidocs/docs/components/models/spiceai.md
index a64507dd..f886e3f3 100644
--- a/spiceaidocs/docs/components/models/spiceai.md
+++ b/spiceaidocs/docs/components/models/spiceai.md
@@ -5,7 +5,7 @@ sidebar_label: 'Spice Cloud Platform'
sidebar_position: 2
---
-To use a model hosted on the [Spice Cloud Platform](https://docs.spice.ai/building-blocks/spice-models), specify the `spice.ai` path in `from`.
+To use a model hosted on the [Spice Cloud Platform](https://docs.spice.ai/building-blocks/spice-models), specify the `spice.ai` path in the `from` field.
Example:
diff --git a/spiceaidocs/docs/components/views/index.md b/spiceaidocs/docs/components/views/index.md
index 38e75347..d0f8ad93 100644
--- a/spiceaidocs/docs/components/views/index.md
+++ b/spiceaidocs/docs/components/views/index.md
@@ -1,18 +1,20 @@
---
title: 'Views'
sidebar_label: 'Views'
-description: 'Documentation for defining Views'
+description: 'Documentation for defining Views in Spice'
sidebar_position: 7
---
-Views in Spice are virtual tables defined by SQL queries. They simplify complex queries and support reuse across applications.
+Views in Spice are virtual tables defined by SQL queries. They help simplify complex queries and promote reuse across different applications by encapsulating query logic in a single, reusable entity.
## Defining a View
-To define a view in `spicepod.yaml`, specify the `views` section. Each view requires a `name` and a `sql` field.
+To define a view in the `spicepod.yaml` configuration file, specify the `views` section. Each view definition must include a `name` and a `sql` field.
### Example
+The following example demonstrates how to define a view named `rankings` that lists the top five products based on the total count of orders:
+
```yaml
views:
- name: rankings
diff --git a/spiceaidocs/docs/features/cdc/index.md b/spiceaidocs/docs/features/cdc/index.md
index 030e3a6c..0c71557c 100644
--- a/spiceaidocs/docs/features/cdc/index.md
+++ b/spiceaidocs/docs/features/cdc/index.md
@@ -7,33 +7,33 @@ pagination_prev: null
pagination_next: null
---
-Change Data Capture (CDC) is a technique that captures changed rows from a database's transaction log and delivers them to consumers with low latency. Leveraging this technique enables Spice to keep [locally accelerated](../data-acceleration/index.md) datasets up-to-date in real time with the source data, and it is highly efficient as it only transfers the changed rows instead of re-fetching the entire dataset on refresh.
+Change Data Capture (CDC) captures changed rows from a database's transaction log and delivers them to consumers with low latency. This technique enables Spice to keep [locally accelerated](../data-acceleration/index.md) datasets up-to-date in real time with the source data. It is efficient because it only transfers the changed rows instead of re-fetching the entire dataset.
## Benefits
-Leveraging locally accelerated datasets configured with CDC enables Spice to provide a solution that combines high-performance accelerated queries and efficient real-time delta updates.
+Using locally accelerated datasets configured with CDC enables Spice to provide high-performance accelerated queries and efficient real-time updates.
## Example Use Case
-Consider a fraud detection application that needs to determine whether a pending transaction is likely fraudulent. The application queries a Spice-accelerated real-time updated table of recent transactions to check if a pending transaction resembles known fraudulent ones. Using CDC, the table is kept up-to-date, allowing the application to quickly identify potential fraud.
+Consider a fraud detection application that needs to determine whether a pending transaction is likely fraudulent. The application queries a Spice-accelerated, real-time updated table of recent transactions to check if a pending transaction resembles known fraudulent ones. With CDC, the table is kept up-to-date, allowing the application to quickly identify potential fraud.
## Considerations
When configuring datasets to be accelerated with CDC, ensure that the [data connector](/components/data-connectors) supports CDC and can return a stream of row-level changes. See the [Supported Data Connectors](#supported-data-connectors) section for more information.
-The startup time for CDC-accelerated datasets may be longer than that for non-CDC-accelerated datasets due to the initial synchronization of the dataset.
+The startup time for CDC-accelerated datasets may be longer than for non-CDC-accelerated datasets due to the initial synchronization.
:::tip
-It's recommended to use CDC-accelerated datasets with persistent data accelerator configurations (i.e. `file` mode for [`DuckDB`](/components/data-accelerators/duckdb.md)/[`SQLite`](/components/data-accelerators/sqlite.md) or [`PostgreSQL`](/components/data-accelerators/postgres/index.md)). This ensures that when Spice restarts, it can resume from the last known state of the dataset instead of re-fetching the entire dataset.
+It is recommended to use CDC-accelerated datasets with persistent data accelerator configurations (i.e., `file` mode for [`DuckDB`](/components/data-accelerators/duckdb.md)/[`SQLite`](/components/data-accelerators/sqlite.md) or [`PostgreSQL`](/components/data-accelerators/postgres/index.md)). This ensures that when Spice restarts, it can resume from the last known state of the dataset instead of re-fetching the entire dataset.
:::
## Supported Data Connectors
-Enabling CDC via setting `refresh_mode: changes` in the acceleration settings requires support from the data connector to provide a stream of row-level changes.
+Enabling CDC by setting `refresh_mode: changes` in the acceleration settings requires support from the data connector to provide a stream of row-level changes.
-At present, the only supported data connector is [Debezium](/components/data-connectors/debezium.md)..
+Currently, the only supported data connector is [Debezium](/components/data-connectors/debezium.md).
## Example
diff --git a/spiceaidocs/docs/features/data-acceleration/constraints.md b/spiceaidocs/docs/features/data-acceleration/constraints.md
index adaeeb73..d5c89718 100644
--- a/spiceaidocs/docs/features/data-acceleration/constraints.md
+++ b/spiceaidocs/docs/features/data-acceleration/constraints.md
@@ -5,11 +5,11 @@ sidebar_position: 2
description: 'Learn how to add/configure constraints on local acceleration tables in Spice.'
---
-Constraints are rules that enforce data integrity in a database. Spice supports constraints on locally accelerated tables to ensure data quality, as well as configuring the behavior for inserting data updates that violate constraints.
+Constraints enforce data integrity in a database. Spice supports constraints on locally accelerated tables to ensure data quality and configure behavior for data updates that violate constraints.
Constraints are specified using [column references](#column-references) in the Spicepod via the `primary_key` field in the acceleration configuration. Additional unique constraints are specified via the [`indexes`](./indexes.md) field with the value `unique`. Data that violates these constraints will result in a [conflict](#handling-conflicts).
-If there are multiple rows in the incoming data that violate any constraint, the entire incoming batch of data will be dropped.
+If multiple rows in the incoming data violate any constraint, the entire incoming batch of data will be dropped.
Example Spicepod:
@@ -72,9 +72,8 @@ datasets:
:::danger[Invalid]
- ```yaml
- datasets:
-
+ ```yaml
+ datasets:
- from: spice.ai/eth.recent_blocks
name: eth.recent_blocks
acceleration:
@@ -82,11 +81,11 @@ datasets:
engine: sqlite
primary_key: hash
indexes:
- "(number, timestamp)": unique
+ '(number, timestamp)': unique
on_conflict:
hash: upsert
- "(number, timestamp)": upsert
- ```
+ '(number, timestamp)': upsert
+ ```
:::
@@ -94,9 +93,8 @@ datasets:
:::tip[Valid]
- ```yaml
- datasets:
-
+ ```yaml
+ datasets:
- from: spice.ai/eth.recent_blocks
name: eth.recent_blocks
acceleration:
@@ -104,20 +102,20 @@ datasets:
engine: sqlite
primary_key: hash
indexes:
- "(number, timestamp)": unique
+ '(number, timestamp)': unique
on_conflict:
hash: drop
- "(number, timestamp)": drop
- ```
+ '(number, timestamp)': drop
+ ```
:::
The following Spicepod is invalid because it specifies multiple `on_conflict` targets with `upsert` and `drop`:
:::danger[Invalid]
- ```yaml
- datasets:
+ ```yaml
+ datasets:
- from: spice.ai/eth.recent_blocks
name: eth.recent_blocks
acceleration:
@@ -125,11 +123,11 @@ datasets:
engine: sqlite
primary_key: hash
indexes:
- "(number, timestamp)": unique
+ '(number, timestamp)': unique
on_conflict:
hash: upsert
- "(number, timestamp)": drop
- ```
+ '(number, timestamp)': drop
+ ```
:::
diff --git a/spiceaidocs/docs/features/data-acceleration/index.md b/spiceaidocs/docs/features/data-acceleration/index.md
index de44141e..92cd53dc 100644
--- a/spiceaidocs/docs/features/data-acceleration/index.md
+++ b/spiceaidocs/docs/features/data-acceleration/index.md
@@ -6,23 +6,23 @@ sidebar_position: 2
pagination_prev: null
---
-Datasets can be locally accelerated by the Spice runtime, pulling data from any [Data Connector](/components/data-connectors) and storing it locally in a [Data Accelerator](/components/data-accelerators) for faster access. Additionally, the data can be configured to be kept up-to-date in realtime or on a refresh schedule, so you always have the latest data locally for querying.
+Datasets can be locally accelerated by the Spice runtime, pulling data from any [Data Connector](/components/data-connectors) and storing it locally in a [Data Accelerator](/components/data-accelerators) for faster access. The data can be kept up-to-date in real-time or on a refresh schedule, ensuring you always have the latest data locally for querying.
## Benefits
-When a dataset is locally accelerated by the Spice runtime, the data is stored alongside your application, providing much faster query times by cutting out network latency to make the request. This benefit is accentuated when the result of a query is large because the data does not need to be transferred over the network. Depending on the [Acceleration Engine](/components/data-accelerators) chosen, the locally accelerated data can also be stored in-memory, further reducing query times. [Indexes](./indexes.md) can also be applied, further speeding up certain types of queries.
+Local data acceleration stores data alongside your application, providing faster query times by eliminating network latency. This is especially beneficial for large query results, as data transfer over the network is avoided. Depending on the [Acceleration Engine](/components/data-accelerators) used, data can also be stored in-memory, further reducing query times. [Indexes](./indexes.md) can be applied to speed up certain queries.
-Locally accelerated datasets can also have [primary key constraints](./constraints.md) applied. This feature comes with the ability to specify what should happen when a constraint is violated, either drop the specific row that violates the constraint or upsert that row into the accelerated table.
+Locally accelerated datasets can also have [primary key constraints](./constraints.md) applied. This feature allows specifying actions when a constraint is violated, such as dropping the violating row or upserting it into the accelerated table.
## Example Use Case
-Consider a high volume e-trading frontend application backed by an AWS RDS database containing a table of trades. In order to retrieve all trades over the last 24 hours, the application would need to query the remote database for all trades in the last 24 hours and then transfer the data over the network. By accelerating the trades table locally using the [AWS RDS Data Connector](https://github.com/spiceai/quickstarts/tree/trunk/rds-aurora-mysql), we can bring the data to the application, saving the round trip time to the database and the time to transfer the data over the network.
+Consider a high-volume e-trading frontend application backed by an AWS RDS database containing a table of trades. To retrieve all trades over the last 24 hours, the application would need to query the remote database and transfer the data over the network. By accelerating the trades table locally using the [AWS RDS Data Connector](https://github.com/spiceai/quickstarts/tree/trunk/rds-aurora-mysql), the data is brought to the application, saving round trip time and data transfer time.
## Considerations
-Data Storage: Ensure that the local storage has enough capacity to store the accelerated data. The amount and type (i.e. Disk or RAM) of storage required will depend on the size of the dataset and the acceleration engine used.
+Data Storage: Ensure local storage has enough capacity for the accelerated data. The required storage type (Disk or RAM) and amount depend on the dataset size and the acceleration engine used.
-Data Security: Assess data sensitivity and secure network connections between edge and data connector when replicating data for further usage. Assess the security of any Data Accelerator that is external to the Spice runtime and connected to the Spice runtime. Implement encryption, access controls, and secure protocols.
+Data Security: Assess data sensitivity and secure network connections between the edge and data connector when replicating data. Secure any external Data Accelerator connected to the Spice runtime with encryption, access controls, and secure protocols.
## Example
diff --git a/spiceaidocs/docs/features/data-acceleration/indexes.md b/spiceaidocs/docs/features/data-acceleration/indexes.md
index 34b17930..917e3017 100644
--- a/spiceaidocs/docs/features/data-acceleration/indexes.md
+++ b/spiceaidocs/docs/features/data-acceleration/indexes.md
@@ -5,7 +5,7 @@ sidebar_position: 1
description: 'Learn how to add indexes to local acceleration tables in Spice.'
---
-Database indexes are an essential tool for optimizing the performance of queries. Learn how to add indexes to the tables that Spice creates to accelerate data locally.
+Database indexes are essential for optimizing query performance. This document explains how to add indexes to tables created by Spice for local data acceleration.
Example Spicepod:
diff --git a/spiceaidocs/docs/features/data-ingestion/index.md b/spiceaidocs/docs/features/data-ingestion/index.md
index a3a7b313..12f20400 100644
--- a/spiceaidocs/docs/features/data-ingestion/index.md
+++ b/spiceaidocs/docs/features/data-ingestion/index.md
@@ -7,31 +7,31 @@ pagination_prev: null
pagination_next: null
---
-Data can be ingested by the Spice runtime for replication to a Data Connector, like PostgreSQL or the Spice.ai Cloud platform.
+Data can be ingested by the Spice runtime for replication to a Data Connector, such as PostgreSQL or the Spice.ai Cloud platform.
-By default, the runtime exposes an [OpenTelemety](https://opentelemetry.io) (OTEL) endpoint at grpc://127.0.0.1:50052 for data ingestion.
+By default, the runtime exposes an [OpenTelemetry](https://opentelemetry.io) (OTEL) endpoint at grpc://127.0.0.1:50052 for data ingestion.
OTEL metrics will be inserted into datasets with matching names (metric name = dataset name) and optionally replicated to the dataset source.
## Benefits
-Spice.ai OSS incorporates built-in data ingestion support, enabling the collection of the latest data from edge nodes for use in subsequent queries. This capability avoids the need for additional ETL pipelines, while also enhancing the speed of the feedback loop.
+Spice.ai OSS includes built-in data ingestion support, allowing the collection of the latest data from edge nodes for use in subsequent queries. This feature eliminates the need for additional ETL pipelines and enhances the speed of the feedback loop.
-As an example, consider CPU usage anomaly detection. When CPU metrics are sent to the Spice OpenTelemetry endpoint, the loaded machine learning model can utilize the most recent observations for inferencing and provide recommendations to the edge node. This process occurs rapidly on the edge itself, within milliseconds and without generating network traffic.
+For example, consider CPU usage anomaly detection. When CPU metrics are sent to the Spice OpenTelemetry endpoint, the loaded machine learning model can use the most recent observations for inferencing and provide recommendations to the edge node. This process occurs quickly on the edge itself, within milliseconds, and without generating network traffic.
-Additional, Spice will replicate the data periodically to the data connector for further usage.
+Additionally, Spice will periodically replicate the data to the data connector for further use.
## Considerations
-Data Quality: Leverage Spice SQL capabilities to transform and cleanse ingested edge data, ensuring high-quality inputs.
+Data Quality: Use Spice SQL capabilities to transform and cleanse ingested edge data, ensuring high-quality inputs.
-Data Security: Assess data sensitivity and secure network connections between edge and data connector when replicating data for further usage. Implement encryption, access controls, and secure protocols.
+Data Security: Evaluate data sensitivity and secure network connections between the edge and data connector when replicating data for further use. Implement encryption, access controls, and secure protocols.
## Example
### [Disk SMART](https://en.wikipedia.org/wiki/Self-Monitoring,_Analysis_and_Reporting_Technology)
-- Start Spice with the following dataset:
+Start Spice with the following dataset:
```yaml
datasets:
@@ -44,7 +44,7 @@ datasets:
enabled: true
```
-- Start telegraf with the following config:
+Start telegraf with the following config:
```
[[inputs.smart]]
diff --git a/spiceaidocs/docs/features/federated-queries/index.md b/spiceaidocs/docs/features/federated-queries/index.md
index 6bf3e542..2d8e4709 100644
--- a/spiceaidocs/docs/features/federated-queries/index.md
+++ b/spiceaidocs/docs/features/federated-queries/index.md
@@ -7,17 +7,15 @@ pagination_prev: null
pagination_next: null
---
-Spice provides a powerful federated query feature that allows you to join and combine data from multiple data sources and perform complex queries. This feature enables you to leverage the full potential of your data by aggregating and analyzing information wherever it is stored.
-
-Spice supports federated query across databases (PostgreSQL, MySQL, etc.), data warehouses (Databricks, Snowflake, BigQuery, etc.), and data lakes (S3, MinIO, etc.). See [Data Connectors](/components/data-connectors/index.md) for the full list of supported sources.
+Spice supports federated queries, enabling you to join and combine data from multiple sources, including databases (PostgreSQL, MySQL), data warehouses (Databricks, Snowflake, BigQuery), and data lakes (S3, MinIO). For a full list of supported sources, see [Data Connectors](/components/data-connectors/index.md).
### Getting Started
-To get started with federated queries using Spice, follow these steps:
+To start using federated queries in Spice, follow these steps:
**Step 1.** Install Spice by following the [installation instructions](/getting-started/index.md).
-**Step 2.** Clone the [Spice Quickstarts repo](https://github.com/spiceai/quickstarts) and navigate to the `federation` directory.
+**Step 2.** Clone the Spice Quickstarts repository and navigate to the `federation` directory.
```bash
git clone https://github.com/spiceai/quickstarts.git
diff --git a/spiceaidocs/docs/features/large-language-models/index.md b/spiceaidocs/docs/features/large-language-models/index.md
index e59a7e4b..7c0eb5d1 100644
--- a/spiceaidocs/docs/features/large-language-models/index.md
+++ b/spiceaidocs/docs/features/large-language-models/index.md
@@ -7,9 +7,7 @@ pagination_prev: null
pagination_next: null
---
-Spice provides a high-performance, OpenAI API-compatible AI Gateway optimized for managing and scaling large language models (LLMs).
-
-Additionally, Spice offers tools for Enterprise Retrieval-Augmented Generation (RAG), such as SQL query across federated datasets and an advanced search feature (see [Search](/features/search)).
+Spice provides a high-performance, OpenAI API-compatible AI Gateway optimized for managing and scaling large language models (LLMs). Additionally, Spice offers tools for Enterprise Retrieval-Augmented Generation (RAG), such as SQL query across federated datasets and an advanced search feature (see [Search](/features/search)).
Spice also supports **full OpenTelemetry observability**, enabling detailed tracking of data flows and requests for full transparency and easier debugging.
diff --git a/spiceaidocs/docs/features/large-language-models/memory.md b/spiceaidocs/docs/features/large-language-models/memory.md
index 51fcf262..95501cf3 100644
--- a/spiceaidocs/docs/features/large-language-models/memory.md
+++ b/spiceaidocs/docs/features/large-language-models/memory.md
@@ -13,9 +13,9 @@ Spice provides memory persistence tools that allow language models to store and
## Enabling Memory Tools
-To enable memory tools for Spice models you need to:
- 1. Define a `store` [memory](/components/data-connectors/memory.md) dataset.
- 2. Specify `memory` in the model's `tools` parameter.
+To enable memory tools for Spice models, define a `store` [memory](/components/data-connectors/memory.md) dataset and specify `memory` in the model's `tools` parameter.
+
+### Example: Enabling Memory Tools
```yaml
datasets:
@@ -31,5 +31,6 @@ models:
```
## Available Tools
- - `store_memory`: Store important information for future reference
- - `load_memory`: Retrieve previously stored memories from the last time period.
+
+- `store_memory`: Store important information for future reference
+- `load_memory`: Retrieve previously stored memories from the last time period.
diff --git a/spiceaidocs/docs/features/large-language-models/parameter_overrides.md b/spiceaidocs/docs/features/large-language-models/parameter_overrides.md
index e41750f2..8424f36d 100644
--- a/spiceaidocs/docs/features/large-language-models/parameter_overrides.md
+++ b/spiceaidocs/docs/features/large-language-models/parameter_overrides.md
@@ -8,21 +8,26 @@ pagination_next: null
---
### Chat Completion Parameter Overrides
-[`v1/chat/completion`](/api/http/chat-completions) is an OpenAI compatible endpoint.
-It supports all request body parameters defined in the [OpenAI reference documentation](https://platform.openai.com/docs/api-reference/chat/create). Spice can configure different defaults for these request parameters.
+[`v1/chat/completion`](/api/http/chat-completions) is an OpenAI-compatible endpoint. It supports all request body parameters defined in the [OpenAI reference documentation](https://platform.openai.com/docs/api-reference/chat/create). Spice can configure different defaults for these request parameters.
+
+### Example: Setting Default Overrides
+
```yaml
models:
- name: pirate-haikus
from: openai:gpt-4o
params:
openai_temperature: 0.1
- openai_response_format: { "type": "json_object" }
+ openai_response_format: { 'type': 'json_object' }
```
+
To specify a default override for a parameter, use the `openai_` prefix followed by the parameter name. For example, to set the `temperature` parameter to `0.1`, use `openai_temperature: 0.1`.
### System Prompt
+
In addition to any system prompts provided in message dialogue, or added by model providers, Spice can configure an additional system prompt.
+
```yaml
models:
- name: pirate-haikus
diff --git a/spiceaidocs/docs/features/large-language-models/runtime_tools.md b/spiceaidocs/docs/features/large-language-models/runtime_tools.md
index 1a2af77f..fe2835d7 100644
--- a/spiceaidocs/docs/features/large-language-models/runtime_tools.md
+++ b/spiceaidocs/docs/features/large-language-models/runtime_tools.md
@@ -7,7 +7,10 @@ pagination_prev: null
pagination_next: null
---
-Spice provides a set of tools that let LLMs interact with the runtime. To provide these tools to a Spice model, specify them in its `params.tools`.
+Spice provides tools that enable LLMs to interact with the runtime. To provide these tools to a Spice model, specify them in its `params.tools`.
+
+### Example: Specifying Tools for a Model
+
```yaml
models:
- name: sql-model
@@ -22,6 +25,7 @@ models:
```
To use all builtin tools with additional tools, use the `builtin` tool group.
+
```yaml
models:
- name: full-runtime
@@ -31,21 +35,23 @@ models:
```
### Tool Recursion Limit
+
When a model requests to call a runtime tool, Spice runs the tool internally and feeds it back to the model. The `tool_recursion_limit` parameter limits the depth of internal recursion Spice will undertake. By default, Spice can infinitely recurse if the model requests to do so.
```yaml
models:
- - name: my-model
- from: openai
- params:
- tool_recursion_limit: 3
+ - name: my-model
+ from: openai
+ params:
+ tool_recursion_limit: 3
```
## Available tools
- - `list_datasets`: List all available datasets in the runtime.
- - `sql`: Execute SQL queries on the runtime.
- - `table_schema`: Get the schema of a specific SQL table.
- - `document_similarity`: For datasets with an embedding column, retrieve documents based on an input query. It is equivalent to [/v1/search](/api/http/search).
- - `sample_distinct_columns`: For a dataset, generate a synthetic sample of data whereby each column has at least a number of distinct values.
- - `random_sample`: Sample random rows from a table.
- - `top_n_sample`: Sample the top N rows from a table based on a specified ordering.
+
+- `list_datasets`: List all available datasets in the runtime.
+- `sql`: Execute SQL queries on the runtime.
+- `table_schema`: Get the schema of a specific SQL table.
+- `document_similarity`: For datasets with an embedding column, retrieve documents based on an input query. It is equivalent to [/v1/search](/api/http/search).
+- `sample_distinct_columns`: For a dataset, generate a synthetic sample of data whereby each column has at least a number of distinct values.
+- `random_sample`: Sample random rows from a table.
+- `top_n_sample`: Sample the top N rows from a table based on a specified ordering.
diff --git a/spiceaidocs/docs/features/machine-learning-models/ml-model-serving/index.md b/spiceaidocs/docs/features/machine-learning-models/ml-model-serving/index.md
index 933e77f4..917c047e 100644
--- a/spiceaidocs/docs/features/machine-learning-models/ml-model-serving/index.md
+++ b/spiceaidocs/docs/features/machine-learning-models/ml-model-serving/index.md
@@ -9,7 +9,7 @@ pagination_next: null
Spice supports loading and serving ONNX models and GGUF LLMs from various sources for embeddings and inference, including local filesystems, Hugging Face, and the Spice Cloud platform.
-Example `spicepod.yml` loading a LLM from HuggingFace:
+### Example: Loading a LLM from Hugging Face
```yaml
models:
diff --git a/spiceaidocs/docs/features/search/index.md b/spiceaidocs/docs/features/search/index.md
index c1982768..1771997e 100644
--- a/spiceaidocs/docs/features/search/index.md
+++ b/spiceaidocs/docs/features/search/index.md
@@ -53,7 +53,7 @@ datasets:
columns:
- name: body
embeddings:
- - from: local_embedding_model # Embedding model used for this column
+ - from: local_embedding_model # Embedding model used for this column
```
By defining embeddings on the `body` column, Spice is now configured to execute similarity searches on the dataset.
diff --git a/spiceaidocs/docs/features/semantic-model/index.md b/spiceaidocs/docs/features/semantic-model/index.md
index 29a777cd..17a3b7c3 100644
--- a/spiceaidocs/docs/features/semantic-model/index.md
+++ b/spiceaidocs/docs/features/semantic-model/index.md
@@ -7,19 +7,17 @@ pagination_prev: null
pagination_next: null
---
-Semantic data models in Spice are defined using the `datasets[*].columns` configuration.
-
-Structured and meaningful data representations can be added to datasets, beneficial for both AI large language models (LLMs) and traditional data analysis.
+Semantic data models in Spice are defined using the `datasets[*].columns` configuration. These models provide structured and meaningful data representations, which are beneficial for both AI large language models (LLMs) and traditional data analysis.
## Use-Cases
### Large Language Models (LLMs)
-The semantic model will automatically be used by [Spice Models](/reference/spicepod/models.md) as context to produce more accurate and context-aware AI responses.
+The semantic model is automatically used by [Spice Models](/reference/spicepod/models.md) as context to produce more accurate and context-aware AI responses.
## Defining a Semantic Model
-Semantic data models are defined within the `spicepod.yaml` file, specifically under the `datasets` section. Each dataset supports `description`, `metadata` and a `columns` field where individual columns are described with metadata and features for utility and clarity.
+Semantic data models are defined within the `spicepod.yaml` file, specifically under the `datasets` section. Each dataset supports `description`, `metadata`, and a `columns` field where individual columns are described with metadata and features for utility and clarity.
### Example Configuration
diff --git a/spiceaidocs/docs/index.md b/spiceaidocs/docs/index.md
index a9679220..5084c5b6 100644
--- a/spiceaidocs/docs/index.md
+++ b/spiceaidocs/docs/index.md
@@ -10,19 +10,19 @@ import ThemeBasedImage from '@site/src/components/ThemeBasedImage';
## What is Spice?
-**Spice** is a portable runtime offering developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake.
+**Spice** is a portable runtime written in Rust that offers developers a unified SQL interface to materialize, accelerate, and query data from any database, data warehouse, or data lake.
📣 Read the [Spice.ai OSS announcement blog post](https://blog.spiceai.org/posts/2024/03/28/adding-spice-the-next-generation-of-spice.ai-oss/).
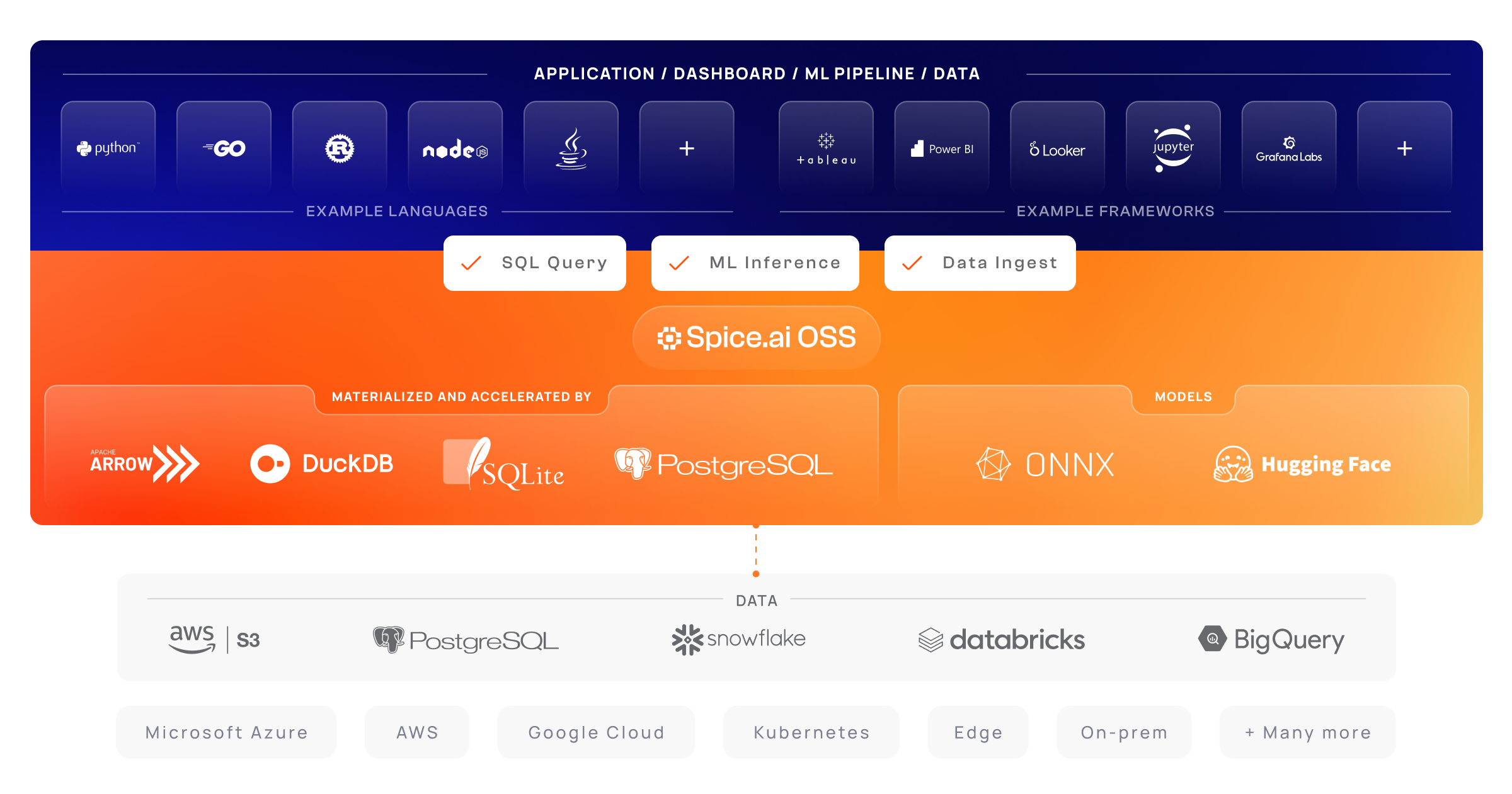
Spice connects, fuses, and delivers data to applications, machine-learning models, and AI-backends, functioning as an application-specific, tier-optimized Database CDN.
-The Spice runtime, written in Rust, is built-with industry leading technologies such as [Apache DataFusion](https://datafusion.apache.org), Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB.
+Spice is built-with industry leading technologies such as [Apache DataFusion](https://datafusion.apache.org), Apache Arrow, Apache Arrow Flight, SQLite, and DuckDB.
## Why Spice?
-Spice makes it easy and fast to query data from one or more sources using SQL. You can co-locate a managed dataset with your application or machine learning model, and accelerate it with Arrow in-memory, SQLite/DuckDB, or with attached PostgreSQL for fast, high-concurrency, low-latency queries. Accelerated engines give you flexibility and control over query cost and performance.
+Spice makes it fast and easy to query data from one or more sources using SQL. You can co-locate a managed dataset with your application or machine learning model, and accelerate it with Arrow in-memory, SQLite/DuckDB, or with attached PostgreSQL for fast, high-concurrency, low-latency queries. Accelerated engines give you flexibility and control over query cost and performance.
@@ -40,7 +40,7 @@ Spice makes it easy and fast to query data from one or more sources using SQL. Y
| | Spice | Trino/Presto | Dremio | Clickhouse |
| -------------------------- | ---------------------------------- | -------------------------------- | -------------------------------- | ----------------------- |
-| Primary Use-Case | Data & AI Applications | Big Data Analytics | Interative Analytics | Real-Time Analytics |
+| Primary Use-Case | Data & AI Applications | Big Data Analytics | Interactive Analytics | Real-Time Analytics |
| Typical Deployment | Colocated with application | Cloud Cluster | Cloud Cluster | On-Prem/Cloud Cluster |
| Application-to-Data System | One-to-One/Many | Many-to-One | Many-to-One | Many-to-One |
| Query Federation | Native with query push-down | Supported with push-down | Supported with limited push-down | Limited |
@@ -64,10 +64,6 @@ Spice makes it easy and fast to query data from one or more sources using SQL. Y
- **Is Spice a CDN for databases?** Yes, you can think of Spice like a CDN for different data sources. Using CDN concepts, Spice enables you to ship (load) a working set of your database (or data lake, or data warehouse) where it's most frequently accessed, like from a data application or for AI-inference.
-:::warning[DEVELOPER PREVIEW]
-Spice is under active **alpha** stage development and is not intended to be used in production until its **1.0-stable** release. If you are interested in running Spice in production, please get in touch below so we can support you.
-:::
-
### Intelligent Applications
Spice enables developers to build both data _and_ AI-driven applications by co-locating data _and_ ML models with applications. Read more about the vision to enable the development of [intelligent AI-driven applications](./intelligent-applications/index.md).
diff --git a/spiceaidocs/docs/intelligent-applications/index.md b/spiceaidocs/docs/intelligent-applications/index.md
index 5c4cac56..c42c2e2a 100644
--- a/spiceaidocs/docs/intelligent-applications/index.md
+++ b/spiceaidocs/docs/intelligent-applications/index.md
@@ -7,14 +7,50 @@ pagination_prev: null
pagination_next: null
---
-As described in the blog post [Making Apps That Learn and Adapt](https://blog.spiceai.org/posts/2021/11/05/making-apps-that-learn-and-adapt/) the long-term vision for Spice.ai is to enable developers to easily build, deploy, and operate intelligent data and AI-driven applications.
+## Building Data-Driven AI Applications with Spice.ai
-With Spice.ai OSS, federated data and ML models are colocated with applications, creating lightweight, high-performance, AI-copilot sidecars.
+Spice.ai represents a paradigm shift in how intelligent applications are developed, deployed, and managed. As outlined in the blog post [Making Apps That Learn and Adapt](https://blog.spiceai.org/posts/2021/11/05/making-apps-that-learn-and-adapt/), the goal of Spice.ai is to eliminate the technical complexity that often hampers developers when building AI-powered solutions. By colocating federated data and machine learning models with applications, Spice.ai provides lightweight, high-performance, and highly scalable AI copilot sidecars. These sidecars streamline application workflows, significantly enhancing both speed and efficiency.
- +At its core, Spice.ai addresses the fragmented nature of traditional AI infrastructure. Data often resides in multiple systems: modern cloud-based warehouses, legacy databases, or unstructured formats like files on FTP servers. Integrating these disparate sources into a unified application pipeline typically requires extensive engineering effort. Spice.ai simplifies this process by federating data across all these sources, materializing it locally for low-latency access, and offering a unified SQL API. This eliminates the need for complex and costly ETL pipelines or federated query engines that operate with high latency.
+
+Spice.ai also colocates machine learning models with the application runtime. This approach reduces the data transfer overhead that occurs when sending data to external inference services. By performing inference locally, applications can respond faster and operate more reliably, even in environments with intermittent network connectivity. The result is an infrastructure that enables developers to focus on building value-driven features rather than wrestling with data and deployment complexities.
+
+---
## The Intelligent Application Workflow
-Dataset definitions and ML Models are packaged as Spicepods and can be published and distributed through the [Spicerack.org](https://spicerack.org) Spicepod registry. Federated datasets are locally materialized, accelerated, and provided to colocated Models. Applications call high-performance, low-latency ML inference APIs for AI generation, insights, recommendations, and forecasts ultimately to make intelligent, AI-driven decisions. Contextual application and environmental data is ingested and replicated back to cloud-scale compute clusters where improved versions of Models are trained and fined-tuned. New versioned Models are automatically deployed to the runtime and are A/B tested and flighted by the application in realtime.
+The workflow for creating intelligent applications with Spice.ai is designed to provide developers with a straightforward, efficient path from data to decision-making. It begins with the creation of `Spicepods`, self-contained packages that define datasets and machine learning models. These packages can be distributed through [Spicerack.org](https://spicerack.org), a registry that allows developers to publish, share, and reuse datasets and models for various applications.
+
+Once deployed, federated datasets are materialized locally within the Spice runtime. Materialization involves prefetching and precomputing data, storing it in high-performance local stores like DuckDB or SQLite. This approach ensures that queries are executed with minimal latency, offering high concurrency and predictable performance. Accelerated access is made possible through advanced caching and query optimization techniques, enabling applications to perform even complex operations without relying on remote databases.
+
+Applications interact with the Spice runtime through high-performance APIs, calling machine learning models for inference tasks such as predictions, recommendations, or anomaly detection. These models are colocated with the runtime, allowing them to leverage the same locally materialized datasets. For example, an e-commerce application could use this infrastructure to provide real-time product recommendations based on user behavior, or a manufacturing system could detect equipment failures before they happen by analyzing time-series sensor data.
+
+As the application runs, contextual and environmental data—such as user actions or external sensor readings—is ingested into the runtime. This data is replicated back to centralized compute clusters where machine learning models are retrained and fine-tuned to improve accuracy and performance. The updated models are automatically versioned and deployed to the runtime, where they can be A/B tested in real time. This continuous feedback loop ensures that applications evolve and improve without manual intervention, reducing time to value while maintaining model relevance.
+
+
+
+---
+
+## Why Spice.ai Is the Future of Intelligent Applications
+
+Spice.ai introduces an entirely new way of thinking about application infrastructure by making intelligent applications accessible to developers of all skill levels. It replaces the need for custom integrations and fragmented tools with a unified runtime optimized for AI and data-driven applications. Unlike traditional architectures that rely heavily on centralized databases or cloud-based inference engines, Spice.ai focuses on tier-optimized deployments. This means that data and computation are colocated wherever the application runs—whether in the cloud, on-prem, or at the edge.
+
+Federation and materialization are at the heart of Spice.ai’s architecture. Instead of querying remote data sources directly, Spice.ai materializes working datasets locally. For example, a logistics application might materialize only the last seven days of shipment data from a cloud data lake, ensuring that 99% of queries are served locally while retaining the ability to fall back to the full dataset as needed. This reduces both latency and costs while improving the user experience.
+
+Machine learning models benefit from the same localized efficiency. Because the models are colocated with the runtime, inference happens in milliseconds rather than seconds, even for complex operations. This is critical for use cases like fraud detection, where split-second decisions can save businesses millions, or real-time personalization, where user engagement depends on instant feedback.
+
+Spice.ai also shines in its ability to integrate with diverse infrastructures. It supports modern cloud-native systems like Snowflake and Databricks, legacy databases like SQL Server, and even unstructured sources like files stored on FTP servers. With support for industry-standard APIs like JDBC, ODBC, and Arrow Flight, it integrates seamlessly into existing applications without requiring extensive refactoring.
+
+In addition to data acceleration and model inference, Spice.ai provides comprehensive observability and monitoring. Every query, inference, and data flow can be tracked and audited, ensuring that applications meet enterprise standards for security, compliance, and reliability. This makes Spice.ai particularly well-suited for industries such as healthcare, finance, and manufacturing, where data privacy and traceability are paramount.
+
+---
+
+## Getting Started with Spice.ai
+
+Developers can start building intelligent applications with Spice.ai by installing the open-source runtime from [GitHub](https://github.com/spiceai/spiceai). The installation process is simple, and the runtime can be deployed across cloud, on-premises, or edge environments. Once installed, developers can create and manage `Spicepods` to define datasets and machine learning models. These `Spicepods` serve as the building blocks for their applications, streamlining data and model integration.
+
+For those looking to accelerate development, [Spicerack.org](https://spicerack.org) provides a curated library of reusable datasets and models. By using these pre-built components, developers can reduce time to deployment while focusing on the unique features of their applications.
+
+The Spice.ai community is an essential resource for new and experienced developers alike. Through forums, documentation, and hands-on support, the community helps developers unlock the full potential of intelligent applications. Whether you’re building real-time analytics systems, AI-enhanced enterprise tools, or edge-based IoT applications, Spice.ai provides the infrastructure you need to succeed.
-
+At its core, Spice.ai addresses the fragmented nature of traditional AI infrastructure. Data often resides in multiple systems: modern cloud-based warehouses, legacy databases, or unstructured formats like files on FTP servers. Integrating these disparate sources into a unified application pipeline typically requires extensive engineering effort. Spice.ai simplifies this process by federating data across all these sources, materializing it locally for low-latency access, and offering a unified SQL API. This eliminates the need for complex and costly ETL pipelines or federated query engines that operate with high latency.
+
+Spice.ai also colocates machine learning models with the application runtime. This approach reduces the data transfer overhead that occurs when sending data to external inference services. By performing inference locally, applications can respond faster and operate more reliably, even in environments with intermittent network connectivity. The result is an infrastructure that enables developers to focus on building value-driven features rather than wrestling with data and deployment complexities.
+
+---
## The Intelligent Application Workflow
-Dataset definitions and ML Models are packaged as Spicepods and can be published and distributed through the [Spicerack.org](https://spicerack.org) Spicepod registry. Federated datasets are locally materialized, accelerated, and provided to colocated Models. Applications call high-performance, low-latency ML inference APIs for AI generation, insights, recommendations, and forecasts ultimately to make intelligent, AI-driven decisions. Contextual application and environmental data is ingested and replicated back to cloud-scale compute clusters where improved versions of Models are trained and fined-tuned. New versioned Models are automatically deployed to the runtime and are A/B tested and flighted by the application in realtime.
+The workflow for creating intelligent applications with Spice.ai is designed to provide developers with a straightforward, efficient path from data to decision-making. It begins with the creation of `Spicepods`, self-contained packages that define datasets and machine learning models. These packages can be distributed through [Spicerack.org](https://spicerack.org), a registry that allows developers to publish, share, and reuse datasets and models for various applications.
+
+Once deployed, federated datasets are materialized locally within the Spice runtime. Materialization involves prefetching and precomputing data, storing it in high-performance local stores like DuckDB or SQLite. This approach ensures that queries are executed with minimal latency, offering high concurrency and predictable performance. Accelerated access is made possible through advanced caching and query optimization techniques, enabling applications to perform even complex operations without relying on remote databases.
+
+Applications interact with the Spice runtime through high-performance APIs, calling machine learning models for inference tasks such as predictions, recommendations, or anomaly detection. These models are colocated with the runtime, allowing them to leverage the same locally materialized datasets. For example, an e-commerce application could use this infrastructure to provide real-time product recommendations based on user behavior, or a manufacturing system could detect equipment failures before they happen by analyzing time-series sensor data.
+
+As the application runs, contextual and environmental data—such as user actions or external sensor readings—is ingested into the runtime. This data is replicated back to centralized compute clusters where machine learning models are retrained and fine-tuned to improve accuracy and performance. The updated models are automatically versioned and deployed to the runtime, where they can be A/B tested in real time. This continuous feedback loop ensures that applications evolve and improve without manual intervention, reducing time to value while maintaining model relevance.
+
+
+
+---
+
+## Why Spice.ai Is the Future of Intelligent Applications
+
+Spice.ai introduces an entirely new way of thinking about application infrastructure by making intelligent applications accessible to developers of all skill levels. It replaces the need for custom integrations and fragmented tools with a unified runtime optimized for AI and data-driven applications. Unlike traditional architectures that rely heavily on centralized databases or cloud-based inference engines, Spice.ai focuses on tier-optimized deployments. This means that data and computation are colocated wherever the application runs—whether in the cloud, on-prem, or at the edge.
+
+Federation and materialization are at the heart of Spice.ai’s architecture. Instead of querying remote data sources directly, Spice.ai materializes working datasets locally. For example, a logistics application might materialize only the last seven days of shipment data from a cloud data lake, ensuring that 99% of queries are served locally while retaining the ability to fall back to the full dataset as needed. This reduces both latency and costs while improving the user experience.
+
+Machine learning models benefit from the same localized efficiency. Because the models are colocated with the runtime, inference happens in milliseconds rather than seconds, even for complex operations. This is critical for use cases like fraud detection, where split-second decisions can save businesses millions, or real-time personalization, where user engagement depends on instant feedback.
+
+Spice.ai also shines in its ability to integrate with diverse infrastructures. It supports modern cloud-native systems like Snowflake and Databricks, legacy databases like SQL Server, and even unstructured sources like files stored on FTP servers. With support for industry-standard APIs like JDBC, ODBC, and Arrow Flight, it integrates seamlessly into existing applications without requiring extensive refactoring.
+
+In addition to data acceleration and model inference, Spice.ai provides comprehensive observability and monitoring. Every query, inference, and data flow can be tracked and audited, ensuring that applications meet enterprise standards for security, compliance, and reliability. This makes Spice.ai particularly well-suited for industries such as healthcare, finance, and manufacturing, where data privacy and traceability are paramount.
+
+---
+
+## Getting Started with Spice.ai
+
+Developers can start building intelligent applications with Spice.ai by installing the open-source runtime from [GitHub](https://github.com/spiceai/spiceai). The installation process is simple, and the runtime can be deployed across cloud, on-premises, or edge environments. Once installed, developers can create and manage `Spicepods` to define datasets and machine learning models. These `Spicepods` serve as the building blocks for their applications, streamlining data and model integration.
+
+For those looking to accelerate development, [Spicerack.org](https://spicerack.org) provides a curated library of reusable datasets and models. By using these pre-built components, developers can reduce time to deployment while focusing on the unique features of their applications.
+
+The Spice.ai community is an essential resource for new and experienced developers alike. Through forums, documentation, and hands-on support, the community helps developers unlock the full potential of intelligent applications. Whether you’re building real-time analytics systems, AI-enhanced enterprise tools, or edge-based IoT applications, Spice.ai provides the infrastructure you need to succeed.
- +In a world where intelligent applications are increasingly becoming the norm, Spice.ai stands out as the definitive platform for building fast, scalable, and secure AI-driven solutions. Its unified approach to data, computation, and machine learning sets a new standard for how applications are developed and deployed.
diff --git a/spiceaidocs/docs/reference/spicepod/catalogs.md b/spiceaidocs/docs/reference/spicepod/catalogs.md
index 5006b7ec..c9dfb703 100644
--- a/spiceaidocs/docs/reference/spicepod/catalogs.md
+++ b/spiceaidocs/docs/reference/spicepod/catalogs.md
@@ -17,7 +17,7 @@ catalogs:
- from: spice.ai
name: spiceai
include:
- - "tpch.*" # Include only the "tpch" tables.
+ - 'tpch.*' # Include only the "tpch" tables.
```
## `from`
@@ -54,7 +54,7 @@ An alternative to adding the catalog definition inline in the `spicepod.yaml` fi
from: spice.ai
name: spiceai
include:
- - "tpch.*" # Include only the "tpch" tables.
+ - 'tpch.*' # Include only the "tpch" tables.
```
**ref used in spicepod.yaml**
diff --git a/spiceaidocs/docs/reference/spicepod/embeddings.md b/spiceaidocs/docs/reference/spicepod/embeddings.md
index a60c2f2a..eb302e64 100644
--- a/spiceaidocs/docs/reference/spicepod/embeddings.md
+++ b/spiceaidocs/docs/reference/spicepod/embeddings.md
@@ -4,13 +4,11 @@ sidebar_label: 'Embeddings'
description: 'Embeddings YAML reference'
---
-# Embeddings
-
-Embeddings allow you to convert text or other data into vector representations, which can be used for various machine learning and natural language processing tasks.
+Embeddings convert text or other data into vector representations for machine learning and natural language processing tasks.
## `embeddings`
-The `embeddings` section in your configuration allows you to specify one or more embedding models to be used with your datasets.
+The `embeddings` section in your configuration specifies one or more embedding models for your datasets.
Example:
@@ -19,7 +17,7 @@ embeddings:
- from: huggingface:huggingface.co/sentence-transformers/all-MiniLM-L6-v2:latest
name: text_embedder
params:
- max_length: "128"
+ max_length: '128'
datasets:
- my_text_dataset
```
@@ -54,4 +52,4 @@ Optional. A map of key-value pairs for additional parameters specific to the emb
### `dependsOn`
-Optional. A list of dependencies that must be loaded and available before this embedding model.
\ No newline at end of file
+Optional. A list of dependencies that must be loaded and available before this embedding model.
diff --git a/spiceaidocs/docs/reference/spicepod/index.md b/spiceaidocs/docs/reference/spicepod/index.md
index 68741b66..ba6c9826 100644
--- a/spiceaidocs/docs/reference/spicepod/index.md
+++ b/spiceaidocs/docs/reference/spicepod/index.md
@@ -7,7 +7,7 @@ description: 'Detailed documentation on the Spicepod manifest syntax (spicepod.y
## About YAML syntax for Spicepod manifests (spicepod.yaml)
-Spicepod manifests use YAML syntax and must be named `spicepod.yaml` or `spicepod.yml`. If you're new to YAML and want to learn more, see "[Learn YAML in Y minutes](https://learnxinyminutes.com/docs/yaml/)."
+Spicepod manifests use YAML syntax and must be named `spicepod.yaml` or `spicepod.yml`. If you are new to YAML and want to learn more, see "[Learn YAML in Y minutes](https://learnxinyminutes.com/docs/yaml/)."
Spicepod manifest files are stored in the root directory of your application code.
@@ -25,7 +25,7 @@ The name of the Spicepod.
## `secrets`
-The secrets section in the Spicepod manifest is optional and is used to configure how secrets are stored and accessed by the Spicepod. [Learn more](/components/secret-stores).
+The secrets section in the Spicepod manifest is optional and is used to configure how secrets are stored and accessed by the Spicepod. For more information, see [Secret Stores](/components/secret-stores).
### `secrets.from`
@@ -215,7 +215,7 @@ Example:
runtime:
cors:
enabled: true
- allowed_origins: ["https://example.com"]
+ allowed_origins: ['https://example.com']
```
This configuration allows requests from the `https://example.com` origin only.
diff --git a/spiceaidocs/docs/reference/spicepod/models.md b/spiceaidocs/docs/reference/spicepod/models.md
index 26fe5d56..843bd046 100644
--- a/spiceaidocs/docs/reference/spicepod/models.md
+++ b/spiceaidocs/docs/reference/spicepod/models.md
@@ -1,6 +1,6 @@
---
-title: "Models"
-sidebar_label: "Models"
+title: 'Models'
+sidebar_label: 'Models'
description: 'Models YAML reference'
pagination_next: null
---
@@ -15,7 +15,6 @@ The model specifications are in early preview and are subject to change.
Spice supports both traditional machine learning (ML) models and language models (LLMs). The configuration allows you to specify either type from a variety of sources. The model type is automatically determined based on the model source and files.
-
| field | Description |
| ------------- | ----------------------------------------------------------------------- |
| `name` | Unique, readable name for the model within the Spicepod. |
@@ -43,7 +42,7 @@ models:
- path: tokenizer.json
type: tokenizer
params:
- max_length: "128"
+ max_length: '128'
datasets:
- my_text_dataset
```
@@ -72,10 +71,10 @@ The `` suffix of the `from` field is a unique (per source) identifier
- For Spice AI: Supports only ML models. Represents the full path to the model in the Spice AI repository. Supports a version suffix (default to `latest`).
- Example: `lukekim/smart/models/drive_stats:60cb80a2-d59b-45c4-9b68-0946303bdcaf`
- For Hugging Face: A repo_id and, optionally, revision hash or tag.
- - `Qwen/Qwen1.5-0.5B` (no revision)
- - `meta-llama/Meta-Llama-3-8B:cd892e8f4da1043d4b01d5ea182a2e8412bf658f` (with revision hash)
+ - `Qwen/Qwen1.5-0.5B` (no revision)
+ - `meta-llama/Meta-Llama-3-8B:cd892e8f4da1043d4b01d5ea182a2e8412bf658f` (with revision hash)
- For local files: Represents the absolute or relative path to the model weights file on the local file system. See [below](#files) for the accepted model weight types and formats.
-- For OpenAI: Only supports LMs. For OpenAI models, valid IDs can be found in their model [documentation](https://platform.openai.com/docs/models/continuous-model-upgrades). For OpenAI compatible providers, specify the value required in their `v1/chat/completion` [payload](https://platform.openai.com/docs/api-reference/chat/create#chat-create-model).
+- For OpenAI: Only supports LMs. For OpenAI models, valid IDs can be found in their model [documentation](https://platform.openai.com/docs/models/continuous-model-upgrades). For OpenAI compatible providers, specify the value required in their `v1/chat/completion` [payload](https://platform.openai.com/docs/api-reference/chat/create#chat-create-model).
### `name`
@@ -94,16 +93,20 @@ Optional. A list of files associated with this model. Each file has:
- `type`: Optional. The type of the file (automatically determined if not specified)
File types include:
+
- `weights`: Model weights
+
- For ML models: typically `.onnx` files
- For LLMs: `.gguf`, `.ggml`, `.safetensors`, or `pytorch_model.bin` files
- These files contain the trained parameters of the model
- `config`: Model configuration
+
- Usually a `config.json` file
- Contains model architecture and hyperparameters
- `tokenizer`: Tokenizer file
+
- Usually a `tokenizer.json` file
- Defines how input text is converted into tokens for the model
@@ -118,8 +121,9 @@ The system attempts to automatically determine the file type based on the file n
Optional. A map of key-value pairs for additional parameters specific to the model.
Example uses include:
- - Setting default OpenAI request parameters for language models, see [parameter overrides](/features/large-language-models/parameter_overrides.md).
- - Allowing Language models to perform actions against spice (e.g. making SQL queries), via language model tool use, see [runtime tools](/features/large-language-models/runtime_tools.md).
+
+- Setting default OpenAI request parameters for language models, see [parameter overrides](/features/large-language-models/parameter_overrides.md).
+- Allowing Language models to perform actions against spice (e.g. making SQL queries), via language model tool use, see [runtime tools](/features/large-language-models/runtime_tools.md).
### `datasets`
diff --git a/spiceaidocs/docs/use-cases/data-mesh/index.md b/spiceaidocs/docs/use-cases/data-mesh/index.md
index ba46e017..2348c37b 100644
--- a/spiceaidocs/docs/use-cases/data-mesh/index.md
+++ b/spiceaidocs/docs/use-cases/data-mesh/index.md
@@ -7,10 +7,10 @@ pagination_prev: null
pagination_next: null
---
-## Accessing data across many, disparate data sources
+## Accessing data across multiple, disparate data sources
-[Federated SQL query](/features/federated-queries) across databases, data warehouses, and data lakes using [Data Connectors](/components/data-connectors).
+Perform [federated SQL queries](/features/federated-queries) across databases, data warehouses, and data lakes using [Data Connectors](/components/data-connectors).
-## Migrations from legacy data systems
+## Migrating from legacy data systems
-A drop-in solution to provides a single, unified endpoint to many data systems without changes to the application.
+Spice provides a drop-in solution that offers a single, unified endpoint to multiple data systems without requiring changes to the application.
diff --git a/spiceaidocs/docs/use-cases/database-cdn/index.md b/spiceaidocs/docs/use-cases/database-cdn/index.md
index 6ca2b293..4d2859c0 100644
--- a/spiceaidocs/docs/use-cases/database-cdn/index.md
+++ b/spiceaidocs/docs/use-cases/database-cdn/index.md
@@ -7,18 +7,18 @@ pagination_prev: null
pagination_next: null
---
-## Slow data applications
+## Enhancing data application performance
Colocate a local working set of hot data with data applications and frontends to serve more concurrent requests and users with faster page loads and data updates.
[Try the CQRS sample app](https://github.com/spiceai/samples/tree/trunk/acceleration#local-materialization-and-acceleration-cqrs-sample)
-## Fragile data applications
+## Increasing application resilience
-Keep local replicas of data with the application for significantly higher application resilience and availability.
+Maintain local replicas of data with the application to significantly enhance application resilience and availability.
-## Slow dashboards, analytics, and BI
+## Improving dashboard, analytics, and BI performance
-Create a materialization layer for visualization products like Power BI, Tableau, or Superset for faster, more responsive dashboards without massive compute costs.
+Create a materialization layer for visualization tools like Power BI, Tableau, or Superset to achieve faster, more responsive dashboards without incurring massive compute costs.
[Watch the Apache Superset demo](https://github.com/spiceai/samples/blob/trunk/sales-bi/README.md)
diff --git a/spiceaidocs/docs/use-cases/enterprise-search/index.md b/spiceaidocs/docs/use-cases/enterprise-search/index.md
index 402cce23..2c946e91 100644
--- a/spiceaidocs/docs/use-cases/enterprise-search/index.md
+++ b/spiceaidocs/docs/use-cases/enterprise-search/index.md
@@ -7,8 +7,8 @@ pagination_prev: null
pagination_next: null
---
-## Vector similarily search across disparate and legacy data systems
+## Vector similarity search across disparate and legacy data systems
-Enterprises face a new challenge when using AI. They now need to access data from disparate and legacy systems so AI has full-knowledge for context. It needs to be fast to be useful.
+Enterprises face the challenge of accessing data from various disparate and legacy systems to provide AI with comprehensive context. Speed is crucial for this process to be effective.
-Spice is a blazingly fast knowledge index into structured and unstructured data.
+Spice offers a fast knowledge index into both structured and unstructured data, enabling efficient vector similarity search across multiple data sources. This ensures that AI applications have access to the necessary data for accurate and timely responses.
diff --git a/spiceaidocs/docs/use-cases/rag/index.md b/spiceaidocs/docs/use-cases/rag/index.md
index 5b504e3e..c564ca46 100644
--- a/spiceaidocs/docs/use-cases/rag/index.md
+++ b/spiceaidocs/docs/use-cases/rag/index.md
@@ -7,6 +7,6 @@ pagination_prev: null
pagination_next: null
---
-Use Spice to access data across disparate datasources for Retrieval-Augmented-Generation (RAG).
+Use Spice to access data across various data sources for Retrieval-Augmented-Generation (RAG).
-Spice helps developers combine structured data via SQL query, and unstructured data recommended by built-in vector similarility search, to feed to large-language-models (LLMs) through a native AI-gateway.
+Spice enables developers to combine structured data via SQL queries and unstructured data through built-in vector similarity search. This combined data can then be fed to large language models (LLMs) through a native AI gateway, enhancing the models' ability to generate accurate and contextually relevant responses.
+In a world where intelligent applications are increasingly becoming the norm, Spice.ai stands out as the definitive platform for building fast, scalable, and secure AI-driven solutions. Its unified approach to data, computation, and machine learning sets a new standard for how applications are developed and deployed.
diff --git a/spiceaidocs/docs/reference/spicepod/catalogs.md b/spiceaidocs/docs/reference/spicepod/catalogs.md
index 5006b7ec..c9dfb703 100644
--- a/spiceaidocs/docs/reference/spicepod/catalogs.md
+++ b/spiceaidocs/docs/reference/spicepod/catalogs.md
@@ -17,7 +17,7 @@ catalogs:
- from: spice.ai
name: spiceai
include:
- - "tpch.*" # Include only the "tpch" tables.
+ - 'tpch.*' # Include only the "tpch" tables.
```
## `from`
@@ -54,7 +54,7 @@ An alternative to adding the catalog definition inline in the `spicepod.yaml` fi
from: spice.ai
name: spiceai
include:
- - "tpch.*" # Include only the "tpch" tables.
+ - 'tpch.*' # Include only the "tpch" tables.
```
**ref used in spicepod.yaml**
diff --git a/spiceaidocs/docs/reference/spicepod/embeddings.md b/spiceaidocs/docs/reference/spicepod/embeddings.md
index a60c2f2a..eb302e64 100644
--- a/spiceaidocs/docs/reference/spicepod/embeddings.md
+++ b/spiceaidocs/docs/reference/spicepod/embeddings.md
@@ -4,13 +4,11 @@ sidebar_label: 'Embeddings'
description: 'Embeddings YAML reference'
---
-# Embeddings
-
-Embeddings allow you to convert text or other data into vector representations, which can be used for various machine learning and natural language processing tasks.
+Embeddings convert text or other data into vector representations for machine learning and natural language processing tasks.
## `embeddings`
-The `embeddings` section in your configuration allows you to specify one or more embedding models to be used with your datasets.
+The `embeddings` section in your configuration specifies one or more embedding models for your datasets.
Example:
@@ -19,7 +17,7 @@ embeddings:
- from: huggingface:huggingface.co/sentence-transformers/all-MiniLM-L6-v2:latest
name: text_embedder
params:
- max_length: "128"
+ max_length: '128'
datasets:
- my_text_dataset
```
@@ -54,4 +52,4 @@ Optional. A map of key-value pairs for additional parameters specific to the emb
### `dependsOn`
-Optional. A list of dependencies that must be loaded and available before this embedding model.
\ No newline at end of file
+Optional. A list of dependencies that must be loaded and available before this embedding model.
diff --git a/spiceaidocs/docs/reference/spicepod/index.md b/spiceaidocs/docs/reference/spicepod/index.md
index 68741b66..ba6c9826 100644
--- a/spiceaidocs/docs/reference/spicepod/index.md
+++ b/spiceaidocs/docs/reference/spicepod/index.md
@@ -7,7 +7,7 @@ description: 'Detailed documentation on the Spicepod manifest syntax (spicepod.y
## About YAML syntax for Spicepod manifests (spicepod.yaml)
-Spicepod manifests use YAML syntax and must be named `spicepod.yaml` or `spicepod.yml`. If you're new to YAML and want to learn more, see "[Learn YAML in Y minutes](https://learnxinyminutes.com/docs/yaml/)."
+Spicepod manifests use YAML syntax and must be named `spicepod.yaml` or `spicepod.yml`. If you are new to YAML and want to learn more, see "[Learn YAML in Y minutes](https://learnxinyminutes.com/docs/yaml/)."
Spicepod manifest files are stored in the root directory of your application code.
@@ -25,7 +25,7 @@ The name of the Spicepod.
## `secrets`
-The secrets section in the Spicepod manifest is optional and is used to configure how secrets are stored and accessed by the Spicepod. [Learn more](/components/secret-stores).
+The secrets section in the Spicepod manifest is optional and is used to configure how secrets are stored and accessed by the Spicepod. For more information, see [Secret Stores](/components/secret-stores).
### `secrets.from`
@@ -215,7 +215,7 @@ Example:
runtime:
cors:
enabled: true
- allowed_origins: ["https://example.com"]
+ allowed_origins: ['https://example.com']
```
This configuration allows requests from the `https://example.com` origin only.
diff --git a/spiceaidocs/docs/reference/spicepod/models.md b/spiceaidocs/docs/reference/spicepod/models.md
index 26fe5d56..843bd046 100644
--- a/spiceaidocs/docs/reference/spicepod/models.md
+++ b/spiceaidocs/docs/reference/spicepod/models.md
@@ -1,6 +1,6 @@
---
-title: "Models"
-sidebar_label: "Models"
+title: 'Models'
+sidebar_label: 'Models'
description: 'Models YAML reference'
pagination_next: null
---
@@ -15,7 +15,6 @@ The model specifications are in early preview and are subject to change.
Spice supports both traditional machine learning (ML) models and language models (LLMs). The configuration allows you to specify either type from a variety of sources. The model type is automatically determined based on the model source and files.
-
| field | Description |
| ------------- | ----------------------------------------------------------------------- |
| `name` | Unique, readable name for the model within the Spicepod. |
@@ -43,7 +42,7 @@ models:
- path: tokenizer.json
type: tokenizer
params:
- max_length: "128"
+ max_length: '128'
datasets:
- my_text_dataset
```
@@ -72,10 +71,10 @@ The `` suffix of the `from` field is a unique (per source) identifier
- For Spice AI: Supports only ML models. Represents the full path to the model in the Spice AI repository. Supports a version suffix (default to `latest`).
- Example: `lukekim/smart/models/drive_stats:60cb80a2-d59b-45c4-9b68-0946303bdcaf`
- For Hugging Face: A repo_id and, optionally, revision hash or tag.
- - `Qwen/Qwen1.5-0.5B` (no revision)
- - `meta-llama/Meta-Llama-3-8B:cd892e8f4da1043d4b01d5ea182a2e8412bf658f` (with revision hash)
+ - `Qwen/Qwen1.5-0.5B` (no revision)
+ - `meta-llama/Meta-Llama-3-8B:cd892e8f4da1043d4b01d5ea182a2e8412bf658f` (with revision hash)
- For local files: Represents the absolute or relative path to the model weights file on the local file system. See [below](#files) for the accepted model weight types and formats.
-- For OpenAI: Only supports LMs. For OpenAI models, valid IDs can be found in their model [documentation](https://platform.openai.com/docs/models/continuous-model-upgrades). For OpenAI compatible providers, specify the value required in their `v1/chat/completion` [payload](https://platform.openai.com/docs/api-reference/chat/create#chat-create-model).
+- For OpenAI: Only supports LMs. For OpenAI models, valid IDs can be found in their model [documentation](https://platform.openai.com/docs/models/continuous-model-upgrades). For OpenAI compatible providers, specify the value required in their `v1/chat/completion` [payload](https://platform.openai.com/docs/api-reference/chat/create#chat-create-model).
### `name`
@@ -94,16 +93,20 @@ Optional. A list of files associated with this model. Each file has:
- `type`: Optional. The type of the file (automatically determined if not specified)
File types include:
+
- `weights`: Model weights
+
- For ML models: typically `.onnx` files
- For LLMs: `.gguf`, `.ggml`, `.safetensors`, or `pytorch_model.bin` files
- These files contain the trained parameters of the model
- `config`: Model configuration
+
- Usually a `config.json` file
- Contains model architecture and hyperparameters
- `tokenizer`: Tokenizer file
+
- Usually a `tokenizer.json` file
- Defines how input text is converted into tokens for the model
@@ -118,8 +121,9 @@ The system attempts to automatically determine the file type based on the file n
Optional. A map of key-value pairs for additional parameters specific to the model.
Example uses include:
- - Setting default OpenAI request parameters for language models, see [parameter overrides](/features/large-language-models/parameter_overrides.md).
- - Allowing Language models to perform actions against spice (e.g. making SQL queries), via language model tool use, see [runtime tools](/features/large-language-models/runtime_tools.md).
+
+- Setting default OpenAI request parameters for language models, see [parameter overrides](/features/large-language-models/parameter_overrides.md).
+- Allowing Language models to perform actions against spice (e.g. making SQL queries), via language model tool use, see [runtime tools](/features/large-language-models/runtime_tools.md).
### `datasets`
diff --git a/spiceaidocs/docs/use-cases/data-mesh/index.md b/spiceaidocs/docs/use-cases/data-mesh/index.md
index ba46e017..2348c37b 100644
--- a/spiceaidocs/docs/use-cases/data-mesh/index.md
+++ b/spiceaidocs/docs/use-cases/data-mesh/index.md
@@ -7,10 +7,10 @@ pagination_prev: null
pagination_next: null
---
-## Accessing data across many, disparate data sources
+## Accessing data across multiple, disparate data sources
-[Federated SQL query](/features/federated-queries) across databases, data warehouses, and data lakes using [Data Connectors](/components/data-connectors).
+Perform [federated SQL queries](/features/federated-queries) across databases, data warehouses, and data lakes using [Data Connectors](/components/data-connectors).
-## Migrations from legacy data systems
+## Migrating from legacy data systems
-A drop-in solution to provides a single, unified endpoint to many data systems without changes to the application.
+Spice provides a drop-in solution that offers a single, unified endpoint to multiple data systems without requiring changes to the application.
diff --git a/spiceaidocs/docs/use-cases/database-cdn/index.md b/spiceaidocs/docs/use-cases/database-cdn/index.md
index 6ca2b293..4d2859c0 100644
--- a/spiceaidocs/docs/use-cases/database-cdn/index.md
+++ b/spiceaidocs/docs/use-cases/database-cdn/index.md
@@ -7,18 +7,18 @@ pagination_prev: null
pagination_next: null
---
-## Slow data applications
+## Enhancing data application performance
Colocate a local working set of hot data with data applications and frontends to serve more concurrent requests and users with faster page loads and data updates.
[Try the CQRS sample app](https://github.com/spiceai/samples/tree/trunk/acceleration#local-materialization-and-acceleration-cqrs-sample)
-## Fragile data applications
+## Increasing application resilience
-Keep local replicas of data with the application for significantly higher application resilience and availability.
+Maintain local replicas of data with the application to significantly enhance application resilience and availability.
-## Slow dashboards, analytics, and BI
+## Improving dashboard, analytics, and BI performance
-Create a materialization layer for visualization products like Power BI, Tableau, or Superset for faster, more responsive dashboards without massive compute costs.
+Create a materialization layer for visualization tools like Power BI, Tableau, or Superset to achieve faster, more responsive dashboards without incurring massive compute costs.
[Watch the Apache Superset demo](https://github.com/spiceai/samples/blob/trunk/sales-bi/README.md)
diff --git a/spiceaidocs/docs/use-cases/enterprise-search/index.md b/spiceaidocs/docs/use-cases/enterprise-search/index.md
index 402cce23..2c946e91 100644
--- a/spiceaidocs/docs/use-cases/enterprise-search/index.md
+++ b/spiceaidocs/docs/use-cases/enterprise-search/index.md
@@ -7,8 +7,8 @@ pagination_prev: null
pagination_next: null
---
-## Vector similarily search across disparate and legacy data systems
+## Vector similarity search across disparate and legacy data systems
-Enterprises face a new challenge when using AI. They now need to access data from disparate and legacy systems so AI has full-knowledge for context. It needs to be fast to be useful.
+Enterprises face the challenge of accessing data from various disparate and legacy systems to provide AI with comprehensive context. Speed is crucial for this process to be effective.
-Spice is a blazingly fast knowledge index into structured and unstructured data.
+Spice offers a fast knowledge index into both structured and unstructured data, enabling efficient vector similarity search across multiple data sources. This ensures that AI applications have access to the necessary data for accurate and timely responses.
diff --git a/spiceaidocs/docs/use-cases/rag/index.md b/spiceaidocs/docs/use-cases/rag/index.md
index 5b504e3e..c564ca46 100644
--- a/spiceaidocs/docs/use-cases/rag/index.md
+++ b/spiceaidocs/docs/use-cases/rag/index.md
@@ -7,6 +7,6 @@ pagination_prev: null
pagination_next: null
---
-Use Spice to access data across disparate datasources for Retrieval-Augmented-Generation (RAG).
+Use Spice to access data across various data sources for Retrieval-Augmented-Generation (RAG).
-Spice helps developers combine structured data via SQL query, and unstructured data recommended by built-in vector similarility search, to feed to large-language-models (LLMs) through a native AI-gateway.
+Spice enables developers to combine structured data via SQL queries and unstructured data through built-in vector similarity search. This combined data can then be fed to large language models (LLMs) through a native AI gateway, enhancing the models' ability to generate accurate and contextually relevant responses.